Kubemetes 的早期版本依靠 Heapster 来实 现 完整的性能数据采集和监控功能, Kubernetes 从 1.8 版本开始,性 能数据开始 以 Metrics API 方式提供标 准化接口,并且从 1.10 版本开始将 Heapster 替换为 Metrics Server。 在 Kubemeles 新的监控体系中, Metrics Server 用于提供核心指标 (Core Metrics ), 包括 Node、 Pod 的 CPU 和内 存使用指标。对其他自 定义指标 ( Custom Metrics ) 的监控则由 Prometheus 等组件来完成。
监控 Node 和 Pod 的 CPU 和内存使用数据
Metrics Server 在部署 完成 后,将通过 Kubemetes 核心 API Server 的 /apis/ metrics.k8s.io/vIbeta1路径提供Node和Pod的监控数据。
1 | |
Prometheus scrapes metrics from instrumented jobs, either directly or via an intermediary push gateway for short-lived jobs. It stores all scraped samples locally and runs rules over this data to either aggregate and record new time series from existing data or generate alerts. Grafana or other API consumers can be used to visualize the collected data.
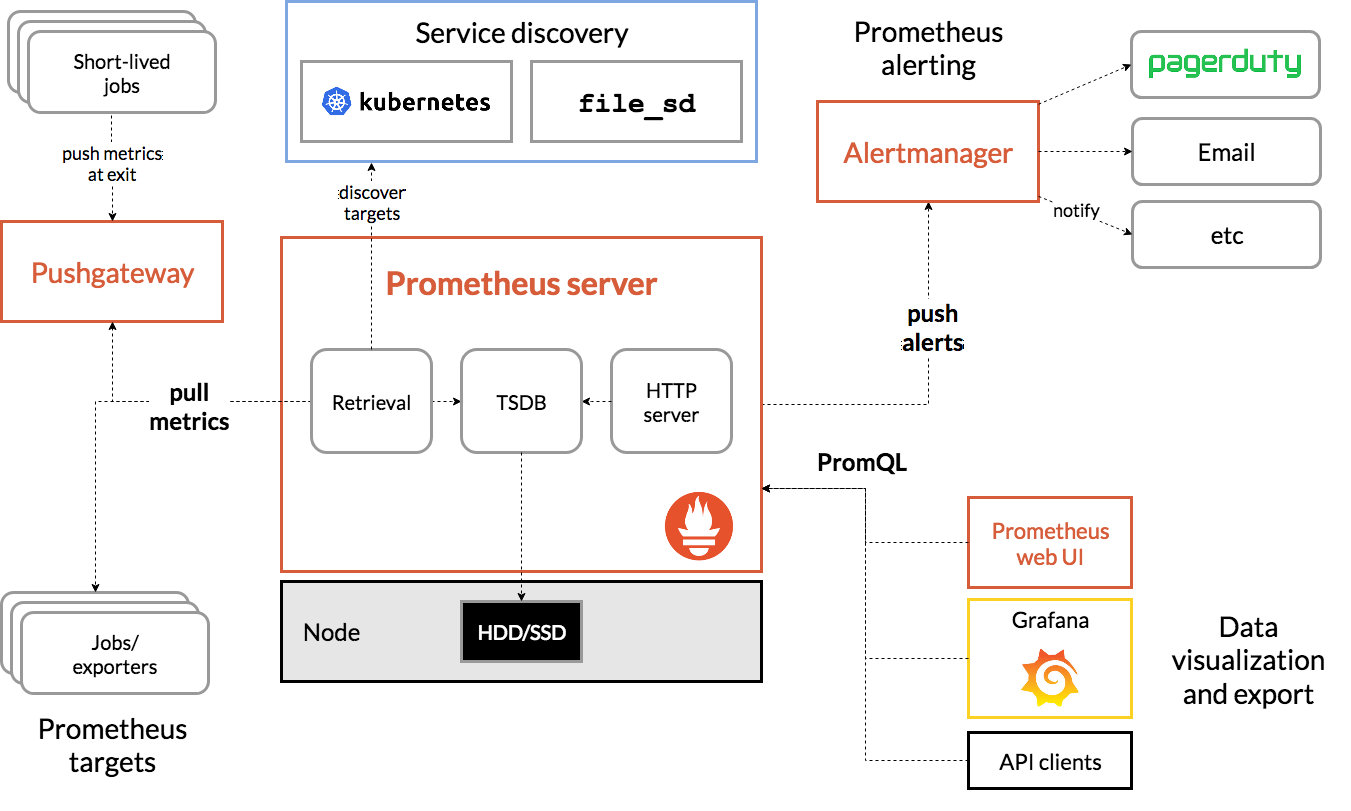
The Prometheus ecosystem consists of multiple components, many of which are optional:
- the main Prometheus server which scrapes and stores time series data
- client libraries for instrumenting application code
- a push gateway for supporting short-lived jobs
- special-purpose exporters for services like HAProxy, StatsD, Graphite, etc.
- an alertmanager to handle alerts
- various support tools
Prometheus是一款基于时序数据库的开源监控告警采统,非常适合Kubernetes集群的监控。Prometheus的基本原理是通过 HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成 过程。 这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做 exporter。目前互联网公司常用的组件大部分都有exporter可以眼接使用,比如Nginx、MySQL、Redis、Kafka、Linux系统信息 (包括磁盘、内存、CPU、网络等等)。Prometheus有以下特点:
- 支持多维数据模型:由指标名和键值对组成的时间序列数据
- 内置置时间序列数据库TSDB
- 支持PromQL查询语言,可以完成非常复杂的查询和分析,对图表展示和告警非常有意义
- 支持HTTP的Pull方式采集时间序列数据
- 支持PushGateway采集瞬时任务的数据
- 支持服务发现和静态配置两种方式发现目标
- 支持接入Grafana
数据采集
Prometheus可通常采用Pull方式采集监控数据,也可以push到PushGateWay,然后Server再pull
| 实时性 | 状态保存 | 控制能力 | 配置的复杂性 | |
|---|---|---|---|---|
| Pull | 通过周期性采集,设置采集时间。实时性不如Push方式 | agent需要数据存储能力,server只负责数据拉取 server可以做到无状态 |
