Train/Dev/Test sets
一般地,我们将所有的样本数据分成三个部分:
- Train sets用来训练你的算法模型;
- Dev sets用来验证不同算法的表现情况,从中选择最好的算法模型;
- Test sets用来测试最好算法的实际表现,作为该算法的无偏估计。
设置合适的Train/Dev/Test sets数量,能有效提高训练效率。
- 数据集规模相对较小,适用传统的划分比例,如60%训练,20%验证和20%测试集
- 数据集规模较大的,验证集和测试集要小于数据总量的20%或10%。 因为Dev sets的目标是用来比较验证不同算法的优劣,从而选择更好的算法模型就行了。 因此,通常不需要所有样本的20%这么多的数据来进行验证。对于100万的样本,往往只需要1万个样本来做验证就够了。 Test sets也是一样,目标是测试已选算法的实际表现,无偏估计。对于100万的样本,往往也只需要1万个样本就够了。 因此,对于大数据样本,Train/Dev/Test sets的比例通常可以设置为98%/1%/1%,或者99%/0.5%/0.5%。样本数据量越大,相应的Dev/Test sets的比例可以设置的越低一些。
训练样本和测试样本来自于不同的分布,解决这一问题的比较科学的办法是尽量保证Dev sets和Test sets来自于同一分布。 值得一提的是,训练样本非常重要,通常我们可以将现有的训练样本做一些处理,例如图片的翻转、假如随机噪声等,来扩大训练样本的数量,从而让该模型更加强大。 即使Train sets和Dev/Test sets不来自同一分布,使用这些技巧也能提高模型性能。
最后一点,就算没有测试集也不要紧,测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。所以如果只有验证集,没有测试集,我们要做的就是,在训练集上训练,尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型。因为验证集中已经涵盖测试集数据,其不再提供无偏性能评估。当然,如果你不需要无偏估计,那就再好不过了。
偏差,方差(Bias /Variance)
Bias和Variance是对立的,分别对应着欠拟合和过拟合,我们常常需要在Bias和Variance之间进行权衡。 而在深度学习中,我们可以同时减小Bias和Variance,构建最佳神经网络模型,两者可以区分对待,而不用权衡。
