结构
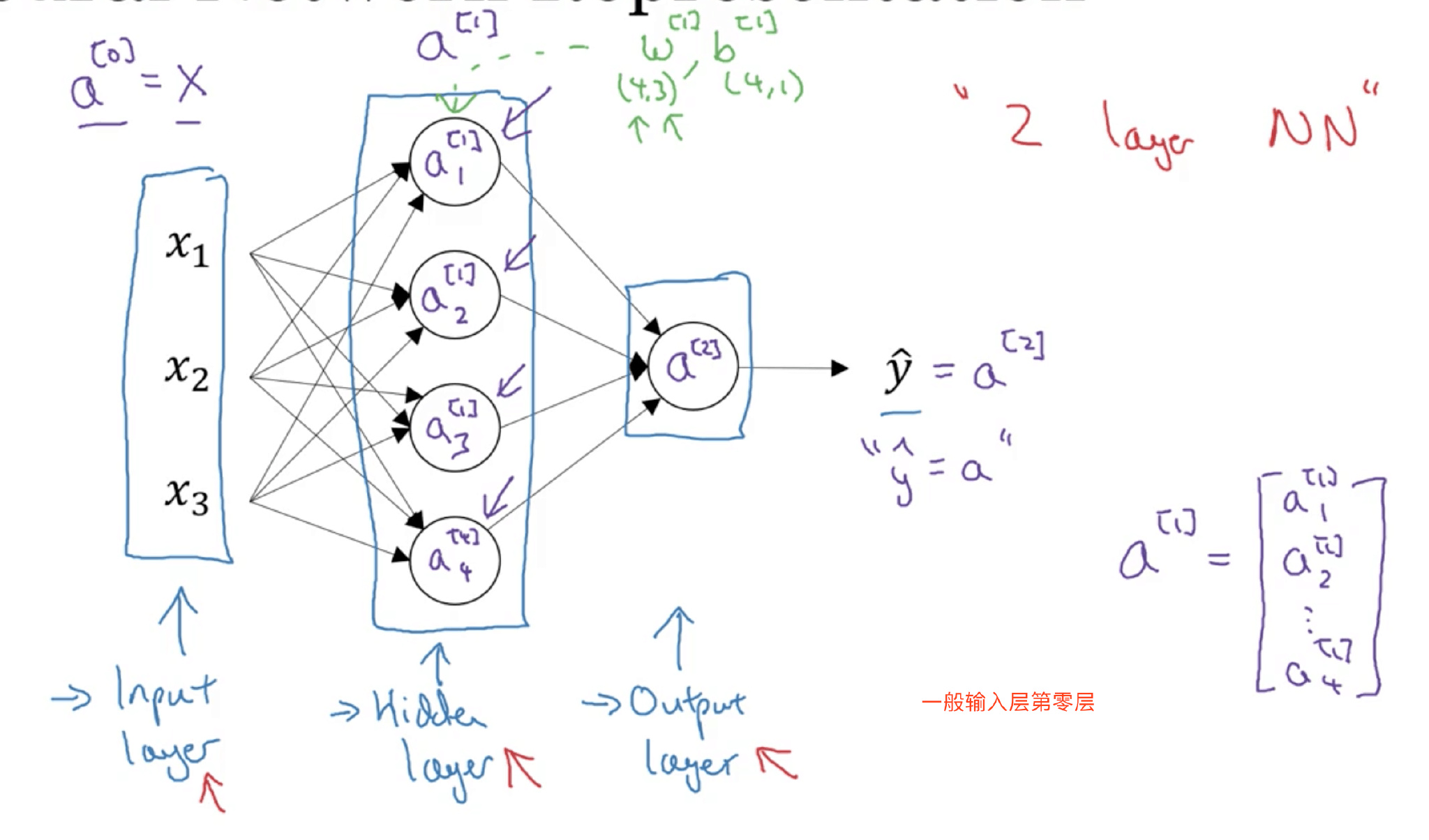 结构上,从左到右,可以分成三层:输入层(Input layer),隐藏层(Hidden layer)和输出层(Output layer)。
输入层和输出层,顾名思义,对应着训练样本的输入和输出,很好理解。隐藏层是抽象的非线性的中间层,这也是其被命名为隐藏层的原因。
结构上,从左到右,可以分成三层:输入层(Input layer),隐藏层(Hidden layer)和输出层(Output layer)。
输入层和输出层,顾名思义,对应着训练样本的输入和输出,很好理解。隐藏层是抽象的非线性的中间层,这也是其被命名为隐藏层的原因。
之所以叫两层神经网络是因为,通常我们只会计算隐藏层输出和输出层的输出,输入层是不用计算的。这也是我们把输入层层数上标记为0的原因
计算
正向传播
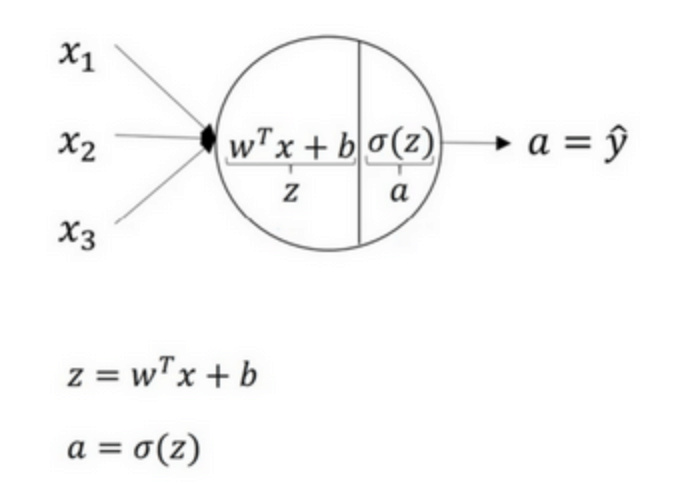
