-
https://github.com/brendangregg/bpf-perf-tools-book
BPF
BPF允许内核在系统和应用程序事件上运行小型程序,从而实现新的系统技术。它使内核完全可编程,使用户(包括非内核开发人员)能够自定义和控制其系统以解决现实世界中的问题。
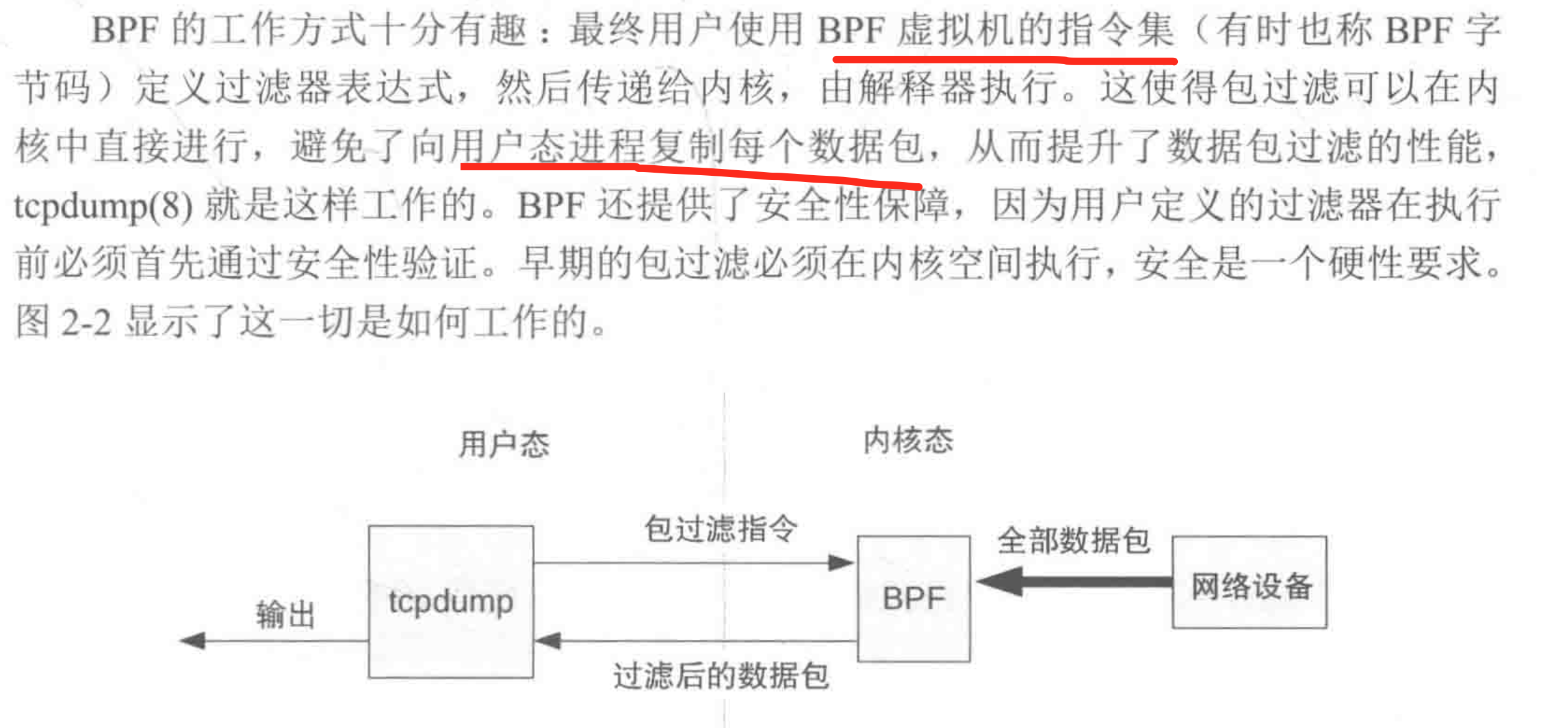
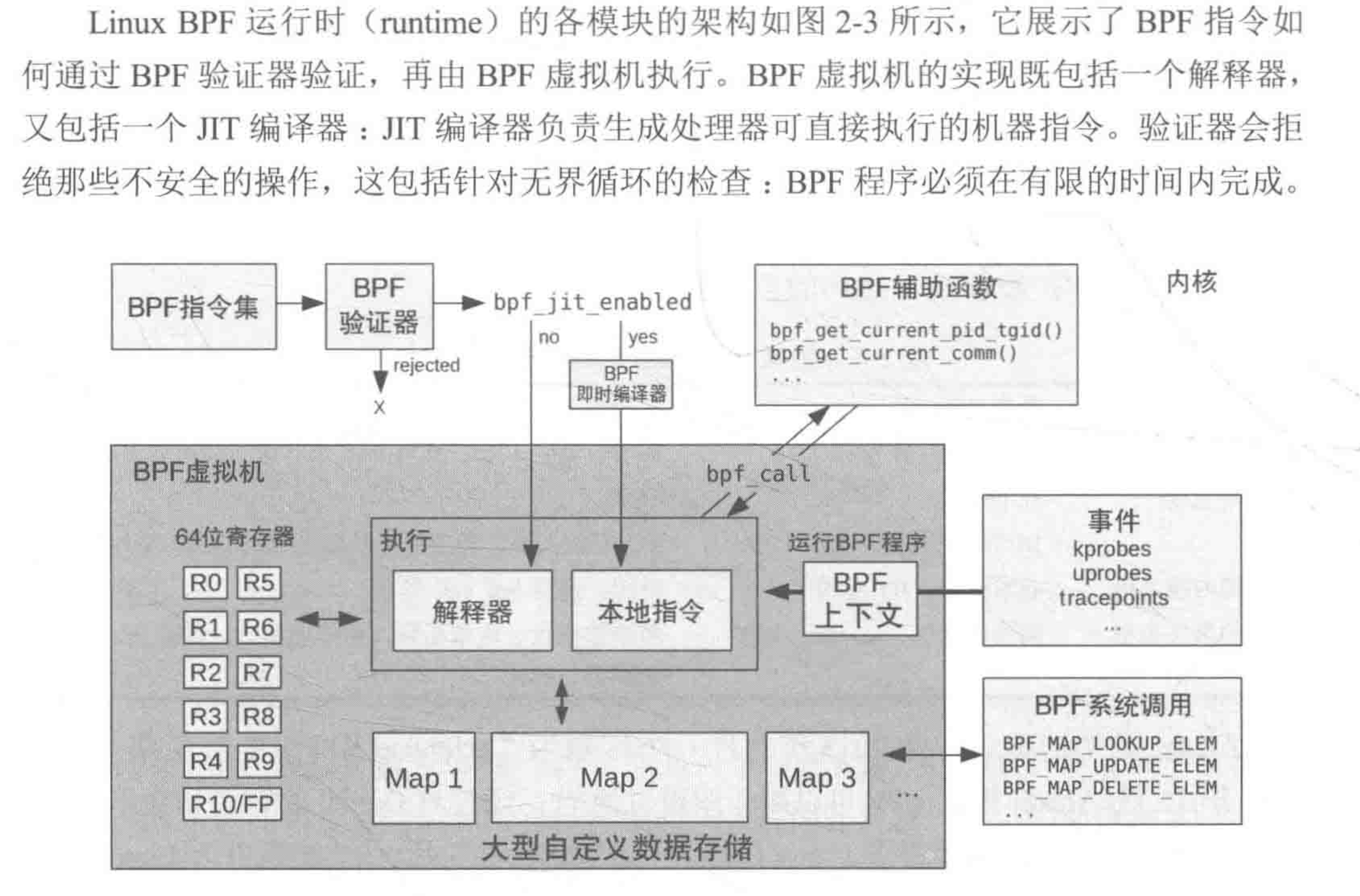
BPF是一种灵活高效的技术,由指令集、存储对象和帮助函数组成。由于其虚拟指令集规范,它可以被视为一种虚拟机。这些指令由Linux内核BPF运行时执行,其中包括一个解释器和一个JIT编译器,用于将BPF指令转换为本地指令以进行执行。BPF指令必须首先通过验证器,该验证器检查安全性,确保BPF程序不会使内核崩溃或损坏(但它无法防止最终用户编写不合逻辑的程序,这些程序可能会执行但没有意义)。
BPF的三个主要用途是网络、可观察性和安全性。
发展史



eBPF
kube-proxy为定义的每个新服务添加了iptables规则集。随着服务数量的增加,该列表将变得庞大,并且可能会影响性能(我们将在不久后看到),因为iptables处理是顺序的。规则在链中越向下,处理所需的时间就越长。那么我们可以删除kube-proxy并用不使用下面的iptables的替代方法替换它吗?是。解决方案(或潜在解决方案之一)在于使用eBPF扩展的伯克利数据包过滤器(Extended Berkeley Packet Filter),从这个名字中,你可以看到它的根源在于过滤网络数据包。
eBPF 是一个框架,允许用户在操作系统的内核内加载和运行自定义程序。这意味着它可以扩展甚至修改内核的行为。
eBPF 提供了一个非常不同的安全方法:eBPF 验证器(verifier),它确保一个 eBPF 程序只有在安全运行的情况下才被加载。
由于 eBPF 允许我们在内核中运行任意代码,需要有一种机制来确保它的安全运行,不会使用户的机器崩溃,也不会损害他们的数据。这个机制就是 eBPF 验证器。
eBPF 程序可以动态地加载到内核中和从内核中删除。不管是什么原因导致该事件的发生,一旦它们被附加到一个事件上就会被该事件所触发。例如,如果你将一个程序附加到打开文件的系统调用,那么只要任何进程试图打开一个文件,它就会被触发。当程序被加载时,该进程是否已经在运行,这并不重要。
这也是使用 eBPF 的可观测性或安全工具的巨大优势之一——即刻获得了对机器上发生的一切事件的可视性。
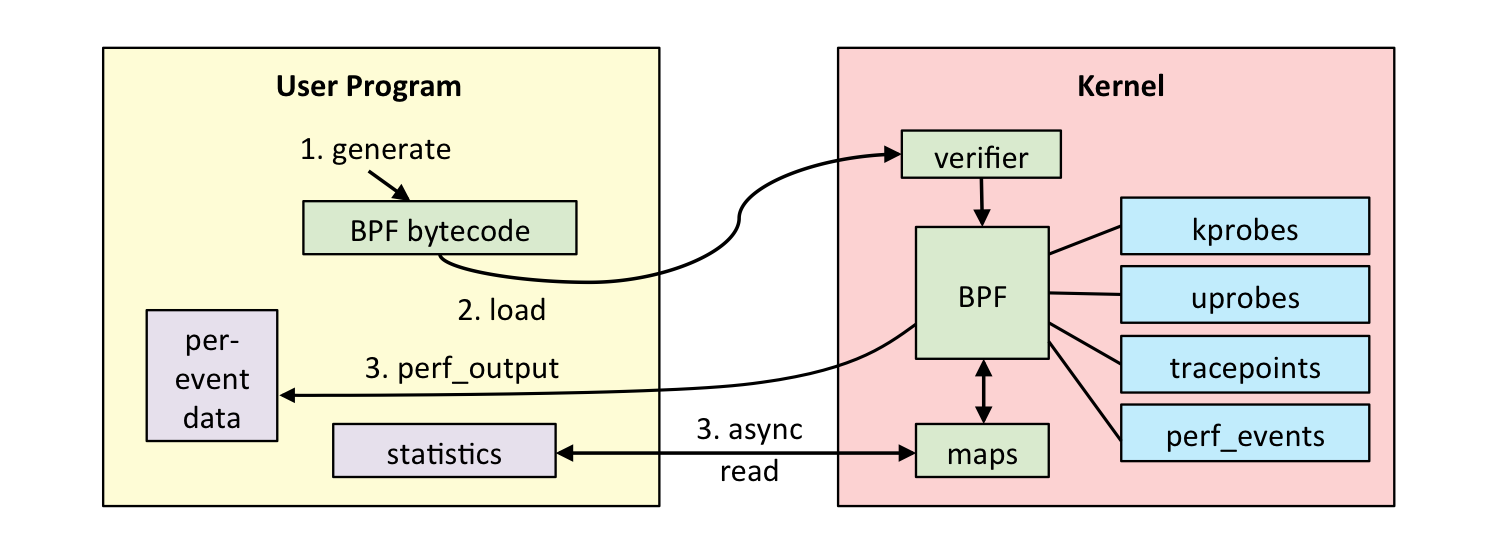
eBPF 分为用户空间程序和内核程序两部分:
- 用户空间程序负责加载 BPF 字节码至内核,如需要也会负责读取内核回传的统计信息或者事件详情;
- 内核中的 BPF 字节码负责在内核中执行特定事件,如需要也会将执行的结果通过 maps 或者 perf-event 事件发送至用户空间;
其中用户空间程序与内核 BPF 字节码程序可以使用 map 结构实现双向通信,这为内核中运行的 BPF 字节码程序提供了更加灵活的控制。
用户空间程序与内核中的 BPF 字节码交互的流程主要如下:
- 我们可以使用 LLVM 或者 GCC 工具将编写的 BPF 代码程序编译成 BPF 字节码;
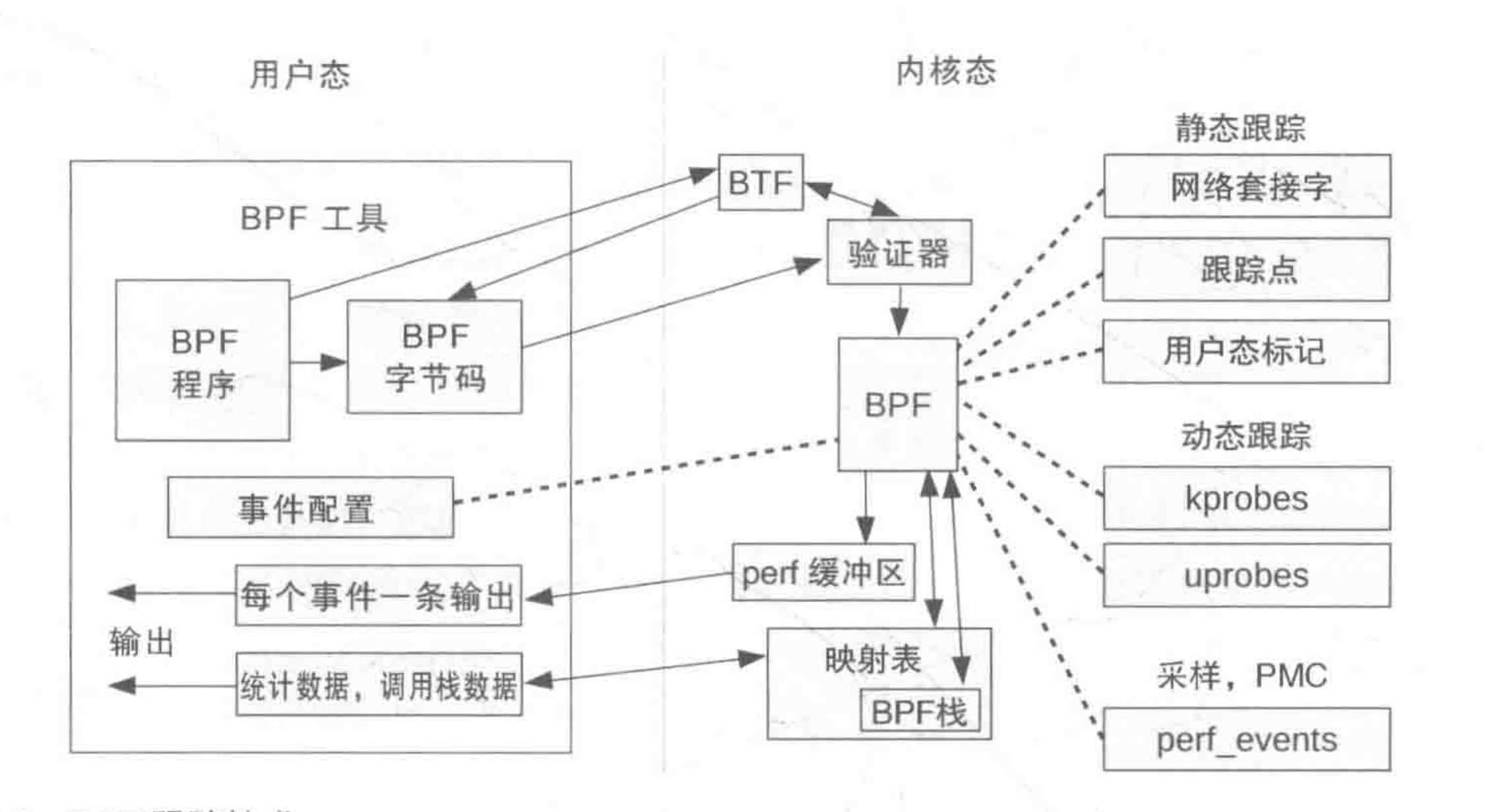
- 然后使用加载程序 Loader 将字节码加载至内核;内核使用验证器(verfier) 组件保证执行字节码的安全性,以避免对内核造成灾难,在确认字节码安全后将其加载对应的内核模块执行;BPF 观测技术相关的程序程序类型可能是 kprobes/uprobes/tracepoint/perf_events 中的一个或多个,其中:
