why
为了解决异构多云,让应用无感知运行在多云多集群。参考
解决问题
- 应用下发的模型是什么样的?
- 应用的模型怎样被调度到不同的集群?
- 在不同的集群下发的模型怎样做到差异化?
- 怎样对需要计算资源的工作负载调度到不同集群,来均衡所有集群的资源?
- 应用下发的模型怎样做到多集群,多机房,多地的灾备和双活的能力?
- 多集群的统一访问入口的网关怎样建设?
- 跨集群的内部服务发现怎样建设,以及跨集群的网络连通?
- 怎样统一内部的访问方式的地址,举例全局域名?
- 怎样在不同的集群间,保证镜像的一致,以及数据的同步?
- 怎样设计统一的下发流程,举例不同环境的下发流程可能会不一样?
- 怎样从顶层设计和规划资源的分配和使用?
- 怎样打通多云部署带来的统一观测性能力的建设?
- 怎样设计和解决在多集群的背景下,有状态服务的调度机制和访问机制?
- 怎样解决云边场景以及混合云的统一应用管理能力?
karmada架构
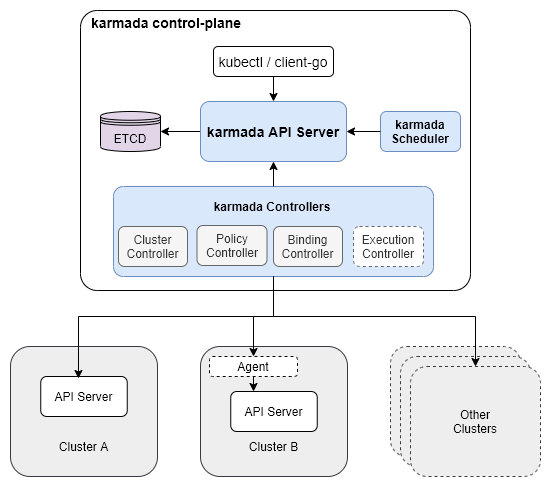
控制平面的组件
-
Karmada API Server
和 Kubernetes 集群中的 api server 是一样的角色,负责处理 api 的请求,以及连接到 etcd 数据源持久化元数据,在这个过程中所有的 controllers 和 scheduler 会和 api server 进行通信,类似 Kubernetes 里的 api server 和 controllers 以及 scheduler 的关系。
-
Karmada Controller Manager
主要负责初始化所有相关的 controllers,以及启动所有的 controllers,让所有的 controllers 去工作起来。
-
Karmada Scheduler
完成在资源对象的调度
-
ETCD
Karmada 控制器管理器运行各种控制器,它们监视 karmada 对象,然后与底层集群的 API 服务器通信以创建常规 Kubernetes 资源。
-
Cluster Controller: 将 kubernetes 集群附加到 Karmada,通过创建集群对象来管理集群的生命周期。
-
Policy Controller: 监视 PropagationPolicy 对象。添加 PropagationPolicy 对象时,控制器会选择与 resourceSelector 匹配的一组资源,并为每个资源对象创建 ResourceBinding。
-
Binding Controller: 监视 ResourceBinding 对象并使用单个资源清单创建与每个集群对应的 Work 对象。
-
Execution Controller: 监视工作对象。当 Work 对象被创建时,控制器会将资源分配给成员集群
karmada agent
Karmada 支持Push和Pull两种模式来管理成员集群。Push和模式之间的主要区别在于Pull部署清单时访问成员集群的方式。
-
push模式:Karmada 控制平面直接访问member 集群的kube-apiserver,获取集群状态和部署资源。
1
kubectl karmada join member1 --kubeconfig=<karmada kubeconfig> --cluster-kubeconfig=<member1 kubeconfig> -
pull模式:Karmada 控制平面不会访问成员集群,而是将其委托给一个名为
karmada-agent- 集群注册到 Karmada(创建