server更加主动,控制采集的内容和采集频率。 | 通过批量配置或者自动发现来获取所有采集点 相对简单,可以做到target充分解耦,无须感知server存在。 |
| Push | 采集数据立即上报到监控中心 | 采集完成后立即上报,本地不会保存采集数据 agent本身无状态,server需要维护各种agent状态。 |
控制方为agent,agent上报的数据决定了上报的周期和内容 | 每个agent都需要配置server的地址。 |
监控指标
Prometheus采用的是时序数据模型,时序数据是按照时间戳序列存放。
总结来说,time-series中的每一行数据=Metric names and labels + sample
- 指标(metric):指标名称和标签两部分
<metric name> {<lable name>=<label value>,...}- 指标名称(metric name):用于说明指标的含义,指标名称必须有字母、数字、下划线或者冒号组成 符合正则表达式 [a-zA-Z:][a-zA-Z0-9:],冒号不能用于exporter。
- 标签(label): 体现指标的维度特性,用于过滤和聚合。通过标签名和标签值组成,键值对形式形成多种维度
sample由以下两部分组成:
- 时间戳(timestamp):一个精确到毫秒的时间戳。
- 样本值(value):一个float64的浮点型数据表示当前样本的值。
指标分类
Prometheus支持文本数据格式OpenMetrics,每个exporter都将监控数据输出成文本数据格式,文本内容以行(\n)为单位。
空行将被忽略,文本内容的最后一行为空行
- ”#”代表注释
- “# HELP”提供帮助信息
- “# TYPE“代表metric类型。
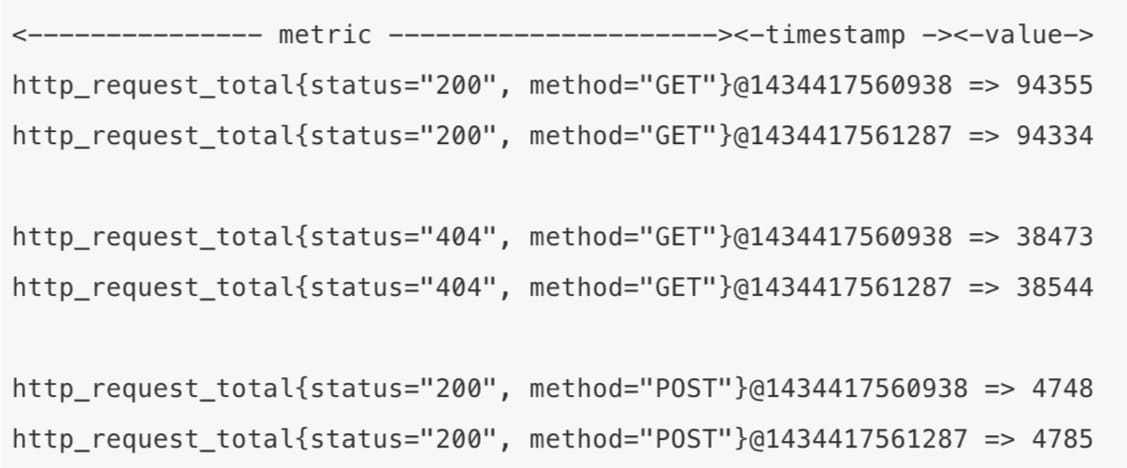
如下所示是调用Prometheus exporter返回的一个监控数据样本:
Counter 计数器
- 计数器类型,只增不减,适用于机器启动时间、HTTP访问量
- 具有很好的不相关性,不会因为机器重启而置0
- 通常会结合rate()方法获取该指标在某个时间段的变化率
1 | |
Gauge
- 仪表盘,表征指标的实时变化情况。
- 可增可减,CPU和内存使用量。
- 大部分监控数据类型都是Gauge类型的
1 | |
Summary
- 高级指标,用于凸显数据的分布情况
- 某个时间段内请求的响应时间
- 可以与Histogram相互转化
- 采样点分位图统计,用于得到数据的分布情况
- 无需消耗服务端资源
- 与histogram相比消耗系统资源更多
- 计算的指标不能再获取平均数等其他指标
- 一般只适用于独立的监控指标,如垃圾回收时间等
1 | |
Histogram
- 反映了某个区间内的样本个数,通过{le=”上边界”}指定这个范围内的样本数。
服务发现
静态配置
- 静态文件配置是一种传统的服务发现方式。
- 适用于有固定的监控环境、IP地址和统一的服务接口的场景。
- 需要在配置中指定采集的目标信息。
- 例如: “target”: [“10.10.10.10:8080”]
动态发现
- 比较适用在云环境下,动态伸缩、迅速配置。
- 容器管理系统、各种云管平台、各种服务发现组件。
- kubernetes为例:
- 需要配置API的地址和认证凭据
- prometheus一直监听集群的变化
- 获取新增/删除集群中机器的信息,并更新采集对象列表。
数据采集
在获取被监控的对象后,Prometheus便可以启动数据采集任务了。 Prometheus采用统一的Restful API方式获取数据,具体来说是调用HTTP GET请求或metrics数据接口获取监控数据。 为了高效地采集数据,Prometheus对每个采集点都启动了一个线程去定时采集数据。
基本流程
采集
- Prometheus Server读取配置解析静态监控端点(static_configs),以及服务发现规则(xxx_sd_configs)自动收集需要监控的 端点
- Prometheus Server周期刮取(scrape_interval)监控端点通过HTTP的Pull方式采集监控数据
- Prometheus Server HTTP请求到达NodeExporter,Exporter返回一个文本响应,每个非注释行包含一条完整的时序数 据:Name+Labels+Samples(一个浮点数和一个时间戳构成),数据来源是一些官方的exporter或自定义sdk或接口;