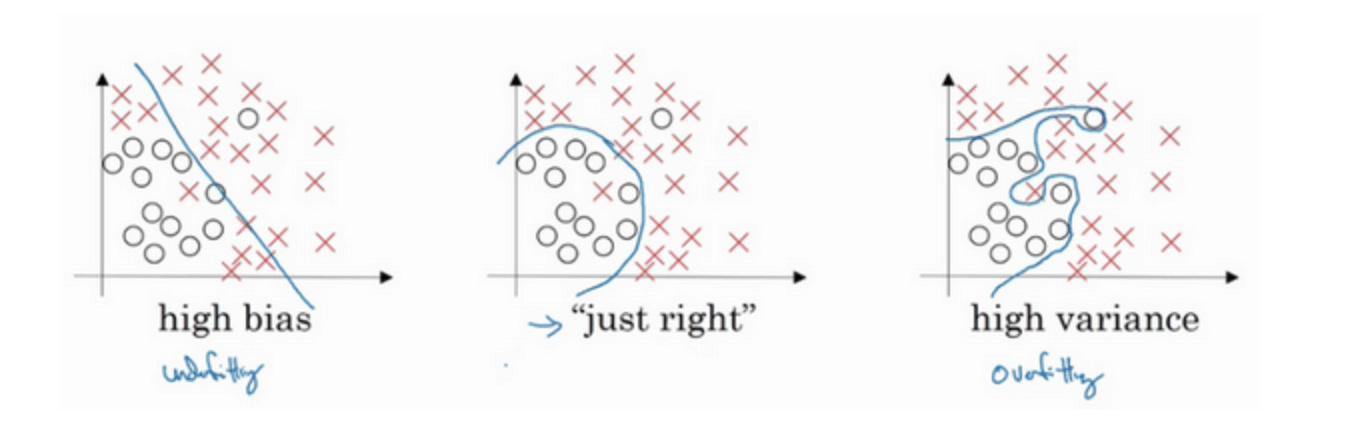 通过两个数值Train set error和Dev set error来理解bias和variance
通过两个数值Train set error和Dev set error来理解bias和variance
- 首先要知道算法的偏差高不高,如果偏差较高,试着评估训练集或训练数据的性能。如果偏差的确很高,甚至无法拟合训练集,那么你要做的就是选择一个新的网络
- 减少bias
- 增加隐藏层数
- 增加神经元个数
- 更多时间来训练网络
- 选择其它更复杂的NN模型
- 减少bias
- 一旦偏差降低到可以接受的数值,检查一下方差有没有问题,为了评估方差,我们要查看验证集性能,我们能从一个性能理想的训练集推断出验证集的性能是否也理想。
- 减少variance
- 增加训练样本数据
- 正则化来减少过拟合
- 减少variance
- 只要正则适度,通常构建一个更大的网络便可以,在不影响方差的同时减少偏差,而采用更多数据通常可以在不过多影响偏差的同时减少方差。 这两步实际要做的工作是:训练网络,选择网络或者准备更多数据,现在我们有工具可以做到在减少偏差或方差的同时,不对另一方产生过多不良影响。
正则化(Regularization)
L2
L2正则比较常用,L1的在微分求导方面比较复杂。 λ就是正则化参数,我们通常使用验证集或交叉验证集来配置这个参数,尝试各种各样的数据,寻找最好的参数, 我们要考虑训练集之间的权衡,把参数设置为较小值,这样可以避免过拟合,所以λ是另外一个需要调整的超级参数
\[\begin{eqnarray}w^{[l]} &:=&w^{[l]}-\alpha\cdot dw^{[l]}\\ &=&w^{[l]}-\alpha\cdot(dw^{[l]}_{before}+\frac{\lambda}{m}w^{[l]})\\ &=&(1-\alpha\frac{\lambda}{m})w^{[l]}-\alpha\cdot dw^{[l]}_{before} \end{eqnarray}\]其中,$(1-\alpha\frac{\lambda}{m})<1$。
当$\lambda$足够大,权重矩阵接近于0的值,相当于减轻了这些隐藏单元对网络的影响,简化网络。 设激活函数为tanh: 当W减少=>z减少=>激活函数趋于线性=>网络趋于线性
l1_regularizer l1_l2_regularizer l2_regularizer
1 | |
必须将正则化损失加到基本损失