Cluster对象) - 维护集群状态并向 Karmada 报告(更新
Cluster对象的状态) - 创建 Karmada Execution空间(命名空间,
karmada-es-<cluster name>),从里面观察清单并部署到为其服务的集群 - 启动 4个 controller,包括 cluster status controller, execution controller,work status controller, service export controller
- 集群注册到 Karmada(创建
我们主要使用pull模式部署,考虑在云边的场景下, Host Cluster 和Member Cluster存在网络隔离。
karmada简介
Karmada 是 CNCF 的云原生项目,主要的能力是纳管多个 Kubernetes 集群,以及基于原生的 Kubernetes 的资源对象,将其下发到多个集群。对于一些有计算资源需求的 Deployment,Job 等 workload 具体副本数调度能力,让不同的 workload 按照一些的策略运行在不同的集群上。以此来达到多云分发的能力的这么一个项目。
Karmada 本身需要运行在 Kubernetes 集群中
-
Host Cluster (宿主集群)
主要是用来运行 Karmada 控制平面的组件,其中包含 Karmada 的 etcd,karmada-api server, karmada-controller manager, Kubernetes controller manager,karmada-scheduler,karmada-webhook, karmada-scheduler-estimator 等控制面的组件。
-
Member Cluster
负责真正运行工作负载的集群,会真正运行业务的容器、一些 Kubernetes 的资源对象、存储、网络、dns 等,同时对于 pull 模式的部署方式,还会运行 Karmada 的 agent 组件,用于和控制面组件通信,完成工作负载的下发能力。
概念介绍
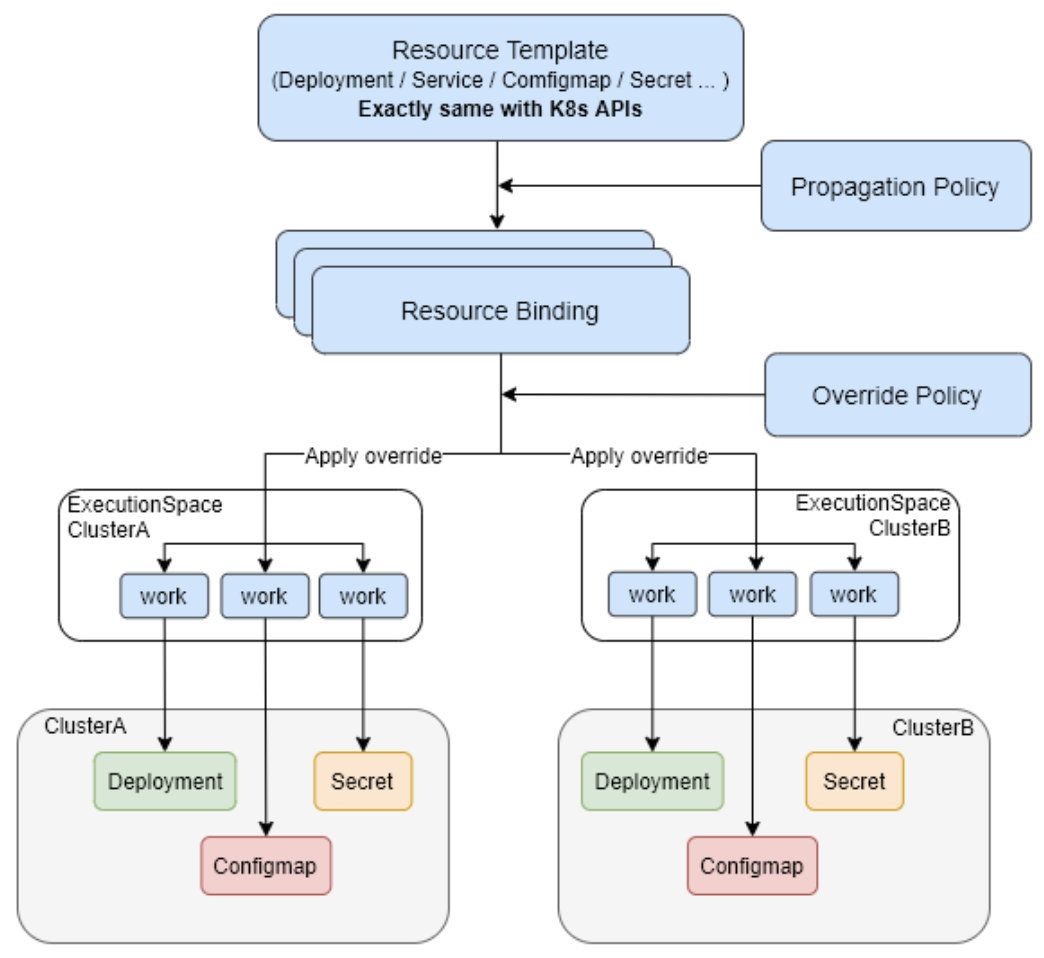
ResourceTemplate
在 Karmada 中没有真正的 crd 类型是 ResourceTemplate,这里的ResourceTemplate 只是对 Karmada 可分发的资源对象的一种抽象,这里的Resource 包含 Kubernetes 中所有支持的资源对象的类型,包括常见的 Deployment,Service,Pod,Ingress,PVC,PV, Job 等等,同时也原生的支持 CRD。
Cluster
Cluster 对象代表一个完整的,单独的一套 Kubernetes 集群,是可用于运行工作负载的集群的抽象和连接配置。在 Karmada 中,集群不仅仅有 spec,还有 status,这个 status 中描述了集群的基本信息,支持的 crd,以及集群的可用物理资源的统计等,用于在后续的调度器中使用这些信息进行调度处理。
策略
-
PropagationPolicy
为了定义资源对象被下发的策略,如下发到哪些集群,以及下发到这些集群中的需要计算资源的工作负载的副本数应该怎样分配。
resource selector这个选择器 让PropagationPolicy 知道自己的策略是作用于哪些资源对象
-
OverridePolicy
