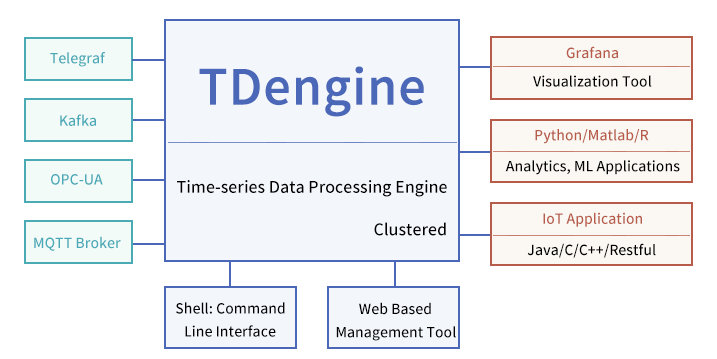
简单介绍
优势
- 10 倍以上的性能提升:定义了创新的数据存储结构,单核每秒能处理至少 2 万次请求,插入数百万个数据点,读出一千万以上数据点,比现有通用数据库快十倍以上。
- 硬件或云服务成本降至 1/5:由于超强性能,计算资源不到通用大数据方案的 1/5;通过列式存储和先进的压缩算法,存储占用不到通用数据库的 1/10。
- 全栈时序数据处理引擎:将数据库、消息队列、缓存、流式计算等功能融为一体,应用无需再集成 Kafka/Redis/HBase/Spark/HDFS 等软件,大幅降低应用开发和维护的复杂度成本。
- 强大的分析功能:无论是十年前还是一秒钟前的数据,指定时间范围即可查询。数据可在时间轴上或多个设备上进行聚合。即席查询可通过 Shell, Python, R, MATLAB 随时进行。
- 高可用性和水平扩展:通过分布式架构和一致性算法,通过多复制和集群特性,TDengine确保了高可用性和水平扩展性以支持关键任务应用程序。
- 零运维成本、零学习成本:安装集群简单快捷,无需分库分表,实时备份。类似标准 SQL,支持 RESTful,支持 Python/Java/C/C++/C#/Go/Node.js, 与 MySQL 相似,零学习成本。
- 核心开源:除了一些辅助功能外,TDengine的核心是开源的。企业再也不会被数据库绑定了。这使生态更加强大,产品更加稳定,开发者社区更加活跃。
场景
TDengine 的典型适用场景是在 IoT ,采用 TDengine,可将典型的物联网、车联网、工业互联网大数据平台的总拥有成本大幅降低。但需要指出的是,因充分利用了物联网时序数据的特点,它无法用来处理网络爬虫、微博、微信、电商、ERP、CRM 等通用型数据。
| 数据源特点和需求 | 不适用 | 可能适用 | 非常适用 | 简单说明 |
|---|---|---|---|---|
| 总体数据量巨大 | √ | TDengine 在容量方面提供出色的水平扩展功能,并且具备匹配高压缩的存储结构,达到业界最优的存储效率。 | ||
| 数据输入速度偶尔或者持续巨大 | √ | TDengine 的性能大大超过同类产品,可以在同样的硬件环境下持续处理大量的输入数据,并且提供很容易在用户环境里面运行的性能评估工具。 | ||
| 数据源数目巨大 | √ | TDengine 设计中包含专门针对大量数据源的优化,包括数据的写入和查询,尤其适合高效处理海量(千万或者更多量级)的数据源。 |

场景Example
在典型的物联网、车联网、运维监测场景中,往往有多种不同类型的数据采集设备,采集一个到多个不同的物理量。而同一种采集设备类型,往往又有多个具体的采集设备分布在不同的地点。大数据处理系统就是要将各种采集的数据汇总,然后进行计算和分析。对于同一类设备,其采集的数据都是很规则的。
数据特征
- 数据高度结构化,时序的;
- 数据极少有更新或删除操作;
- 无需传统数据库的事务处理;
- 相对互联网应用,写多读少;
- 流量平稳,根据设备数量和采集频次,可以预测出来;
- 用户关注的是一段时间的趋势,而不是某一特定时间点的值;