- kprobes:实现内核中动态跟踪。 kprobes 可以跟踪到 Linux 内核中的函数入口或返回点,但是不是稳定 ABI 接口,可能会因为内核版本变化导致,导致跟踪失效。
- uprobes:用户级别的动态跟踪。与 kprobes 类似,只是跟踪的函数为用户程序中的函数。
- tracepoints:内核中静态跟踪。tracepoints 是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限。
- perf_events:定时采样和 PMC。
- 内核中运行的 BPF 字节码程序可以使用两种方式将测量数据回传至用户空间
- maps 方式可用于将内核中实现的统计摘要信息(比如测量延迟、堆栈信息)等回传至用户空间;
- perf-event 用于将内核采集的事件实时发送至用户空间,用户空间程序实时读取分析;
总得来说,eBPF 是一套通用执行引擎,提供了可基于系统或程序事件高效安全执行特定代码的通用能力,通用能力的使用者不再局限于内核开发者;eBPF 可由执行字节码指令、存储对象和 Helper 辅助函数组成,字节码指令在内核执行前必须通过 BPF 验证器 Verfier 的验证,同时在启用 BPF JIT 模式的内核中,会直接将字节码指令转成内核可执行的本地指令运行。
限制
- eBPF 程序不能调用任意的内核参数,只限于内核模块中列出的 BPF Helper 函数,函数支持列表也随着内核的演进在不断增加
- eBPF 程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止
- eBPF 程序中循环次数限制且必须在有限时间内结束,这主要是用来防止在 kprobes 中插入任意的循环,导致锁住整个系统;解决办法包括展开循环,并为需要循环的常见用途添加辅助函数。Linux 5.3 在 BPF 中包含了对有界循环的支持,它有一个可验证的运行时间上限。
- eBPF 堆栈大小被限制在 MAX_BPF_STACK,截止到内核 Linux 5.8 版本,被设置为 512;参见 include/linux/filter.h,这个限制特别是在栈上存储多个字符串缓冲区时:一个char[256]缓冲区会消耗这个栈的一半。目前没有计划增加这个限制,解决方法是改用 bpf 映射存储,它实际上是无限的。
- eBPF 字节码大小最初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令( BPF_COMPLEXITY_LIMIT_INSNS),参见:include/linux/bpf.h,对于无权限的BPF程序,仍然保留4096条限制 ( BPF_MAXINSNS );新版本的 eBPF 也支持了多个 eBPF 程序级联调用,虽然传递信息存在某些限制,但是可以通过组合实现更加强大的功能。
附属于事件的自定义程序
eBPF 程序本身通常是用 C 或 Rust 编写的,并编入一个对象文件 2。这是一个标准的 ELF(可执行和可链接格式,Executable and Linkable Format)文件,可以用像 readelf 这样的工具来检查,它包含程序字节码和任何映射的定义(我们很快就会讨论)。如 图 3-1 所示,如果在前一章中提到的验证器允许的话,用户空间程序会读取这个文件并将其加载到内核中。
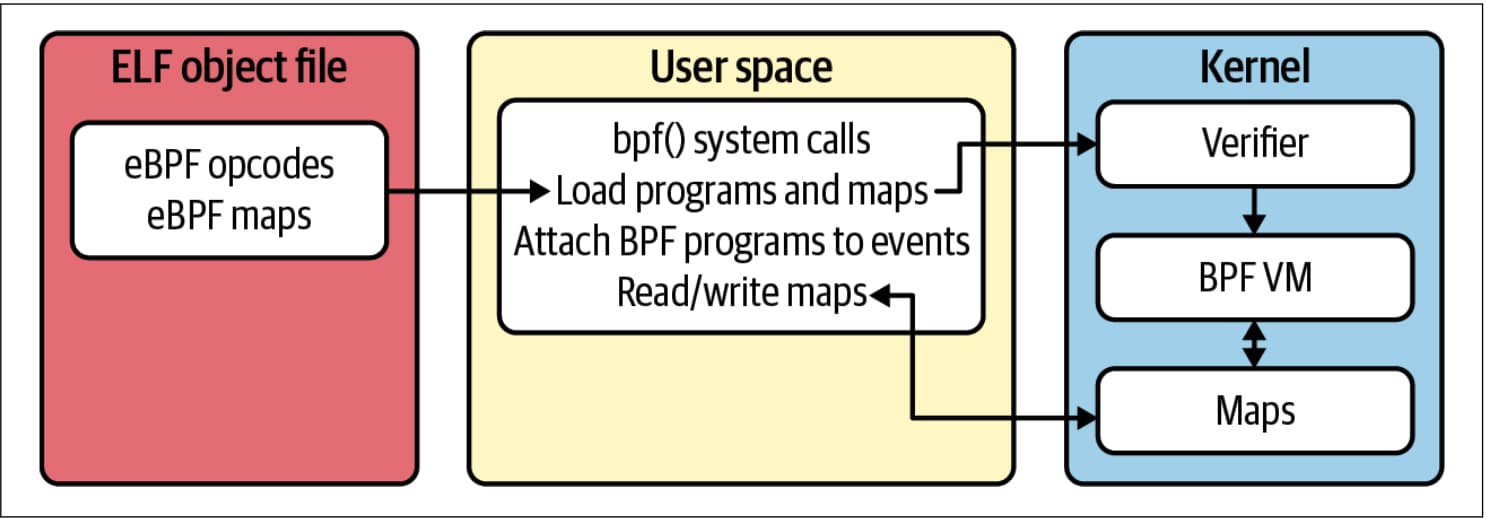
图 3-1. 用户空间应用程序使用 bpf() 系统调用从 ELF 文件中加载 eBPF 程序到内核中
eBPF 程序加载到内核中时必须被附加到事件上。每当事件发生,相关的 eBPF 程序就会运行。有一个非常广泛的事件,你可以将程序附加到其中;我不会涵盖所有的事件,但以下是一些更常用的选项。