定义在下发到不同集群中的配置,例如不同的集群所对应的镜像仓库的地址是不一样的,那就需要设置在不同集群中的工作负载的镜像地址是不一样,例如在不同的环境下,需要设置不同的环境变量等。
OverridePolicy 的作用时机是在 PropagationPolicy 之后,以及在真正在下发到集群之前,主要处理逻辑是 binding controller 中处理的,会在后续的篇幅中提到。其中可以使用的 override 的能力目前包括 Plaintext,ImageOverrider,CommandOverrider,ArgsOverrider 这几种,用来完成不同集群的差异化配置能力。同样,OverridePolicy 也会通过 resource selector 的机制来匹配到需要查建议配置的资源对象。
1 | |
ResourceBinding
ResourceBinding 这个 crd 不是用于给最终用户使用的,而是 Karmada 自身机制工作需要的,主要的用途是说明了某一个资源被绑定到了哪个集群上了,这个和集群绑定的逻辑是在 detector 的 PropagationPolicy 的 controller 中来控制,可以理解成 ResourceBinding 是 PropagationPolicy 派生出来的一个 cr 对象。
同时 Karmada 的调度器的处理对象就是以一个 ResourceBinding 为处理单元,在此基础上来完成资源对象所需要副本数的计算和调度,最终会由 binding controller 完成对 ResourceBinding 的处理,从而生成 Work 对象,同步下发到对应的集群上。
1 | |
Execution Namespace
在 Karmada 的控制平面中,会为每一个被纳管的集群创建一个集群相关的 namespace,这个 namespace 中存放的资源对象是 work。每一个和这个集群相关的 Kubernetes 资源对象都会对应到这个 namespace 下的一个 work。
举例,在 Karmada 的控制平面创建了一个 service 资源对象,同时通过 PropagationPolicy 下发到两个集群中,那在每一个集群对应的 execution namespace 中都会有一个 work 对象对应到当前集群需要负责的 service对象上。
1 | |
work
Work 这个对象代表了所有资源对象,以及所有资源对象需要下发到多个集群的时候所对应的业务模型。
举例来说,一个 Deployment 需要下发到两个集群中去,那对应到这个 Deployment 的 work 的对象就会有两个,因为 work 是集群单位的对象,主要的作用就是对应和代表一个资源对象在一个集群中的逻辑对象。这个逻辑对象 (work),它保存在控制平面。这里就是 Karmada 在做多集群下发中完成 Host Cluster 和 member Cluster 之间真正业务能力的体现。
跨集群服务发现
ServiceImport 的作用是配合 ServiceExport 来完成跨集群的服务发现,要想在某一个集群中去发现另一个集群的服务,除了要在暴露服务的集群中创建 ServiceExport,还要在需要发现和使用这个服务的集群中,创建 ServiceImport 对象,以此来在集群中发现其它集群的服务,和使用这个其它集群的服务。
ServiceExport不是 Karmada 自己的 CRD,而是 Kubernetes 社区在解决跨集群服务发现的场景下定义的一套 mcs api 规范。