- Prometheus Server收到响应,Relabel处理之后(relabel_configs)将其存储在TSDB中并建立倒排索引
告警
- Prometheus Server另一个周期计算任务(evaluation_interval)开始执行,根据配置的Rules逐个计算与设置的闻值进行匹配, 若结果超过阈值并持续时长超过临界点将进行报警,此时发送Alert到AlertManager独立组件中。
- AlertManager收到告警请求,根据配置的策略决定是否需要触发告警,如需告警则根据配置的路由链路依次发送告警,比如 邮件、微信、Slack、PagerDuty、WebHook等等。
- 当通过界面或HTTP调用查询时序数据利用PromQL表达式查询,Prometheus Server处理过滤完之后返回瞬时向量(Instant vector,N条只有一个Sample的时序数据),区间向量(Rangevector,N条包含M个Sample的时序数据),或标量数据(Scalar 一个浮点数)
- 采用Grafana开源的分析和可视化工具进行数据的图形化展示。
告警
-
在Prometheus Server中定义告警规则以及产生告警
-
Alertmanager组件则用于处理这些由Prometheus产生的告警。
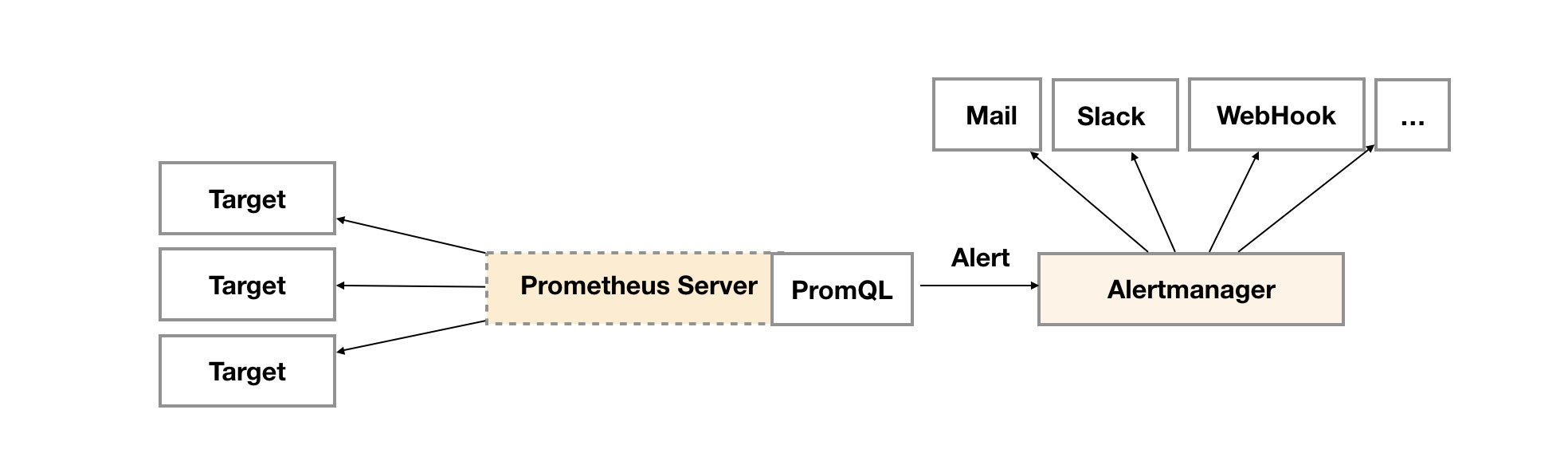
在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息。Alertmanager可以对这些告警信息进行进一步的处理,比如当接收到大量重复告警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方,Prometheus内置了对邮件,Slack等多种通知方式的支持,同时还支持与Webhook的集成,以支持更多定制化的场景。例如,目前Alertmanager还不支持钉钉,那用户完全可以通过Webhook与钉钉机器人进行集成,从而通过钉钉接收告警信息。同时AlertManager还提供了静默和告警抑制机制来对告警通知行为进行优化。
特性
Alertmanager除了提供基本的告警通知能力以外,还主要提供了如:分组、抑制以及静默等告警特性:
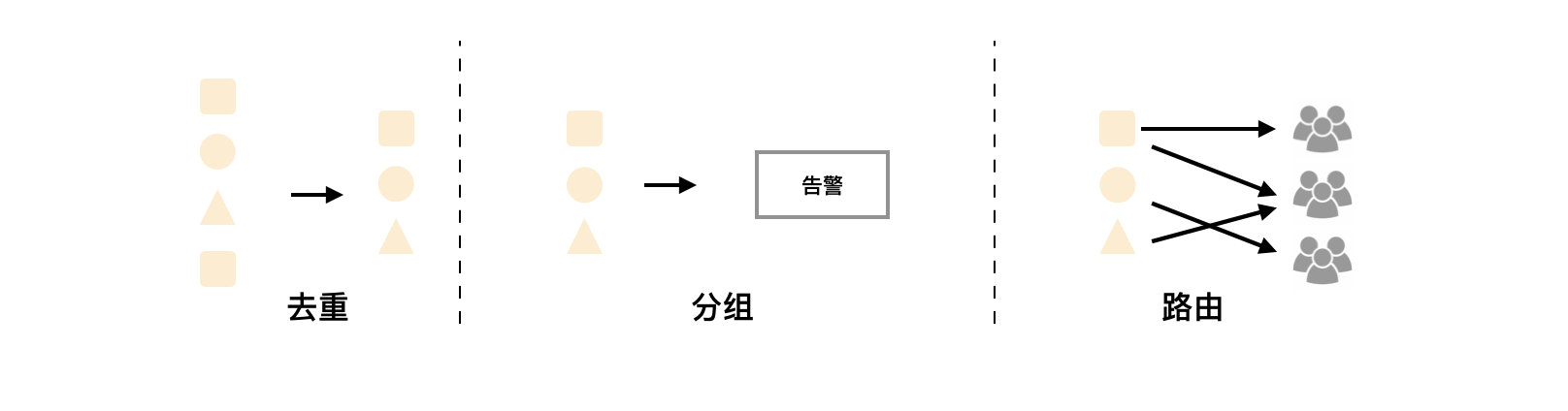
分组
分组机制可以将详细的告警信息合并成一个通知。在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
例如,当集群中有数百个正在运行的服务实例,并且为每一个实例设置了告警规则。假如此时发生了网络故障,可能导致大量的服务实例无法连接到数据库,结果就会有数百个告警被发送到Alertmanager。
而作为用户,可能只希望能够在一个通知中中就能查看哪些服务实例收到影响。这时可以按照服务所在集群或者告警名称对告警进行分组,而将这些告警内聚在一起成为一个通知。
告警分组,告警时间,以及告警的接受方式可以通过Alertmanager的配置文件进行配置。
抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
例如,当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。
抑制机制同样通过Alertmanager的配置文件进行设置。
静默
静默提供了一个简单的机制可以快速根据标签对告警进行静默处理。如果接收到的告警符合静默的配置,Alertmanager则不会发送告警通知。
静默设置需要在Alertmanager的Web页面上进行设置。
定义告警规则
一条典型的告警规则如下所示:
1 | |
修改Prometheus配置文件prometheus.yml,添加以下配置,为了能够让Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule_files指定一组告警规则文件的访问路径,Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知:
1 | |
默认情况下Prometheus会每分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期,则可以通过evaluation_interval来覆盖默认的计算周期:
1 | |
通过$labels.<labelname>变量可以访问当前告警实例中指定标签的值。$value则可以获取当前PromQL表达式计算的样本值。
1 | |
例如,可以通过模板化优化summary以及description的内容的可读性:
1 | |
alert manager
1 | |
主要就是配置路由匹配对应的告警规则,上面的是告警规则,告警的receiver,组合之类的。
告警状态
inactive: 非pending、非firing的状态pending: 已经触发但是少于持续时间的状态firing: 已经触发且超过持续时间的状态
告警生命周期
Prometheus定期从受监控的目标中抓取指标,由scrape_interval(默认为1m)定义。抓取间隔可以全局配置,然后按作业覆盖。然后将抓取的指标永久存储在其本地存储中。
Prometheus 有另一个循环,它的时钟独立于抓取循环,它定期评估警报规则,由evaluation_interval(默认为1m)定义。在每个评估周期中,Prometheus 都会运行每个警报规则中定义的表达式并更新警报状态。
状态转换
警报仅在评估周期期间从一种状态转换到另一种状态。转换如何发生,取决于是否设置了警报的FOR子句
- 警报没有的
FOR(或设置为0)将立即变成firing。 - 警报规则
FOR > 0将先变成pending在变到firing,过程至少需要2个evaluation_interval周期
Example
让我们举一个例子来更好地解释警报的生命周期。我们确实有一个简单的警报来监控节点的负载 1m,并在它高于 20 时触发至少 1 分钟。
1 | |
Prometheus 配置为每 20 秒抓取一次指标,评估间隔为 1 分钟。
1 | |
问题:NODE_LOAD_1M一旦机器上的avgload高于20 ,需要多长时间才能触发?
答:1m到 20s + 1m + 1m。上限可能比您在设置时预期的要高FOR 1m
这种最坏情况计时的原因可以通过警报的生命周期来解释。下图显示了时间线上的事件序列:
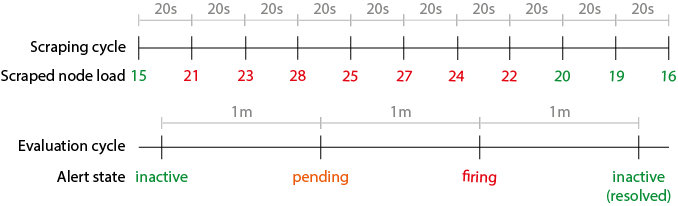
- 节点的负载不断变化,但它会被 Prometheus 每次
scrape_interval(即。20s) - 然后根据抓取的指标评估警报规则每个
evaluation_interval(即。1m) - 当警报规则表达式为真(即
node_load1 > 20)时,警报切换到pending,以遵守FOR子句 - 在下一个评估周期中,如果警报表达式仍然为真,一旦
FOR遵守该子句,警报最终会切换到firing并将通知推送到alert manager
alert manager
告警发送前,alert manager会把告警状态从firing切换到**inactive ** ,然后才发送告警。
分组通知的缺点是它可能会导致进一步的延迟
警报管理器通知分组基本上由以下设置控制:
1 | |
当一个新的警报被触发时,它会等待group_wait一段时间,直到通知被调度。该等待时间对于最终将匹配相同group_by条件的更多即将到来的警报进行分组是必要的(换句话说,如果两个警报具有完全相同的group_by标签值,则会将它们组合在一起)。
这意味着如果group_wait设置为30s,警报管理器会将警报通知缓冲 30 秒,等待其他潜在通知附加到缓冲的通知。一旦group_wait时间到期,则最终发送通知。
下一次发送同组告警,需要等group_interval时间。
Recoding Rules
通过PromQL可以实时对Prometheus中采集到的样本数据进行查询,聚合以及其它各种运算操作。而在某些PromQL较为复杂且计算量较大时,直接使用PromQL可能会导致Prometheus响应超时的情况。这时需要一种能够类似于后台批处理的机制能够在后台完成这些复杂运算的计算,对于使用者而言只需要查询这些运算结果即可。Prometheus通过Recoding Rule规则支持这种后台计算的方式,可以实现对复杂查询的性能优化,提高查询效率。
在Prometheus配置文件中,通过rule_files定义recoding rule规则文件的访问路径。
1 | |
每一个规则文件通过以下格式进行定义:
1 | |
一个简单的规则文件可能是这个样子的:
1 | |
