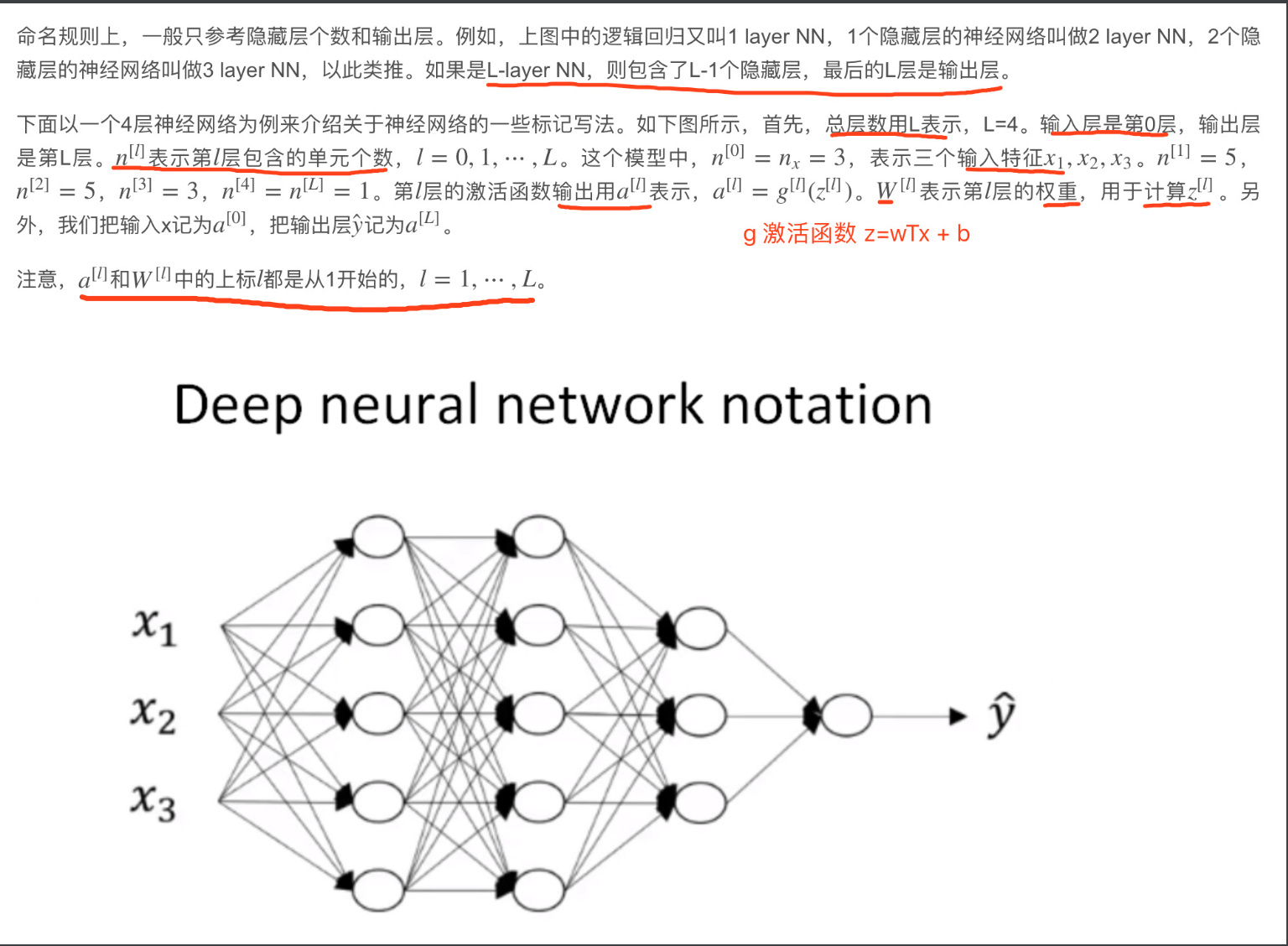
结构
L-layer NN,则包含了L-1个隐藏层,最后的L层是输出层
传播
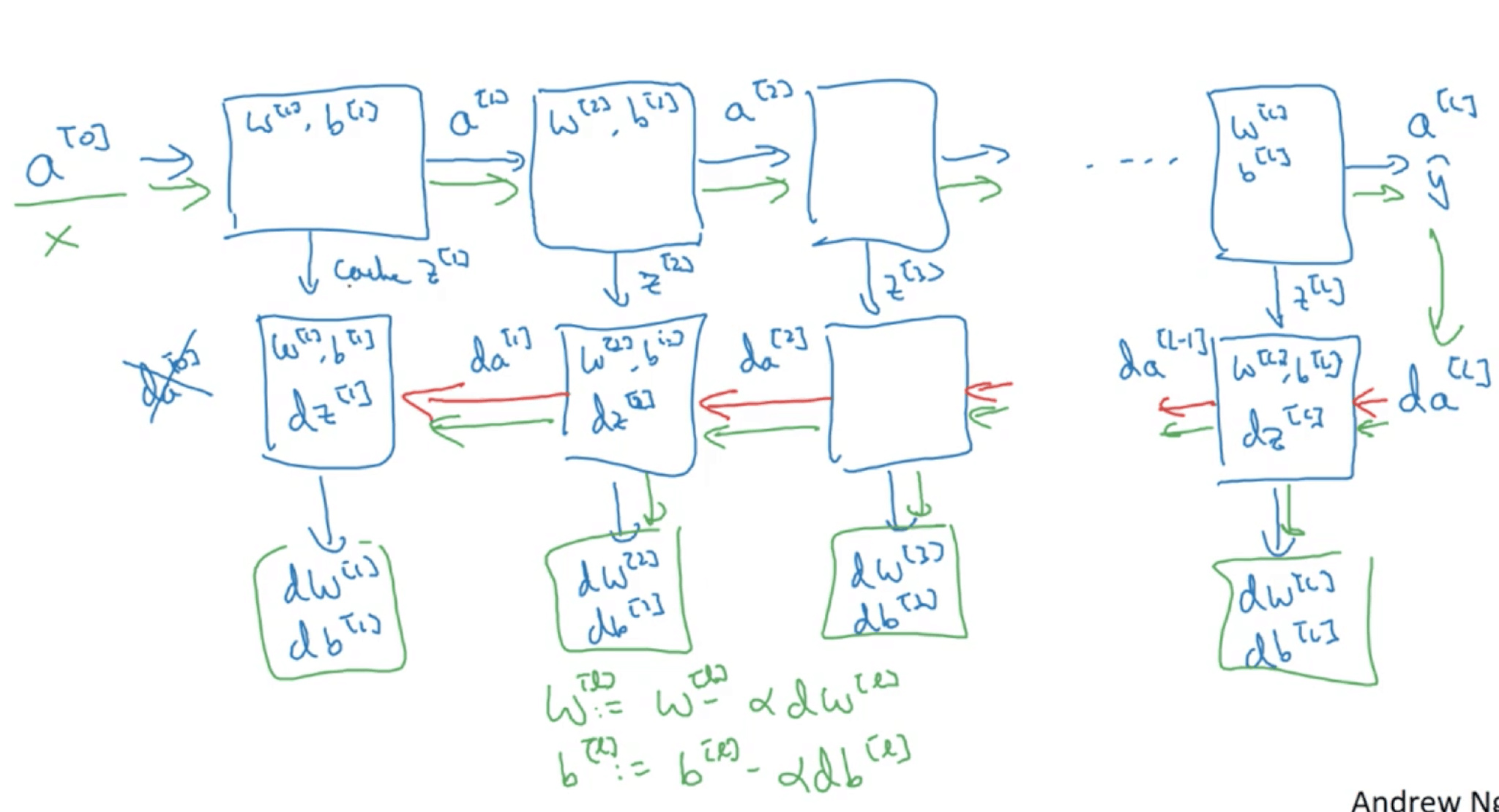
正向传播过程
$A^{\lbrack0\rbrack}$ 就是X。 只使用一次for 循环 从后往前层数l 1到L