从函数中进入或退出
你可以附加一个 eBPF 程序,在内核函数进入或退出时被触发。当前的许多 eBPF 例子都使用了 kprobes(附加到一个内核函数入口点)和 kretprobes(函数退出)的机制。在最新的内核版本中,有一个更有效的替代方法,叫做 fentry/fexit 3。
请注意,你不能保证在一个内核版本中定义的所有函数一定会在未来的版本中可用,除非它们是稳定 API 的一部分,如 syscall 接口。
你也可以用 uprobes 和 uretprobes 将 eBPF 程序附加到用户空间函数上。
网络接口——eXpress Data Path
eXpress Data Path(XDP)允许将 eBPF 程序附加到网络接口上,这样一来,每当收到一个数据包就会触发 eBPF 程序。它可以检查甚至修改数据包,程序的退出代码可以告诉内核如何处理该数据包:传递、放弃或重定向。这可以构成一些非常有效的网络功能的基础。
套接字和其他网络钩子
当应用程序在网络套接字上打开或执行其他操作时,以及当消息被发送或接收时,你可以附加运行 eBPF 程序。在内核的网络堆栈中也有称为 流量控制(traffic control) 或 tc 的 钩子,eBPF 程序可以在初始数据包处理后运行。
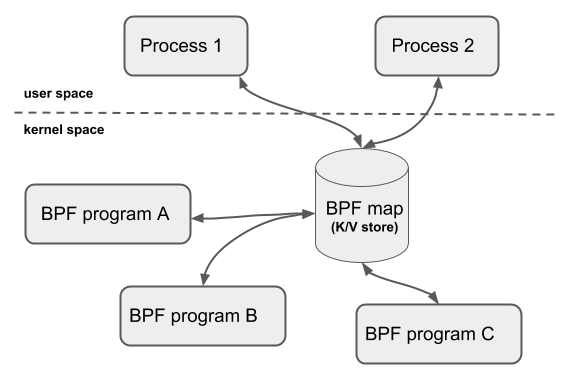
一些功能可以单独用 eBPF 程序实现,但在许多情况下,我们希望 eBPF 代码能从用户空间的应用程序接收信息,或将数据传递给用户空间的应用程序。允许数据在 eBPF 程序和用户空间之间,或在不同的 eBPF 程序之间传递的机制被称为 map。
eBPF Map
map 的开发是 eBPF 缩略语中的 e 代表 extended 重要区别之一。
map 是与 eBPF 程序一起定义的数据结构体。有各种不同类型的 map ,但它们本质上都是键值存储。eBPF 程序可以读取和写入 map,用户空间代码也可以。map 的常见用途包括:
- eBPF 程序写入关于事件的指标和其他数据,供用户空间代码以后检索。
- 用户空间代码编写配置信息,供 eBPF 程序读取并作出相应的行为。
- eBPF 程序将数据写入 map ,供另一个 eBPF 程序以后检索,允许跨多个内核事件的信息协调。
如果内核和用户空间的代码都要访问同一个映射,它们需要对存储在该映射中的数据结构体有一个共同的理解。这可以通过在用户空间和内核代码中加入定义这些数据结构体的头文件来实现,但是如果这些代码不是用相同的语言编写的,作者将需要仔细创建逐个字节兼容的结构体定义。
我们已经讨论了 eBPF 工具的主要组成部分:在内核中运行的 eBPF 程序,加载和与这些程序交互的用户空间代码,以及允许程序共享数据的 map 。为了更具体化,让我们看一个例子。
跨内核的可移植性
长期以来,有个问题使得编写和发布 eBPF 程序相对困难,那就是内核兼容性。
eBPF 程序可以访问内核数据结构,而这些结构可能在不同的内核版本中发生变化。这些结构本身被定义在头文件中,构成了 Linux 源代码的一部分。在过去编译 eBPF 程序时,必须基于你想运行这些程序的内核兼容的头文件集。
为了解决跨内核的可移植性问题,BCC 1(BPF 编译器集合,BPF Compiler Collection)项目采取了在运行时编译 eBPF 代码的方法,在目标机器上就地进行。这意味着编译工具链需要安装到每个你想让代码运行的目标机器上,而且你必须在工具启动之前等待编译完成,而且文件系统上必须有内核头文件(实际上并不总是这样)。这就引出了 BPF CO-RE。
CO-RE
CO-RE(Compile Once, Run Everyone,编译一次,到处运行)方法由以下元素组成。
BTF(BPF Type Format)