至于在这个集群中是怎样发现的,以及怎样访问的,是不同的方案提供商来实现的,这了会涉及到 Kubernetes 中已有资源对象EndpointSlice
Submariner
Karmada使用 Submariner 连接成员集群之间的网络,Submariner将连接的集群之间的网络扁平化,并实现 Pod 和服务之间的 IP 可达性,与网络插件 (CNI) 无关。可以其他实现了MCS的组件替换Submariner。
基本架构
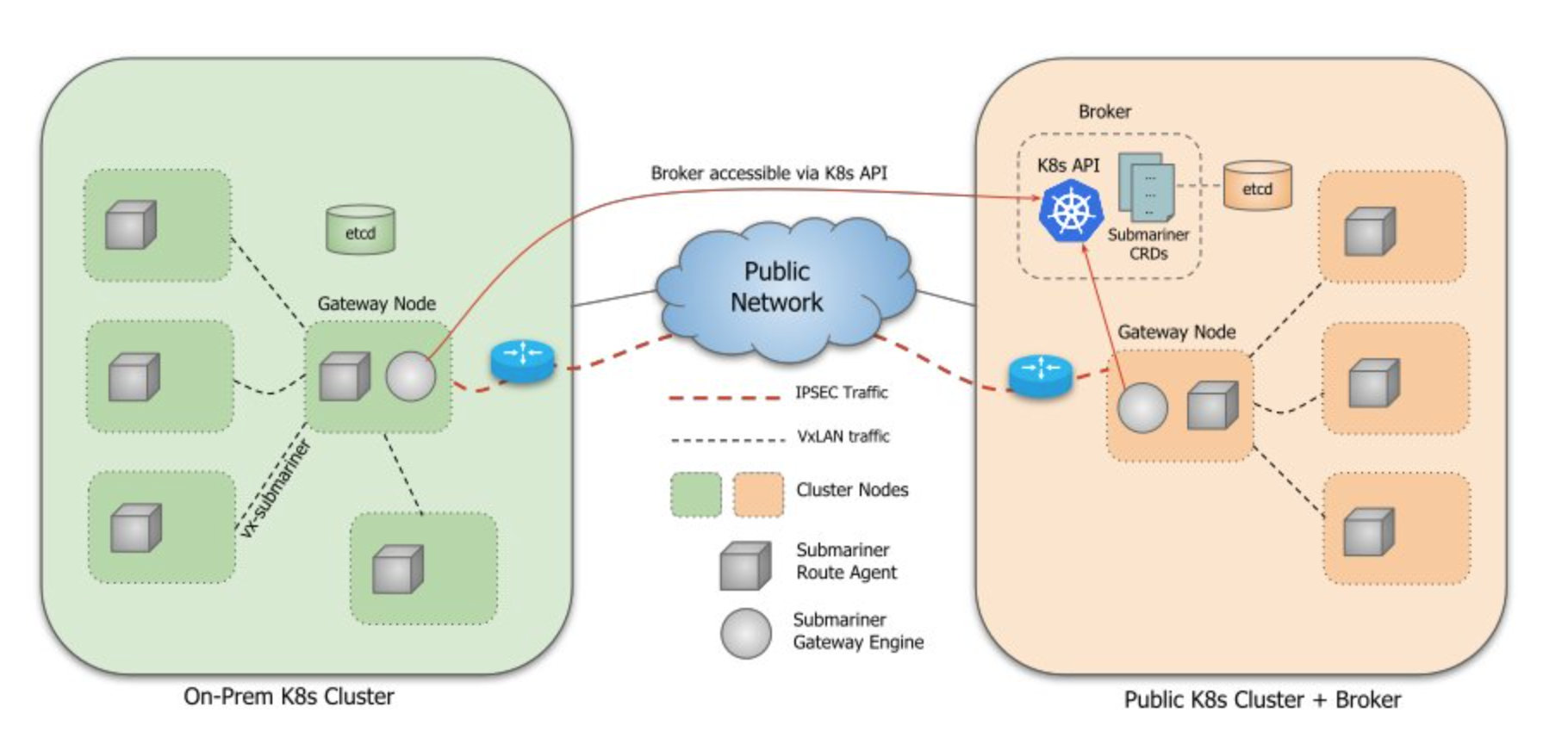
-
broker
给submariner-operator之间交互信息的crd
-
submariner-operator
- gateway 负责建立到其他集群的安全隧道
- routeragent 将跨集群流量从所有节点路由到活动的网关引擎节点。
- lighthouse 为多集群环境提供DNS发现
broker
Broker 是一个 API,所有参与的集群都可以访问,其中两个对象通过 CRD 交换在.submariner.io
Broker 必须部署在单个 Kubernetes 集群上。Submariner 连接的所有 Kubernetes 集群必须可以访问该集群的 API 服务器。它可以是专用集群,也可以是连接的集群之一。
Submariner 使用中央代理组件来促进部署在参与集群中的网关引擎之间的元数据信息交换。Broker 基本上是一组由 Kubernetes 数据存储支持的自定义资源定义 (CRD)。Broker 还定义了一个 ServiceAccount 和 RBAC 组件,以使其他 Submariner 组件能够安全地访问 Broker 的 API。没有使用 Broker 部署的 Pod 或服务。
Submariner 定义了两个通过 Broker 交换的 CRD:Endpoint和Cluster. CRD 包含有关集群中活动网关引擎的Endpoint信息,例如其 IP,集群相互连接所需的信息。CRD 包含有关原始集群的Cluster静态信息,例如其 Service 和 Pod CIDR。
Broker 是部署在集群上的单例组件,其 Kubernetes API 必须可供所有参与的集群访问。如果同时存在本地集群和公共集群,Broker 可以部署在公共集群上。Broker 集群可以是参与集群之一,也可以是未部署其他 Submariner 组件的独立集群。每个参与集群中部署的网关引擎组件都配置有安全连接到代理集群 API 的信息。
Broker 集群的可用性不会影响参与集群上 dataplane 的操作,即当 Broker 不可用时,dataplane 将继续使用最后一个已知信息路由流量。但是,在此期间,控制平面组件将无法向其他集群发布新信息或更新信息,也无法从其他集群了解新信息或更新信息。当与 Broker 重新建立连接时,每个组件将自动与 Broker 重新同步其本地信息,并在必要时更新数据平面。
Endpoint
1 | |
Cluster
1 | |
GateWay
网关引擎组件部署在每个参与的集群中,负责建立到其他集群的安全隧道。
- an IPsec implementation using Libreswan. This is currently the default.
- an implementation for WireGuard (via the wgctrl library).
- an un-encrypted tunnel implementation using VXLAN.