1 | |
dropout
每层的神经元,按照一定的概率将其暂时从网络中丢弃 => 每一层都有部分神经元不工作,简化网络。 主要用于计算机视觉。计算视觉中的输入量非常大,输入太多像素,以至于没有足够的数据。因为我们通常没有足够的数据,所以一直存在过拟合。
概率为0.5
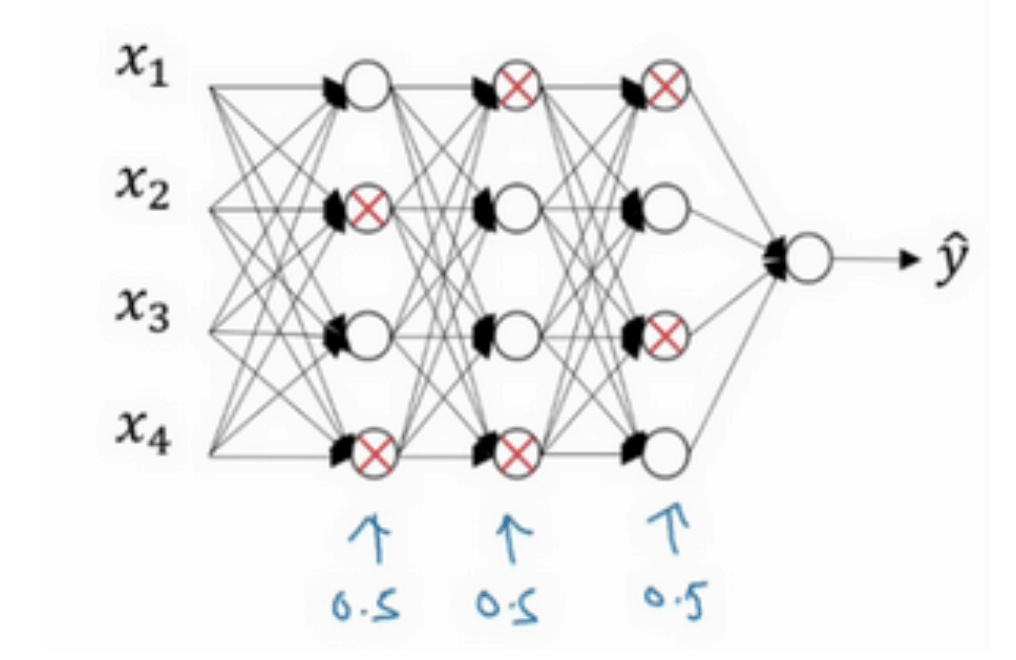
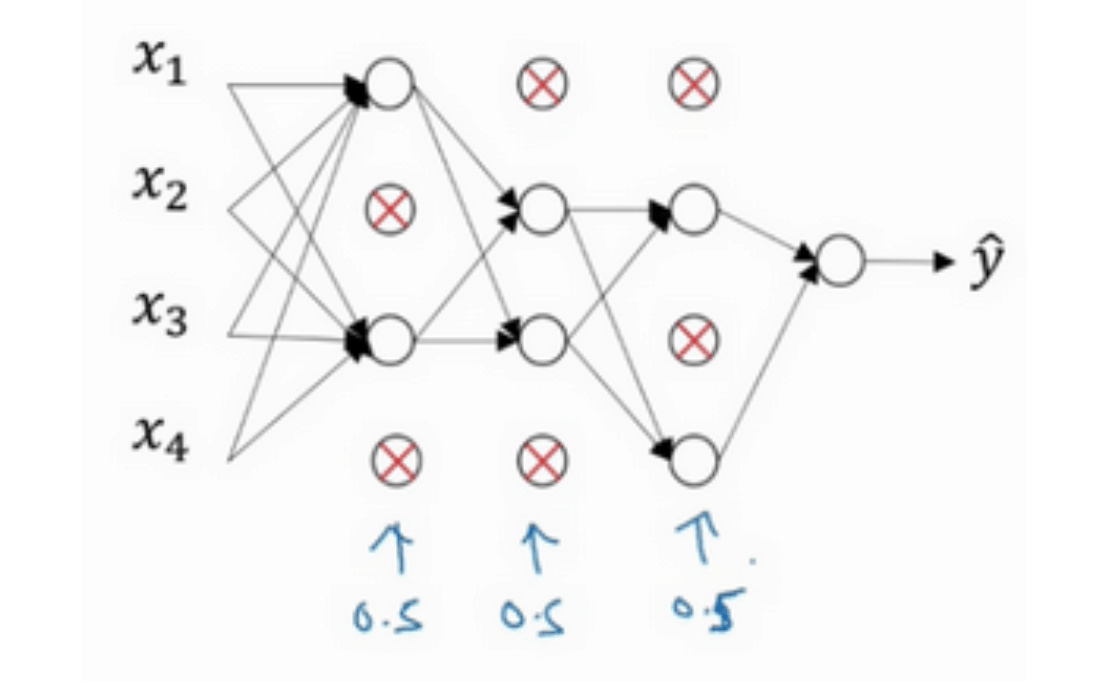
1 | |
1 | |
反向随机失活
units失去(1-keep_prob),Wa也会减少(1-keep_prob),为了不影响z的期望值,所以Wa/keep_prob修正或弥补我们所需的那(1-keep_prob)
训练过程
- 对于m个样本,单次迭代训练时,随机删除掉隐藏层一定数量的神经元; 然后,在删除后的剩下的神经元上正向和反向更新权重w和常数项b; 接着,下一次迭代中,再恢复之前删除的神经元,重新随机删除一定数量的神经元,进行正向和反向更新w和b。不断重复上述过程,直至迭代训练完成。
- 每层的keep_prob可以不同,因为每层units数量不一定相同。或者一些层用dropout,有些不同。
- 值得注意的是,使用dropout训练结束后,在测试和实际应用模型时,不需要进行dropout和随机删减神经元,所有的神经元都在工作。
缺点
代价函数不再被明确。通常会关闭dropout函数,将keep-prob的值设为1,运行代码, 确保J函数单调递减。然后打开dropout函数,希望在dropout过程中,代码并未引入bug。 我觉得你也可以尝试其它方法,虽然我们并没有关于这些方法性能的数据统计,但你可以把它们与dropout方法一起使用。
其他正则化手段
数据扩增
对已有的训练样本进行一些处理来“制造”出更多的样本,称为data augmentation。 例如图片识别问题中,可以对已有的图片进行水平翻转、垂直翻转、任意角度旋转、缩放或扩大等等。 数字识别中,也可以将原有的数字图片进行任意旋转或者扭曲,或者增加一些noise。
early stopping
随着迭代训练次数增加,train set error一般是单调减小的。而dev set error 先减小,之后又增大。发生了过拟合。 选择合适的迭代次数,即early stopping
summary