这是一种用于表达数据结构和函数签名布局的格式。现代 Linux 内核支持 BTF,因此你可以从运行中的系统中生成一个名为 vmlinux.h 的头文件,其中包含一个 BPF 程序可能需要的关于内核的所有数据结构信息。
libbpf,BPF 库
libbpf 一方面提供了加载 eBPF 程序和映射到内核的功能,另一方面也在可移植性方面也起着重要的作用:它依靠 BTF 信息来调整 eBPF 代码,以弥补其编译时的数据结构与目标机器上的数据结构之间的差异。
编译器支持
clang 编译器得到了增强,因此当它编译 eBPF 程序时,它包括所谓的 BTF 重定位(relocation),这使得 libbpf 在加载 BPF 程序和映射到内核时知道要调整什么。
BPF CO-RE 方法使得 eBPF 程序更易于在任意 Linux 发行版上运行 —— 或者至少在新 Linux 发行版上支持任意 eBPF 能力。但这并不能使 eBPF 更优雅:它本质上仍然是内核编程。
云原生环境中的 eBPF
同一主机上的所有容器共享一个内核
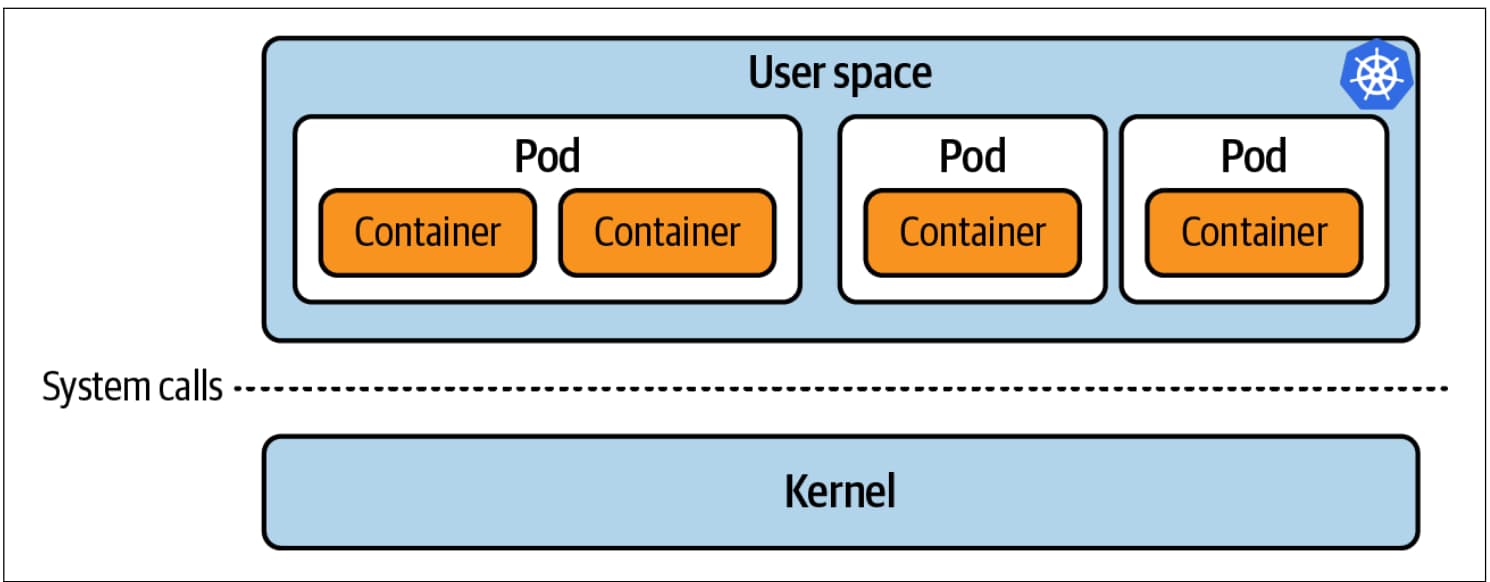
通过对内核的检测,就像我们在使用 eBPF 时做的那样,我们可以同时检测在该机器上运行的所有应用程序代码。当我们将 eBPF 程序加载到内核并将其附加到事件上时,它就会被触发,而不考虑哪个进程与该事件有关。
eBPF 与 sidecar 模式的比较
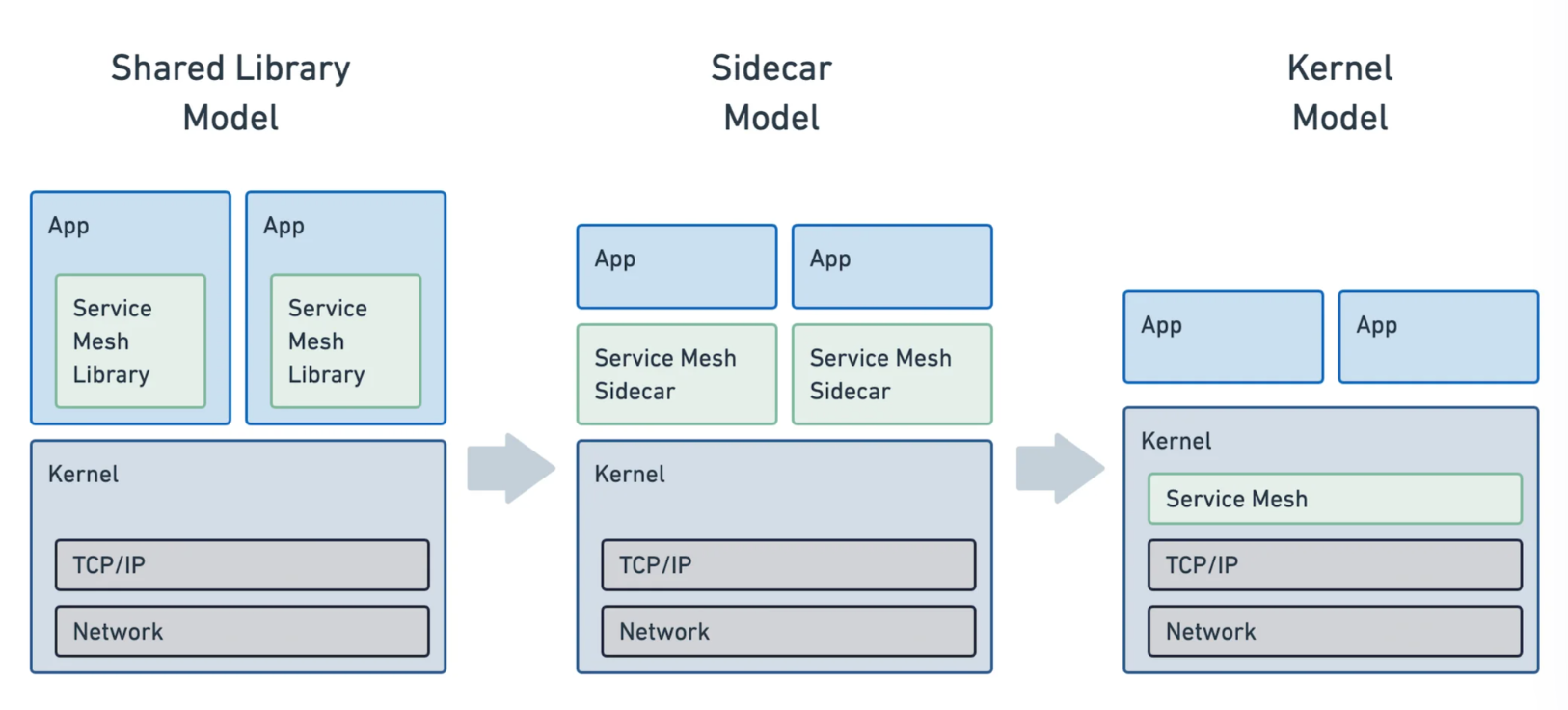
在 eBPF 之前,Kubernetes 的可观测性和安全工具大多都采用了 sidecar 模式。这种模式允许你在与应用程序相同的 pod 中,单独部署一个工具容器。这种模式的发明是一个进步,因为这意味着不再需要直接在应用程序中编写工具代码。仅仅通过部署 sidecar,工具就获得了同一 pod 中的其他容器的可视性。注入 sidecar 的过程通常是自动化的。
每个 sidecar 容器都会消耗资源,而这要乘以注入了 sidecar 的 pod 的数量。这可能是非常重要的 —— 例如,如果每个 sidecar 需要它自己的路由信息副本,或策略规则。
Sidecar 的另一个问题是,你不能保证机器上的每一个应用程序都被正确检测。设想下有一个攻击者设法破坏了你的一台主机,并启动了一个单独的 pod 来运行,比如,加密货币挖矿程序。他们不可能用你的 sidecar 可观测或安全工具来检测他们的挖矿 pod。但同样的加密货币矿工与运行在该主机上的合法 pod 共享内核。如果你使用基于 eBPF 的工具,矿工会自动受到它的影响。
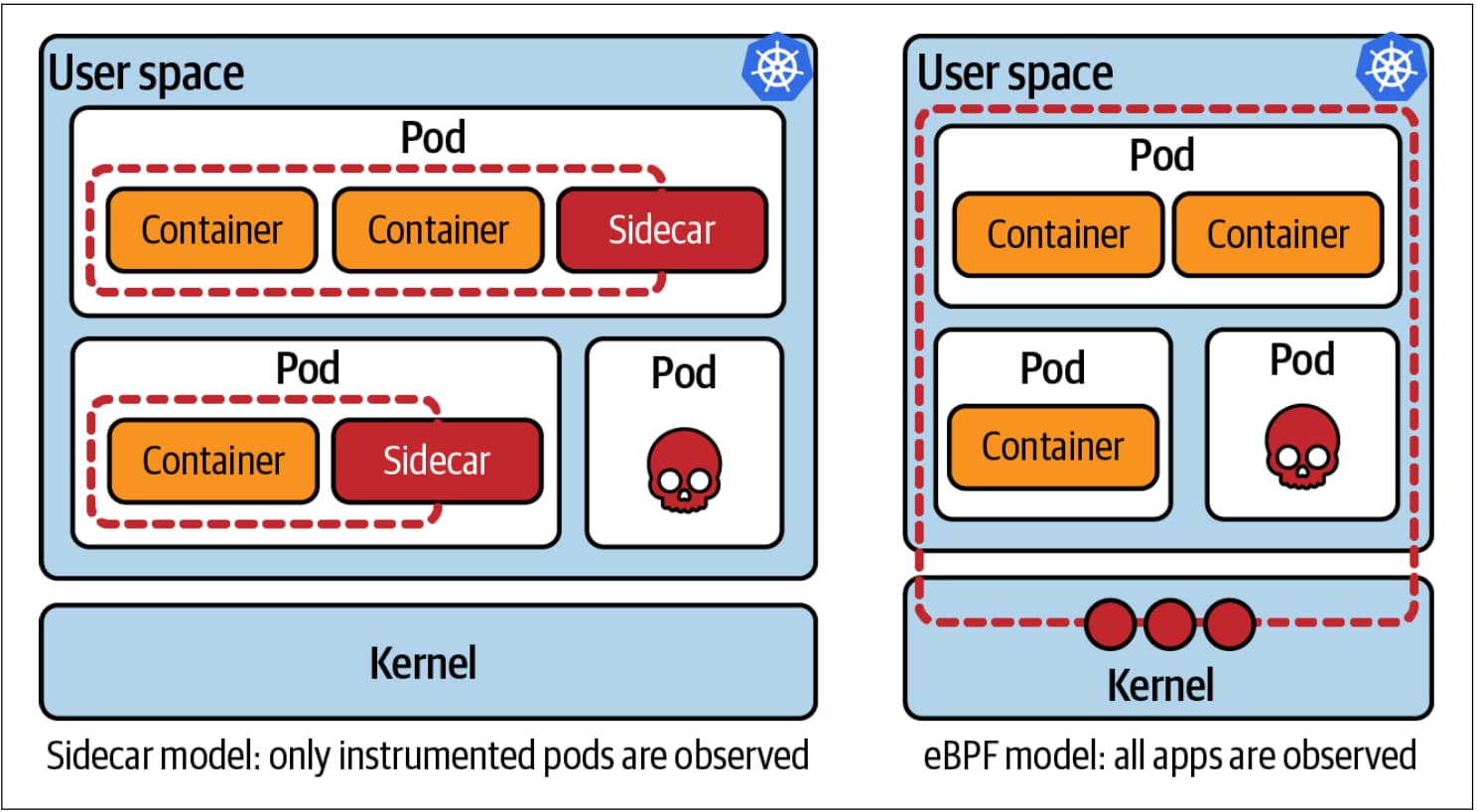
请注意,这些 pod 共享同一个内核,而内核原生不能感知 pod 或容器。相反,内核对进程进行操作,并使用 cgroup 和 namespace 来隔离进程。这些结构由内核监管,以隔离用户空间中的进程,防止它们互相干扰。只要数据在内核中处理(例如,从磁盘中读取或发送到网络中),你就依赖于内核的正确行为。只有内核代码控制文件权限。没有其他层面的东西可以阻止内核忽略文件权限的东西,内核可以从任何文件中读取数据 —— 只是内核本身不会这样做。
存在于 Linux 系统中的安全控制措施假定内核本身是可以信任的。它们的存在是为了防止在用户空间运行的代码产生不良行为。
eBPF 检查器确保 eBPF 程序只能访问它有权限的内存。检查器检查程序时不可能超出其职权范围,包括确保内存为当前进程所拥有或为当前网络包的一部分。这意味着 eBPF 代码比它周围的内核代码受到更严格的控制,内核代码不需要通过任何类型的检查器。