- 数据有保留期限;
- 数据的查询分析一定是基于时间段和空间区域;
- 除存储、查询操作外,还需要各种统计和实时计算操作;
- 数据量巨大,一天可能采集的数据就可以超过 100 亿条。
通用大数据架构为什么不适合处理物联网数据
- 开发效率低:因为不是单一软件,需要集成至少4个以上模块,而且很多模块都不是标准的POSIX或SQL接口,都有自己的开发工具、开发语言、配置等等,需要一定的学习成本。而且由于数据从一个模块流动到另外一个模块,数据一致性容易受到破坏。同时,这些模块基本上都是开源软件,总会有各种BUG,即使有技术论坛、社区的支持,一旦被一技术问题卡住,总要耗费工程师不少时间。总的来讲,需要搭建一个还不错的团队才能将这些模块顺利的组装起来,因此需要耗费较大的人力资源。
- 运行效率低:现有的这些开源软件主要是用来处理互联网上非结构化的数据,但是物联网采集的数据都是时序的、结构化的。用非结构化数据处理技术来处理结构化数据,无论是存储还是计算,消费的资源都大很多。举个例子,智能电表采集电流、电压两个量,用HBase或其他KV型数据库存储的话,其中的Row Key往往是智能电表的ID,加上其他静态标签值。每个采集量的key由Row Key,Column Family, Column Qualifier, 时间戳,键值类型等组成,然后紧跟具体的采集量的值。这样存储数据,overhead很大,浪费存储空间。而且如果要做计算的话,需要将具体采集量先解析出来。比如计算一段时间电压的平均值,就需要先将电压值从KV的存储里解析出来,放入一个数组,然后再进行计算。解析KV结构的overhead很大,导致计算的效率大幅降低。KV型存储的最大好处是schemaless, 写数据前不用定义数据结构,想怎么记录就可以怎么记录,这对于几乎每天都会更新的互联网应用而言,是个很诱人的设计。但是对于物联网、车联网等应用而言,没多少引人之处,因为物联网设备产生的数据的schema一般是不变的,即使改变,频次很低,因为相应的配置或固件需要更新才行。
- 运维成本高:每个模块,无论是Kafka, HBase, HDFS还是Redis,都有自己的管理后台,都需要单独管理。在传统的信息系统中,一个DBA只要学会管理MySQL或是Oracle就可以了,但现在一个DBA需要学会管理、配置、优化很多模块,工作量大了很多。而且由于模块数过多,定位一个问题变的更为复杂。比如用户发现有条采集的数据丢失,这丢失是Kafka, HBase,Spark,还是应用程序丢失?无法迅速定位,往往需要花很长时间,找到方法将各模块的日志关联起来才能找到原因。而且模块越多,系统整体的稳定性就越低。
- 应用推出慢、利润低:由于研发效率低,运维成本高,导致产品推向市场的时间变长,让企业丧失商机。而且这些开源软件都在演化中,要同步使用最新的版本也需要耗费一定的人力。除互联网头部公司外,中小型公司在大数据平台的人力资源成本一般都远超过专业公司的产品或服务费用。
