Mini-batch gradient descent
Batch Gradient Descent
所有m个样本,m很大,每次迭代都要对所有样本进行进行求和运算和矩阵运算,训练速度往往会很慢。
Mini-batch Gradient Descent
把m个训练样本分成若干个子集,称为mini-batches,这样每个子集包含的数据量就小了,每次在单一子集上进行神经网络训练,速度就会大大提高。 先将总的训练样本分成T个子集(mini-batches),然后对每个mini-batch进行神经网络训练,包括Forward Propagation,Compute Cost Function,Backward Propagation,循环至T个mini-batch都训练完毕。
1 | |
经过T次循环之后,所有m个训练样本都进行了梯度下降计算。这个过程,我们称之为经历了一个epoch。
对于Batch Gradient Descent而言,一个epoch只进行一次梯度下降算法;而Mini-Batches Gradient Descent,一个epoch会进行T次梯度下降算法。
mini-batch上迭代训练,其cost不是单调下降,而是受类似noise的影响,出现振荡。但整体的趋势是下降的,最终也能得到较低的cost值。
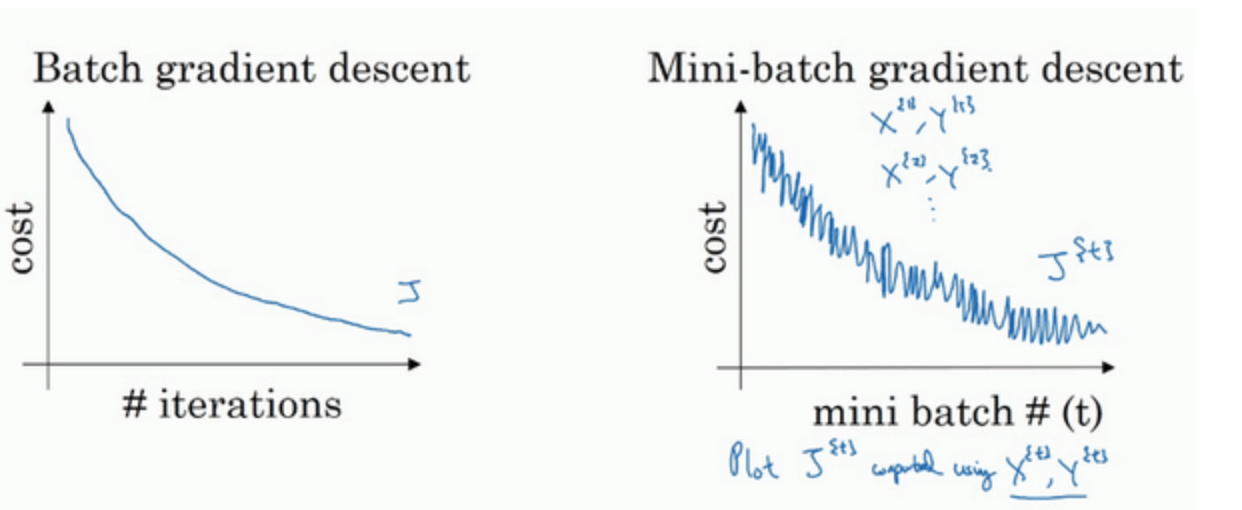 振荡的原因是不同的mini-batch之间是有差异的
振荡的原因是不同的mini-batch之间是有差异的