rule_group的具体配置项如下所示:
1 | |
与告警规则一致,一个group下可以包含多条规则rule。
1 | |
根据规则中的定义,Prometheus会在后台完成expr中定义的PromQL表达式计算,并且将计算结果保存到新的时间序列record中。同时还可以通过labels为这些样本添加额外的标签。
这些规则文件的计算频率与告警规则计算频率一致,都通过global.evaluation_interval定义:
1 | |
模板
-
Alertmanager配置文件中使用模板字符串
1
2
3
4
5receivers: - name: 'slack-notifications' slack_configs: - channel: '#alerts' text: 'https://internal.myorg.net/wiki/alerts//' -
自定义模板文件custom-template.tmpl
1
https://internal.myorg.net/wiki/alerts//
通过在Alertmanager的全局设置中定义templates配置来指定自定义模板的访问路径
1 | |
设置了自定义模板的访问路径后,用户则可以直接在配置中使用该模板
1 | |
高可用
在Prometheus设计上,使用本地存储可以降低Prometheus部署和管理的复杂度同时减少高可用(HA)带来的复杂性。 在默认情况下,用户只需要部署多套Prometheus,采集相同的Targets即可实现基本的HA。同时由于Prometheus高效的数据处理能力,单个Prometheus Server基本上能够应对大部分用户监控规模的需求。
当然本地存储也带来了一些不好的地方,首先就是数据持久化的问题,特别是在像Kubernetes这样的动态集群环境下,如果Promthues的实例被重新调度,那所有历史监控数据都会丢失。 其次本地存储也意味着Prometheus不适合保存大量历史数据(一般Prometheus推荐只保留几周或者几个月的数据)。最后本地存储也导致Prometheus无法进行弹性扩展。为了适应这方面的需求,Prometheus提供了remote_write和remote_read的特性,支持将数据存储到远端和从远端读取数据。通过将监控与数据分离,Prometheus能够更好地进行弹性扩展。
除了本地存储方面的问题,由于Prometheus基于Pull模型,当有大量的Target需要采样本时,单一Prometheus实例在数据抓取时可能会出现一些性能问题,联邦集群的特性可以让Prometheus将样本采集任务划分到不同的Prometheus实例中,并且通过一个统一的中心节点进行聚合,从而可以使Prometheuse可以根据规模进行扩展。
- Remote Storage可以分离监控样本采集和数据存储,解决Prometheus的持久化问题
- 联邦集群特性对Promthues进行扩展,以适应不同监控规模的变化
本地存储
Prometheus 2.x 采用自定义的存储格式将样本数据保存在本地磁盘当中。
如下所示,按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中,
每一个块中包含该时间窗口内的所有
- 样本数据(chunks),
- 元数据文件(meta.json)
- 索引文件(index)。
当前传入样本的块保存在内存中,但尚未完全保留。通过预写日志(WAL)防止崩溃,可以在崩溃后重新启动Prometheus服务器时重放。预写日志文件以128MB段存储在wal目录中。这些文件包含尚未压缩的原始数据,因此它们比常规块文件大得多。
此期间如果通过API删除时间序列,删除记录也会保存在单独的逻辑文件当中(tombstone)。
1 | |
用户可以通过命令行启动参数的方式修改本地存储的配置。
| 启动参数 | 默认值 | 含义 |
|---|---|---|
| –storage.tsdb.path | data/ | Base path for metrics storage |
| –storage.tsdb.retention | 15d | How long to retain samples in the storage |
| –storage.tsdb.min-block-duration | 2h | The timestamp range of head blocks after which they get persisted |
