为什么会有crd
随着 Kubernetes 使用的越来越多,用户自定义资源的需求也会越来越多。而 Kubernetes 提供的聚合各个子资源的功能,已经不能满足日益增长的广泛需求了。用户希望提供一种用户自定义的资源,把各个子资源全部聚合起来。但 Kubernetes 原生资源的扩展和使用比较复杂,因此诞生了用户自定义资源这么一个功能。
crd是什么
CR(Custom Resource)其实就是在 Kubernetes 中定义一个自己的资源类型,是一个具体的 “自定义资源” 实例,为了能够让 Kubernetes 认识这个 CR,就需要让 Kubernetes 明白这个 CR 的宏观定义是什么,也就是需要创建所谓的 CRD(Custom Resource Definition)来表述。
下图是自定义资源通常包括的一些属性
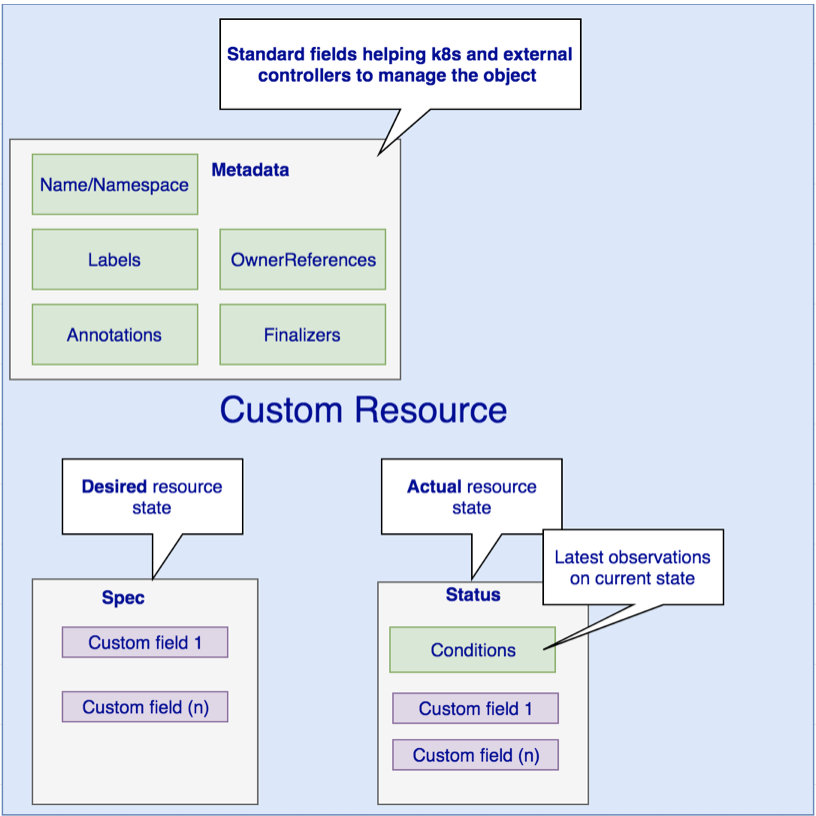
用户可以根据自己的需求添加自定义的 Kubernetes 对象资源。这里用户自己添加的 Kubernetes 对象资源都是 native 的、都是一等公民,和 Kubernetes 中自带的、原生的那些 Pod、Deployment 是同样的对象资源。在 Kubernetes 的 API Server 看来,它们都是存在于 etcd 中的一等资源。
自定义资源和原生内置的资源一样,都可以用 kubectl 来去创建、查看,也享有 RBAC、安全功能。用户可以开发自定义Controller来感知或者操作自定义资源的变化。
crd 实操
在 Kubernetes 中,CRD 本身也是一种资源,它是 Kubernetes 内部 apiextensions-apiserver 提供的 API Group:apiextensions.k8s.io/v1,注意,这里是 v1 版本,在 Kubernetes 1.16 版本中,CRD 转正了,成为了正式版本 ,但是,在 v1.16 之前,都是以 v1beta1 的版本存在,所以在编写的时候注意一下你的 Kubernetes 版本。
1 | |
通过在 Kubernetes 集群中注册 CRD 对象。然后 Kubernetes 中的 kube-apiserver 组件中运行的 apiextensions-apiserver 就会检查对应 CRD 的名字是否合法之类的,当一切检查都 OK 之后,那么就会返回给你创建成功的状态了