- mini-batch size=m,即为Batch gradient descent
-
mini-batch size=1,即为Stachastic gradient descent
- Batch gradient descent会比较平稳地接近全局最小值,但是因为使用了所有m个样本,每次前进的速度有些慢。
- Stachastic gradient descent每次前进速度很快,但是路线曲折,有较大的振荡,最终会在最小值附近来回波动,难以真正达到最小值处。 而且在数值处理上就不能使用向量化的方法来提高运算速度。
- Mini-batch gradient descent每次前进速度较快,且振荡较小,基本能接近全局最小值。既能使用向量化优化算法,又能叫快速地找到最小值。
m不太大时,例如$m\leq2000$,建议直接使用Batch gradient descent。 如果总体样本数量m很大时,建议将样本分成许多mini-batches。推荐常用的mini-batch size为64,128,256,512。 这些都是2的幂。之所以这样设置的原因是计算机存储数据一般是2的幂,这样设置可以提高运算速度。
EVA
指数加权平均(Exponentially weighted averages),通过移动平均(moving average)的方法来对每天气温进行平滑处理。 根据之前的推导公式,其一般形式为:
\[V_t=\beta V_{t-1}+(1-\beta)\theta_t\]$\beta$值决定了指数加权平均的天数,近似表示为:
\[\frac{1}{1-\beta}\]例如,当$\beta=0.9$,则$\frac{1}{1-\beta}=10$,表示将前10天进行指数加权平均。$\beta$值越大,则指数加权平均的天数越多,平均后的趋势线就越平缓,但是同时也会向右平移。
Gradient descent with momentum
动量梯度下降算法,其速度要比传统的梯度下降算法快很多。每次训练时,对梯度进行指数加权平均处理,然后用得到的梯度值更新权重W和常数项b

RMSprop
 加快了W方向的速度,减小了b方向的速度,减小振荡,实现快速梯度下降。因此,表达式中Sb较大,而SW较小。
加快了W方向的速度,减小了b方向的速度,减小振荡,实现快速梯度下降。因此,表达式中Sb较大,而SW较小。
Adam
Adam(Adaptive Moment Estimation)算法结合了动量梯度下降算法和RMSprop算法。

Learning rate decay
随着迭代次数增加,学习因子α逐渐减小,有效提高神经网络训练速度 Learning rate decay中对$\alpha$可由下列公式得到:
\[\alpha=\frac{1}{1+decay\_rate*epoch}\alpha_0\]其中,deacy_rate是参数(可调),epoch是训练完所有样本的次数。随着epoch增加,$\alpha$会不断变小。
局部最优解(local optima)