Gateway和broker通信,以将其资源Endpoint和Cluster资源通告给连接到代理的其他集群,同时确保它是Endpoint其集群的唯一。Gateway也会在 Broker 上建立一个监视,以了解其他集群所通告的活动Endpoint和 Cluster。一旦两个集群知道彼此的信息Endpoints,它们就可以建立一个安全的隧道,通过该隧道可以路由流量。
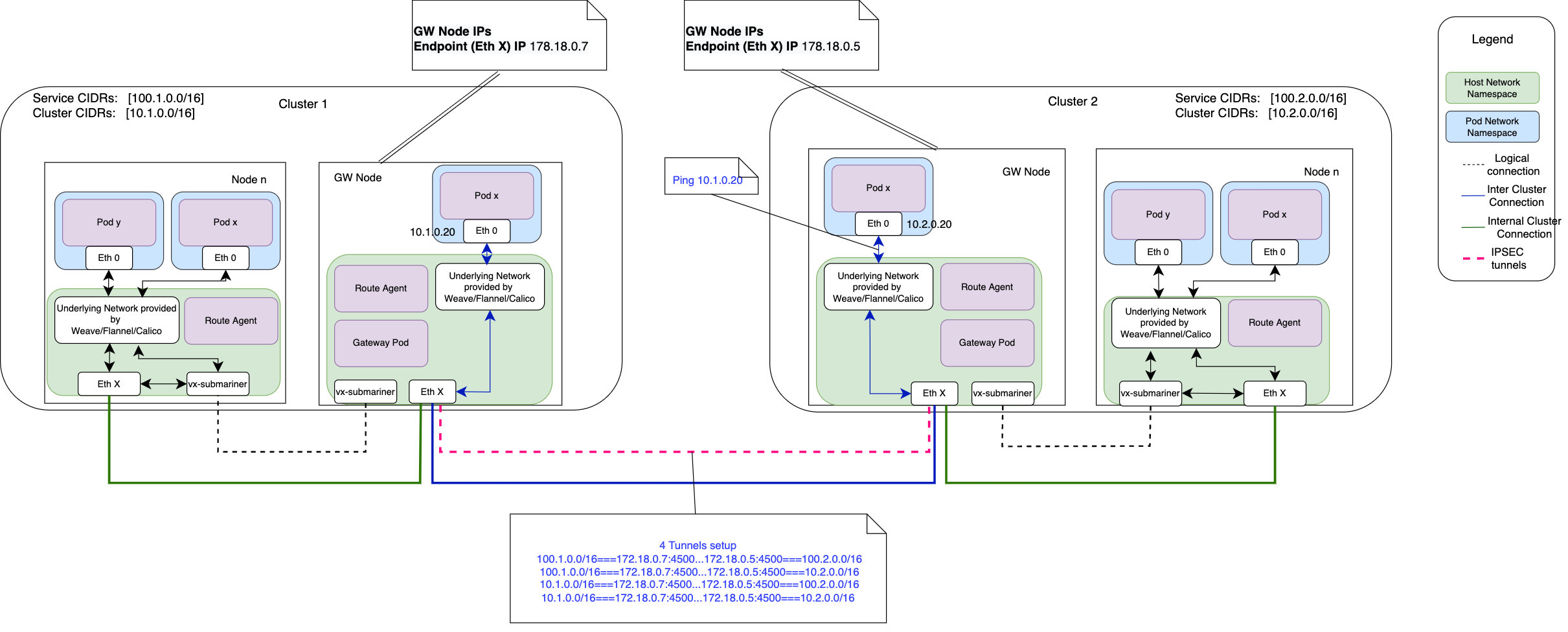
连接两个集群时,网关必须在其公共或私有 IP 地址和封装端口上至少有单向连接。这是在集群之间创建隧道所必需的。默认封装端口是4500/UDP
In this case, Libreswan is configured to create 4 IPsec tunnels to allow for:
- Pod subnet to Pod subnet connectivity
- Pod subnet to Service subnet connectivity
- Service subnet to Pod subnet connectivity
- Service subnet to Service subnet connectivity
容灾
Gateway Engine 部署为 DaemonSet,配置为仅在标有 的节点上运行submariner.io/gateway=true。
网关引擎的实例在集群中特定指定的节点上运行,其中可能有多个节点用于容错。Submariner 支持网关引擎组件的主动/被动高可用性,这意味着集群中一次只有一个活动网关引擎实例。他们执行领导者选举过程以确定活动实例,其他人在待机模式下等待准备好在活动实例失败时接管。
如果活动网关引擎发生故障,则其他指定节点之一上的另一个网关引擎将获得领导权并执行协调以宣传其Endpoint并确保它是唯一的Endpoint。远程集群将Endpoint通过 Broker 获知新的并建立新的隧道。同样,在本地集群中运行的 Route Agent Pod 会自动更新每个节点上的路由表,以指向集群中新的活动网关节点。
网关引擎持续监控连接集群的运行状况。它定期 ping 每个集群并收集统计数据,包括基本连接、往返时间 (RTT) 和平均延迟。此信息在Gateway 资源中更新。每当网关引擎检测到对特定集群的 ping 失败时,它的连接状态都会被标记为错误状态。服务发现使用此信息来避免服务发现期间不健康的集群。
RouterAgent
RouterAgent了解本地信息Endpoint并设置必要的基础架构,以将跨集群流量从所有节点路由到活动的网关引擎节点。