1 | |
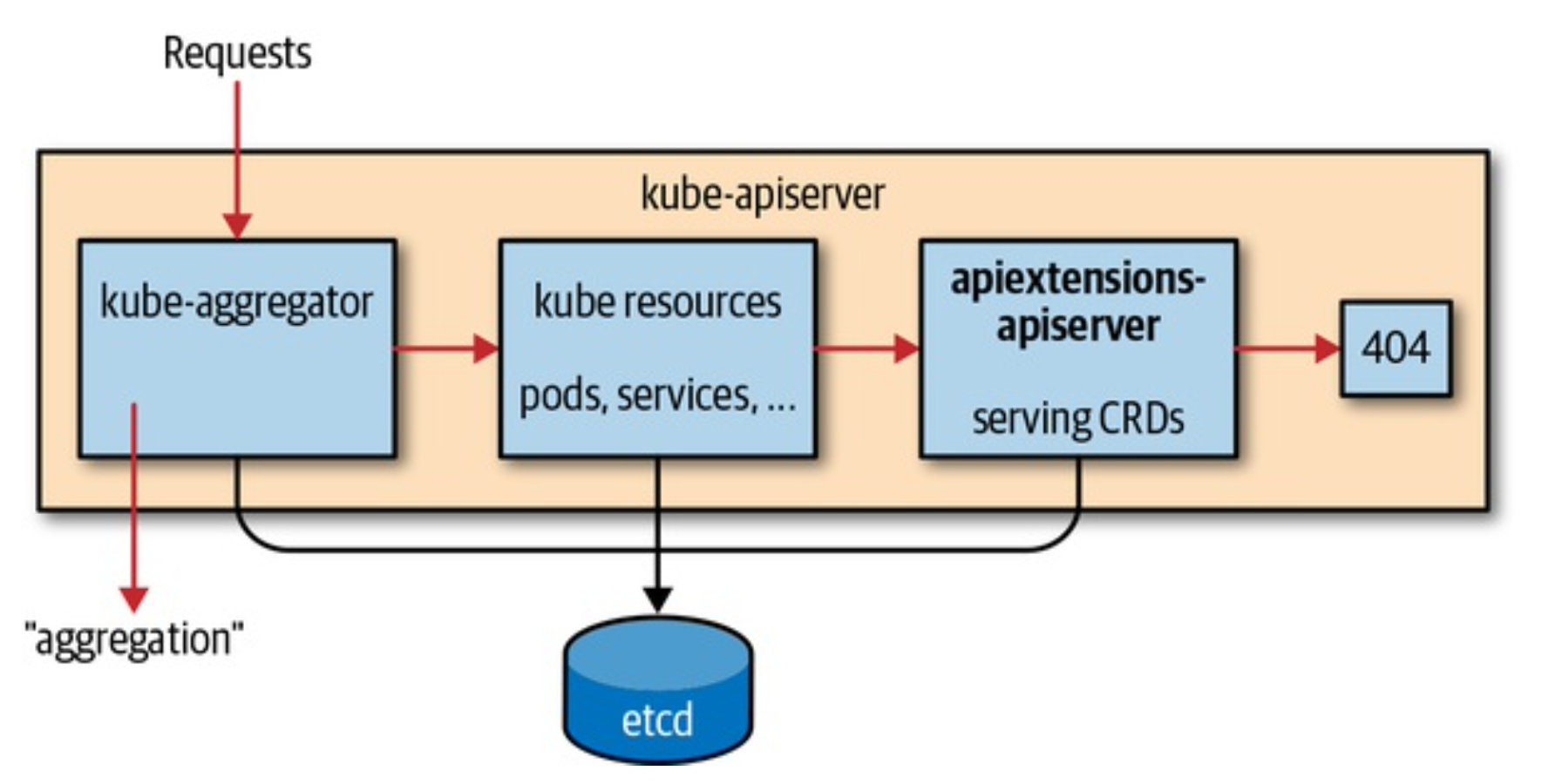
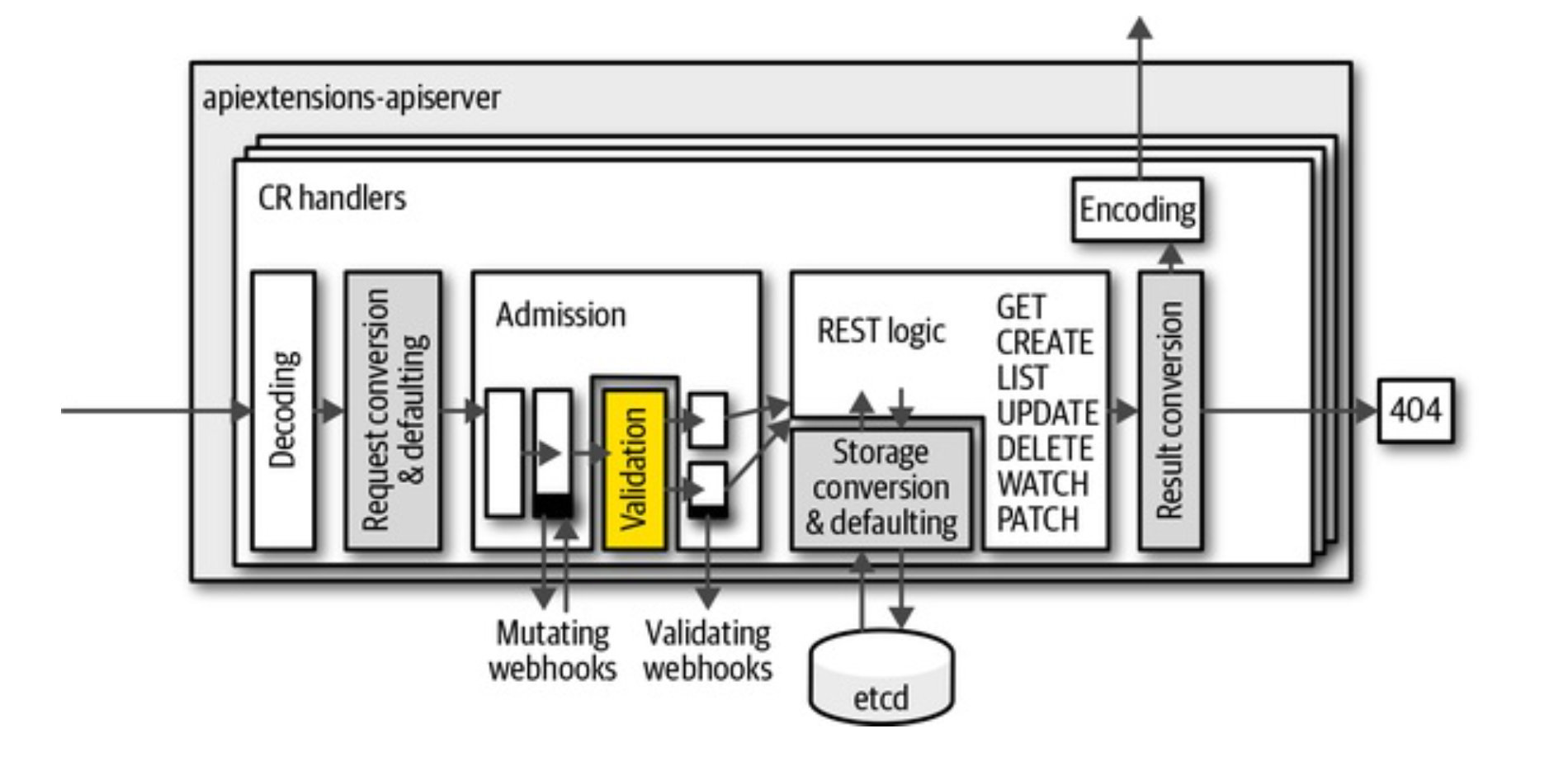
cr创建由apiextensions-apiserver根据 OpenAPI v3 schema检验失败返回400
1 | |
创建cr
1 | |
概念解析
Kind
表示实体的类型。每个对象都有一个字段 Kind(JSON 中的小写 kind,Golang 中的首字母大写 Kind),该字段告诉如 kubectl 之类的客户端它表示什么类型。
API group
在逻辑上相关的一组 Kind 集合。 如 Job 和 ScheduledJob 都在 batch API group 里。
Version
标示 API group 的版本更新, API group 会有多个版本 (version)。
- v1alpha1: 初次引入
- v1beta1: 升级改进
- v1: 开发完成毕业
在持续开发中,对象会发生变化,便用 Version 来标示版本变化。 对象会存储所有版本的对象属性的并集。但是在取出时指定版本,即只会取出这个版本所需要的对象定义。
Resource
通常是小写的复数词(例如,pod),用于标识一组 HTTP 端点(路径),来对外暴露 CURD 操作。
GVR
Resource 和 API group、Version 一起称为 GroupVersionResource(GVR),来唯一标示一个 HTTP 路径。

API 示例
我们不止使用kubectl控制,还可以通过k8s api操作cr
1 | |
API 访问方式 GET POST PUT/PATCH DELETE
1 | |
修改子资源
1 | |
post 创建名为foo2的cr
1 | |
GET
1 | |
PUT的请求体根据GET的reponse修改,PATCH根据POST请求体修改。具体有什么不一样看下面
DELETE
1 | |
delete原理
Finalizer 是带有命名空间的键,告诉 Kubernetes 等到特定的条件被满足后, 再完全删除被标记为删除的资源。 Finalizer 提醒Controller清理被删除的对象拥有的资源。