- 对于小数据量场景,私有化部署太重:在物联网、车联网场景中,因为涉及到生产经营数据的安全,很多还是采取私有化部署。而每个私有化部署,处理的数据量有很大的区别,从几百台联网设备到数千万台设备不等。对于数据量小的场景,通用的大数据解决方案就显得过于臃肿,投入产出不成正比。因此有的平台提供商往往有两套方案,一套针对大数据场景,使用通用的大数据平台,一套针对小数据规模场景,就使用MySQL或其他DB来搞定一切。但这样导致研发、维护成本提高。
支持平台
TDengine 服务器支持的平台列表
| CentOS 6/7/8 | Ubuntu 16/18/20 | Other Linux | 统信 UOS | 银河/中标麒麟 | 凝思 V60/V80 | 华为 EulerOS | |
|---|---|---|---|---|---|---|---|
| X64 | ● | ● | ○ | ● | ● | ● | |
| 龙芯 MIPS64 | ● | ||||||
| 鲲鹏 ARM64 | ○ | ○ | ● | ||||
| 申威 Alpha64 | ○ | ● | |||||
| 飞腾 ARM64 | ○ 优麒麟 | ||||||
| 海光 X64 | ● | ● | ● | ○ | ● | ● | |
| 瑞芯微 ARM64 | ○ | ||||||
| 全志 ARM64 | ○ | ||||||
| 炬力 ARM64 | ○ | ||||||
| 华为云 ARM64 | ● |
注: ● 表示经过官方测试验证, ○ 表示非官方测试验证。
TDengine 客户端和连接器支持的平台列表
目前 TDengine 的连接器可支持的平台广泛,目前包括:X64/X86/ARM64/ARM32/MIPS/Alpha 等硬件平台,以及 Linux/Win64/Win32 等开发环境。
对照矩阵如下:
| CPU | X64 64bit | X86 32bit | ARM64 | ARM32 | MIPS 龙芯 | Alpha 申威 | X64 海光 | ||
|---|---|---|---|---|---|---|---|---|---|
| OS | Linux | Win64 | Win32 | Win32 | Linux | Linux | Linux | Linux | Linux |
| C/C++ | ● | ● | ● | ○ | ● | ● | ● | ● | ● |
| JDBC | ● | ● | ● | ○ | ● | ● | ● | ● | ● |
| Python | ● | ● | ● | ○ | ● | ● | ● | – | ● |
| Go | ● | ● | ● | ○ | ● | ● | ○ | – | – |
| NodeJs | ● | ● | ○ | ○ | ● | ● | ○ | – | – |
| C# | ● | ● | ○ | ○ | ○ | ○ | ○ | – | – |
| RESTful | ● | ● | ● | ● | ● | ● | ● | ● | ● |
注:● 表示官方测试验证通过,○ 表示非官方测试验证通过,– 表示未经验证。
基础概念
- 关系型数据库模型 ,使用标准的 SQL 语言
- 对每个数据采集点单独建表