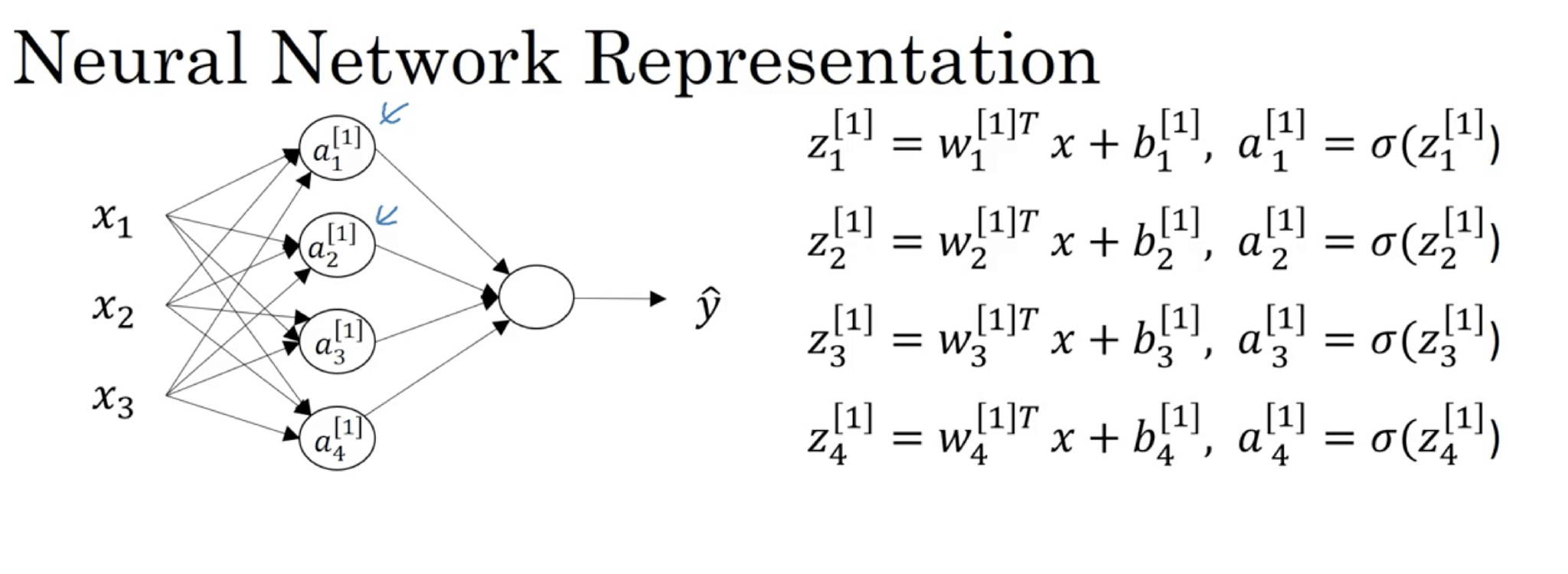
激活函数 Activation functions
why Activation functions
用来加入非线性因素的,因为线性模型的表达能力不够,解决线性模型所不能解决的问题。
假设所有的激活函数都是线性的,使用神经网络与直接使用线性模型的效果并没有什么两样。神经网络就没有任何作用。
如果所有的隐藏层全部使用线性激活函数,只有输出层使用非线性激活函数,那么整个神经网络的结构就类似于一个简单的逻辑回归模型,而失去了神经网络模型本身的优势和价值。
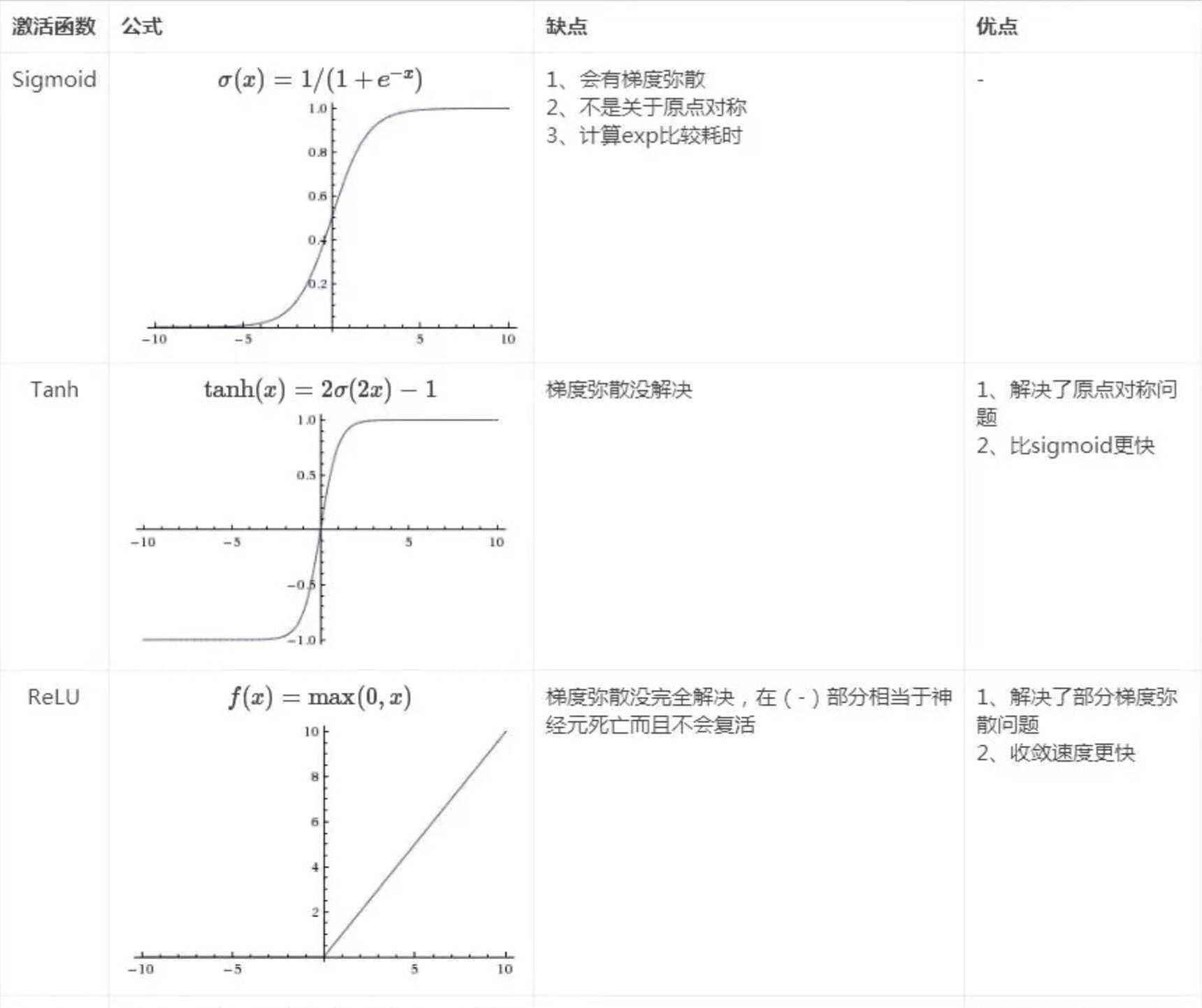
Activation functions 种类对比
神经网络隐藏层和输出层都需要激活函数