Route Agent 组件在每个参与集群的每个节点上运行,它负责在现有的 Kubernetes CNI 插件之上设置必要的主机网络元素。Route Agent 接收检测到的 CNI 插件作为其配置的一部分。
kube-proxy iptables
Route Agent 负责设置 VXLAN 隧道并将跨集群流量从节点路由到集群的活动网关引擎,后者随后将流量发送到目标集群。
RouterAgent使用Endpoint从其他集群同步的资源来配置路由并编写必要的 iptables 规则以启用完整的跨集群连接。
服务发现
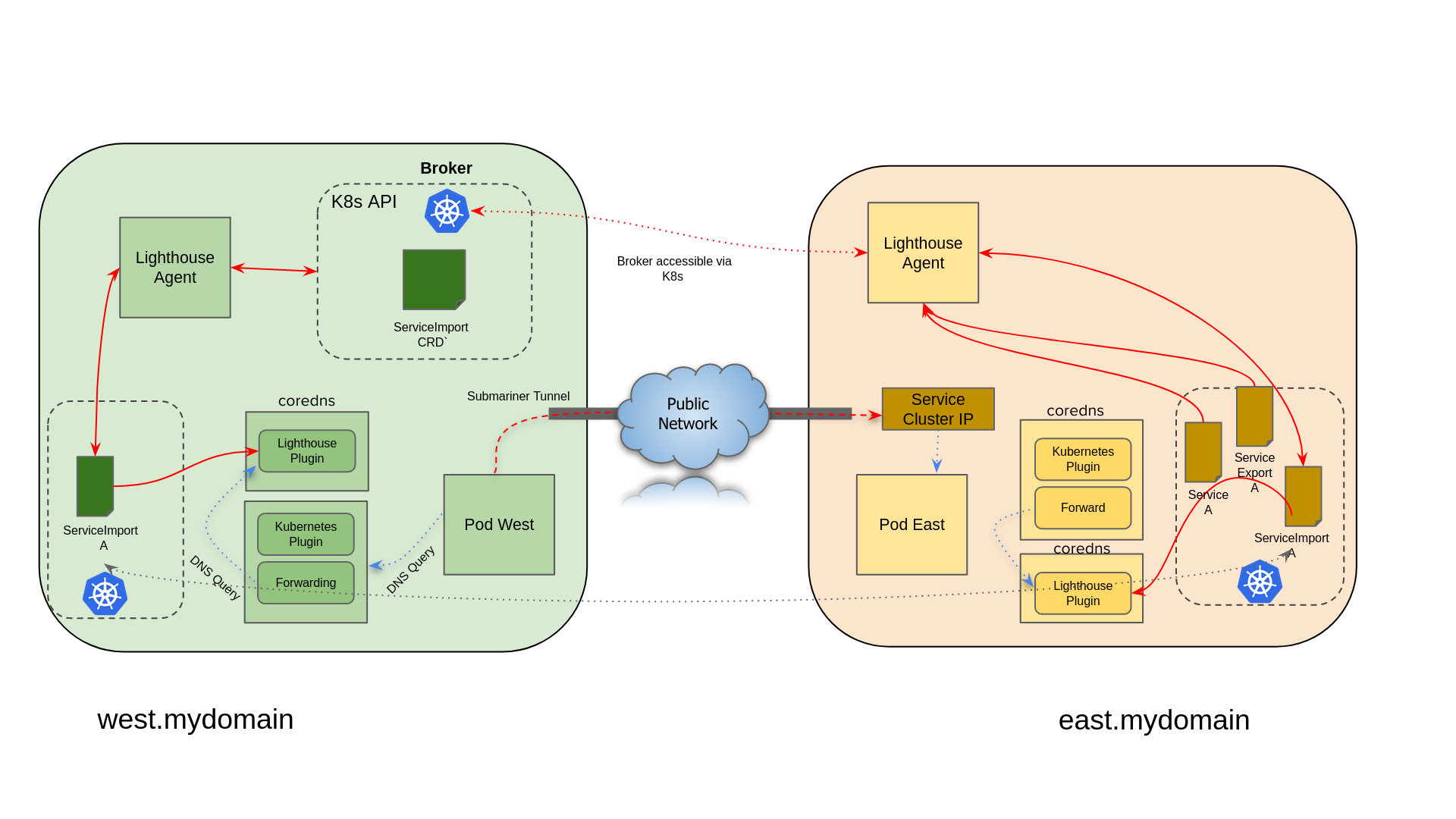
Lighthouse为使用Submariner 的k8s多集群环境提供DNS发现,实现MCS API
Lighthouse Agent 原理
- Lighthouse Agent 连接到 Broker 的 Kubernetes API 服务器。
- 对于本地集群中已创建 ServiceExport 的每个 Service,Agent 都会创建相应的 ServiceImport 资源并将其导出到 Broker 以供其他集群使用。
- 对于从另一个集群导出的 Broker 中的每个 ServiceImport 资源,它会在本地集群中创建它的副本。
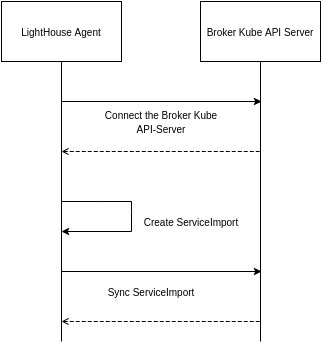
Lighthouse DNS 原理
Lighthouse DNS 服务器作为拥有域的外部 DNS 服务器运行clusterset.local。CoreDNS 配置为将发送到 Lighthouse DNS 服务器的任何请求转发到clusterset.localLighthouse DNS 服务器。
1 | |
该服务器使用控制器分发的 ServiceImport 资源进行 DNS 解析。Lighthouse DNS 服务器支持使用 A 记录和 SRV 记录的查询。
- Pod 尝试使用域名解析服务名称
clusterset.local。 - CoreDNS 将请求转发到 Lighthouse DNS 服务器。
- Lighthouse DNS 服务器将使用其 ServiceImport 缓存来尝试解析请求。
- 如果记录存在,则返回,否则返回 NXDomain 错误。
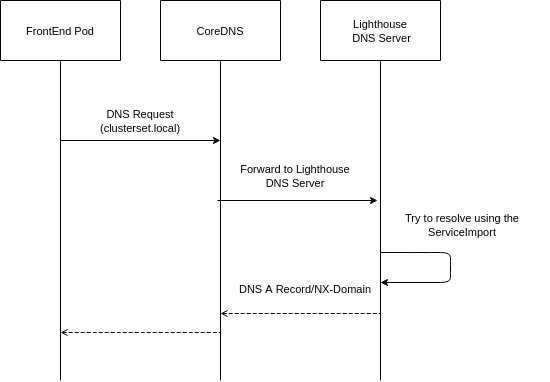
GLOBALNET CONTROLLER
集群之间不重叠的 Pod 和服务 CIDR。这是为了防止路由冲突。对于地址确实重叠的情况,可以设置globalnet。