- 保证一个采集点的数据在存储介质上是以块为单位连续存储的,如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
- 由于不同采集设备产生数据的过程完全独立,每个设备的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
- 对于一个数据采集点而言,其产生的数据是时序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
- 表的第一列必须是时间戳,即数据类型为 timestamp。对采集的数据,TDengine 将自动按照时间戳建立索引,但对采集的物理量不建任何索引。数据用列式存储方式保存。
- 超级表:同一类型数据采集点的集合,解决表的数量巨增,采集点之间的聚合操作
总结:
表用来代表一个具体的数据采集点,超级表用来代表一组相同类型的数据采集点集合
一张超级表包含有多张表,这些表具有相同的时序数据 schema,但带有不同的标签值
聚合操作时,TDengine 会先把满足标签过滤条件的表从超级表中找出来,然后再扫描这些表的时序数据,进行聚合操作,这样需要扫描的数据集会大幅减少,从而显著提高聚合计算的性能。
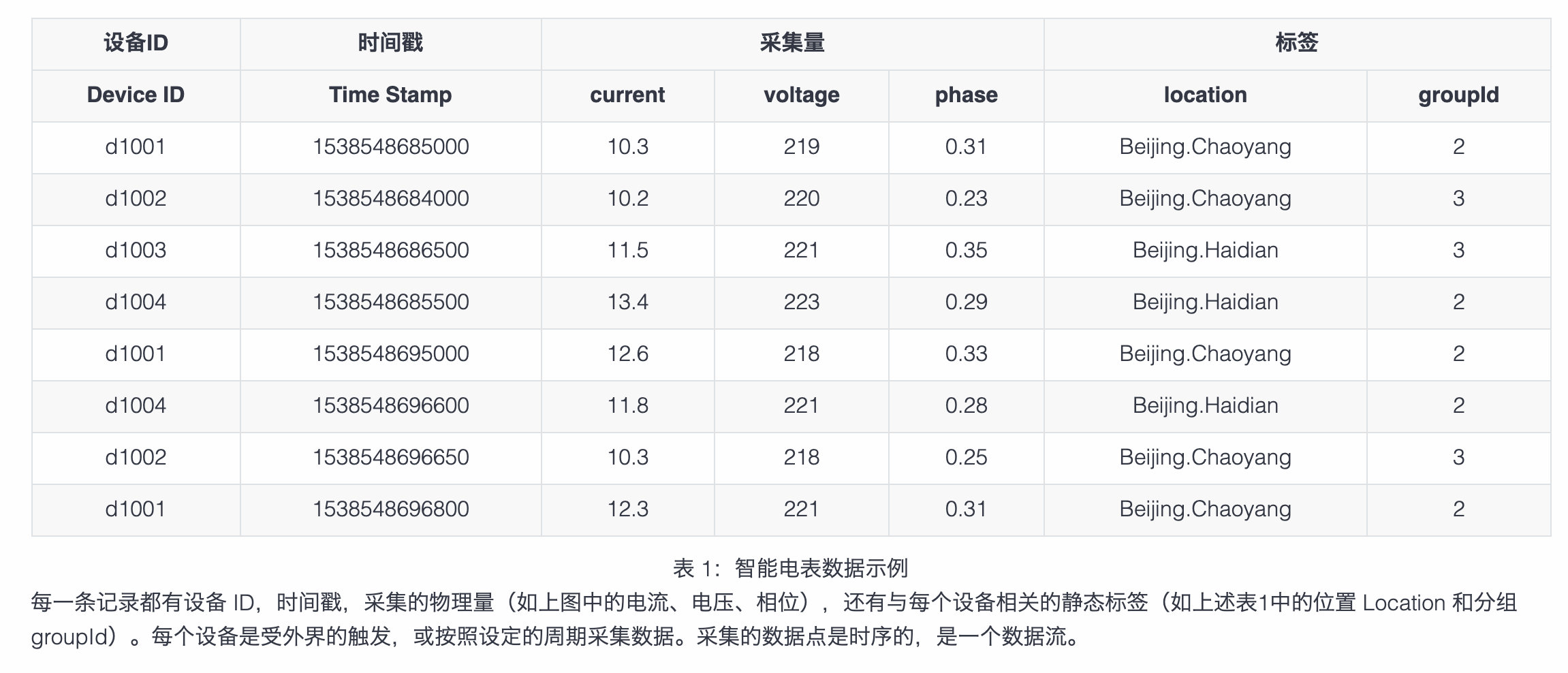
整体架构
集群(cluster)由若干数据节点(dnode)、TDengine 应用驱动(taosc)以及应用(app)组成。
数据节点(dnode)
dnode 是 TDengine 服务器侧执行代码 taosd 在物理节点上的一个运行实例,一个工作的系统必须有至少一个数据节点。
dnode 包含零到多个逻辑的虚拟节点(vnode),零或者至多一个逻辑的管理节点(mnode)。
dnode 在系统中的唯一标识由实例的 End Point (EP)决定。EP 是 dnode 所在物理节点的 FQDN + Port的组合。
通过配置不同的端口,一个物理节点(一台物理机、虚拟机或容器)可以运行多个实例,或有多个数据节点。
虚拟节点(vnode)
为更好的支持数据分片、负载均衡,防止数据过热或倾斜,数据节点被虚拟化成多个虚拟节点(vnode,图中 V2, V3, V4等)。每个 vnode 都是一个相对独立的工作单元,是时序数据存储的基本单元,具有独立的运行线程、内存空间与持久化存储的路径。
-
一个 vnode 包含一定数量的表(数据采集点)。当创建一张新表时,系统会检查是否需要创建新的 vnode。一个数据节点上能创建的 vnode 的数量取决于该数据节点所在物理节点的硬件资源。
-
一个 DB 可以有多个 vnode,一个 vnode 只属于一个 DB。
-
一个 vnode 除存储的时序数据外,也保存有所包含的表的 schema、标签值等。一个虚拟节点由所属的数据节点的EP,以及所属的 VGroup ID 在系统内唯一标识,由管理节点创建并管理。
虚拟节点组(VGroup)
不同数据节点上的 vnode 可以组成一个虚拟节点组(vnode group)来保证系统的高可靠。
虚拟节点组内采取 master/slave 的方式进行管理。写操作只能在 master vnode 上进行,系统采用异步复制的方式将数据同步到 slave vnode,这样确保了一份数据在多个物理节点上有拷贝。