get min cost function 和 防止overfit 是对立的。early stopping 通过减少训练防止过拟合,这样J不会足够小。 在深度学习中,我们可以同时减小Bias和Variance,构建最佳神经网络模型。early stopping做到同时优化,但可能没有“分而治之”的效果好。
L2 regularization可以实现“分而治之”的效果:迭代训练足够多,减小J,而且也能有效防止过拟合。 而L2 regularization的缺点之一是最优的正则化参数$\lambda$的选择比较复杂。 对这一点来说,early stopping比较简单。总的来说,L2 regularization更加常用一些。
Normalizing input
标准化输入可以提高训练神经网络的速度。如果特征之间取值范围差异过大,只能选择很小的学习因子α,多次迭代,来避免J发生振荡。
使得数据均值为0,方差为1,原始数据减去其均值μ后,再除以其方差$\sigma^2$。注意保证了训练集合测试集的标准化操作一致,用同一个μ和$\sigma^2$,由训练集数据计算得来
\[X:=\frac{X-\mu}{\sigma^2}\]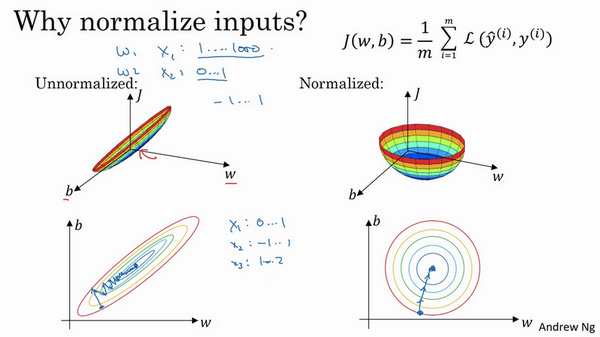 标准化后代价函数优化起来更简单快速。可用较大步长,较小次数迭代。
标准化后代价函数优化起来更简单快速。可用较大步长,较小次数迭代。
梯度消失/梯度爆炸(Vanishing / Exploding gradients)
基于反向传播随机梯度下降来训练深度网络,不同的层学习的速度差异很大,因为学习速率= 激活值*残差,而残差是从上层的残差加权得到的,也与激活函数有关。
极深的网络存在的问题
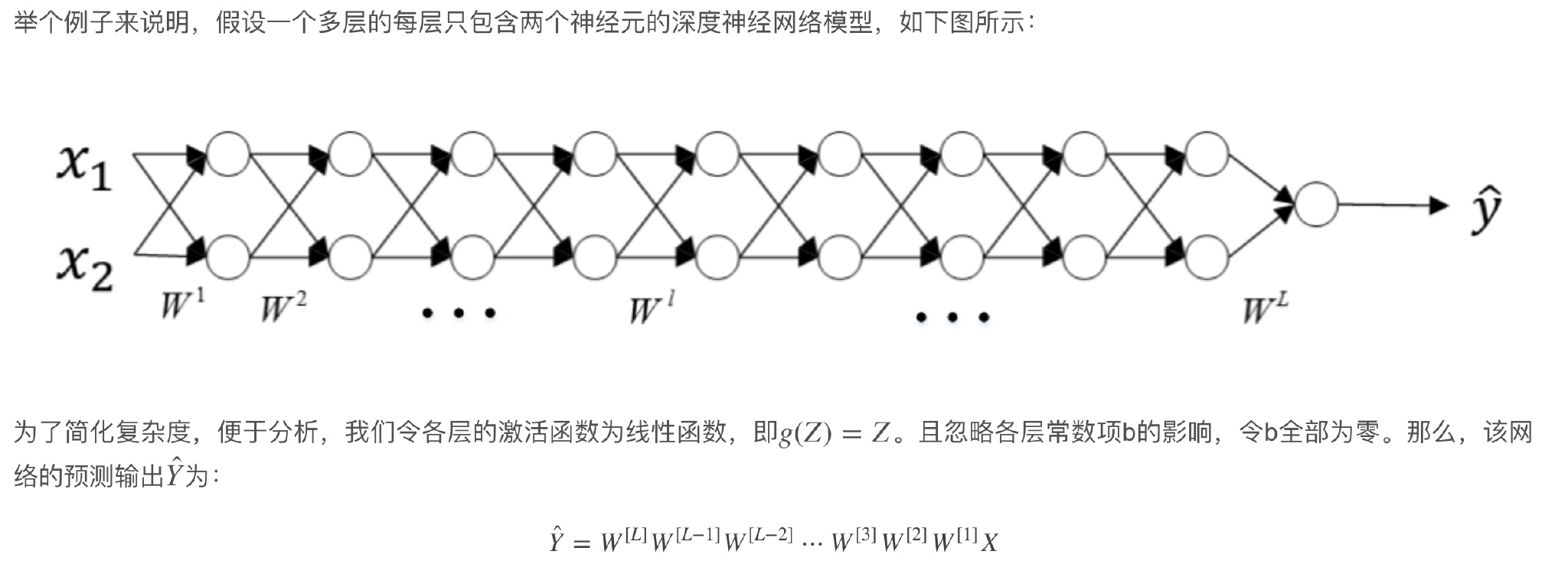
- 各层权重W的元素都稍大于1,1.5,L越大,Ŷ呈指数型增长。我们称之为数值爆炸。
- 各层权重W的元素都稍小于1,0.5,L越大,Ŷ呈指数型减小。我们称之为数值消失。 同样,这种情况也会引起梯度呈现同样的指数型增大或减小的变化。L非常大时,例如L=150,则梯度会非常大或非常小 ,引起每次更新的步进长度过大或者过小,这让训练过程十分困难。
完善w初始化
单个unit
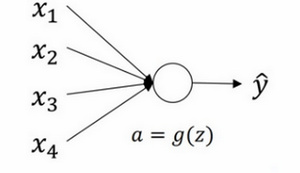
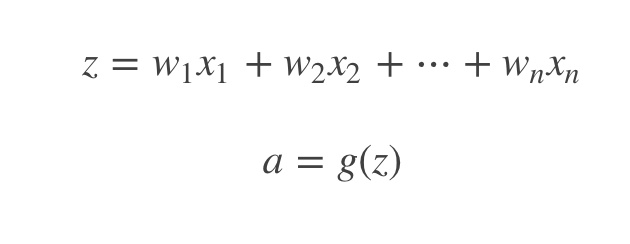 这里忽略了常数项b。为了让z不会过大或者过小,思路是让w与n有关,且n越大,w应该越小才好。