\[ReLU(X) = max(0,x)\] \[Leaky ReLu(X) = max(0.01x,x)\]sigmoid不多用 梯度爆炸/消失 涉及除法和指数计算量大
\[sigmoid(x) = \frac1{1+e^{-x}}\] \[tanh(x) = \frac{exp(x)-\;exp(-x)}{exp(x)+exp(-x)}\]why tanh better than sigmoid
tanh函数在所有场合都优于sigmoid函数 二分类的问题上,隐藏层使用tanh激活函数,输出层使用sigmoid函数
因为tanh函数的取值范围在[-1,+1]之间,隐藏层的输出被限定在[-1,+1]之间,可以看成是在0值附近分布,均值为0。 这样从隐藏层到输出层,数据起到了归一化(均值为0)的效果。 因此,隐藏层的激活函数,tanh比sigmoid更好一些。而对于输出层的激活函数, 因为二分类问题的输出取值为[0,+1],所以一般会选择sigmoid作为激活函数。
sigmoid函数和tanh函数两者共同的缺点
在x特别大或者特别小 即 |x|很大 的情况下, 激活函数的斜率(梯度)很小,最后就会接近于0, 导致降低梯度下降的速度
所以输入层使|x|尽可能限定在零值附近,从而提高梯度下降算法运算速度 使用 Normalizing input
ReLU激活函数
sigmoid函数和tanh函数的这个缺陷 ReLU激活函数在z大于零时梯度始终为1;在z小于零时梯度始终为0;z等于零时的梯度可以当成1也可以当成0,实际应用中并不影响。 对于隐藏层,选择ReLU作为激活函数能够保证z大于零时梯度始终为1,从而提高神经网络梯度下降算法运算速度。但当z小于零时,存在梯度为0的缺点, 实际应用中,这个缺点影响不是很大。
为了弥补这个缺点,出现了Leaky ReLU激活函数,能够保证z小于零是梯度不为0。
summary
- 实践中隐藏层使用ReLU作为激活函数,比其他学习速度快。
