OpenEBS
OpenEBS 管理每个 Kubernetes 节点上可用的存储,并使用该存储为有状态工作负载提供本地或分布式(也称为复制)持久卷。
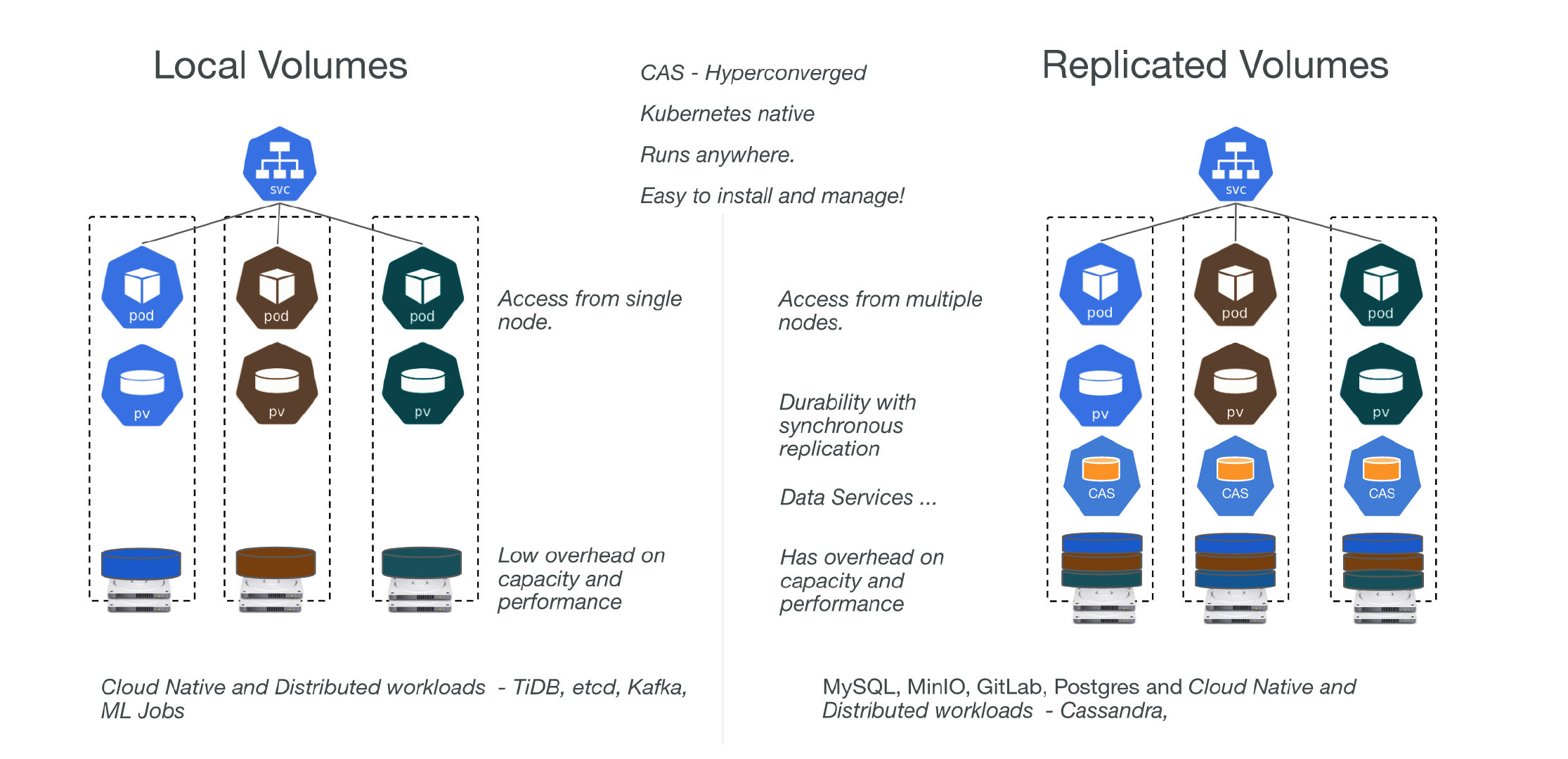
- local
- OpenEBS 可以使用原始块设备或分区,或使用Hostpath上的子目录,或使用 LVM、ZFS 或稀疏文件来创建PV。
- 本地卷直接安装到 Stateful Pod 中,数据路径中没有来自 OpenEBS 的任何额外开销,从而减少了延迟。
- OpenEBS 为本地卷提供了额外的工具,用于监控、备份/恢复、灾难恢复、ZFS 或 LVM 支持的快照、基于容量的调度等。
- 默认目录/var/openebs/local
- Distributed (aka Replicated) Volumes
- OpenEBS 使用其引擎之一(Mayastor、cStor 或 Jiva)为每个分布式持久卷创建微服务。
- Stateful Pod 将数据写入 OpenEBS 引擎,这些引擎将数据同步复制到集群中的多个节点。OpenEBS 引擎本身部署为 pod,由 Kubernetes 编排。当运行有状态 pod 的节点发生故障时,该 pod 将被重新调度到集群中的另一个节点,OpenEBS 使用其他节点上的可用数据副本提供对数据的访问。
- Stateful Pod 使用 iSCSI(cStor 和 Jiva)或 NVMeoF(Mayastor)连接到 OpenEBS 分布式持久卷。
- OpenEBS cStor 和 Jiva 专注于存储的易用性和耐用性。这些引擎分别使用定制版本的 ZFS 和 Longhorn 技术将数据写入存储。
- OpenEBS Mayastor 是最新的引擎,以耐用性和性能为设计目标而开发;OpenEBS Mayastor 有效地管理计算(hugepages、内核)和存储(NVMe 驱动器)以提供快速的分布式块存储。
OpenEBS 贡献者更喜欢将分布式块存储卷称为复制卷,以避免与传统的分布式块存储混淆,原因如下:
- 分布式块存储倾向于将卷的数据块分片到集群中的多个节点上。复制卷将卷的所有数据块保存在节点上,并且为了持久性将整个数据复制到集群中的其他节点。
- 在访问卷数据时,分布式块存储依赖于元数据哈希算法来定位块所在的节点,而复制卷可以从任何持久保存数据的节点(也称为副本节点)访问数据。
- 与传统的分布式块存储相比,复制卷的爆炸半径更小。
- 复制卷专为云原生有状态工作负载而设计,这些工作负载需要大量容量的卷,这些容量通常可以从单个节点提供服务,而不是数据在集群中的多个节点之间分片的单个大卷。
HostPath
由于 Local Volume 只能从单个节点访问,因此本地卷受底层节点可用性的影响,并不适合所有应用程序。如果一个节点变得不健康,那么本地卷也将变得不可访问,使用它的 Pod 将无法运行。使用本地卷的应用程序必须能够容忍这种可用性降低以及潜在的数据丢失,具体取决于底层磁盘的耐用性特征。
cStor
cStor 是通过 OpenEBS 为工作负载提供额外弹性的推荐方式,并且是仅次于 LocalPV 的第二大部署最广泛的存储引擎。cStor 的主要功能是以云原生方式使用底层磁盘或云卷为 iSCSI 块存储提供服务。cStor 是一个非常轻量且功能丰富的存储引擎。它提供企业级功能,例如同步数据复制、快照、克隆、数据自动精简配置、数据的高弹性、数据一致性以及按需增加容量或性能。
当有状态应用程序希望存储提供数据的高可用性时,cStor 被配置为具有 3 个副本,其中数据同步写入所有三个副本。cStor 目标正在将数据复制到 Node1 (R1)、Node3(R2) 和 Node4(R3)。在将响应发送回应用程序之前,数据被写入三个副本。需要注意的是,副本 R1、R2 和 R3 是目标写入的相同数据的副本,数据不会跨副本或跨节点条带化。(每个节点都有完整数据)

对于statefulset,通常使用单个副本配置 cStor。这是一个可能首选使用 LocalPV 的用例。
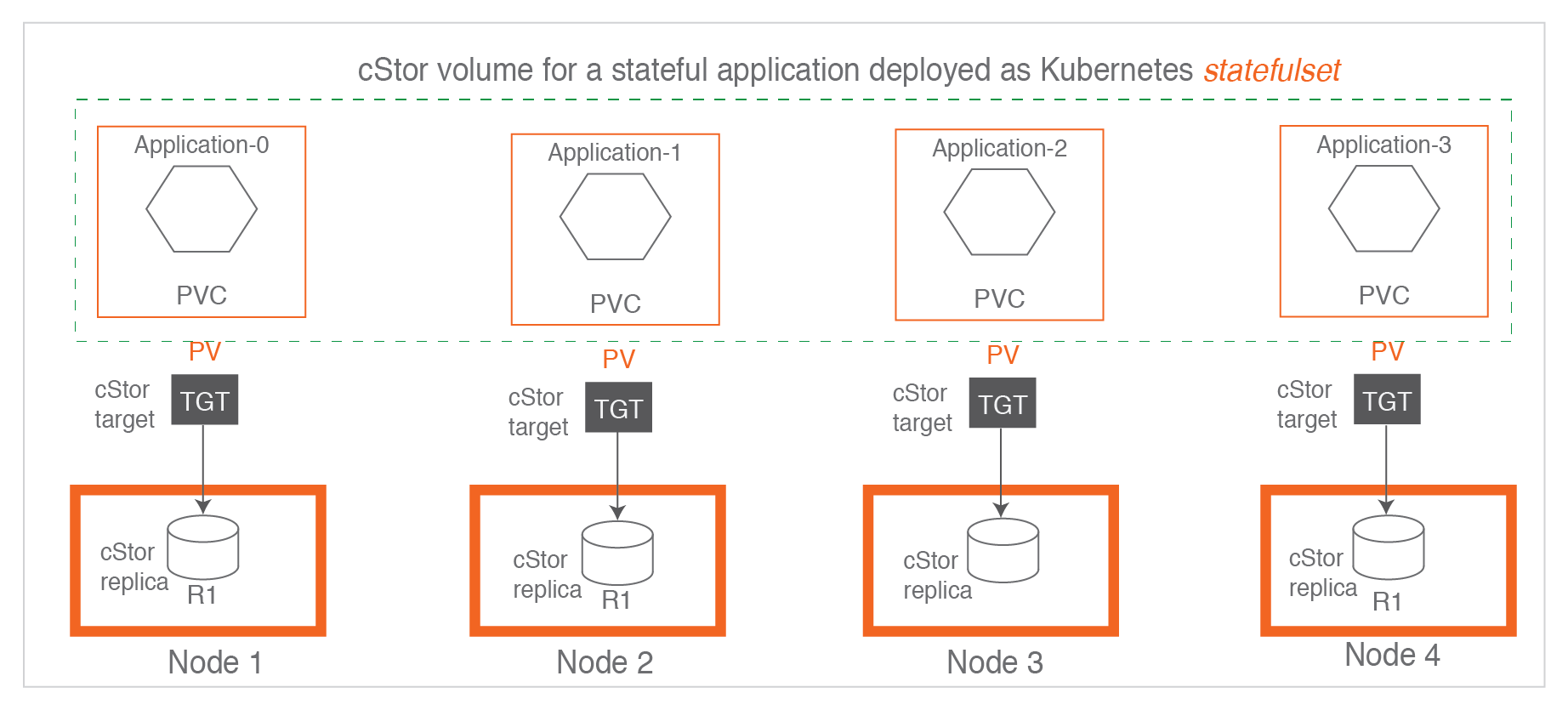
cStor 有两个主要组件
-
cStor Pool Pods