这样能够保证z不会过大。一种方法是在设$Var(w_i)\;=\;\frac1n$,n表示神经元的输入特征数量。
这里忽略了常数项b。为了让z不会过大或者过小,思路是让w与n有关,且n越大,w应该越小才好。
这样能够保证z不会过大。一种方法是在设$Var(w_i)\;=\;\frac1n$,n表示神经元的输入特征数量。
1 | |
tanh,一般选择上面的初始化方法 ReLU,权重w的初始化一般令其方差为$\frac2n$
Xavier and He Initialization



1 | |
默认是 glorot_uniform_initializer 某程度上和xavier_initializer差不多
1 | |
激活函数
Gradient checking
Back Propagation神经网络有一项重要的测试是梯度检查(gradient checking)。 其目的是检查验证反向传播过程中梯度下降算法是否正确。
近似求出梯度值
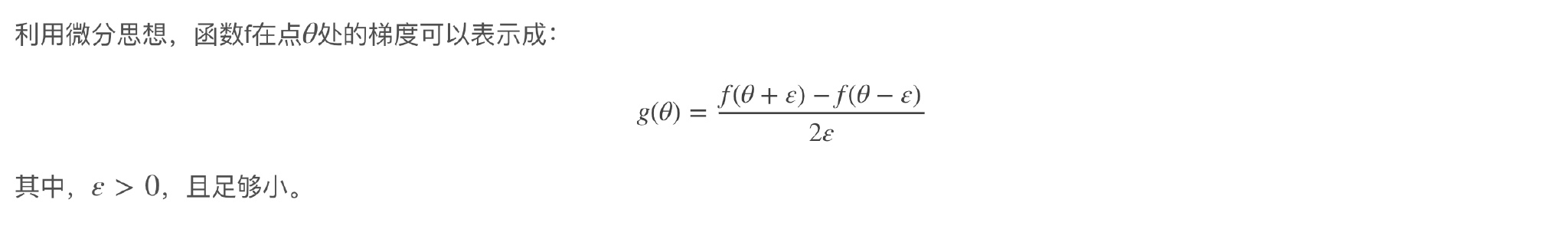
梯度检查首先要做的是分别将$W^{[1]},b^{[1]},\cdots,W^{[L]},b^{[L]}$这些矩阵构造成一维向量, 然后将这些一维向量组合起来构成一个更大的一维向量$\theta$。这样cost function $J(W^{[1]},b^{[1]},\cdots,W^{[L]},b^{[L]})$就可以表示成$J(\theta)$。
然后将反向传播过程通过梯度下降算法得到的$dW^{[1]},db^{[1]},\cdots,dW^{[L]},db^{[L]}$按照一样的顺序构造成一个一维向量$d\theta$。$d\theta$的维度与$\theta$一致。
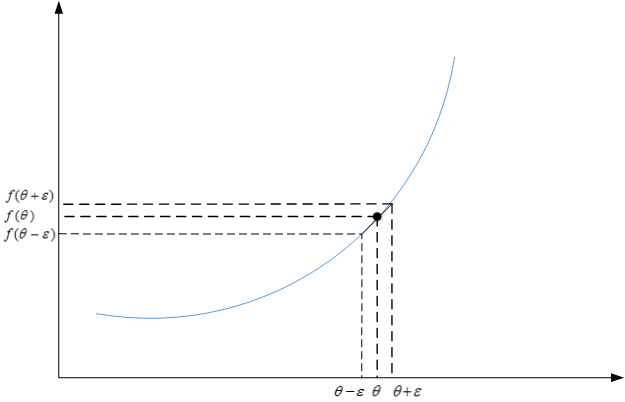
接着利用$J(\theta)$对每个$\theta_i$计算近似梯度,其值与反向传播算法得到的$d\theta_i$相比较,检查是否一致。例如,对于第i个元素,近似梯度为:
\[d\theta_{approx}[i]=\frac{J(\theta_1,\theta_2,\cdots,\theta_i+\varepsilon,\cdots)-J(\theta_1,\theta_2,\cdots,\theta_i-\varepsilon,\cdots)}{2\varepsilon}\]计算完所有$\theta_i$的近似梯度后,可以计算$d\theta_{approx}$与$d\theta$的欧氏(Euclidean)距离来比较二者的相似度。公式如下:
\[\frac{||d\theta_{approx}-d\theta||_2}{||d\theta_{approx}||_2+||d\theta||_2}\]一般来说,如果欧氏距离越小,例如$10^{-7}$,甚至更小,则表明$d\theta_{approx}$与$d\theta$越接近,即反向梯度计算是正确的,没有bugs。 如果欧氏距离较大,例如$10^{-5}$,则表明梯度计算可能出现问题,需要再次检查是否有bugs存在。如果欧氏距离很大,例如$10^{-3}$,甚至更大, 则表明$d\theta_{approx}$与$d\theta$差别很大,梯度下降计算过程有bugs,需要仔细检查。
实施梯度检验的实用技巧和注意
- 不要在训练中使用梯度检验,只用于调试。
- 如果梯度检查出现错误,找到对应出错的梯度,检查其推导是否出现错误。
- 注意不要忽略正则化项,计算近似梯度的时候要包括进去。
- 梯度检查时关闭dropout,检查完毕后再打开dropout。
- 随机初始化时运行梯度检查,经过一些训练后再进行梯度检查(不常用)
Batch Normalization
尽管使用 He初始化和 ELU(或任何 ReLU 变体)可以显著减少训练开始阶段的梯度消失/爆炸问题,但不保证在训练期间问题不会回来。
Batch Normalization不仅可以让调试超参数更加简单,而且可以让神经网络模型更加“健壮”。 也就是说较好模型可接受的超参数范围更大一些,包容性更强,使得更容易去训练一个深度神经网络。 Normalizing input只是对输入进行了处理,Batch Normalization各隐藏层的输入进行标准化处理。
第l层隐藏层的输入就是第l-1层隐藏层的输出$A^{[l-1]}$。对$A^{[l-1]}$进行标准化处理,从原理上来说可以提高$W^{[l]}$和$b^{[l]}$的训练速度和准确度。
这种对各隐藏层的标准化处理就是Batch Normalization。值得注意的是,实际应用中,一般是对$Z^{[l-1]}$进行标准化处理而不是$A^{[l-1]}$,其实差别不是很大。

Normalizing inputs和Batch Normalization有区别的,Normalizing inputs使所有输入的均值为0,方差为1。 而Batch Normalization可使各隐藏层输入的均值和方差为任意值。实际上,从激活函数的角度来说,如果各隐藏层的输入均值在靠近0的区域即处于激活函数的线性区域, 这样不利于训练好的非线性神经网络,得到的模型效果也不会太好。这也解释了为什么需要用γ和β来对zl作进一步处理。