| –storage.tsdb.max-block-duration | 36h | The maximum timestamp range of compacted blocks,It’s the minimum duration of any persisted block. |
| –storage.tsdb.no-lockfile | false | Do not create lockfile in data directory |
在一般情况下,Prometheus中存储的每一个样本大概占用1-2字节大小。如果需要对Prometheus Server的本地磁盘空间做容量规划时,可以通过以下公式计算:
\[needed\_disk\_space = retention\_time\_seconds * ingested\_samples\_per\_second * bytes\_per\_sample\]从上面公式中可以看出在保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果想减少本地磁盘的容量需求,只能通过减少每秒获取样本数(ingested_samples_per_second)的方式。
因此有两种手段,
- 是减少时间序列的数量,
- 增加采集样本的时间间隔。
考虑到Prometheus会对时间序列进行压缩效率,减少时间序列的数量效果更明显。
从失败中恢复
如果本地存储由于某些原因出现了错误,最直接的方式就是停止Prometheus并且删除data目录中的所有记录。当然也可以尝试删除那些发生错误的块目录,不过相应的用户会丢失该块中保存的大概两个小时的监控记录。
远程存储
本地存储也意味着Prometheus无法持久化数据,无法存储大量历史数据,同时也无法灵活扩展和迁移。
为了保持Prometheus的简单性,Prometheus并没有尝试在自身中解决以上问题,而是通过定义两个标准接口(remote_write/remote_read),让用户可以基于这两个接口对接将数据保存到任意第三方的存储服务中,这种方式在Promthues中称为Remote Storage。
Prometheus 通过三种方式与远程存储系统集成:
- Prometheus 可以将它摄取的样本以标准化格式写入远程 URL。
- Prometheus 可以以标准化格式从其他 Prometheus 服务器接收样本。
- Prometheus 可以从远程 URL 以标准化格式读取(返回)样本数据。

读和写协议都使用通过 HTTP 进行快速压缩的协议缓冲区编码。这些协议尚未被视为稳定的 API,将来可能会更改为使用基于 HTTP/2 的 gRPC,届时 Prometheus 和远程存储之间的所有跃点都可以安全地被假定支持 HTTP/2。
写
Prometheus将采集到的样本数据通过HTTP的形式发送给适配器(Adaptor)。而用户则可以在适配器中对接外部任意的服务。外部服务可以是真正的存储系统,公有云的存储服务,也可以是消息队列等任意形式。
读
在远程读的流程当中,当用户发起查询请求后,Promthues将向remote_read中配置的URL发起查询请求(matchers,ranges),Adaptor根据请求条件从第三方存储服务中获取响应的数据。同时将数据转换为Promthues的原始样本数据返回给Prometheus Server。
当获取到样本数据后,Prometheus 仅从远程端获取一组标签选择器和时间范围的原始系列数据。所有 PromQL 对原始数据的评估仍然发生在 Prometheus 本身
注意:启用远程读设置后,只在数据查询时有效,对于规则文件的处理,以及Metadata API的处理都只基于Prometheus本地存储完成。
配置
Prometheus配置文件中添加remote_write和remote_read配置,其中url用于指定远程读/写的HTTP服务地址。如果该URL启动了认证则可以通过basic_auth进行安全认证配置。对于https的支持需要设定tls_concig。proxy_url主要用于Prometheus无法直接访问适配器服务的情况下。
remote_write和remote_write具体配置如下所示:
1 | |
自定义Remote Storage Adaptor
remote_write
1 | |