负责将数据持久化到磁盘中,在节点上实例化,并随附一个或多个用于保存数据的磁盘。每个 cStor pool pod 可以保存一个或多个 cStor 卷的数据,为每个卷副本分配空间,管理副本的快照和克隆。
一组这样的 cStor Pool Pods 形成一个单一的存储池。在为 cStor 卷创建 StorageClass 之前,管理员必须创建一个 cStor 类型的存储池。
-
cStor Target Pod
配置 cStor Volume 时,它会创建一个新的 cStor target pod。从workload接收数据,然后将其传递到相应的 cStor 卷副本(在 cStor 池上)。还会处理其副本的同步复制和仲裁管理。
cStor pools
是磁盘和其绑定节点的集合。一个池包含不同卷的副本,给定卷的副本不超过一个。OpenEBS 调度程序在运行时决定根据策略在池中调度副本。可以动态扩展池而不影响驻留在其中的卷。此功能的一个优势是 cStor 卷的自动精简配置。cStor 卷大小在供应时可能比池中的实际可用容量大得多。
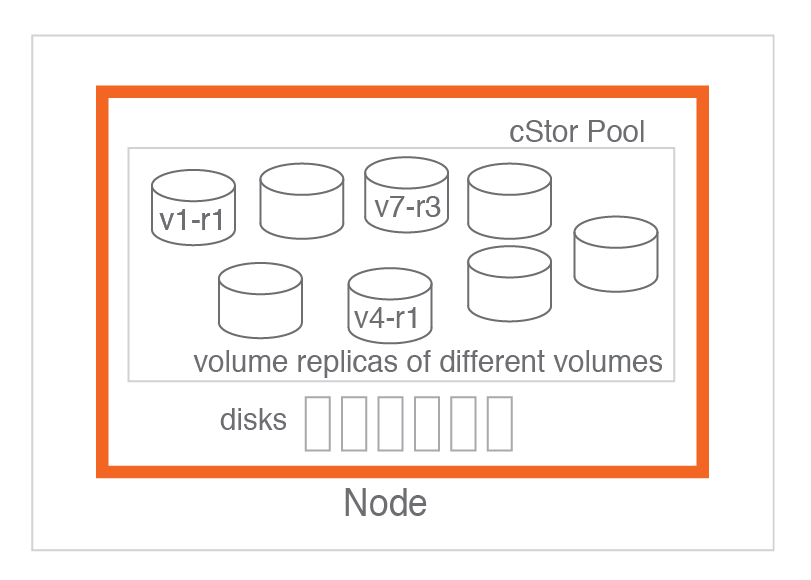
好处
- 集合形式可以按需增加可用容量和/或性能
- 精简配置容量。可以为卷分配比节点中可用容量更多的容量。
- 设置为mirror,当发生磁盘丢失时实现存储的高可用性
1 | |
cStor storage pools
1 | |
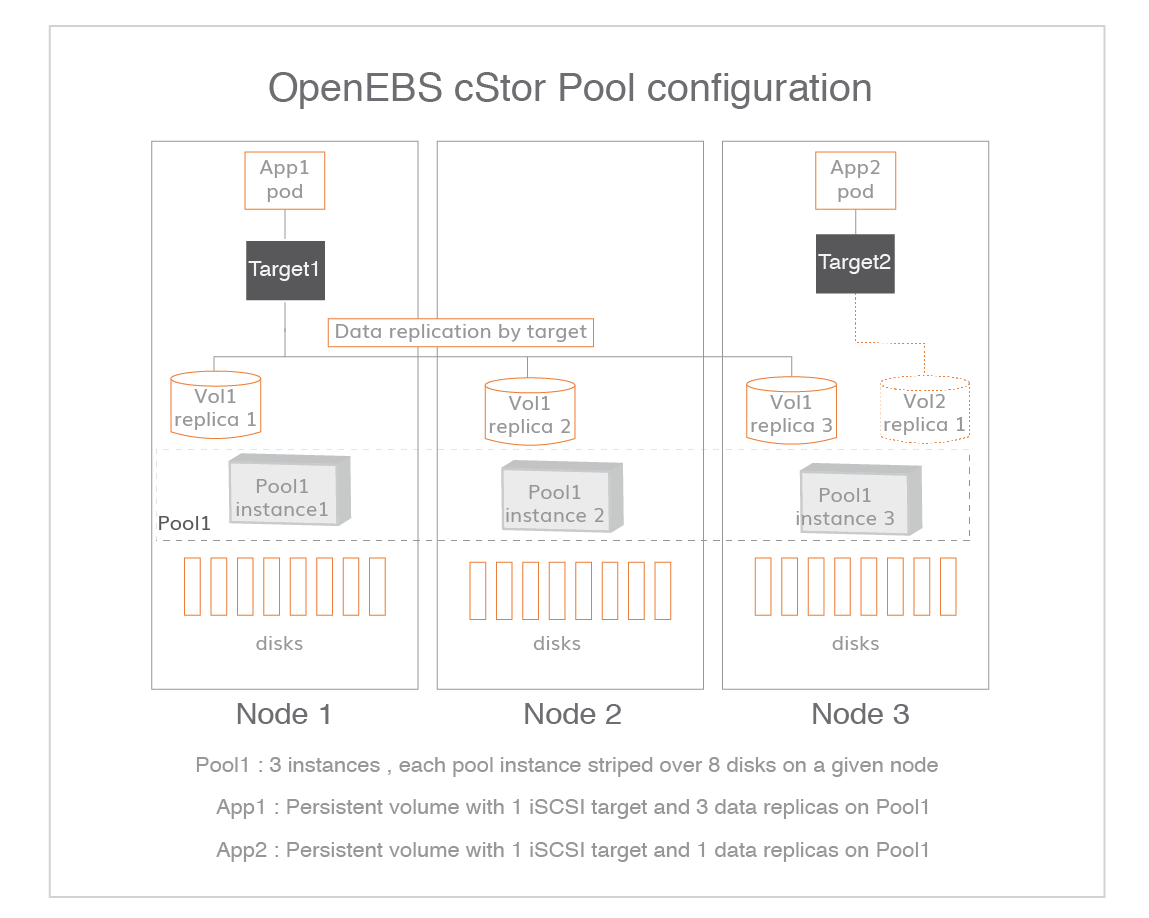
cStor 卷和 cStor 池之间的关系
cStor 池是一组单独的池,每个节点都有一个池实例。每个池实例都有对应的pod,池之间彼此独立。卷副本只由cStor Target决定再何处托管 ,cStor Target在卷级别进行同步数据复制和重建,和池没有关系。
1 | |
jiva
每个jiva卷都由一个Controller和若干Replicas构成。Jiva模拟block device(由iSCSI target实现,叫gotgt是Controller一部分),block device会被发现和挂载到pod所在的远程主机。
Jiva Controller会将传入的 IO 并行复制到它的副本中,副本反过来将这些 IO 写入稀疏文件。