如果实际应用的样本与训练样本分布不同,即发生了covariate shift,则一般是要对模型重新进行训练的。深度神经网络中,covariate shift会导致模型预测效果变差。 而Batch Norm的作用恰恰是减小covariate shift的影响,让模型变得更加健壮,鲁棒性更强。Batch Norm减少了各层$W^{[l]}、B^{[l]}$之间的耦合性,让各层更加独立, 实现自我训练学习的效果。也就是说,如果输入发生covariate shift,那么因为Batch Norm的作用, 对个隐藏层输出$Z^{[l]}$进行均值和方差的归一化处理,$W^{[l]}和B^{[l]}$更加稳定,使得原来的模型也有不错的表现。
从另一个方面来说,Batch Norm也起到轻微的正则化(regularization)效果。具体表现在:
- 每个mini-batch都进行均值为0,方差为1的归一化操作
- 每个mini-batch中,对各个隐藏层的$Z^{[l]}$添加了随机噪声,效果类似于Dropout
- mini-batch越小,正则化效果越明显 但是,Batch Norm的正则化效果比较微弱,正则化也不是Batch Norm的主要功能。
Softmax 多分类
目前我们介绍的都是二分类问题,神经网络输出层只有一个神经元, 表示预测输出$\hat y$是正类的概率$P(y=1|x),$\hat y>0.5$则判断为正类,$\hat y<0.5$则判断为负类。
对于多分类问题,用C表示种类个数,神经网络中输出层就有C个神经元,即$Cn^{[L]}=C$。 其中,每个神经元的输出依次对应属于该类的概率,即$P(y=c|x)$。为了处理多分类问题,我们一般使用Softmax回归模型。
Softmax回归模型输出层的激活函数
Softmax回归模型输出层的激活函数如下所示:
\[z^{[L]}=W^{[L]}a^{[L-1]}+b^{[L]}\] \[a^{[L]}_i=\frac{e^{z^{[L]}_i}}{\sum_{i=1}^Ce^{z^{[L]}_i}}\]输出层每个神经元的输出$a^{[L]}_i$对应属于该类的概率,满足:
\[\sum_{i=1}^Ca^{[L]}_i=1\]所有的$a^{[L]}_i,即\hat y$,维度为(C, 1)。