区分一维数组和 行变量 列变量
 一维数组 行为 不总与行变量or列变量一直,造成不必要的bug。总是使用nx1维矩阵(基本上是列向量),
或者1xn维矩阵(基本上是行向量),这样你可以减少很多assert语句来节省核矩阵和数组的维数的时间。
另外,为了确保你的矩阵或向量所需要的维数时,不要羞于reshape操作。
一维数组 行为 不总与行变量or列变量一直,造成不必要的bug。总是使用nx1维矩阵(基本上是列向量),
或者1xn维矩阵(基本上是行向量),这样你可以减少很多assert语句来节省核矩阵和数组的维数的时间。
另外,为了确保你的矩阵或向量所需要的维数时,不要羞于reshape操作。
1 | |
sklearn
train_test_split
1 | |
sklearn
1 | |
clean
处理文本和类别属性 文本标签转换为数字
1 | |
使用类LabelBinarizer,我们可以用一步执行这两个转换(从文本分类到整数分类LabelEncoder,再从整数分类到独热向量OneHotEncoder)
1 | |
1 | |
Pipeline
Sequentially apply a list of transforms and a final estimator. Intermediate steps of the pipeline must be ‘transforms’, that is, they must implement fit and transform methods. The final estimator only needs to implement fit.
当你调用流水线的fit()方法,就会对所有转换器顺序调用fit_transform()方法, 将每次调用的输出作为参数传递给下一个调用,一直到最后一个估计器,它只执行fit()方法。
1 | |
Pipeline 合并 并行执行,等待输出,然后将输出合并起来,并返回结果
1 | |
评估
1 | |
1 | |
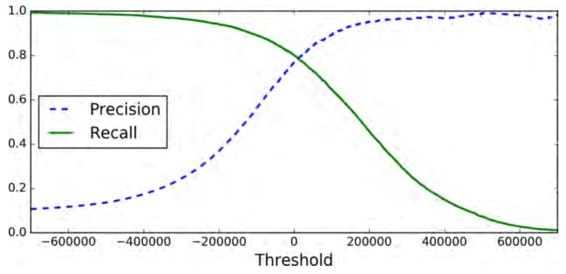
save/load
1 | |
交叉验证
1 | |
超参数微调
GridSearchCV
1 | |
网格搜索会探索12 + 6 = 18种RandomForestRegressor的超参数组合,会训练每个模型五次(因为用的是五折交叉验证)。 换句话说,训练总共有18 × 5 = 90轮!K 折将要花费大量时间,完成后,你就能获得参数的最佳组合.
1 | |
随机搜索
当超参数的搜索空间很大时,最好使用RandomizedSearchCV
通过选择每个超参数的一个随机值的特定数量的随机组合。这个方法有两个优点:
- 如果你让随机搜索运行,比如 1000 次,它会探索每个超参数的 1000 个不同的值(而不是像网格搜索那样,只搜索每个超参数的几个值)。
- 你可以方便地通过设定搜索次数,控制超参数搜索的计算量。
feature select
1 | |
学习曲线
1 | |
pandas
summary
pd compare sql pd index slice etc
plot
1 | |
关系
1 | |
数据清洗
用DataFrame的dropna(),drop(),和fillna()方法,可以方便地实现
1 | |
scipy
1 | |
应用
1 | |
1 | |
1 | |
1 | |