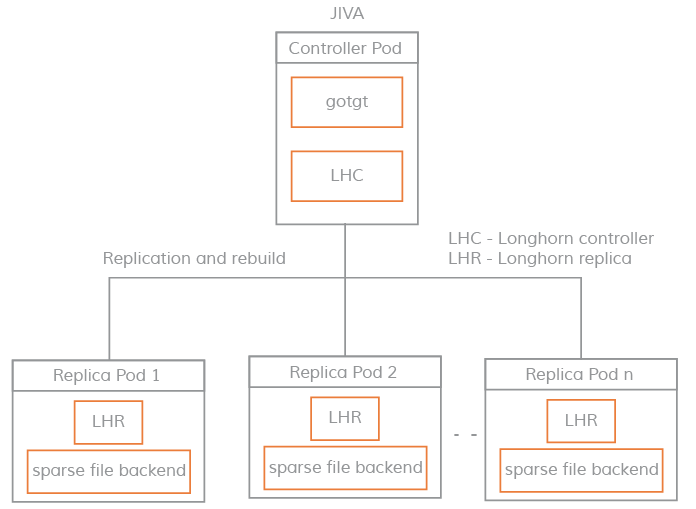
Jiva 卷Controller负责启动和协调同步副本的流程。一旦副本出现,它会尝试添加到控制器,控制器会将其标记为 WO(只写)。然后副本从其他健康副本启动重建流程。同步完成后,卷控制器将新副本设置为 RW(读写)模式。当控制器检测到其中一个副本出现故障时,它会将副本标记为处于错误状态并触发重建流程。
Jiva 是一种轻量级存储引擎,建议用于低容量工作负载。另一个cStor引擎的快照和存储管理功能更高级,在需要快照时推荐使用。
Mayastor
Mayastor目前正在作为开源 CNCF 项目OpenEBS的子项目进行开发。OpenEBS 是一种“容器附加存储”或 CAS 解决方案,它使用声明性数据平面扩展 Kubernetes,为有状态应用程序提供灵活、持久的存储。
OpenEBS Mayastor 结合了英特尔的存储性能开发工具包。它从头开始设计,以利用 NVMe-oF 语义的协议和计算效率,以及最新一代固态存储设备的性能,以提供存储抽象,其性能开销被测量为在个位数百分比的范围。
Mayastor 是测试版软件,正在积极开发中。
-
支持 SSE4.2 指令的x86-64 CPU 内核
1
2
3cat /proc/cpuinfo |grep sse4_2 flags : ... sse4_2 ... -
Linux 内核5.13 或更高版本,支持nvme-tcp,ext4 和可选的 xfs
1
2
3
4
5
6
7
8
9# 内核 uname -a # 查看已加模块 lsmod |grep xxx modinfo xxx lsmod |grep nvme -
hugepage
1
2
3
4
5
6
7
8
9
10
11
12# 验证 HugePages_Total > 1024 cat /proc/meminfo |grep -i huge AnonHugePages: 7006208 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB # restart kubelet or reboot the node echo vm.nr_hugepages = 1024 | sudo tee -a /etc/sysctl.conf -