如果攻击者逃脱了容器化的应用程序而到了节点上,而且还能够提升权限,那么该攻击者就可以危害到同一节点上的其他应用程序。由于这些逃逸是未知的,作为一个容器安全专家,我不建议在没有额外安全工具的情况下,在共享机器上与不受信任的应用程序或用户一起运行敏感的应用程序。对于高度敏感的数据,你甚至可能不希望在虚拟机中与不受信任的用户在同一裸机上运行。但是,如果你准备在同一台虚拟机上并行运行应用程序(这在许多不是特别敏感的应用程序中是完全合理的),那么 eBPF 就不会在共享内核已经存在的风险之上增加额外的风险。
当然,恶意的 eBPF 程序可能造成各种破坏,当然也很容易写出劣迹的 eBPF 代码 —— 例如,复制每个网络数据包并将其发送给窃听者。默认情况下,非 root 用户没有加载 eBPF 程序的权限, 只有当你真正信任他们时,你才应该授予用户或软件系统这种权限,就像 root 权限一样。
和kubeproxy对比datapath
kube-proxy 包转发路径
使用传统的 kube-proxy 处理 Kubernetes Service 时,包在内核中的 转发路径是怎样的?如下图所示
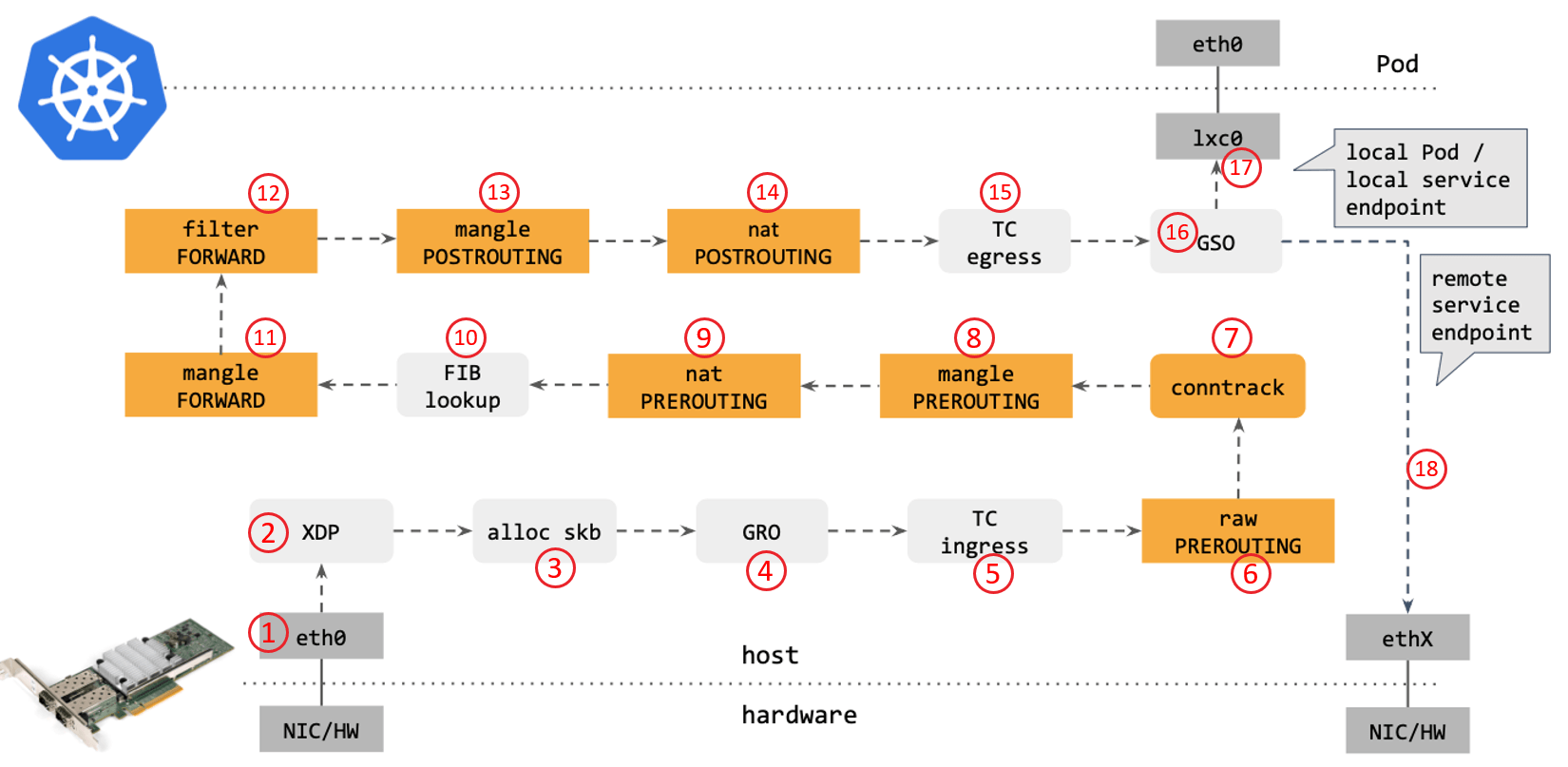
- 网卡收到一个包(通过 DMA 放到 ring-buffer)。
- 包经过 XDP hook 点。
- 内核给包分配内存,此时才有了大家熟悉的
skb(包的内核结构体表示),然后 送到内核协议栈。 - 包经过 GRO 处理,对分片包进行重组。
- 包进入 tc(traffic control)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点。
- Netfilter:在
PREROUTINGhook 点处理rawtable 里的 iptables 规则。 - 包经过内核的连接跟踪(conntrack)模块。
- Netfilter:在
PREROUTINGhook 点处理mangletable 的 iptables 规则。 - Netfilter:在
PREROUTINGhook 点处理nattable 的 iptables 规则。 - 进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示,译者注) 。接下来又是四个 Netfilter 处理点。
- Netfilter:在
FORWARDhook 点处理mangletable 里的 iptables 规则。 - Netfilter:在
FORWARDhook 点处理filtertable 里的 iptables 规则。 - Netfilter:在
POSTROUTINGhook 点处理mangletable 里的 iptables 规则。 - Netfilter:在
POSTROUTINGhook 点处理nattable 里的 iptables 规则。 - 包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
- 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:
- 发送到一个本机 veth 设备,或者一个本机 service endpoint,
- 或者,如果目的 IP 是主机外,就通过网卡发出去。
Cilium eBPF 包转发路径
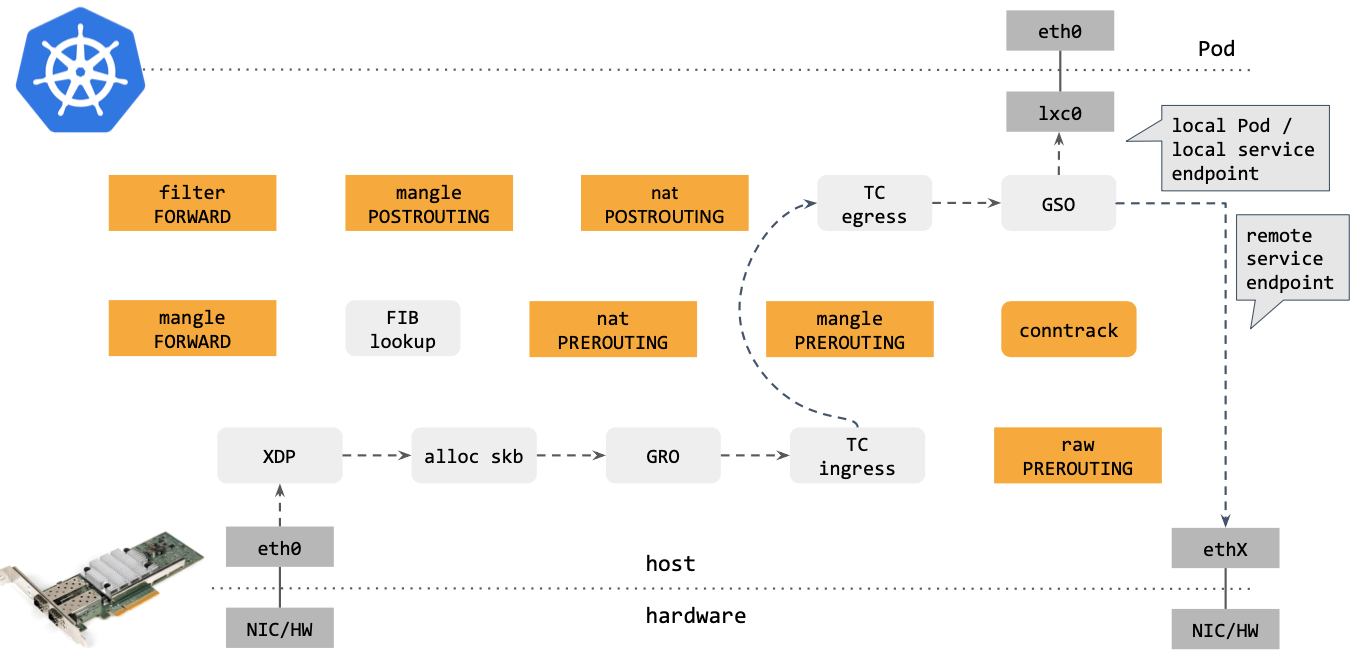
Cilium eBPF datapath 做了短路处理:从 tc ingress 直接 shortcut 到 tc egress,节省了 9 个中间步骤(总共 17 个)。更重要的是:这个 datapath 绕过了 整个 Netfilter 框架(橘黄色的框们),Netfilter 在大流量情况下性能是很差的。
去掉那些不用的框之后,Cilium eBPF datapath 长这样:
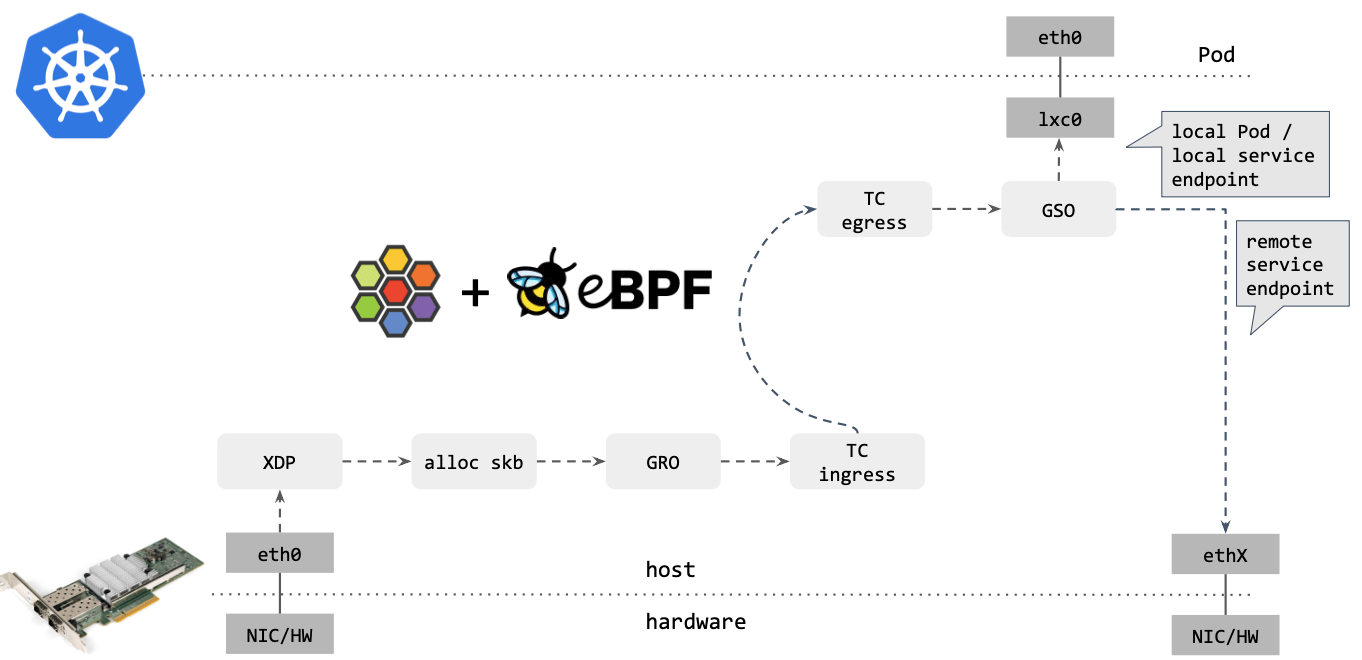
Cilium/eBPF 还能走的更远。例如,如果包的目的端是另一台主机上的 service endpoint,那你可以直接在 XDP 框中完成包的重定向(收包 1->2,在步骤 2 中对包 进行修改,再通过 2->1 发送出去),将其发送出去,如下图所示:

可以看到,这种情况下包都没有进入内核协议栈(准确地说,都没有创建 skb)就被转 发出去了,性能可想而知。
XDP 是 eXpress DataPath 的缩写,支持在网卡驱动中运行 eBPF 代码,而无需将包送 到复杂的协议栈进行处理,因此处理代价很小,速度极快。
Cilium 的 Service load balancing 设计
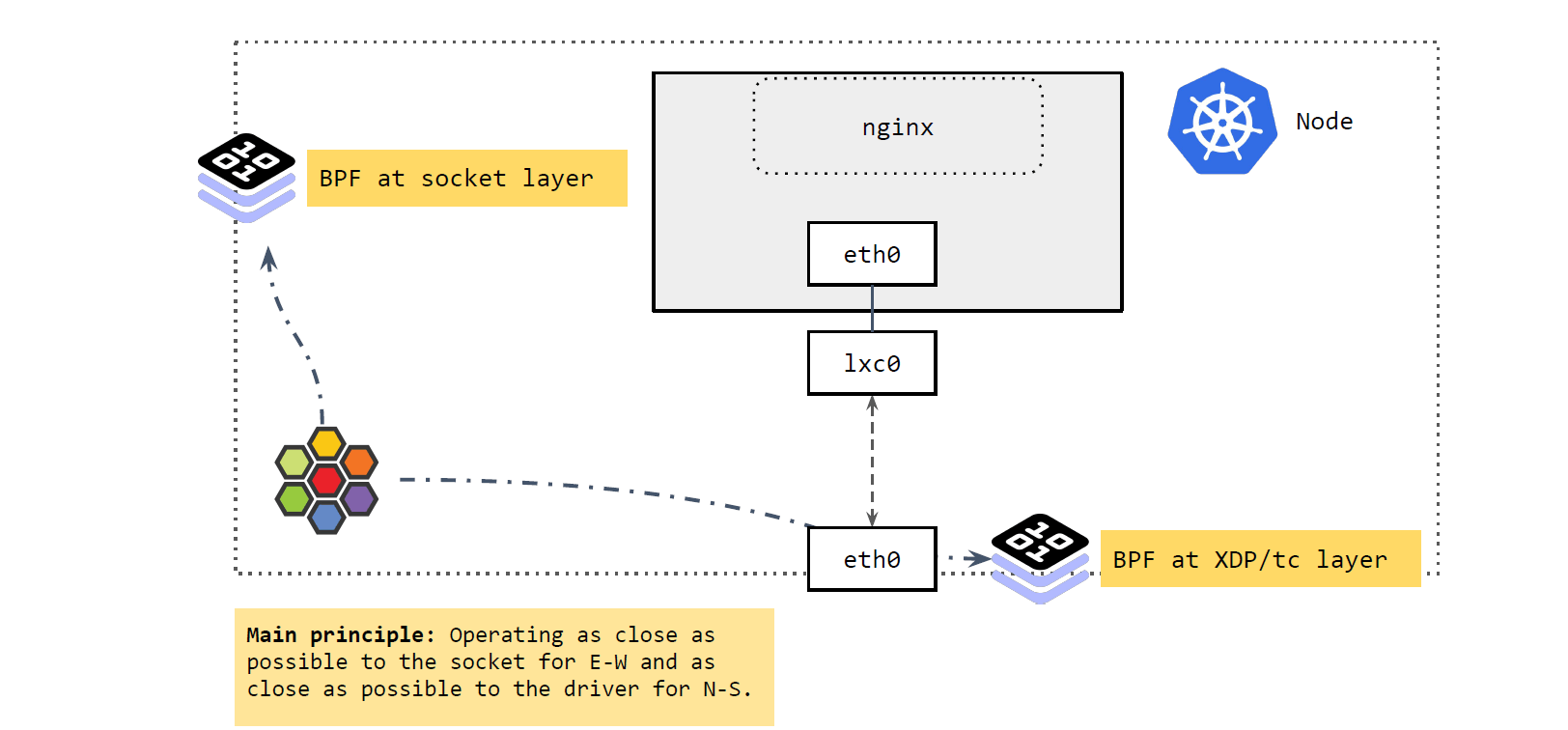
如上图所示,主要涉及两部分:
- 在 socket 层运行的 BPF 程序
- 在 XDP 和 tc 层运行的 BPF 程序
东西向流量
我们先来看 socker 层。
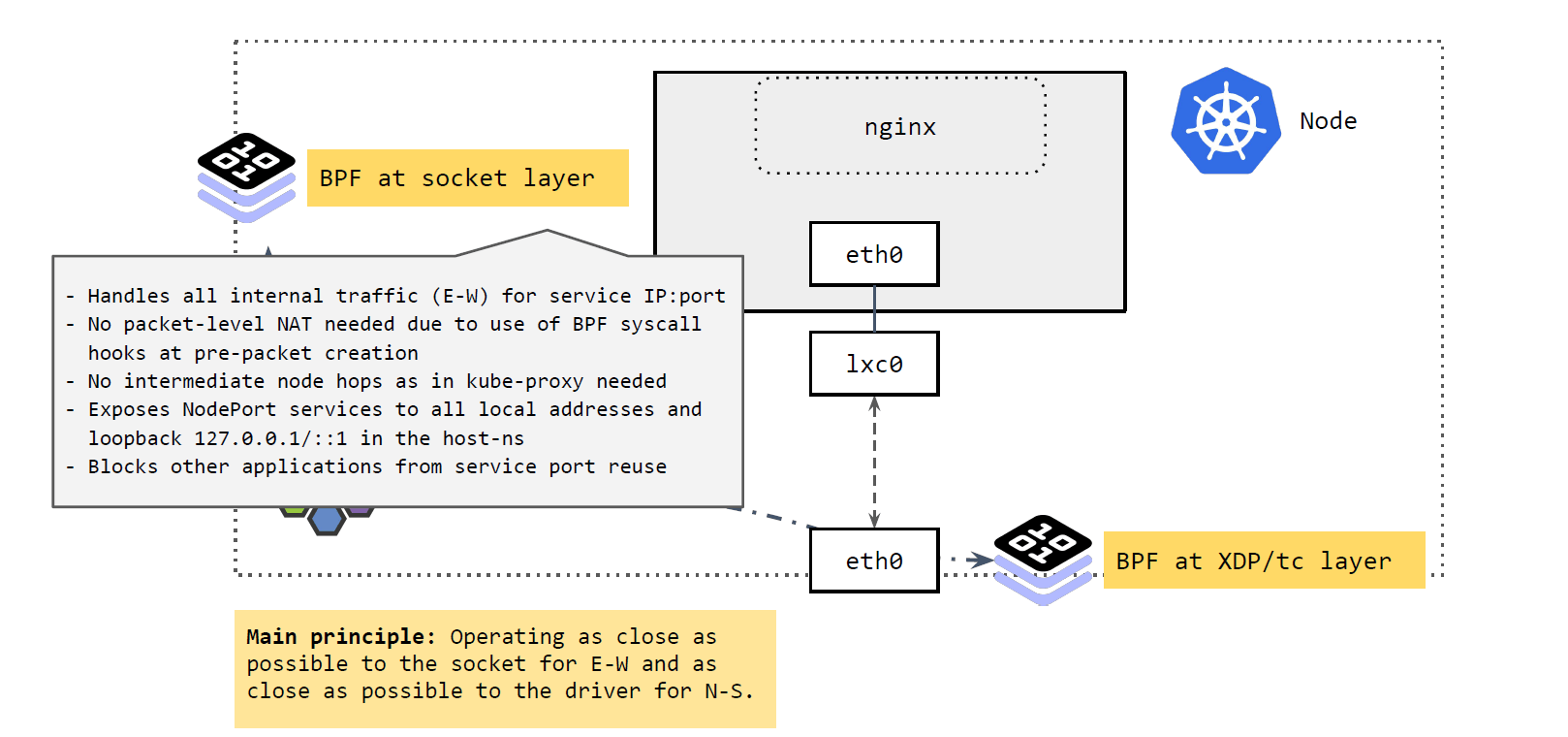
如上图所示,
Socket 层的 BPF 程序主要处理 Cilium 节点的东西向流量(E-W)。
- 将 Service 的
IP:Port映射到具体的 backend pods,并做负载均衡。 - 当应用发起 connect、sendmsg、recvmsg 等请求(系统调用)时,拦截这些请求, 并根据请求的
IP:Port映射到后端 pod,直接发送过去。反向进行相反的变换。
这里实现的好处:性能更高。
- 不需要包级别(packet leve)的地址转换(NAT)。在系统调用时,还没有创建包,因此性能更高。
- 省去了 kube-proxy 路径中的很多中间节点(intermediate node hops)
可以看出,应用对这种拦截和重定向是无感知的(符合 k8s Service 的设计)。
南北向流量
再来看从 k8s 集群外进入节点,或者从节点出 k8s 集群的流量(external traffic), 即南北向流量(N-S):
区分集群外流量的一个原因是:Pod IP 很多情况下都是不可路由的(与跨主机选用的网 络方案有关),只在集群内有效,即,集群外访问 Pod IP 是不通的。
因此,如果 Pod 流量直接从 node 出宿主机,必须确保它能正常回来。而 node IP 一般都是全局可达的,集群外也可以访问,所以常见的解决方案就是:在 Pod 通过 node 出集群时,对其进行 SNAT,将源 IP 地址换成 node IP 地址;应答包回来时,再进行相 反的 DNAT,这样包就能回到 Pod 了。
译者注
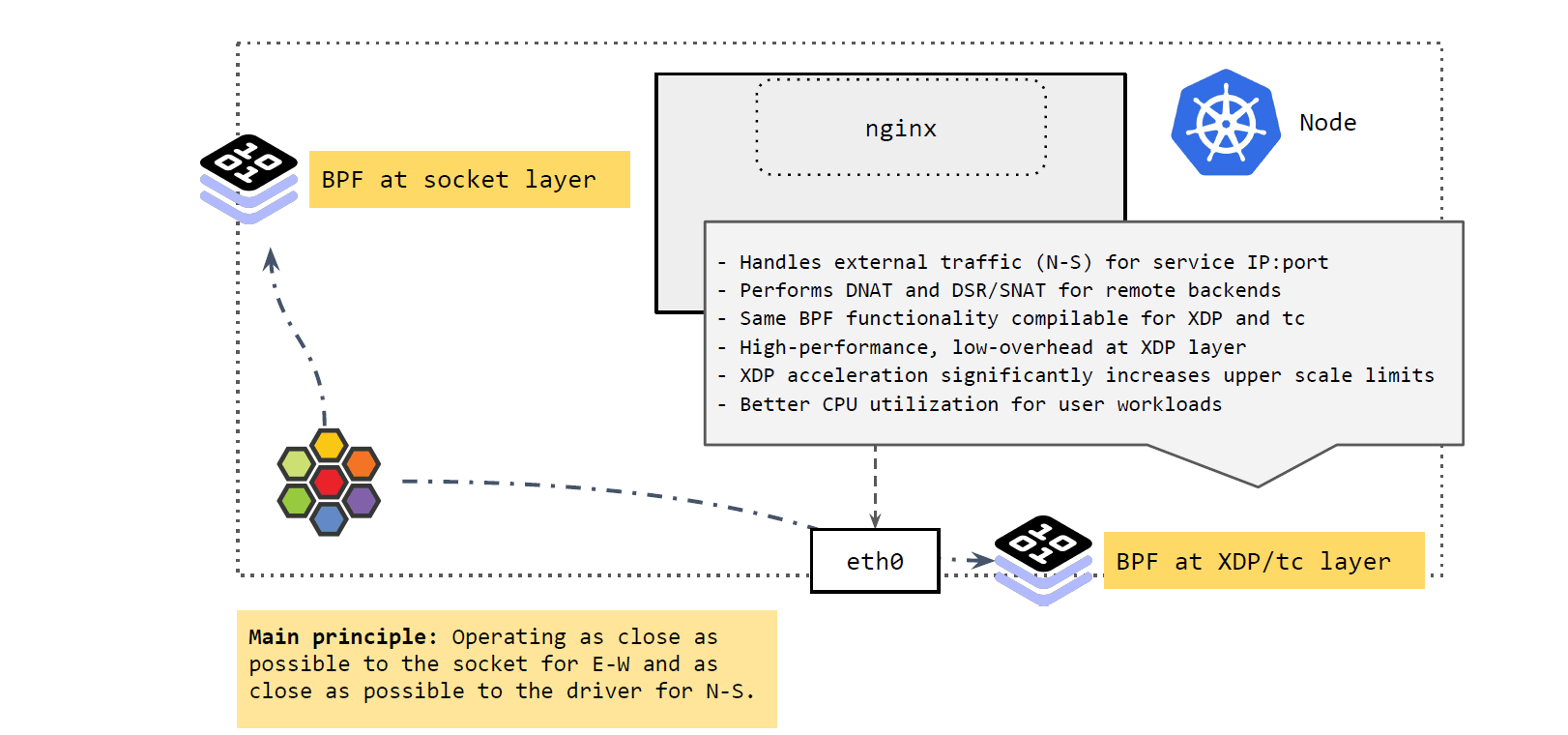
如上图所示,集群外来的流量到达 node 时,由 XDP 和 tc 层的 BPF 程序进行处理, 它们做的事情与 socket 层的差不多,将 Service 的 IP:Port 映射到后端的 PodIP:Port,如果 backend pod 不在本 node,就通过网络再发出去。发出去的流程我们 在前面 Cilium eBPF 包转发路径 讲过了。
这里 BPF 做的事情:执行 DNAT。这个功能可以在 XDP 层做,也可以在 TC 层做,但 在 XDP 层代价更小,性能也更高。
总结起来,这里的核心理念就是:
- 将东西向流量放在离 socket 层尽量近的地方做。
- 将南北向流量放在离驱动(XDP 和 tc)层尽量近的地方做。
eBPF 工具
eBPF 的开源项目的例子,这些项目提供了三方面的能力:网络、可观测性和安全。
网络
eBPF 程序可以连接到网络接口和内核的网络堆栈的各个点。在每个点上,eBPF 程序可以丢弃数据包,将其发送到不同的目的地,甚至修改其内容。这就实现了一些非常强大的功能。让我们来看看通常用 eBPF 实现的几个网络功能。