- sigmoid和tanh函数的导数在正负饱和区的梯度都会接近于0,这会造成梯度弥散, 而Relu和Leaky ReLu函数大于0部分都为常数,不会产生梯度弥散现象。 (同时应该注意到的是,Relu进入负半区的时候,梯度为0,神经元此时不会训练,产生所谓的稀疏性,而Leaky ReLu不会有这问题)
-
在ReLu的梯度一半都是0,但是,有足够的隐藏层使得z值大于0,所以对大多数的训练数据来说学习过程仍然可以很快。
- sigmoid激活函数:除了输出层是一个二分类问题基本不会用它。
- tanh激活函数:tanh是非常优秀的,几乎适合所有场合。
- ReLu激活函数:最常用的默认函数,,如果不确定用哪个激活函数,就使用ReLu
图像对比

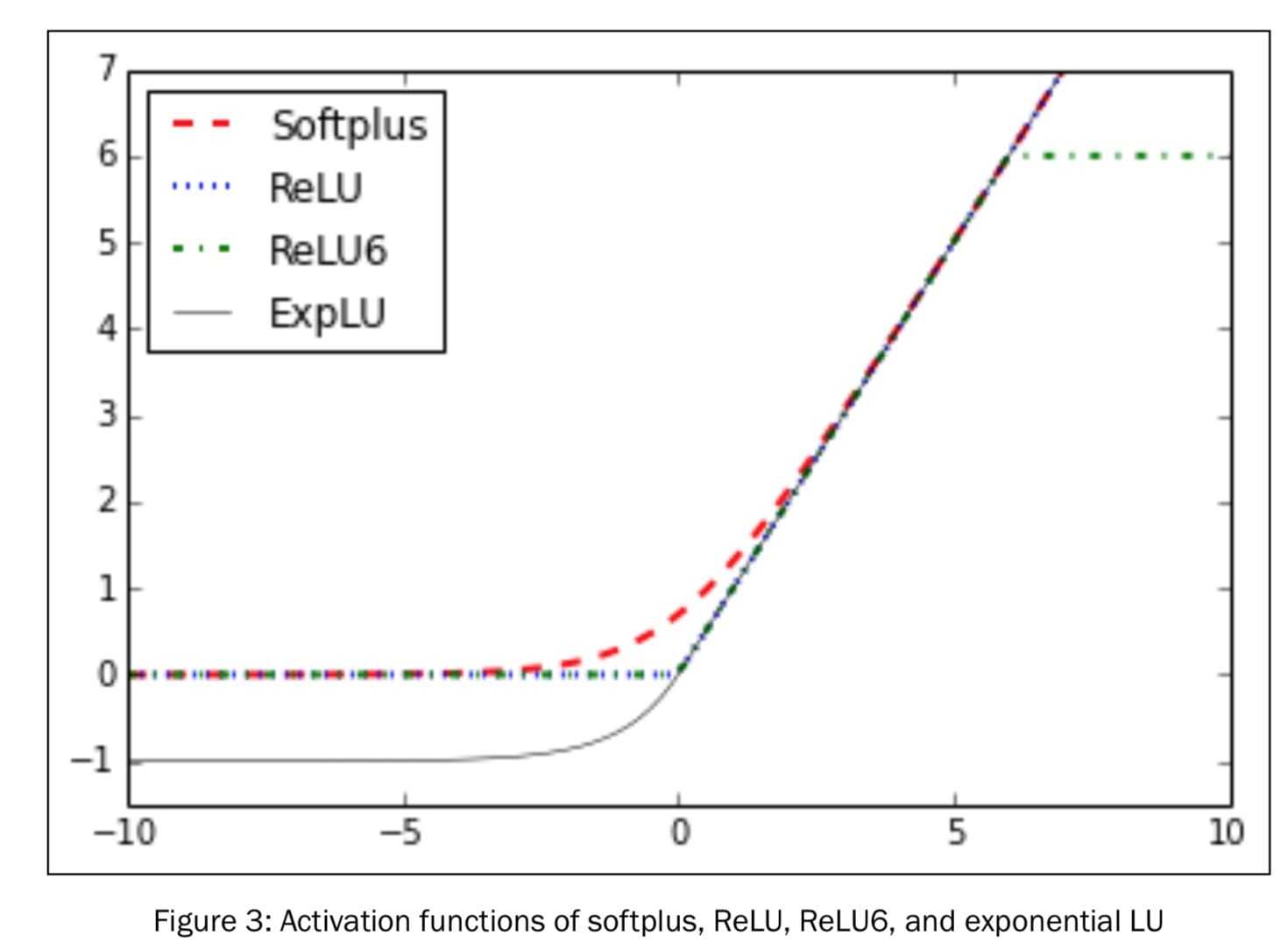
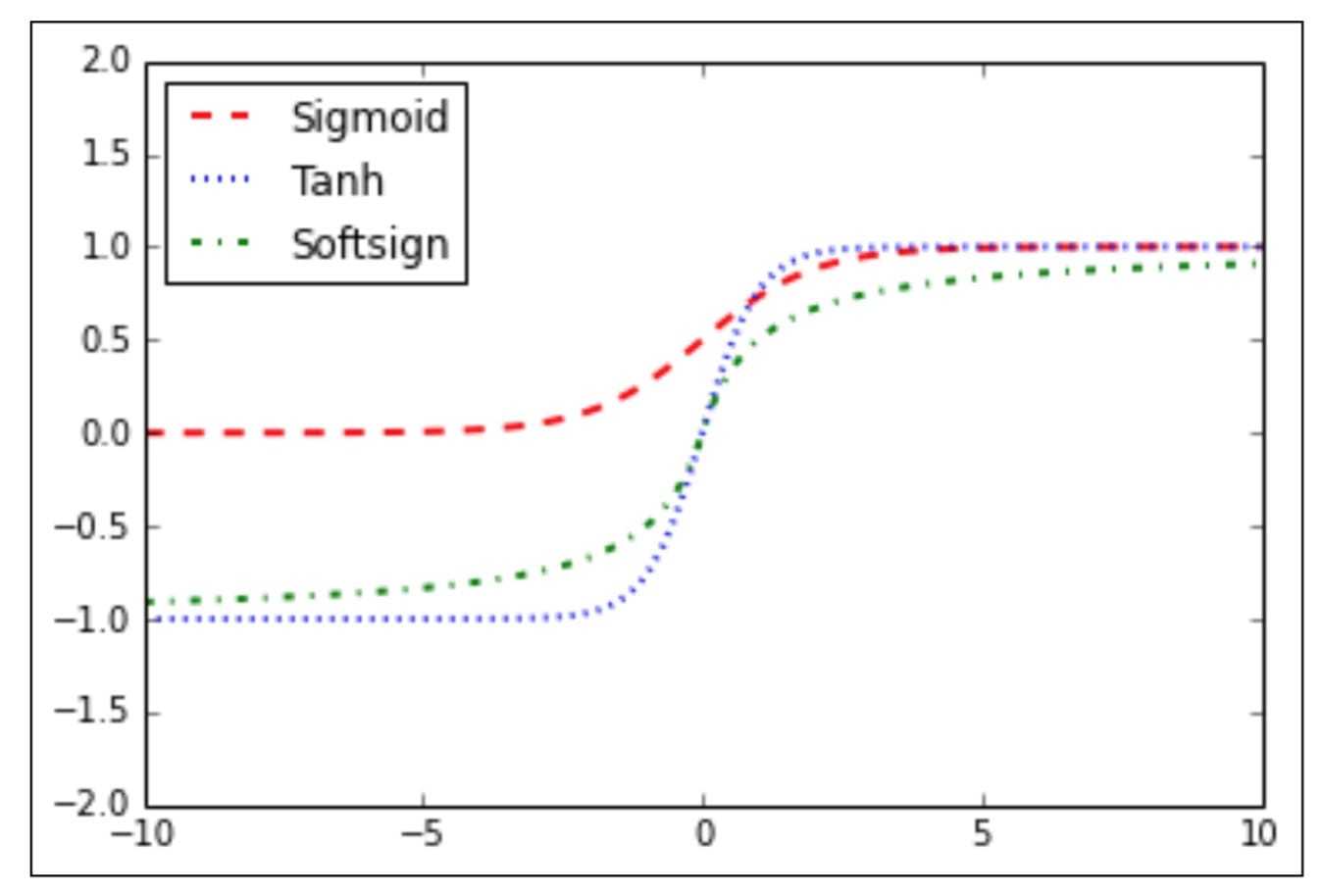
激活函数导数

权重初始化
why not all 0
权重每次迭代更新都会得到完全相同的结果,都是相等,这样隐藏层设置多个神经元就没有任何意义了。 参数b可以全部初始化为零,并不会影响神经网络训练效果
随机尽量小
把这种权重W全部初始化为零带来的问题称为symmetry breaking problem。 解决方法也很简单,就是将W进行随机初始化(b可初始化为零)
1 | |
乘以0.01的目的是尽量使得权重W初始化比较小的值,因为如果使用sigmoidortanh函数作为激活函数的话, W比较小,得到的|x|也比较小(靠近零点),而零点区域的梯度比较大, 这样能大大提高梯度下降算法的更新速度,尽快找到全局最优解。如果W较大,得到的|x|也比较大,附近曲线平缓,梯度较小,训练过程会慢很多。
如果激活函数是ReLU或者Leaky ReLU函数,则不需要考虑这个问题。但是,如果输出层是sigmoid函数,则对应的权重W最好初始化到比较小的值。