Kubernetes 删除一个指定了 Finalizer 的对象时, Kubernetes API 通过填充 .metadata.deletionTimestamp 来标记要删除的对象, 并返回202状态码 (HTTP “已接受”) 使其进入只读状态。
Finalizers 通常不指定要执行的代码。 相反,它们通常是特定资源上的键的列表,类似于注解。 Kubernetes 自动指定了一些 Finalizers,但你也可以指定你自己的。
当你使用清单文件创建资源时,你可以在 metadata.finalizers 字段指定 Finalizers。 当你试图删除该资源时,处理删除请求的 API 服务器会注意到 finalizers 字段中的值, 并进行以下操作:
- 修改对象,将你开始执行删除的时间添加到
metadata.deletionTimestamp字段。 - 禁止对象被删除,直到其
metadata.finalizers字段为空。 - 返回
202状态码(HTTP “Accepted”)。
每当一个 Finalizer 的条件被满足时,控制器就会从资源的 finalizers 字段中删除该键。 当 finalizers 字段为空时,deletionTimestamp 字段被设置的对象会被自动删除。 你也可以使用 Finalizers 来阻止删除未被管理的资源。
kubernetes update和patch区别
背景
调用put 更新了spec.replicas=3
1 | |
调用 K8s api 接口做更新。结果收到报错如下:
1 | |
因为 YAML 文件中没有包含 resourceVersion 字段。对于 update 请求而言,应该取出当前 K8s 中的对象做修改后提交
正确应该
1 | |
原理
对一个 Kubernetes 资源对象做更新操作,简单来说就是通知 kube-apiserver 组件我们希望如何修改这个对象。
而 K8s 为这类需求定义了两种“通知”方式,分别是 update 和 patch。
- 在 update 请求中,我们需要将整个修改后的对象提交给 K8s;K8s 对 update 请求的版本控制机制所限制的。
- 而对于 patch 请求,我们只需要将对象中某些字段的修改提交给 K8s。
Update 机制
也就是PUT方法