负载均衡
Cilium 项目作为一个 eBPF Kubernetes 网络插件更为人所知(我一会儿会讨论),但作为独立的负载均衡器,它也被用于大型电信公司和企业内部部署。同样,因为它能够在早期阶段处理数据包,而不需要进入到用户空间,它具有很高的性能。
Kubernetes 网络
CNCF 项目 Cilium 最初基于 eBPF 的 CNI 实现。它最初是由一群从事 eBPF 工作的内核维护者发起的,他们认识到 eBPF 在云原生网络中的应用潜力。它现在被用作谷歌 Kubernetes 引擎、亚马逊 EKS Anywhere 和阿里云的默认数据平面。
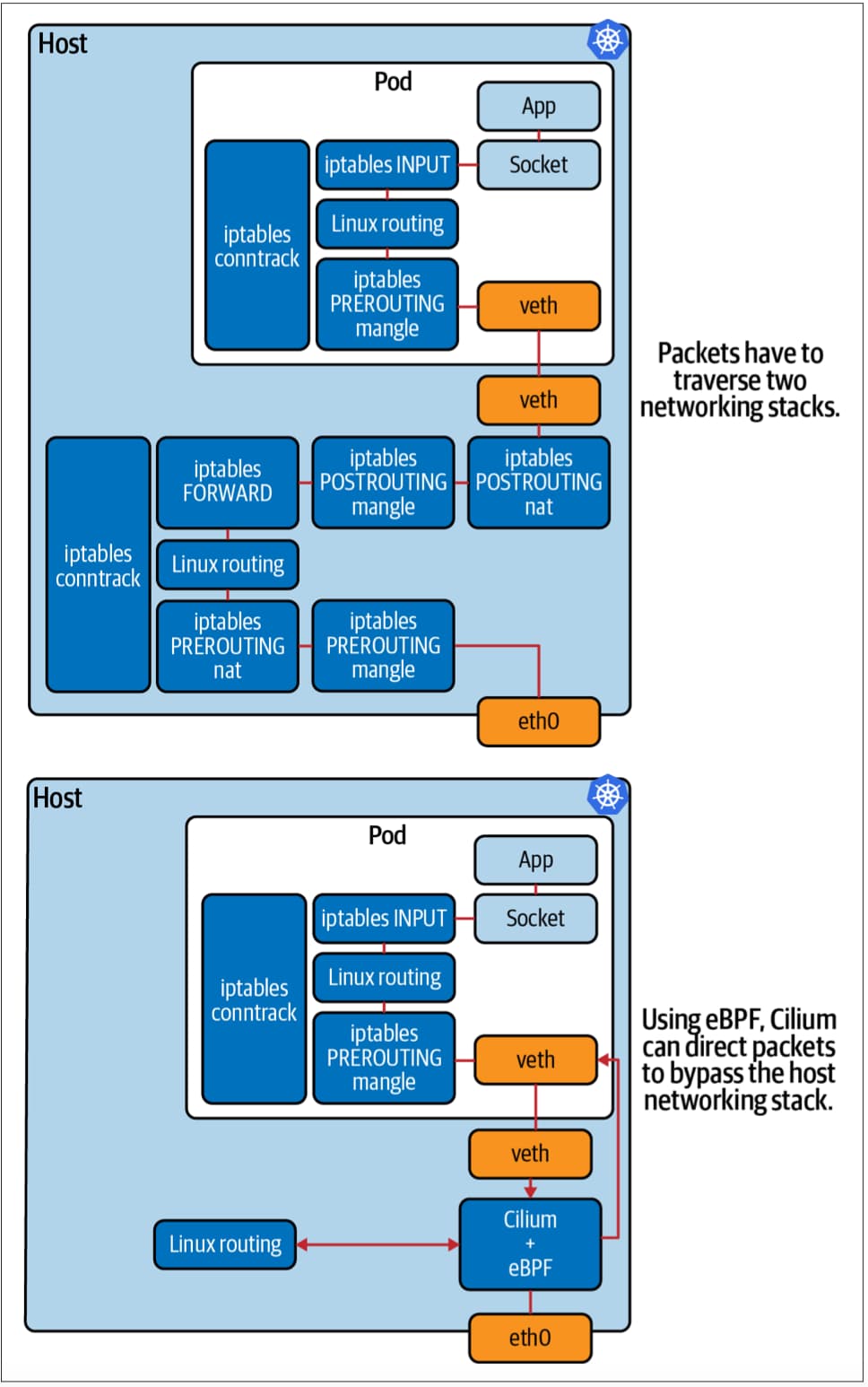
在云原生环境下,pod 在不断的启停,每个 pod 都会被分配一个 IP 地址。在启用 eBPF 网络之前,当 pod 启停的时候,每个节点都必须为它们更新 iptables 规则,以便在 pod 之间进行路由;而当这些 iptable 规则规模变大后,将十分不便于管理。如下图所示,Cilium 极大地简化了路由,仅需在 eBPF 中创建的一个简单的查找表,就可以获得 可观的性能改进。
用 eBPF 绕过主机网络堆栈
服务网格
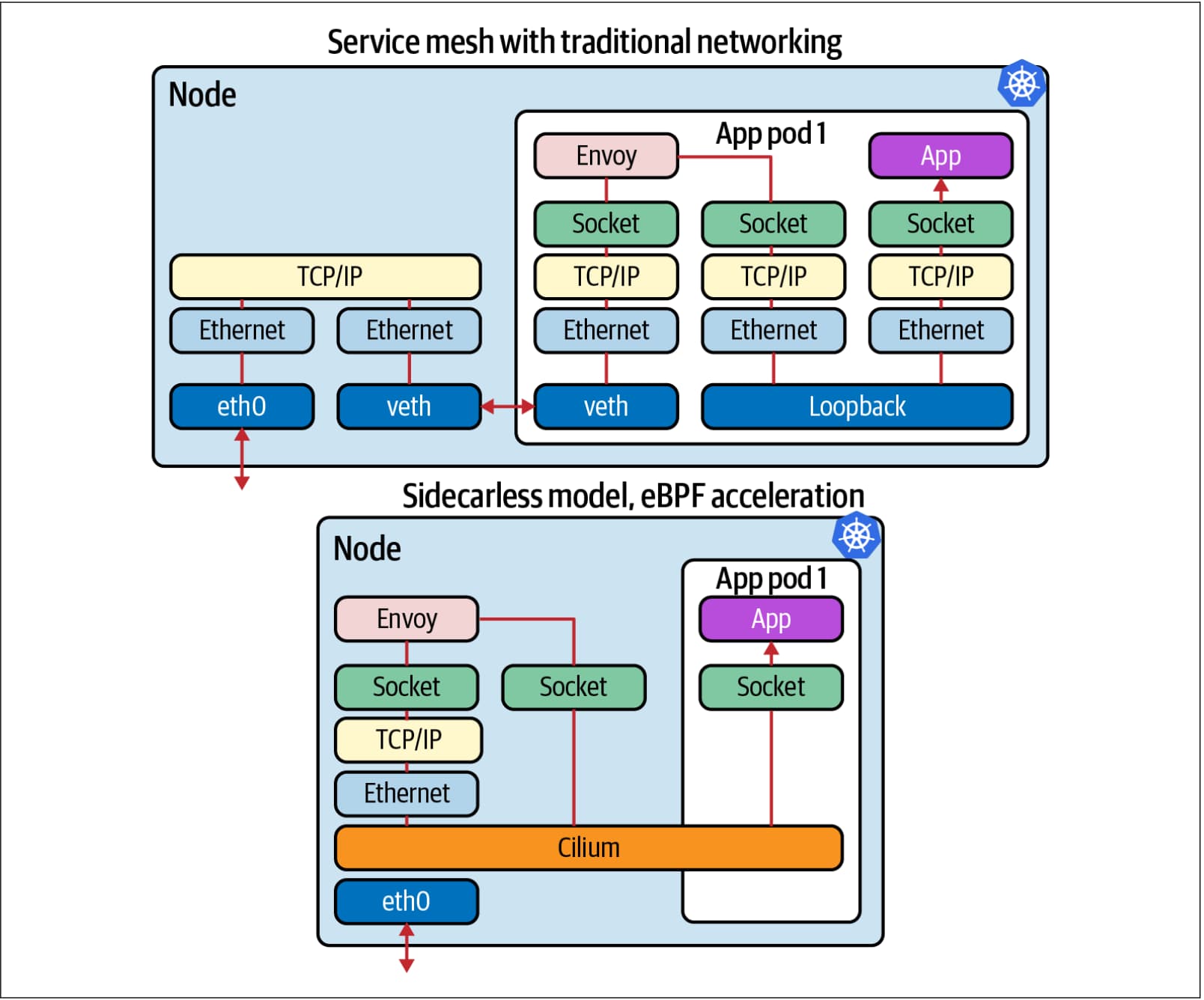
eBPF 作为服务网格数据平面的基础也是非常有意义的。许多服务网格在七层,即应用层运行,并使用代理组件(如 Envoy)来辅助应用程序。在 Kubernetes 中,这些代理通常以 sidecar 模式部署,每个 pod 中有一个代理容器,这样代理就可以访问 pod 的网络命名空间。
eBPF 有一个比 sidecar 模型更有效的方法。由于内核可以访问主机中所有 pod 的命名空间,我们可以使用 eBPF 连接 pod 中的应用和主机上的代理。eBPF 实现了服务网格的高效无 sidecar 模型,每个节点一个代理,而不是每个应用 pod 一个代理
可观测性
eBPF 程序可以获得对机器上发生的一切的可观测性。通过收集事件数据并将其传递给用户空间,eBPF 实现了一系列强大的可观测性工具,可以向你展示你的应用程序是如何执行和表现的,而不需要对这些应用程序做任何改变。
几年来,Brendan Gregg 在 Netflix 做了开创性的工作,展示了这些 eBPF 工具如何被用来 观测我们感兴趣的几乎任何指标,而且是大规模和高性能的。
新一代的项目和工具正在这项工作的基础上,提供基于 GUI 的观测能力。CNCF 项目 Pixie 可以让你运行预先写好的或自定义的脚本,通过一个强大的、视觉上吸引人的用户界面查看指标和日志。因为它是基于 eBPF 的,这意味着你可以自动检测所有应用程序,获得性能数据,而无需进行任何代码修改或配置。
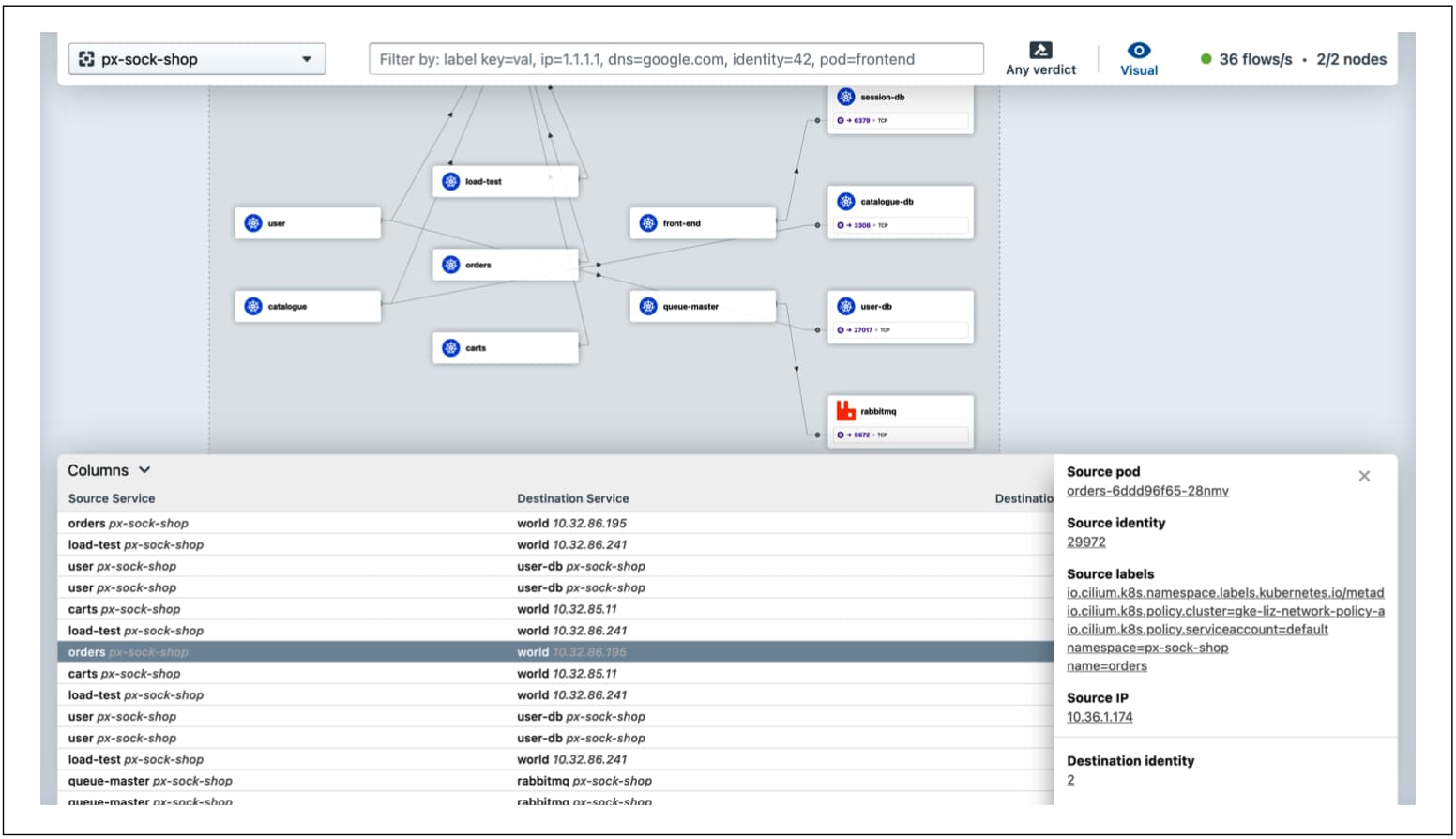
Cilium 的 Hubble 组件是一个具有命令行界面和用户界面的可观测性工具(如下图所示),它专注于 Kubernetes 集群中的网络流。
Cilium 的 Hubble 用户界面显示了 Kubernetes 集群中的网络流量
安全
有一些强大的云原生工具,通过使用 eBPF 检测甚至防止恶意活动来增强安全性。我将其分为两类:一类是确保网络活动的安全,另一类是确保应用程序在运行时的预期行为。
网络安全
由于 eBPF 可以检查和操纵网络数据包,它在网络安全方面有许多用途。基本原理是,如果一个网络数据包被认为是恶意的或有问题的,因为它不符合一些安全验证标准,就可以被简单地丢弃。eBPF 可以很高效的来验证这一点,因为它可以钩住内核中网络堆栈的相关部分,甚至在网卡上。这意味着策略外的或恶意的数据包可以在产生网络堆栈处理和传递到用户空间的处理成本之前被丢弃。