This label will be used as a node selector by the Mayastor Daemonset
1
kubectl label node <node_name> openebs.io/engine=mayastor
安装部署
安装环境
三个全角色节点,k8s v1.23.6, rke v1.3.11
| ip | 系统 | cpu | 内存 | 硬盘 | 内核 |
|---|---|---|---|---|---|
| xx.xx.xx.57 | CentoOS7 x86_64 | 8 | 31 | xfs 500G | 3.10.0-1062.1.1.el7.x86_64 |
| xx.xx.xx.53 | CentoOS7 x86_64 | 8 | 31 | xfs 500G | 3.10.0-1062.1.1.el7.x86_64 |
| xx.xx.xx.155 | CentoOS7 x86_64 | 8 | 31 | xfs 500G | 3.10.0-1062.1.1.el7.x86_64 |
对于cstor机器上面要有raw disk: 没有分区,挂载,格式化的磁盘,已挂载磁盘不会显示blockdevice
安装localpath,cstor,jiva可以正常运行。
预配置
镜像
1 | |
Centos 安装iSCSI
1 | |
1 | |
获取helm chart, openceb helm 参数用法
1 | |
hostpath
1 | |
check hostpath
1 | |
1 | |
cStor
cStor依赖iSCSI服务
- csTor invalid pool spec: block device has file system {ext4} CStorPoolCluster不能绑定文件系统是ext4的block device,xfs可以
1 | |
values.yaml