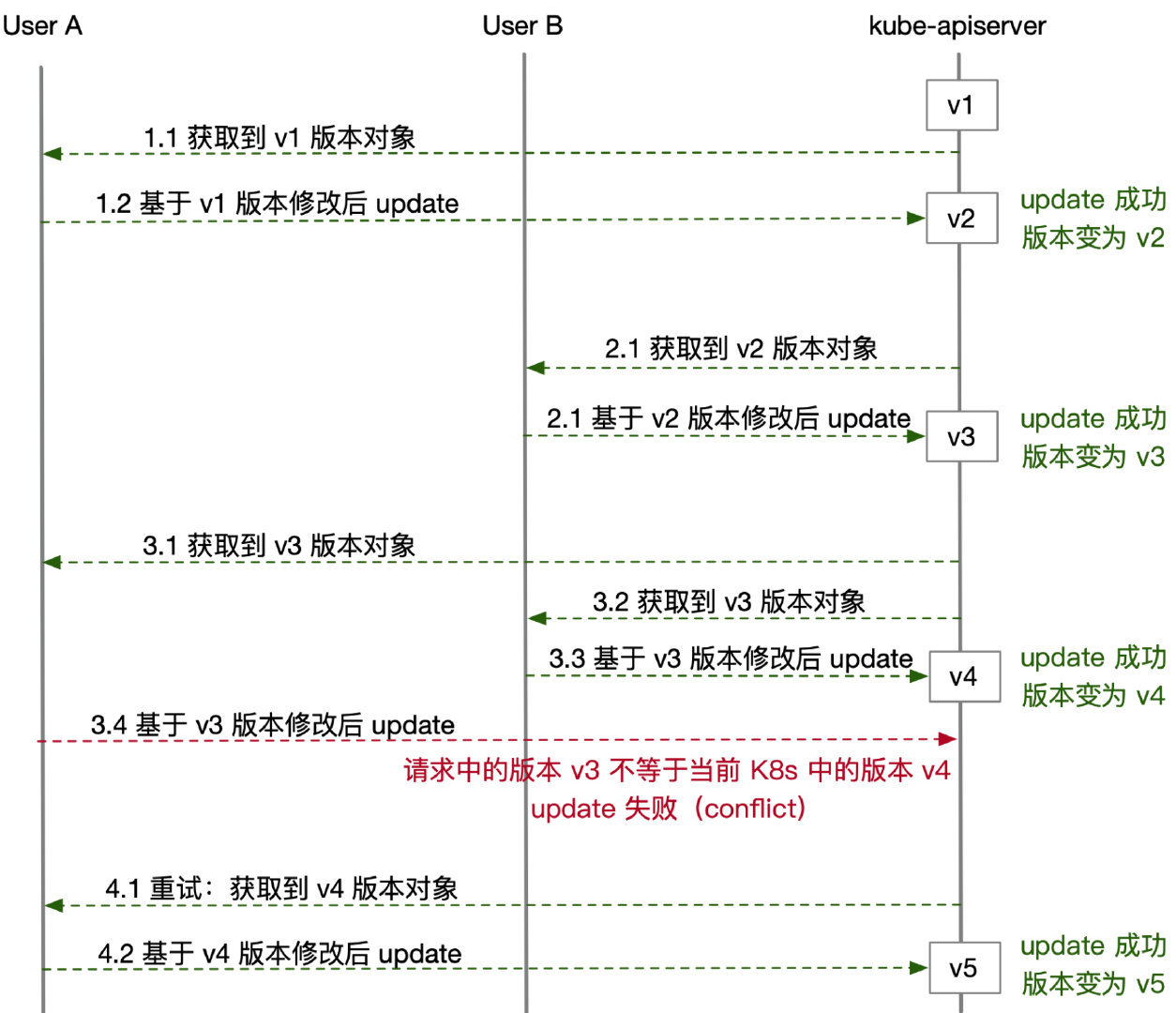
Kubernetes 中的所有资源对象,都有一个全局唯一的版本号(metadata.resourceVersion)。每个资源对象从创建开始就会有一个版本号,而后每次被修改(不管是 update 还是 patch 修改),版本号都会发生变化。
唯一能做的就是通过比较版本号相等来确定对象是否是同一个版本(即是否发生了变化),resourceVersion 一个重要的用处,就是来做 update 请求的版本控制。
K8s 要求用户 update 请求中提交的对象必须带有 resourceVersion,也就是说我们提交 update 的数据必须先来源于 K8s 中已经存在的对象。因此,一次完整的 update 操作流程是:
- 首先,从 K8s 中拿到一个已经存在的对象(可以选择直接从 K8s 中查询;如果在客户端做了 list watch,推荐从本地 informer 中获取)
- 然后,基于这个取出来的对象做一些修改,比如将 Deployment 中的 replicas 做增减,或是将 image 字段修改为一个新版本的镜像
- 最后,将修改后的对象通过 update 请求提交给 K8s
- 此时,kube-apiserver 会校验用户 update 请求提交对象中的 resourceVersion 一定要和当前 K8s 中这个对象最新的 resourceVersion 一致,才能接受本次 update。否则,K8s 会拒绝请求,并告诉用户发生了版本冲突(Conflict)。
至于metadata.Generation
该字段是自动生成的,是每次修改/创建crd对象,都会修改,创建时为1。后面每次修改都会+1。只有当spec修改时,才会触发Generation+1,status的修改不会触发。
Patch 机制
当用户对某个资源对象提交一个 patch 请求时,kube-apiserver 不会考虑版本问题,而是直接接受用户的合法请求,也就是将 patch 打到对象上、同时更新版本号。
有不同的更新策略
1 | |
Example
如果针对一个已有的 Deployment 对象,假设 template 中已经有了一个名为 app 的容器
-
如果要在其中新增一个 nginx 容器,如何 patch 更新?