反向传播

矩阵维度
做深度神经网络的反向传播时,一定要确认所有的矩阵维数是前后一致的,可以大大提高代码通过率


why deep
不需要很大的神经网络,但是得有有深度。
网络描述
- 大小 隐藏单元的数量
- 深度 隐藏层数量
原因
- 随着深度增加,神经元提取的特征从简单到复杂。特征复杂度与神经网络层数成正相关。特征越来越复杂,功能也越来越强大。
- 减少神经元个数,从而减少计算量。使用浅层网络达到深层网络效果需要指数增长隐藏单元的数量。
对实际问题进行建模时,尽量先选择层数少的神经网络模型,对于比较复杂的问题,再使用较深的神经网络模型
Parameters vs Hyperparameters
神经网络中的参数就是我们熟悉的$W^{[l]}和b^{[l]}$。 而超参数则是例如学习速率$\alpha$,训练迭代次数N,神经网络层数L,各层神经元个数$n^{[l]}$,激活函数g(z)等。 之所以叫做超参数的原因是它们决定了参数$W^{[l]}和b^{[l]}$的值。
how 最优参数
经验 or 不停的尝试不同的值测试 选择超参数一定范围内的值,分别代入神经网络进行训练, 测试cost function随着迭代次数增加的变化,根据结果选择cost function最小时对应的超参数值。 这类似于validation的方法
即使用了很久的模型,可能你在做网络广告应用,在你开发途中,很有可能学习率的最优数值或是其他超参数的最优值是会变的, 所以即使你每天都在用当前最优的参数调试你的系统,你还是会发现,最优值过一年就会变化, 因为电脑的基础设施,CPU或是GPU可能会变化很大。所以有一条经验规律可能每几个月就会变。 如果你所解决的问题需要很多年时间,只要经常试试不同的超参数, 勤于检验结果,看看有没有更好的超参数数值,相信你慢慢会得到设定超参数的直觉,知道你的问题最好用什么数值。