一个 vgroup 里虚拟节点个数就是数据的副本数。如果一个 DB 的副本数为 N,系统必须有至少 N 数据节点。副本数在创建DB时通过参数 replica 可以指定,缺省为 1。
使用 TDengine 的多副本特性,可以不再需要昂贵的磁盘阵列等存储设备,就可以获得同样的数据高可靠性。
虚拟节点组由管理节点创建、管理,并且由管理节点分配一个系统唯一的 ID,VGroup ID。如果两个虚拟节点的 vnode group ID 相同,说明他们属于同一个组,数据互为备份。虚拟节点组里虚拟节点的个数是可以动态改变的,容许只有一个,也就是没有数据复制。VGroup ID 是永远不变的,即使一个虚拟节点组被删除,它的ID也不会被收回重复利用。
管理节点(mnode)
一个虚拟的逻辑单元,负责所有数据节点运行状态的监控和维护,以及节点之间的负载均衡(图中 M)。同时,管理节点也负责元数据(包括用户、数据库、表、静态标签等)的存储和管理,因此也称为 Meta Node。TDengine 集群中可配置多个(开源版最多不超过 3 个) mnode,它们自动构建成为一个虚拟管理节点组(图中 M0, M1, M2)。
mnode 间采用 master/slave 的机制进行管理,而且采取强一致方式进行数据同步, 任何数据更新操作只能在 Master 上进行。mnode 集群的创建由系统自动完成,无需人工干预。
每个 dnode 上至多有一个 mnode,由所属的数据节点的EP来唯一标识。每个 dnode 通过内部消息交互自动获取整个集群中所有 mnode 所在的 dnode 的EP。
TAOSC
taosc 是 TDengine 给应用提供的驱动程序(driver),负责处理应用与集群的接口交互。
这个模块负责获取并缓存元数据;将插入、查询等请求转发到正确的数据节点;
在把结果返回给应用时,还需要负责最后一级的聚合、排序、过滤等操作。
这个模块是在应用所处的物理节点上运行。同时,为支持全分布式的 RESTful 接口,taosc 在 TDengine 集群的每个 dnode 上都有一运行实例。
节点之间的通讯
应用驱动与各数据节点之间的通讯是通过 TCP/UDP 进行的。对于数据节点之间的数据复制,只采用 TCP 方式进行数据传输。
TDengine 实现了自己的超时、重传、确认等机制,以确保 UDP 的可靠传输。
对于数据量不到15K的数据包,采取 UDP 的方式进行传输,
超过 15K 的,或者是查询类的操作,自动采取 TCP 的方式进行传输。
TDengine 根据配置和数据包,会自动对数据进行压缩/解压缩,数字签名/认证等处理。
FQDN配置:一个数据节点有一个或多个 FQDN,可以在系统配置文件 taos.cfg 通过参数”fqdn”进行指定,如果没有指定,系统将自动获取计算机的 hostname 作为其 FQDN。如果节点没有配置 FQDN,可以直接将该节点的配置参数 fqdn 设置为它的IP地址。但不建议使用 IP,因为 IP 地址可变,一旦变化,将让集群无法正常工作。一个数据节点的 EP(End Point) 由 FQDN + Port 组成。采用 FQDN,需要保证 DNS 服务正常工作,或者在节点以及应用所在的节点配置好 hosts 文件。另外,这个参数值的长度需要控制在 96 个字符以内。