联邦
分层联邦允许 Prometheus 扩展到具有数十个数据中心和数百万个节点的环境。在这个用例中,联邦拓扑类似于一棵树,更高级别的 Prometheus 服务器从大量从属服务器收集聚合时间序列数据
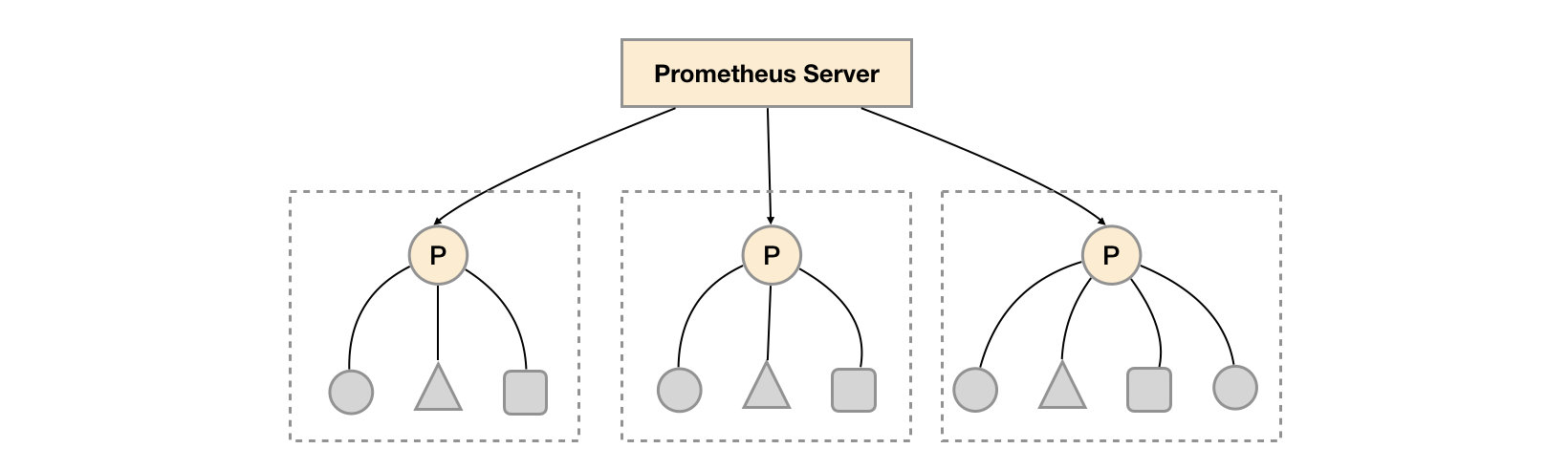
在每个数据中心部署单独的Prometheus Server,用于采集当前数据中心监控数据。并由一个中心的Prometheus Server负责聚合多个数据中心的监控数据。这一特性在Promthues中称为联邦集群。
联邦集群的核心在于每一个Prometheus Server都包含额一个用于获取当前实例中监控样本的接口/federate。对于中心Prometheus Server而言,无论是从其他的Prometheus实例还是Exporter实例中获取数据实际上并没有任何差异。
1 | |
为了有效的减少不必要的时间序列,通过params参数可以用于指定只获取某些时间序列的样本数据,例如
1 | |
通过URL中的match[]参数指定我们可以指定需要获取的时间序列。match[]参数必须是一个瞬时向量选择器,例如up或者{job=”api-server”}。配置多个match[]参数,用于获取多组时间序列的监控数据。
horbor_labels配置true可以确保当采集到的监控指标冲突时,能够自动忽略冲突的监控数据。如果为false时,prometheus会自动将冲突的标签替换为”exported_“的形式。
功能分区
联邦集群的特性可以帮助用户根据不同的监控规模对Promthues部署架构进行调整。例如如下所示,可以在各个数据中心中部署多个Prometheus Server实例。每一个Prometheus Server实例只负责采集当前数据中心中的一部分任务(Job),例如可以将不同的监控任务分离到不同的Prometheus实例当中,再有中心Prometheus实例进行聚合。
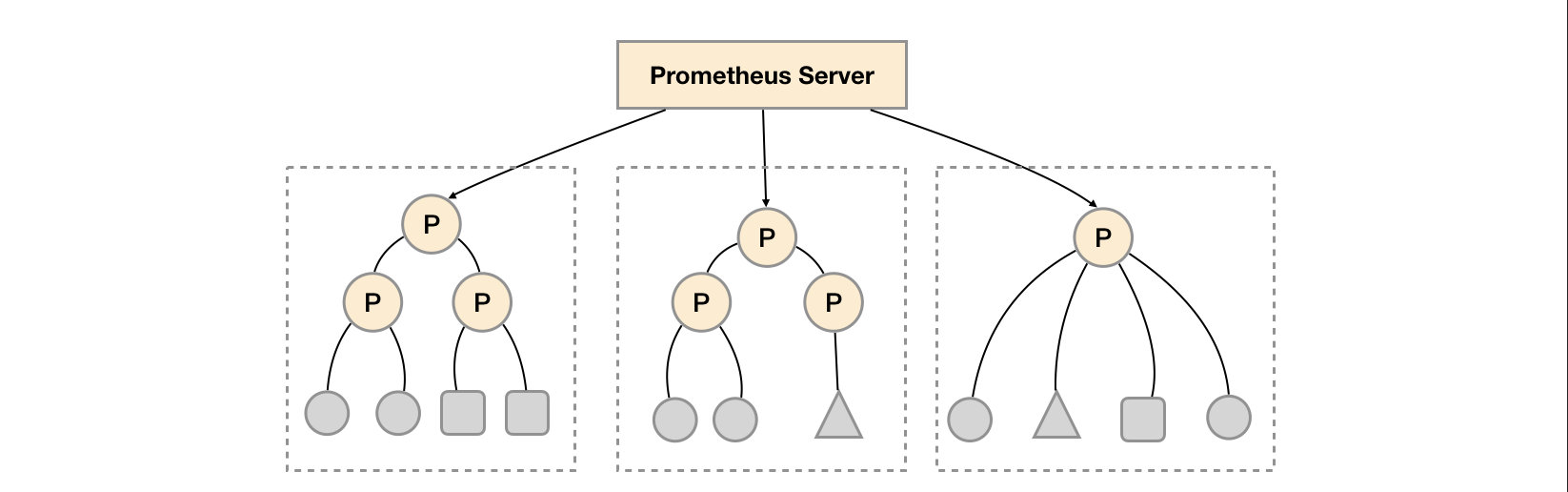
功能分区,即通过联邦集群的特性在任务级别对Prometheus采集任务进行划分,以支持规模的扩展。
Prometheus高可用
基本HA:服务可用性
由于Promthues的Pull机制的设计,为了确保Promthues服务的可用性,用户只需要部署多套Prometheus Server实例,并且采集相同的Exporter目标即可。
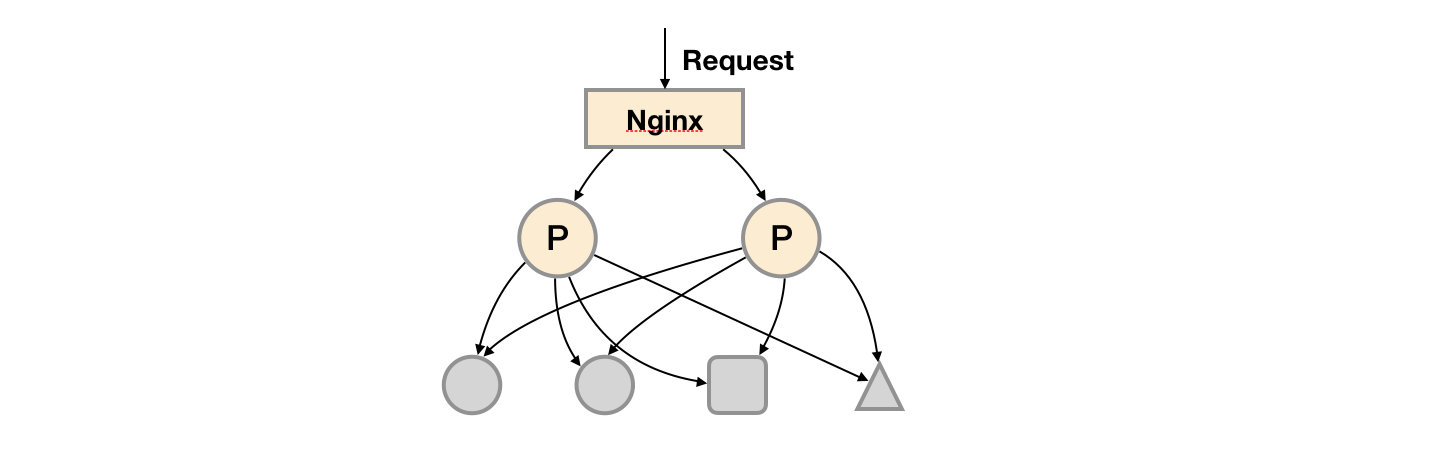
基本的HA模式只能确保Promthues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
基本HA + 远程存储
在基本HA模式的基础上通过添加Remote Storage存储支持,将监控数据保存在第三方存储服务上。
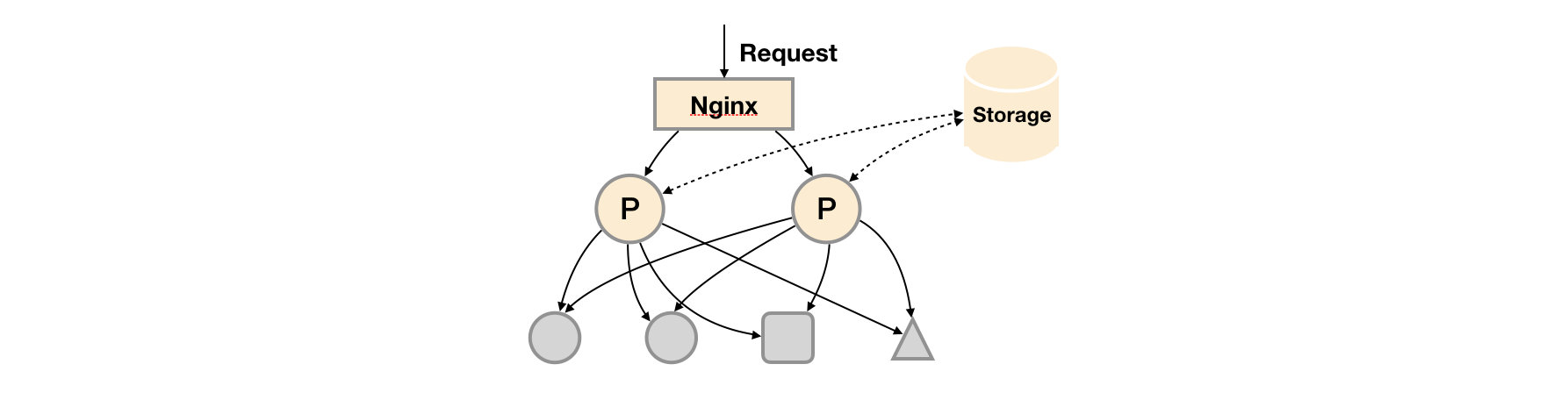
在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景。
基本HA + 远程存储 + 联邦集群
当单台Promthues Server无法处理大量的采集任务时,用户可以考虑基于Prometheus联邦集群的方式将监控采集任务划分到不同的Promthues实例当中即在任务级别功能分区。
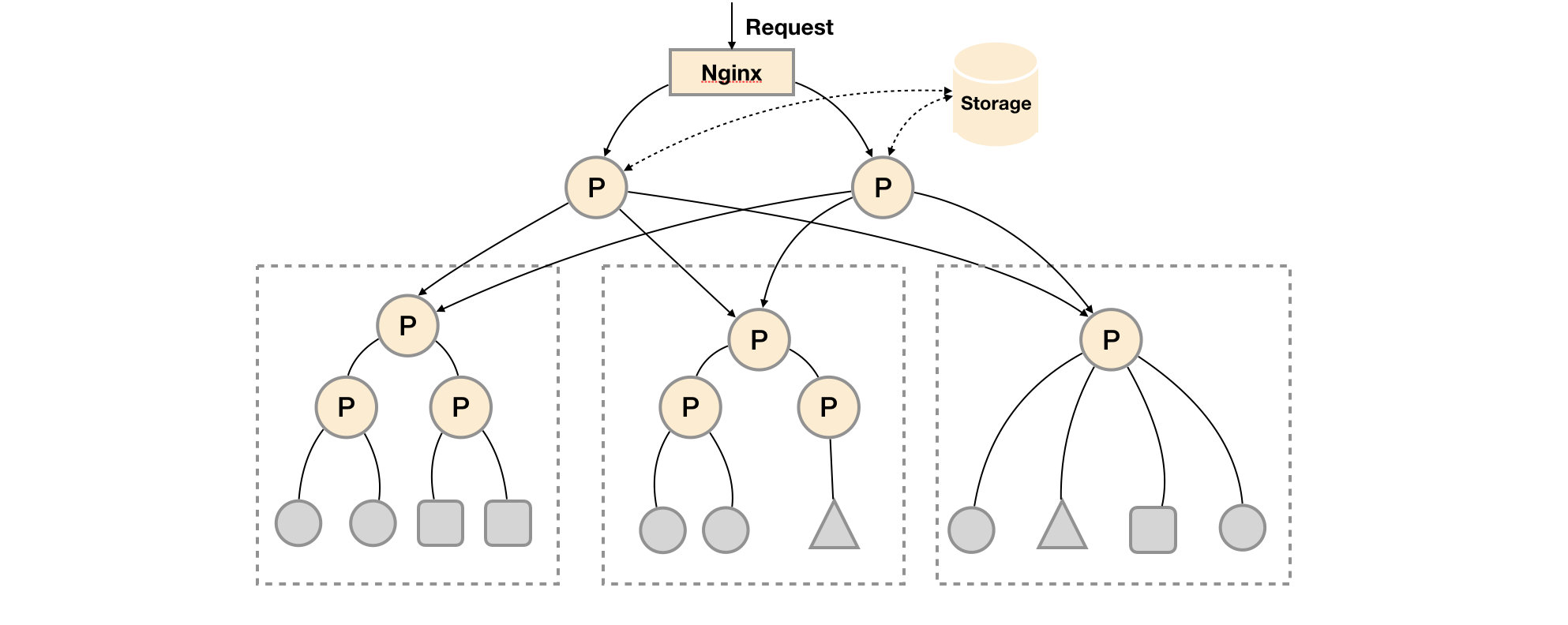 基本HA + 远程存储 + 联邦集群
基本HA + 远程存储 + 联邦集群
这种部署方式一般适用于两种场景:
场景一:单数据中心 + 大量的采集任务
这种场景下Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
场景二:多数据中心
这种模式也适合与多数据中心的情况,当Promthues Server无法直接与数据中心中的Exporter进行通讯时,在每一个数据中部署一个单独的Promthues Server负责当前数据中心的采集任务是一个不错的方式。这样可以避免用户进行大量的网络配置,只需要确保主Promthues Server实例能够与当前数据中心的Prometheus Server通讯即可。 中心Promthues Server负责实现对多数据中心数据的聚合。
按照实例进行功能分区