1 | |
pod
1 | |
创建cStor storage pools
通过命令查看 block devices
1 | |
创建cStor storage pools,进行node和device绑定,创建CStorPoolCluster
cspc.yaml
1 | |
1 | |
cStor storage classes
创建存储类
cstor-csi-disk.yaml
1 | |
1 | |
测试
ebs-cstor.yaml
1 | |
1 | |
Jiva
使用hostpath作为副本存储类 ,Kubernetes version 1.21 or higher
安装
1 | |
values.yaml
1 | |
1 | |
测试
1 | |
1 | |
排错
关于block device问题可以参考Node Disk Manager
1 | |
补充说明
Data striping
当处理设备请求数据的速度比单个存储设备提供数据的速度快时,条带化很有用。通过将段分布到可以同时访问的多个设备上,可以增加总数据吞吐量。它也是一种在磁盘阵列之间平衡 I/O 负载的有用方法。
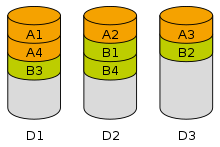
数据条带化示例。四个块的文件 A 和 B 分别分布在磁盘 D1 到 D3 上。
一种条带化方法是通过从数据序列的开始以循环方式交错存储设备上的顺序段来完成的。这适用于流数据,但随后的随机访问将需要知道哪个设备包含数据。如果数据被存储,使得每个数据段的物理地址被分配到特定设备的一对一映射,则可以从地址计算出访问请求的每个段的设备,而无需知道数据在数据中的偏移量全序列。
可以采用其他方法,其中顺序段不存储在顺序设备上。这种非顺序交织在一些纠错方案中可能有好处。
条带化的优势包括性能和吞吐量。
-
数据访问的顺序时间交织允许每个存储设备的较小数据访问吞吐量累积乘以所使用的存储设备的数量。
-
增加的吞吐量允许数据处理设备不间断地继续其工作,从而更快地完成其过程。这体现在数据处理性能的提高上。