An example of three clusters configured to use with Submariner (without Globalnet) would look like the following:
默认情况下,Submariner 的一个限制是它不处理跨集群的重叠 CIDR(ServiceCIDR 和 ClusterCIDR)。每个集群必须使用不同的 CIDR,这些 CIDR 不会与将成为 ClusterSet 一部分的任何其他集群冲突或重叠。
这在很大程度上是有问题的,因为大多数实际部署使用集群的默认 CIDR,因此每个集群最终都使用相同的 CIDR。更改现有集群上的 CIDR 是一个非常具有破坏性的过程,需要重新启动集群。所以 Submariner 需要一种方法来允许具有重叠 CIDR 的集群连接在一起。
为了支持连接集群中的重叠 CIDR,Submariner 有一个名为 Global Private Network 的组件 Globalnet ( globalnet)。这个 Globalnet 是一个虚拟网络,专门用于支持具有 Global CIDR 的 Submariner 的多集群解决方案。
每个集群都从这个虚拟全球专用网络中获得一个子网,配置为新的集群参数GlobalCIDR(例如 242.0.0.0/8),该参数可在部署时进行配置。globalnet-cidr用户还可以使用传递给subctl join命令的标志为加入代理的每个集群手动指定 GlobalCIDR 。如果在 Broker 中未启用 Globalnet,或者如果在集群中预配置了 GlobalCIDR,则提供的 Globalnet CIDR 将被忽略。
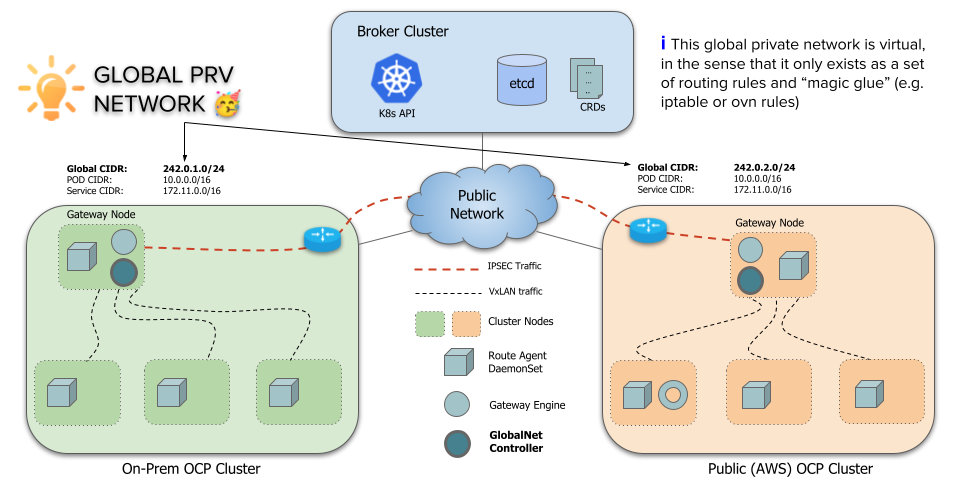
关于GlobalCIDR分配IP机制
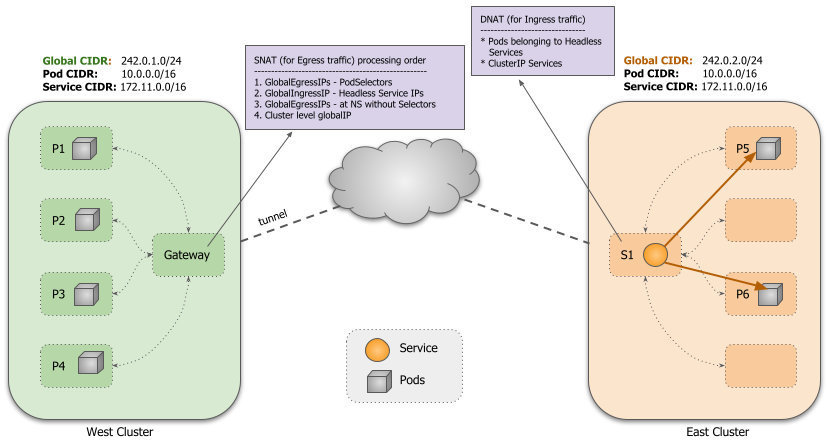
默认情况下,每个集群都分配有可配置数量的全局 IP,由ClusterGlobalEgressIP资源表示,用作跨集群通信的出口 IP。支持多个 IP 以避免临时端口耗尽问题。默认值为 8。IP 是从可配置的全局 CIDR 分配的。在主机网络上运行的访问远程集群的应用程序也使用集群级别的全局出口 IP。
1 | |
也可以为每个命名空间分配可配置数量的全局 IP,从全局 CIDR 分配的,并用作命名空间中所有或选定 pod 的出口 IP,并优先于集群级别的全局 IP
1 | |