这时在考虑另外一种极端情况,即单个采集任务的Target数也变得非常巨大。这时简单通过联邦集群进行功能分区,Prometheus Server也无法有效处理时。这种情况只能考虑继续在实例级别进行功能划分。
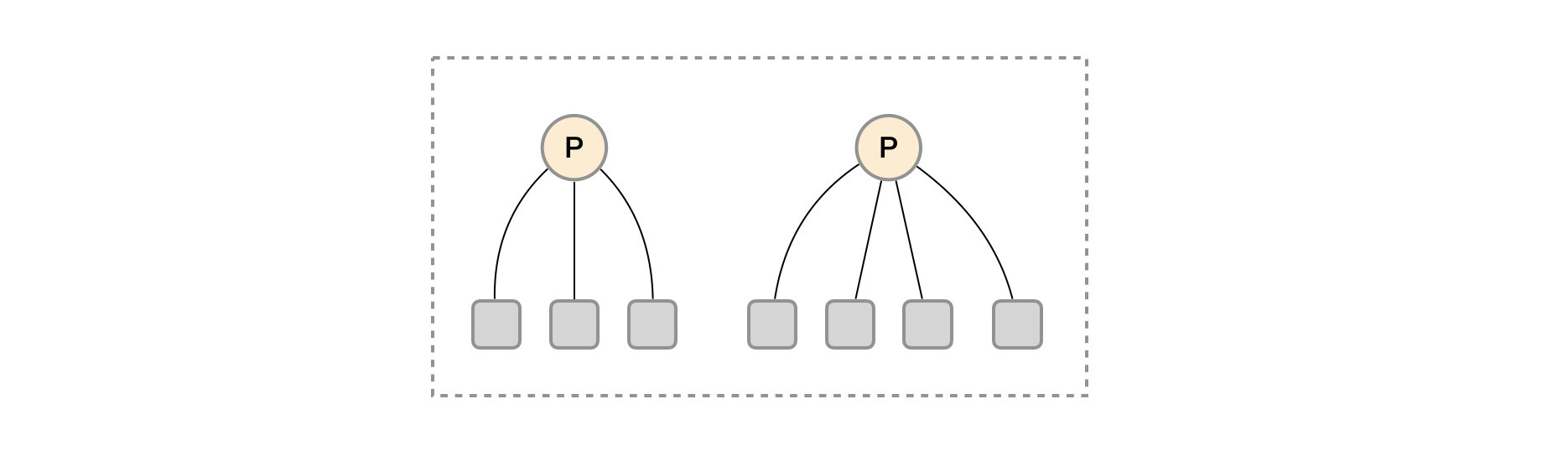 实例级别功能分区
实例级别功能分区
如上图所示,将统一任务的不同实例的监控数据采集任务划分到不同的Prometheus实例。通过relabel设置,我们可以确保当前Prometheus Server只收集当前采集任务的一部分实例的监控指标。
1 | |
并且通过当前数据中心的一个中心Prometheus Server将监控数据进行聚合到任务级别。
1 | |
Alertmanager高可用
Alertmanager成为单点
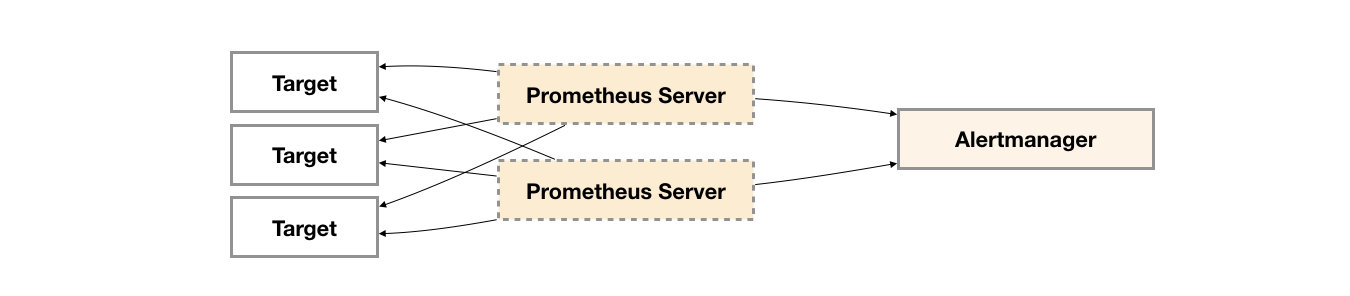
虽然Alertmanager能够同时处理多个相同的Prometheus Server所产生的告警。但是由于单个Alertmanager的存在,当前的部署结构存在明显的单点故障风险,当Alertmanager单点失效后,告警的后续所有业务全部失效。
如下所示,最直接的方式,就是尝试部署多套Alertmanager。但是由于Alertmanager之间不存在并不了解彼此的存在,因此则会出现告警通知被不同的Alertmanager重复发送多次的问题。
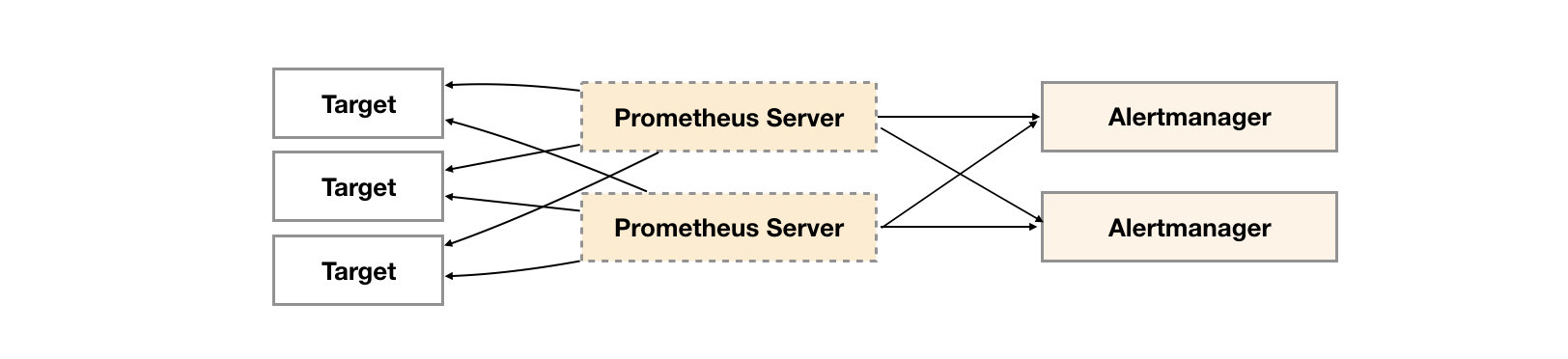
Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
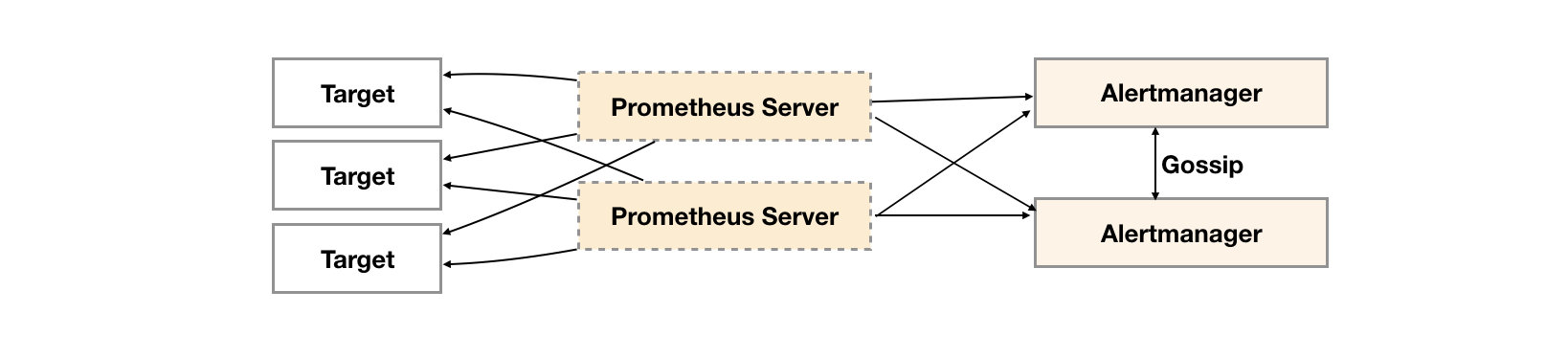
gossip 协议
用于实现分布式节点之间的信息交换和状态同步。Gossip协议同步状态类似于流言或者病毒的传播,如下所示:
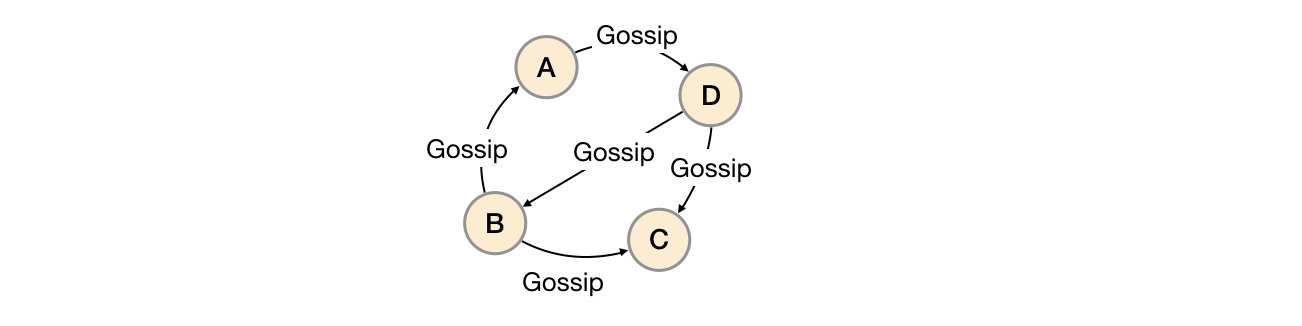
一般来说Gossip有两种实现方式分别为Push-based和Pull-based。在Push-based当集群中某一节点A完成一个工作后,随机的从其它节点B并向其发送相应的消息,节点B接收到消息后在重复完成相同的工作,直到传播到集群中的所有节点。而Pull-based的实现中节点A会随机的向节点B发起询问是否有新的状态需要同步,如果有则返回。
在简单了解了Gossip协议之后,我们来看Alertmanager是如何基于Gossip协议实现集群高可用的。如下所示,当Alertmanager接收到来自Prometheus的告警消息后,会按照以下流程对告警进行处理:
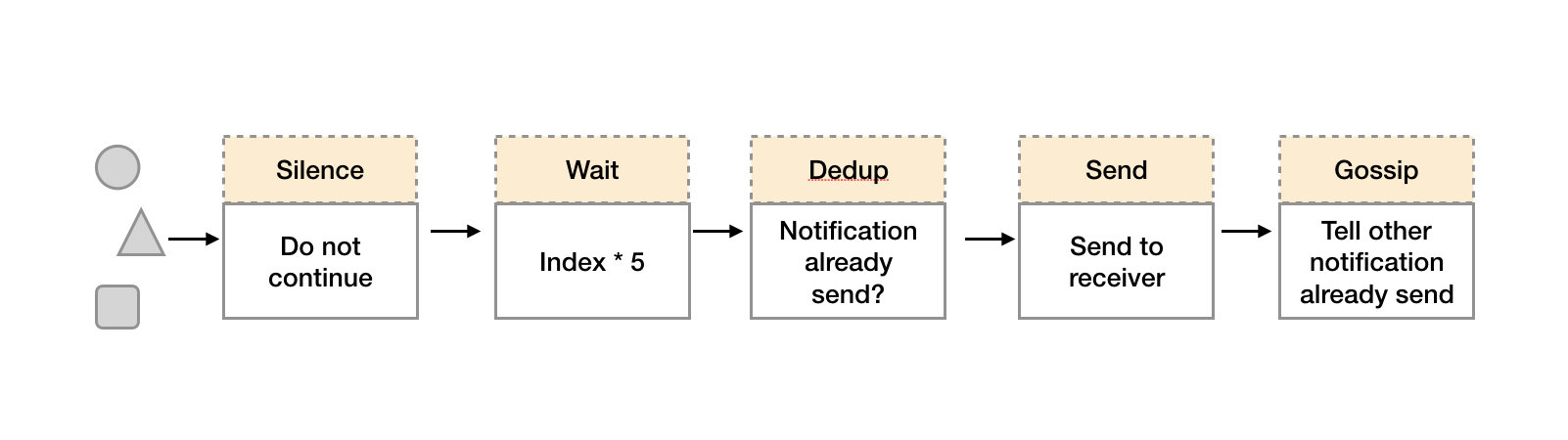 通知流水线
通知流水线
- 在第一个阶段Silence中,Alertmanager会判断当前通知是否匹配到任何的静默规则,如果没有则进入下一个阶段,否则则中断流水线不发送通知。
- 在第二个阶段Wait中,Alertmanager会根据当前Alertmanager在集群中所在的顺序(index)等待index * 5s的时间。
- 当前Alertmanager等待阶段结束后,Dedup阶段则会判断当前Alertmanager数据库中该通知是否已经发送,如果已经发送则中断流水线,不发送告警,否则则进入下一阶段Send对外发送告警通知。
- 告警发送完成后该Alertmanager进入最后一个阶段Gossip,Gossip会通知其他Alertmanager实例当前告警已经发送。其他实例接收到Gossip消息后,则会在自己的数据库中保存该通知已发送的记录。
因此如下所示,Gossip机制的关键在于两点:
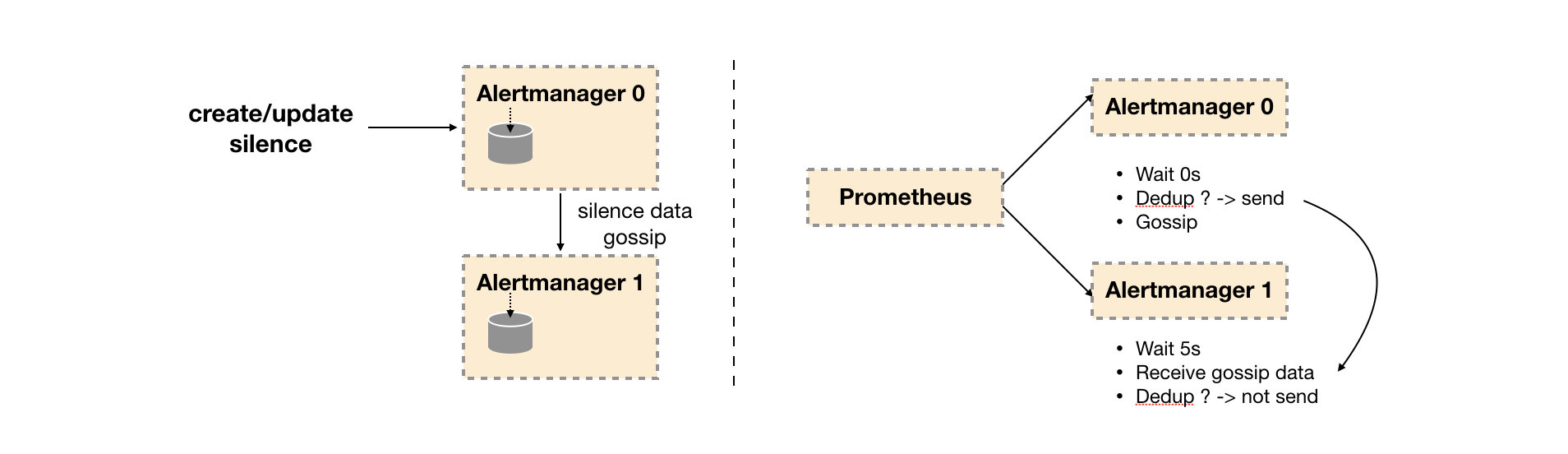 Gossip机制
Gossip机制
- Silence设置同步:Alertmanager启动阶段基于Pull-based从集群其它节点同步Silence状态,当有新的Silence产生时使用Push-based方式在集群中传播Gossip信息。
- 通知发送状态同步:告警通知发送完成后,基于Push-based同步告警发送状态。Wait阶段可以确保集群状态一致。
Alertmanager基于Gossip实现的集群机制虽然不能保证所有实例上的数据时刻保持一致,但是实现了CAP理论中的AP系统,即可用性和分区容错性。同时对于Prometheus Server而言保持了配置了简单性,Promthues Server之间不需要任何的状态同步。