端口配置:一个数据节点对外的端口由 TDengine 的系统配置参数 serverPort 决定,对集群内部通讯的端口是 serverPort+5。为支持多线程高效的处理 UDP 数据,每个对内和对外的 UDP 连接,都需要占用5个连续的端口。
- 集群内数据节点之间的数据复制操作占用一个 TCP 端口,是 serverPort+10。
- 集群数据节点对外提供 RESTful 服务占用一个 TCP 端口,是 serverPort+11。
- 集群内数据节点与 Arbitrator 节点之间通讯占用一个 TCP 端口,是 serverPort+12。
因此一个数据节点总的端口范围为 serverPort 到 serverPort+12,总共 13 个 TCP/UDP 端口。使用时,需要确保防火墙将这些端口打开。每个数据节点可以配置不同的 serverPort。
集群对外连接:TDengine 集群可以容纳单个、多个甚至几千个数据节点。应用只需要向集群中任何一个数据节点发起连接即可,连接需要提供的网络参数是一数据节点的 End Point(FQDN加配置的端口号)。通过命令行CLI启动应用 taos 时,可以通过选项-h来指定数据节点的 FQDN, -P 来指定其配置的端口号,如果端口不配置,将采用 TDengine 的系统配置参数 serverPort。
集群内部通讯:各个数据节点之间通过 TCP/UDP 进行连接。一个数据节点启动时,将获取 mnode 所在的 dnode 的 EP 信息,然后与系统中的 mnode 建立起连接,交换信息。获取 mnode 的 EP 信息有三步:
- 检查 mnodeEpSet.json 文件是否存在,如果不存在或不能正常打开获得 mnode EP 信息,进入第二步;
- 检查系统配置文件 taos.cfg,获取节点配置参数 firstEp、secondEp(这两个参数指定的节点可以是不带 mnode 的普通节点,这样的话,节点被连接时会尝试重定向到 mnode 节点),如果不存在或者 taos.cfg 里没有这两个配置参数,或无效,进入第三步;
- 将自己的EP设为 mnode EP,并独立运行起来。
获取 mnode EP 列表后,数据节点发起连接,如果连接成功,则成功加入进工作的集群,如果不成功,则尝试 mnode EP 列表中的下一个。如果都尝试了,但连接都仍然失败,则休眠几秒后,再进行尝试。
MNODE的选择:TDengine 逻辑上有管理节点,但没有单独的执行代码,服务器侧只有一套执行代码 taosd。那么哪个数据节点会是管理节点呢?这是系统自动决定的,无需任何人工干预。原则如下:一个数据节点启动时,会检查自己的 End Point, 并与获取的 mnode EP List 进行比对,如果在其中,该数据节点认为自己应该启动 mnode 模块,成为 mnode。如果自己的 EP 不在 mnode EP List 里,则不启动 mnode 模块。在系统的运行过程中,由于负载均衡、宕机等原因,mnode 有可能迁移至新的 dnode,但一切都是透明的,无需人工干预,配置参数的修改,是 mnode 自己根据资源做出的决定。