这里有一个 eBPF 早期在生产中大规模使用的一个例子 —— Cloudflare 的 DDoS(分布式拒绝服务)保护。DDoS 攻击者用许多网络信息淹没目标机,希望目标机忙于处理这些信息,导致无法提供有效工作。Cloudflare 的工程师使用 eBPF 程序,在数据包到达后立即对其进行检查,并迅速确定一个数据包是否是这种攻击的一部分,如果是,则将其丢弃。数据包不必通过内核的网络堆栈,因此需要的处理资源要少得多,而且目标可以应对更大规模的恶意流量。
eBPF 程序也被用于动态缓解 ”死亡数据包“ 的内核漏洞。攻击者以这样的方式制作一个网络工作数据包——利用了内核中的一个错误,使其无法正确处理该数据包。与其等待内核补丁的推出,不如通过加载一个 eBPF 程序来缓解攻击,该程序可以寻找这些特别制作的数据包并将其丢弃。这一点的真正好处是,eBPF 程序可以动态加载,而不必改变机器上的任何东西。
标准的 Kubernetes 网络策略规则适用于进出应用 pod 的流量,但由于 eBPF 对所有网络流量都有可视性,它也可用于主机防火墙功能,限制进出主机(虚拟机)的流量 。
eBPF 也可以被用来提供透明的加密,无论是通过 WireGuard 还是 IPsec 。在这里,透明 意味着应用程序不需要任何修改 —— 事实上,应用程序可以完全不知道其网络流量是被加密的。
运行时安全
eBPF 也被用来构建工具,检测恶意程序,防止恶意行为。这些恶意程序包括访问未经许可的文件,运行可执行程序,或试图获得额外的权限。
Tracee 是另一个使用 eBPF 的运行时安全开源项目。除了基于系统调用的检查之外,它还使用 LSM 接口。这有助于避免受到 TOCTTOU 竞争 条件的影响,因为只检查系统调用时可能会出现这种情况。Tracee 支持用 Open Policy Agent 的 Rego 语言定义的规则,也允许用 Go 定义的插件规则。
Cilium 的 Tetragon 组件提供了另一种强大的方法,使用 eBPF 来监控 容器安全可观测性的四个黄金信号:进程执行、网络套接字、文件访问和七层网络身份。这使操作人员能够准确地看到所有恶意或可疑事件,直击特定 pod 中的可执行文件名称和用户身份。例如,如果你受到加密货币挖矿的攻击,你可以看到到底是什么可执行程序打开了与矿池的网络连接,什么时候,从哪个 pod。这些取证是非常有价值的,可以了解漏洞是如何发生的,并使其容易建立安全策略,以防止类似的攻击再次发生。
eBPF和内核版本支持
https://github.com/brendangregg/bpf-perf-tools-book
eBPF 还在快速发展期,内核中的功能也日趋增强,一般推荐基于Linux 4.4+ (4.9 以上会更好) 内核的来使用 eBPF。部分 Linux Event 和 BPF 版本支持见下图
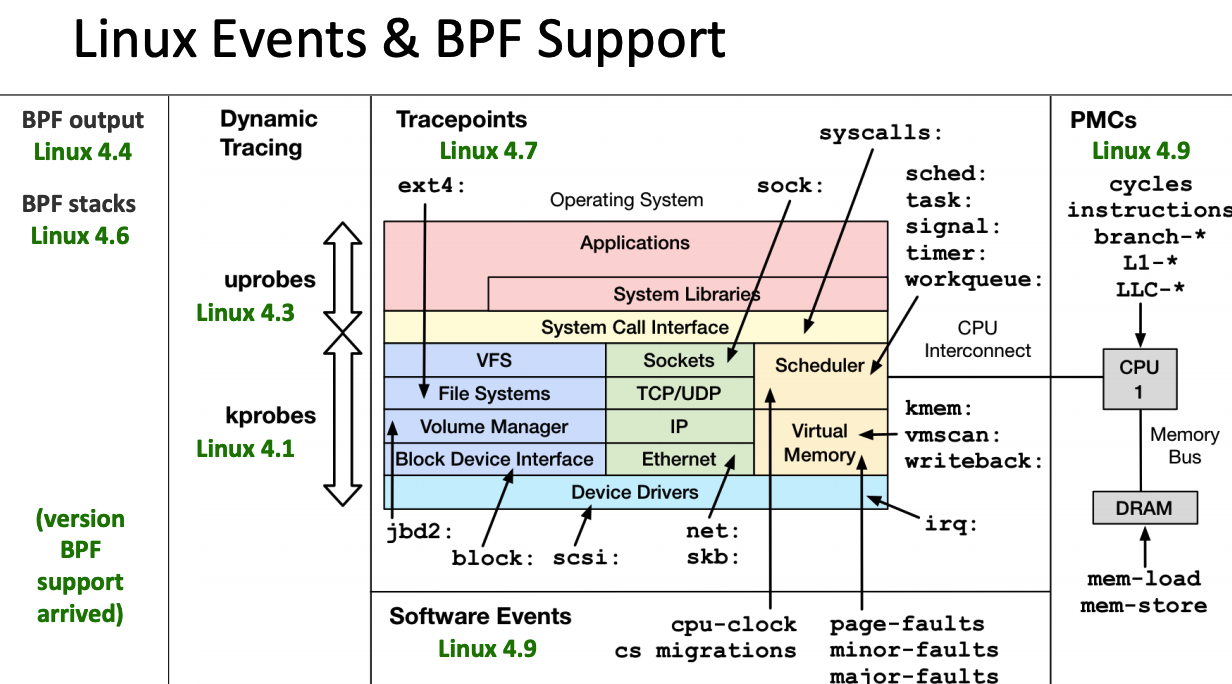
eBPF features by Linux version
插桩
动态
对内核函数动态插桩kprobes,用户函数动态插桩uprobes


静态
动态插桩随着内核或者软件版本升级,出现BPF工具不能工作。 tracepoint(内核跟踪点)和USDT(用户态静态插桩)

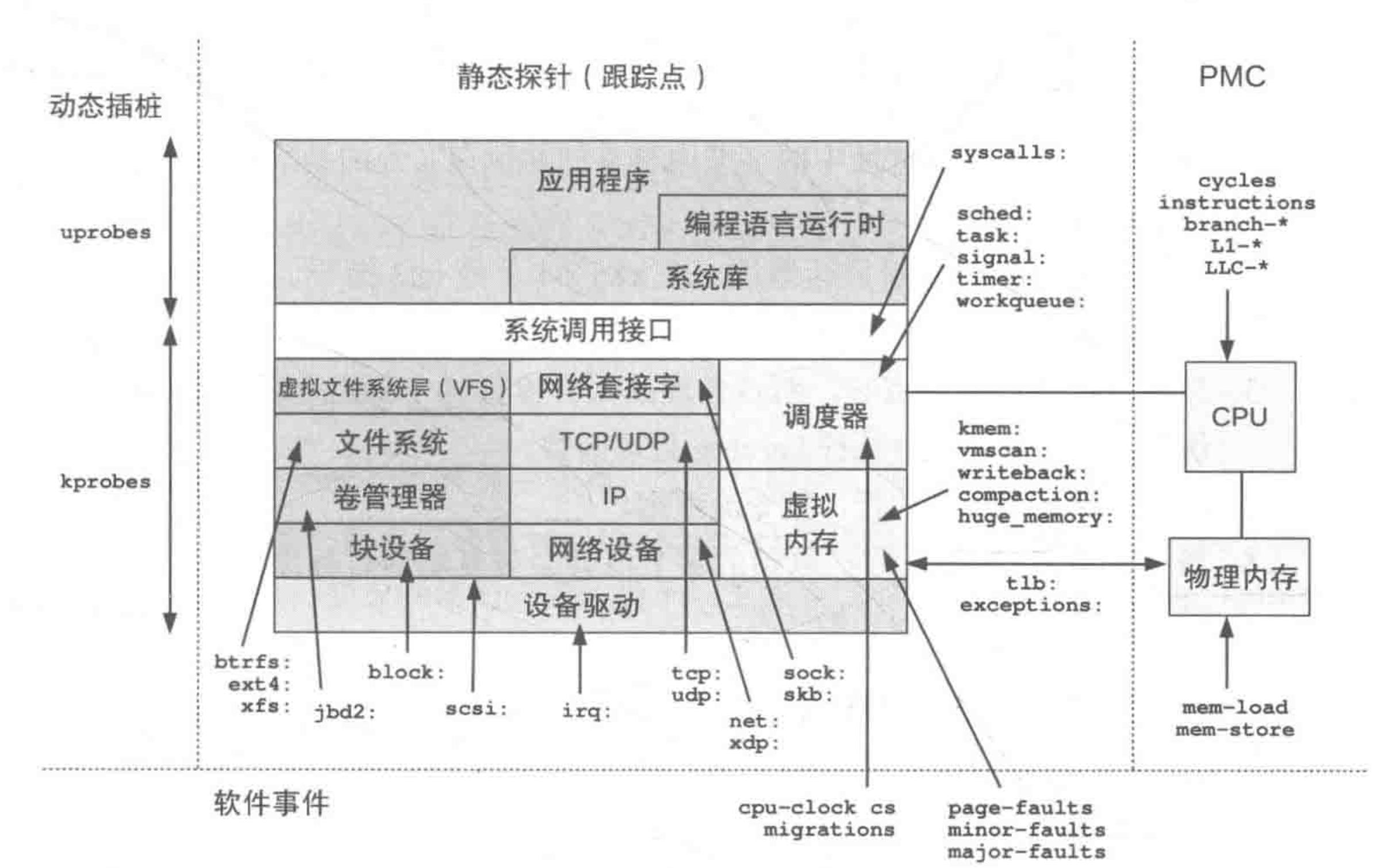

kprobe 接口

uprobe接口

tracing 工作原理


tracing接口

负载画像
- 负载是谁产生(进程ID,用户ID,进程名,IP地址)
- 为什么产生代码路径,调用栈,火焰图
- 负载组成是(IOPS 吞吐量 负载类型)
- 怎样随着时间发生变化
分析
- 从业务最高层开始分析
- 检查下一层
- 挑出线索