-
如果要修改 app 容器的镜像,如何 patch 更新?
json patch
新增容器:
1 | |
修改已有容器 image:
1 | |
可以看到,在 json patch 中我们要指定操作类型,比如 add 新增还是 replace 替换,另外在修改 containers 列表时要通过元素序号来指定容器。
merge patch
无法单独更新一个列表中的某个元素,因此不管我们是要在 containers 里新增容器、还是修改已有容器的 image、env 等字段,都要用整个 containers 列表来提交 patch
1 | |
显然,这个策略并不适合我们对一些列表深层的字段做更新,更适用于大片段的覆盖更新。
不过对于 labels/annotations 这些 map 类型的元素更新,merge patch 是可以单独指定 key-value 操作的,相比于 json patch 方便一些,写起来也更加直观:
1 | |
strategic merge patch
在我们 patch 更新 containers 不再需要指定下标序号了,而是指定 name 来修改,K8s 会把 name 作为 key 来计算 merge。比如针对以下的 patch 操作
1 | |
如果 K8s 发现当前 containers 中已经有名字为 nginx 的容器,则只会把 image 更新上去;而如果当前 containers 中没有 nginx 容器,K8s 会把这个容器插入 containers 列表。
目前 strategic 策略只能用于原生 K8s 资源以及 Aggregated API 方式的自定义资源,对于 CRD 定义的资源对象,是无法使用的。这很好理解,因为 kube-apiserver 无法得知 CRD 资源的结构和 merge 策略。如果用 kubectl patch 命令更新一个 CR,则默认会采用 merge patch 的策略来操作
kubectl的封装
参考Kubernetes Apply vs. Replace vs. Patch
其实 kubectl 为了给命令行用户提供良好的交互体感,设计了较为复杂的内部执行逻辑,诸如 apply、edit 这些常用操作其实背后并非对应一次简单的 update 请求。默认为 strategic merge patch 格式
apply
使用默认参数执行 apply 时,触发的是 client-side apply。kubectl 逻辑如下
首先解析用户提交的数据(YAML/JSON)为一个对象 A;然后调用 Get 接口从 K8s 中查询这个资源对象:
- 如果查询结果不存在,kubectl 将本次用户提交的数据记录到对象 A 的 annotation 中(key 为 kubectl.kubernetes.io/last-applied-configuration),最后将对象 A提交给 K8s 创建;
- 如果查询到 K8s 中已有这个资源,假设为对象 B:
- kubectl 尝试从对象 B 的 annotation 中取出 kubectl.kubernetes.io/last-applied-configuration 的值(对应了上一次 apply 提交的内容)
- kubectl 根据前一次 apply 的内容和本次 apply 的内容计算出 diff(默认为 strategic merge patch 格式,如果非原生资源则采用 merge patch)
- 将 diff 中添加本次的 kubectl.kubernetes.io/last-applied-configuration annotation,最后用 patch 请求提交给 K8s 做更新。
edit
当用户修改完成、保存退出时,kubectl 并非直接把修改后的对象提交 update(避免 Conflict,如果用户修改的过程中资源对象又被更新)
而是会把修改后的对象和初始拿到的对象计算 diff,最后将 diff 内容用 patch 请求提交给 K8s。
replace
相当于手动edit(先get xxx -o yaml ,修改后再replace),加上--forse参数相当于delete资源后,再post
patch
就相当于patch方法,修改资源的一部分
crd是怎么被发现的
- kubectl 通过/apis询问Api server所有的 API group
- kubectl 通过/apis/group/version 查看所有的group存在的资源,找到对应资源所在的Group、Version和Resources

总结
- 资源对象的元数据 (Schema ) 的定义 :可以将其理解为数据 库 Table 的定义, 定 义了对应资源对象的数据结构,官方内建资源对象的元数据定义是固化在源码中的 。
- 资源对象的校验逻辑:确保用户提交的资源对象的属性的合法性 。
- 资源对象的 CRUD 操作代码:可以将其理解为数据库 表的 CRUD 代码,但比后 者更难,因为 API Server 对资源对象的 CRUD 操作都会保存到 etcd 数据库中,对处理性 能的要求也更高,还要考虑版本兼容性和版本转换等复杂问题 。
- 资源对象相关的“自动控制器”(如 RC 、 Deployment 等资源对象背后的控制器): 这是很重要的一个功能 。 Kubernetes 是一个以自动化为核心目标的平台,用户给出期望的资源对象声明,运行过程中由资源背后的“自动控制器“确保对应资源对象的数量、状态 、 行为等始终符合用户的预期。
controller概况
从上面看出,其实有了CRD还不足以实现现实复杂的功能。因为我们可以把CRD当成是数据库的schema,后台开发api的输入格式,控制应用的配置等等,而真正实现逻辑的部分是controller。要了解它,要看看一下的概念。
在 Kubernetes 中我们使用 Deployment、DamenSet,StatefulSet 来管理应用 Workload,使用 Service,Ingress 等来管理应用的访问方式,使用 ConfigMap 和 Secret 来管理应用配置。在集群中,对这些资源的创建,更新,删除的动作都会被转换为事件(Event)。