新数据节点的加入:系统有了一个数据节点后,就已经成为一个工作的系统。添加新的节点进集群时,有两个步骤。
- 第一步:使用 TDengine CLI 连接到现有工作的数据节点,然后用命令”create dnode”将新的数据节点的 End Point 添加进去;
- 第二步:在新的数据节点的系统配置参数文件 taos.cfg 里,将 firstEp, secondEp 参数设置为现有集群中任意两个数据节点的 EP 即可。具体添加的详细步骤请见详细的用户手册。这样就把集群一步一步的建立起来。
重定向:无论是 dnode 还是 taosc,最先都是要发起与 mnode 的连接,但 mnode 是系统自动创建并维护的,因此对于用户来说,并不知道哪个 dnode 在运行 mnode。TDengine 只要求向系统中任何一个工作的 dnode 发起连接即可。
因为任何一个正在运行的 dnode,都维护有目前运行的 mnode EP List。当收到一个来自新启动的 dnode 或 taosc 的连接请求,如果自己不是 mnode,则将 mnode EP List 回复给对方,taosc 或新启动的 dnode 收到这个 list, 就重新尝试建立连接。当 mnode EP List 发生改变,通过节点之间的消息交互,各个数据节点就很快获取最新列表,并通知 taosc。
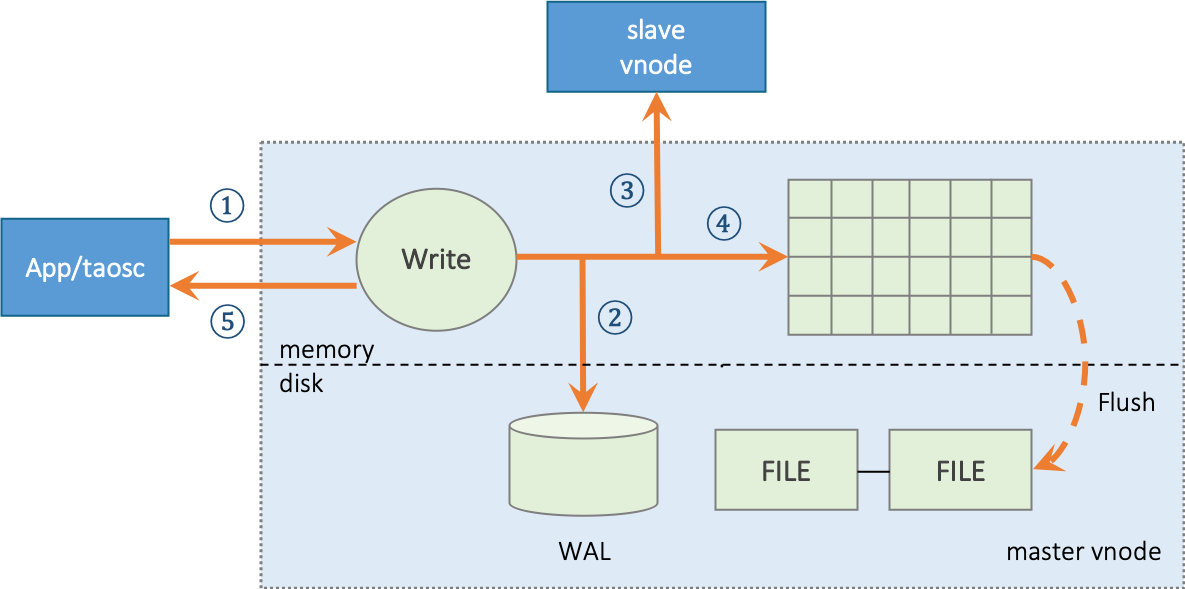
典型的消息流程
为解释 vnode、mnode、taosc 和应用之间的关系以及各自扮演的角色,下面对写入数据这个典型操作的流程进行剖析。
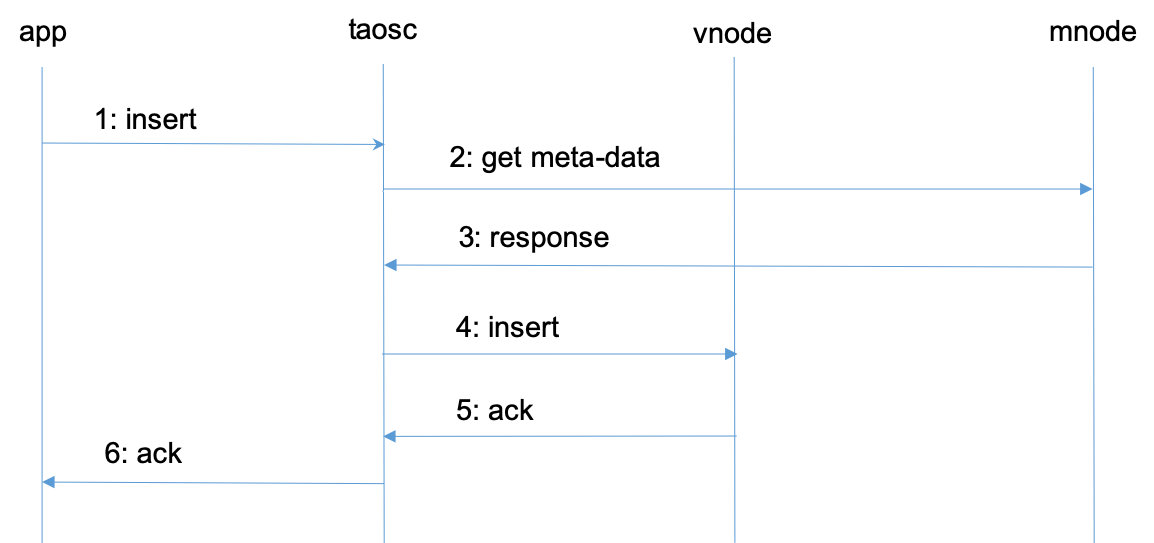
图 2 TDengine 典型的操作流程
- 应用通过 JDBC、ODBC 或其他API接口发起插入数据的请求。
- taosc 会检查缓存,看是否保存有该表的 meta data。如果有,直接到第 4 步。如果没有,taosc 将向 mnode 发出 get meta-data 请求。
- mnode 将该表的 meta-data 返回给 taosc。Meta-data 包含有该表的 schema, 而且还有该表所属的 vgroup信息(vnode ID 以及所在的 dnode 的 End Point,如果副本数为 N,就有 N 组 End Point)。如果 taosc 迟迟得不到 mnode 回应,而且存在多个 mnode, taosc 将向下一个 mnode 发出请求。
- taosc 向 master vnode 发起插入请求。
- vnode 插入数据后,给 taosc 一个应答,表示插入成功。如果 taosc 迟迟得不到 vnode 的回应,taosc 会认为该节点已经离线。这种情况下,如果被插入的数据库有多个副本,taosc 将向 vgroup 里下一个 vnode 发出插入请求。
- taosc 通知 APP,写入成功。