对于ClusterIP 类型services自动从Global CIDR分配一个全局IP作为入口,对于每个headless services和pod自动从Global CIDR分配一个全局IP作为出口和入口。pod如果符合GlobalEgressIP规则则会作为出口。
设置针对某些pod使用唯一全局IP
1 | |
submariner-globalnet
实现pod到远程service跨集群连接服务,从Global CIDR分配给pod和serivce,并在GateWay Node上配置所需的规则以使用全局 IP 提供跨集群连接,Globalnet 还支持从节点(包括使用主机网络的 pod)到远程服务的全局 IP 的连接。分成两个部分IP Address Manager and Globalnet。Globalnet依赖kube-proxy
IP Address Manager (IPAM)
GlobalCIDR根据集群上的配置创建一个 IP 地址池。- 从全局池中为所有入口和出口分配 IP,并在不再需要时释放它们。
Globalnet
维护iptable路由规则
- 为 Globalnet 规则创建初始 iptables 链
- 对于每个
GlobalEgressIP,创建相应的 SNAT 规则以将所有匹配 pod 的源 IP 转换为分配给GlobalEgressIP对象的相应全局 IP - 对于每个导出的服务,创建一个入口规则,将所有发往服务全局 IP 的流量引导到服务的
kube-proxyiptables 链,进而将流量引导到服务的后端 pod - 删除Pod, Service 或者ServiceExport时候,会清理gateway node的规则
Lighthouse
让pod知道远程机器服务的IP,Lighthouse controller
- 为
ClusterIP服务创建ServiceImport使用全局IP - 对于headless services, 创建
EndpointSlice时候后台pod的全局IP会被分发到其他集群 - Lighthouse plugin 会使用这些全局IP作为DNS询问的应答。
注意事项
- member集群之间的Pod CIDR 和 Service CIDR必须不一样,集群节点IP要在Pod/Service CIDR 范围之外
- 网关节点之间的 IP 可达性,默认封装端口为 4500/UDP
- Submariner 使用 UDP 端口 4800 封装从工作节点和主节点到网关节点的 Pod 流量。这是为了保留 Pod 的源 IP 地址所必需的。确保防火墙配置允许集群中所有节点双向使用 4800/UDP。