Kubernetes 的 Controller Manager 负责监听这些事件并触发相应的任务来满足用户的期望。这种方式我们称为声明式,用户只需要关心应用程序的最终状态,其它的都通过 Kubernetes 来帮助我们完成,通过这种方式可以大大简化应用的配置管理复杂度。
Controller 其实是 Kubernetes 提供的一种可插拔式的方法来扩展或者控制声明式的 Kubernetes 资源。它是 Kubernetes 的大脑,负责大部分资源的控制操作。以 Deployment 为例,它就是通过 kube-controller-manager 来部署的。
比如说声明一个 Deployment 有 replicas、有 2 个 Pod,那么 kube-controller-manager 在观察 etcd 时接收到了该请求之后,就会去创建两个对应的 Pod 的副本,并且它会去实时地观察着这些 Pod 的状态,如果这些 Pod 发生变化了、回滚了、失败了、重启了等等,它都会去做一些对应的操作。
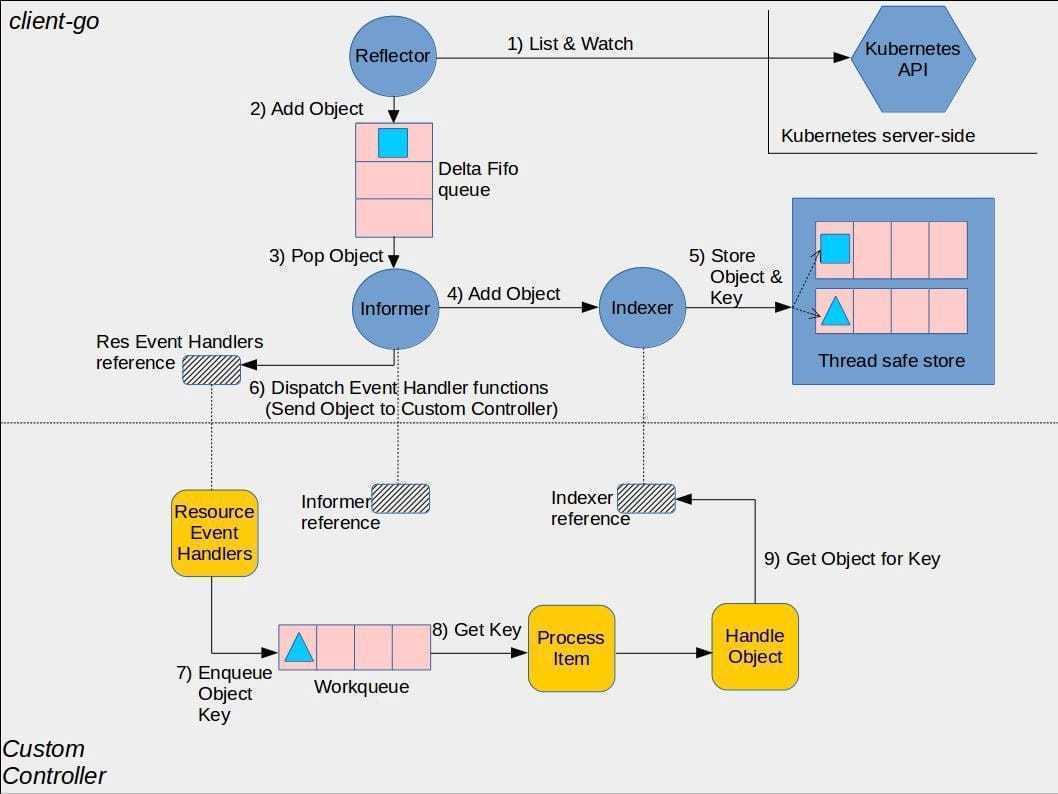
下图是k8s-client-go对controller的实现,黄色部分是用户自定义部分
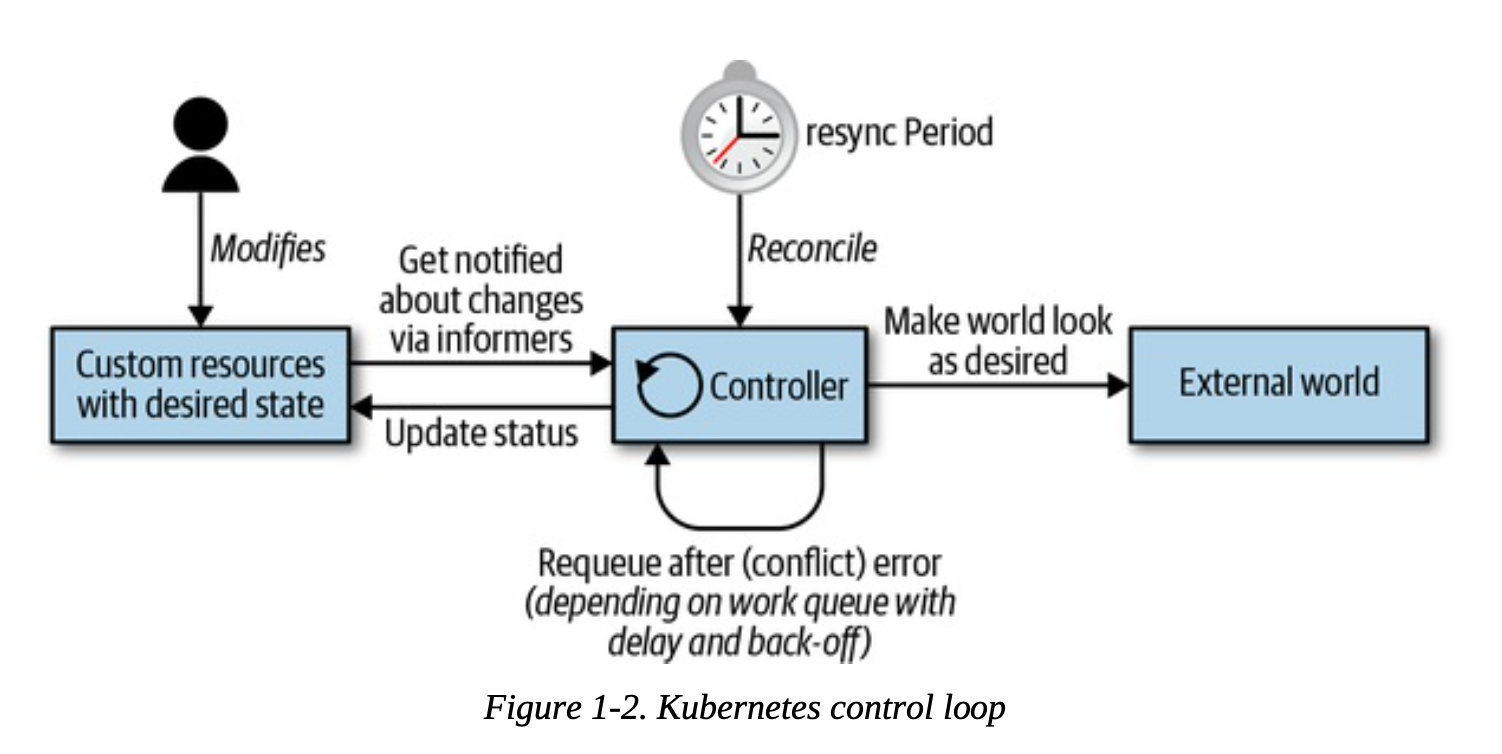
Controller 实现控制循环,通过 API Server 监听集群的共享状态,根据资源的当前状态做出反应更改真实世界,使将资源更接近期望状态。
所有的控制器都按照以下逻辑运行:
-
由事件驱动来读取资源 (resources) 的状态 (state)。
-
更改集群内或集群外对象的状态 (state)。比如,启动一个 Pod,创建 Endpoint。
-
通过 API server 更新步骤 1 中的资源状态(status),存储到 etcd 中。
-
重复循环,返回步骤 1。下一次循环会用最新的状态,自动从失败中恢复
controller核心部分
Reflector
- List 用来在 Controller 重启以及 Watch 中断的情况下,进行系统资源的全量更新;
- 通过 HTTP 长连接 Watch 不断监听得到 etcd 变化的数据,接收 Kubernetes API Server 发来的资源变更事件、定时同步的时候都可以获取到资源的期望状态。
- 当 Watch 监控到集群中有资源对象变化的事件时,会触发 watchHandler 回调,将变化的资源对象放入 Delta FIFO 中,同时更新本地缓存。
- Delta 队列中塞入一个包括资源对象信息本身以及资源对象事件类型的 Delta 记录,Delta 队列中可以保证同一个对象在队列中仅有一条记录,从而避免 Reflector 重新 List 和 Watch 的时候产生重复的记录。
当长时间运行的 watch 连接中断时,Informers尝试用发起另一个 watch 请求从错误中恢复,在不丢失任何事件的情况下拾取事件流。