由于不同的数据段保存在不同的存储设备上,一个设备的故障会导致整个数据序列的损坏。实际上,存储设备阵列的故障率等于每个存储设备的故障率之和。为了纠错的目的,可以通过存储冗余信息(例如奇偶校验)来克服条带化的这个缺点。在这样的系统中,以需要额外存储为代价克服了缺点。
块存储
块存储将数据视为一系列固定大小的“块”,其中每个文件或对象可以分布在多个块上。不需要连续存储这些块。每当用户请求该数据时,底层存储系统将数据块合并在一起并提供用户请求。
传统的文件系统,是直接访问存储数据的硬件介质的。介质不关心也无法去关心这些数据的组织方式以及结构,因此用的是最简单粗暴的组织方式:所有数据按照固定的大小分块,每一块赋予一个用于寻址的编号。以大家比较熟悉的机械硬盘为例,一块就是一个扇区,老式硬盘是512字节大小,新硬盘是4K字节大小。老式硬盘用柱面-磁头-扇区号(CHS,Cylinder-Head-Sector)组成的编号进行寻址,现代硬盘用一个逻辑块编号寻址(LBA,Logical Block Addressing)。所以,硬盘往往又叫块设备(Block Device),当然,除了硬盘还有其它块设备,例如不同规格的软盘,各种规格的光盘,磁带等。
至于哪些块组成一个文件,哪些块记录的是目录/子目录信息,这是文件系统的事情。不同的文件系统有不同的组织结构,这个就不展开了。为了方便管理,硬盘这样的块设备通常可以划分为多个逻辑块设备,也就是我们熟悉的硬盘分区(Partition)。反过来,单个介质的容量、性能有限,可以通过某些技术手段把多个物理块设备组合成一个逻辑块设备,例如各种级别的RAID,JBOD,某些操作系统的卷管理系统(Volume Manager)如Windows的动态磁盘、Linux的LVM等。
在网络存储中,服务器把本地的一个逻辑块设备——底层可能是一个物理块设备的一部分,也可能是多个物理块设备的组合,又或者多个物理块设备的组合中的一部分,甚至是一个本地文件系统上的一个文件——通过某种协议模拟成一个块设备,远程的客户端(可以是一台物理主机,也可以是虚拟机,某个回答所说的块设备是给虚拟机用是错误的)使用相同的协议把这个逻辑块设备作为一个本地存储介质来使用,划分分区,格式化自己的文件系统等等。这就是块存储,比较常见的块存储协议是iSCSI。