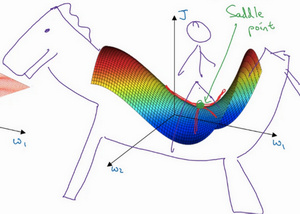
在使用梯度下降算法不断减小cost function时,可能会得到局部最优解(local optima)而不是全局最优解(global optima)。 之前我们对局部最优解的理解是形如碗状的凹槽,如下图左边所示。但是在神经网络中,local optima的概念发生了变化。 准确地来说,大部分梯度为零的“最优点”并不是这些凹槽处,而是形如右边所示的马鞍状,称为saddle point。
类似马鞍状的plateaus会降低神经网络学习速度。Plateaus是梯度接近于零的平缓区域,如下图所示。
在plateaus上梯度很小,前进缓慢,到达saddle point需要很长时间。
到达saddle point后,由于随机扰动,梯度一般能够沿着图中绿色箭头,离开saddle point,继续前进,只是在plateaus上花费了太多时间。
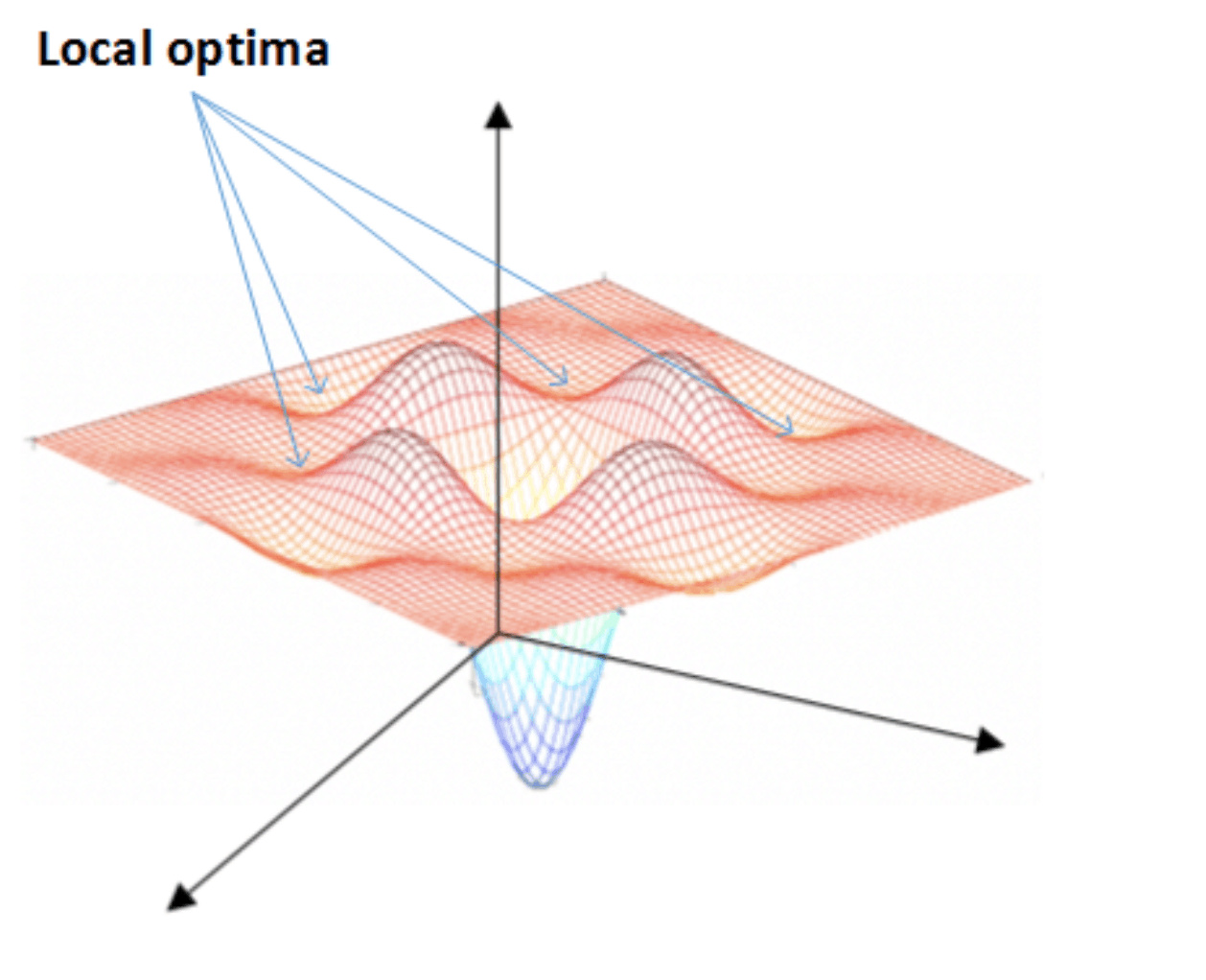
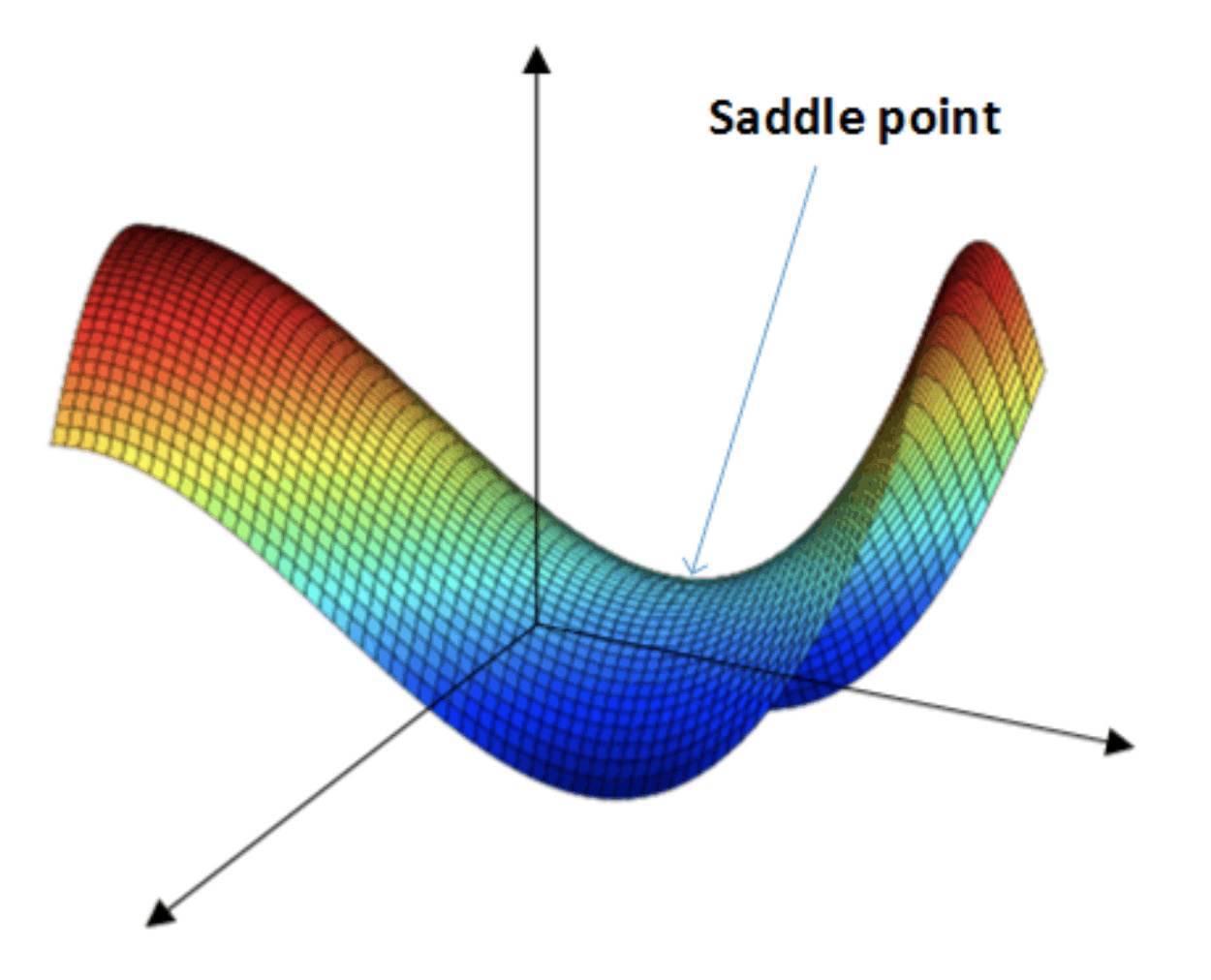
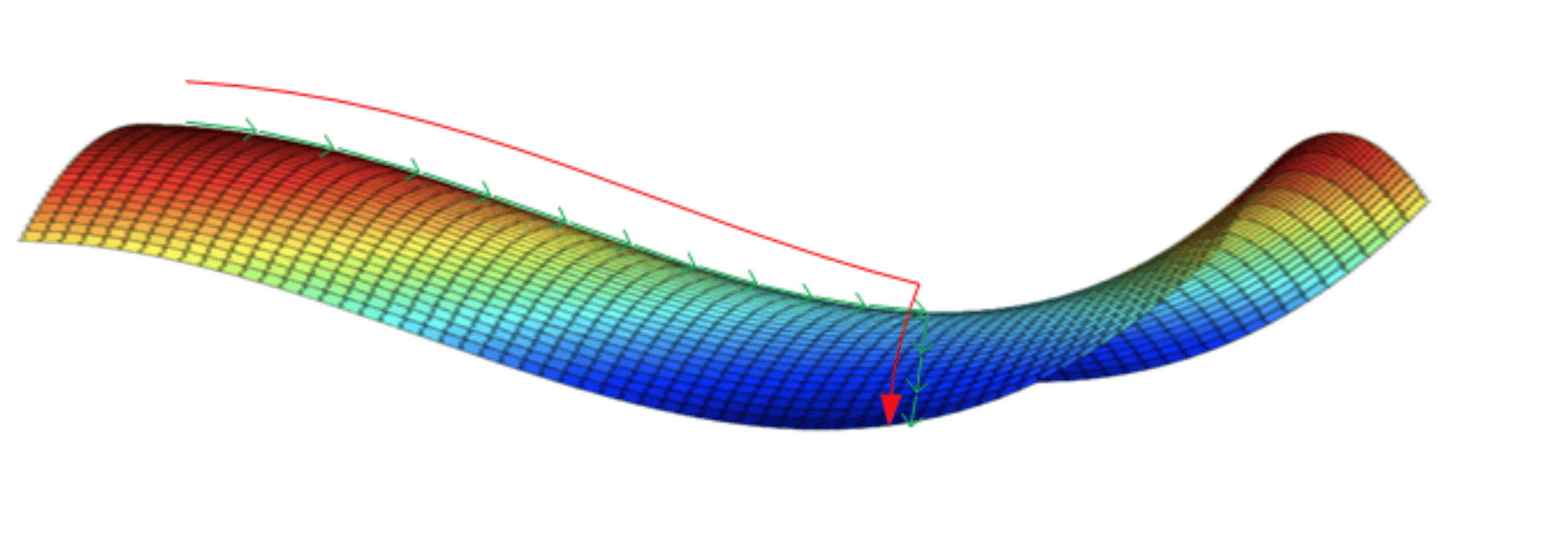
- 只要选择合理的强大的神经网络,一般不太可能陷入local optima
- Plateaus可能会使梯度下降变慢,降低学习速度
动量梯度下降,RMSprop,Adam算法都能有效解决plateaus下降过慢的问题,大大提高神经网络的学习速度。