如果中断时间很长,新的watch连接成功前,etcd把event清空了导致api server丢失事件,Informers会重新列出所有对象,然后会有个周期resync(可配置间隔resyncPeriod),内存缓存和业务逻辑之间进行协调,每次都会为所有对象调用已注册的handler
这个resync是纯内存的操作,不会触发对系统的调用,曾经不是这样的,现在的watch错误处理机制,改进到足以使重新列表变得不必要。
Resync 机制会将 Indexer 本地存储中的资源对象同步到 DeltaFIFO 中,因为在处理 SharedInformer 事件回调时,可能存在处理失败的情况,定时的 Resync 让这些处理失败的事件有了重新 onUpdate 处理的机会。
Informer 组件不断地从 Delta 队列中弹出 delta 记录,然后把资源对象交给 indexer,之后,再把这个事件交给事件的回调函数。
减轻的 apiserver 和 etcd 的负担
- 一个GroupVersionResource一个informer,Shared Informer 共享机制,同类型的资源对象共享一个 Informer,因此同类型的资源对象获取后只需要进行一次 apiserver 的 List 和 Watch 请求
- 维护Indexer 本地存储,Control Loop 通过索引可直接从缓存中获取资源对象的数据,不需要再和 apiserver 进行交互
Informer
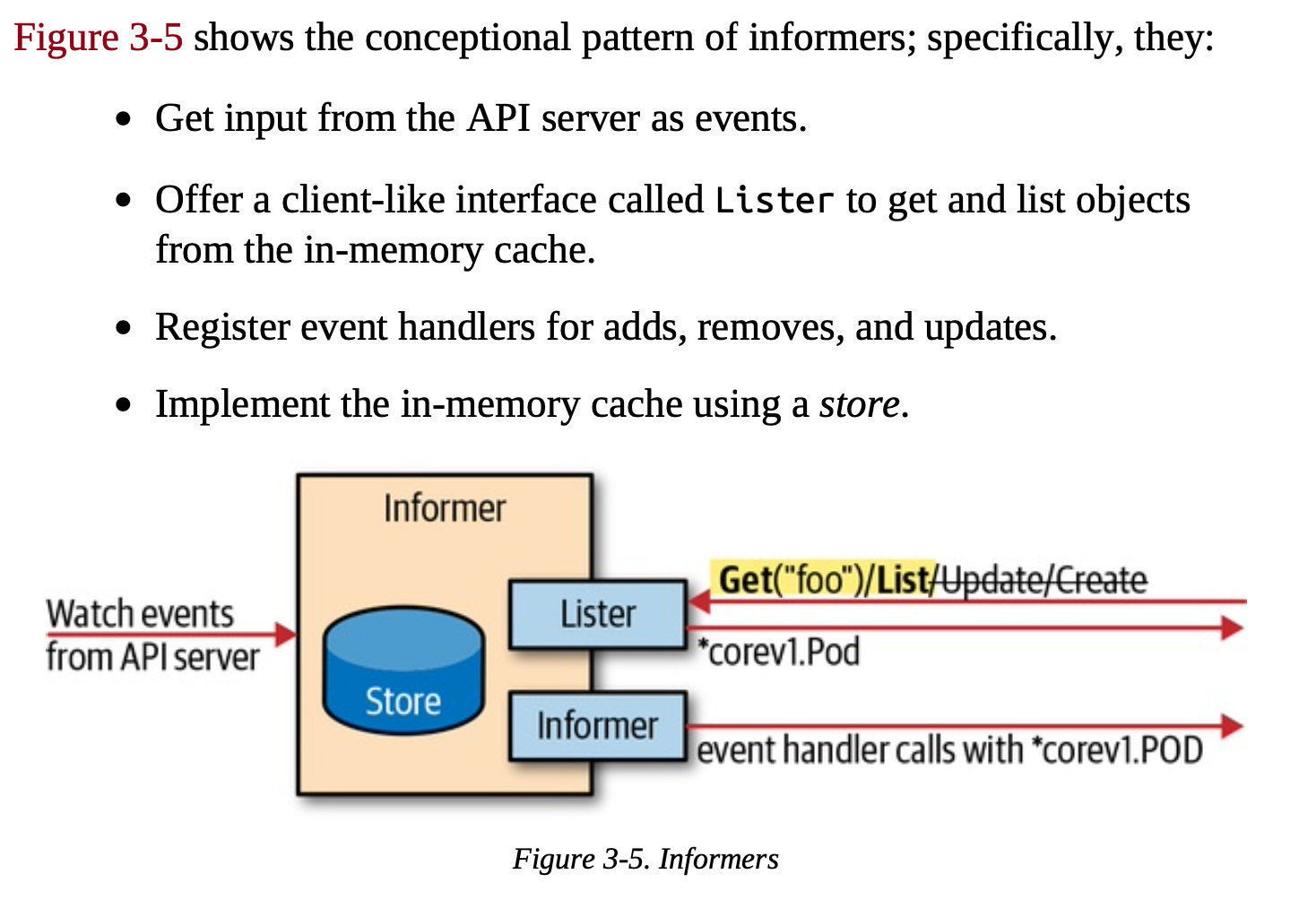
- 接受从API server获取事件和对象
- 注册不同事件的处理函数
- 根据事件传递对象给对应事件的处理函数
Indexer
用来存储资源对象并自带索引功能的本地存储,Reflector 从 DeltaFIFO 中将消费出来的资源对象存储到 Indexer,Indexer 与 Etcd 集群中的数据完全保持一致。从而 client-go 可以本地读取,减少 Kubernetes API 和 Etcd 集群的压力。
ThreadSafeStore 是一个并发安全内存中存储,通常使用MetaNamespaceKeyFunc定义key(meta.namespace/meta.name ),value 用于存储资源对象。
可以被 Controller Manager 或多个 Controller 所共享。
控制器
主要由事件处理函数以及 worker 组成。
事件处理函数之间会相互关注资源的新增、更新、删除的事件,并根据控制器的逻辑去决定是否需要处理。对需要处理的事件,会把事件关联资源的key塞入一个工作队列中(内存空间的消耗,方便获取到对象最新的状态)。
并且由后续的 worker 池中的一个 Worker 来处理,工作队列会对存储的对象进行去重,从而避免多个 Woker 处理同一个资源的情况。
工作完成之后,即把对应的事件处理完之后,就把这个 key 丢掉,代表已经处理完成。如果处理过程中有什么问题,就直接报错,打出一个事件来,再把这个 key 重新放回到队列中,下一个 Worker 就可以接收过来继续进行相同的处理。