对于第二和第三步,taosc 启动时,并不知道 mnode 的 End Point,因此会直接向配置的集群对外服务的 End Point 发起请求。如果接收到该请求的 dnode 并没有配置 mnode,该 dnode 会在回复的消息中告知mnode EP 列表,这样 taosc 会重新向新的 mnode 的 EP 发出获取 meta-data 的请求。
对于第四和第五步,没有缓存的情况下,taosc 无法知道虚拟节点组里谁是 master,就假设第一个 vnodeID 就是 master,向它发出请求。如果接收到请求的 vnode 并不是 master,它会在回复中告知谁是 master,这样 taosc 就向建议的 master vnode 发出请求。一旦得到插入成功的回复,taosc 会缓存 master 节点的信息。
上述是插入数据的流程,查询、计算的流程也完全一致。taosc 把这些复杂的流程全部封装屏蔽了,对于应用来说无感知也无需任何特别处理。
通过 taosc 缓存机制,只有在第一次对一张表操作时,才需要访问 mnode,因此 mnode 不会成为系统瓶颈。但因为 schema 有可能变化,而且 vgroup 有可能发生改变(比如负载均衡发生),因此 taosc 会定时和mnode 交互,自动更新缓存。
存储模型
TDengine 存储的数据包括采集的时序数据以及库、表相关的元数据、标签数据等,这些数据具体分为三部分:
- 时序数据:存放于 vnode 里,由 data、head 和 last 三个文件组成,数据量大,查询量取决于应用场景。容许乱序写入,但暂时不支持删除操作,并且仅在 update 参数设置为 1 时允许更新操作。通过采用一个采集点一张表的模型,一个时间段的数据是连续存储,对单张表的写入是简单的追加操作,一次读,可以读到多条记录,这样保证对单个采集点的插入和查询操作,性能达到最优。
- 标签数据:存放于 vnode 里的 meta 文件,支持增删改查四个标准操作。数据量不大,有 N 张表,就有 N 条记录,因此可以全内存存储。如果标签过滤操作很多,查询将十分频繁,因此 TDengine 支持多核多线程并发查询。只要计算资源足够,即使有数千万张表,过滤结果能毫秒级返回。
- 元数据:存放于 mnode 里,包含系统节点、用户、DB、Table Schema 等信息,支持增删改查四个标准操作。这部分数据的量不大,可以全内存保存,而且由于客户端有缓存,查询量也不大。因此目前的设计虽是集中式存储管理,但不会构成性能瓶颈。
与典型的 NoSQL 存储模型相比,TDengine 将标签数据与时序数据完全分离存储,它具有两大优势:
- 能够极大地降低标签数据存储的冗余度:一般的 NoSQL 数据库或时序数据库,采用的 K-V 存储,其中的 Key 包含时间戳、设备 ID、各种标签。每条记录都带有这些重复的内容,浪费存储空间。而且如果应用要在历史数据上增加、修改或删除标签,需要遍历数据,重写一遍,操作成本极其昂贵。
- 能够实现极为高效的多表之间的聚合查询:做多表之间聚合查询时,先把符合标签过滤条件的表查找出来,然后再查找这些表相应的数据块,这样大幅减少要扫描的数据集,从而大幅提高查询效率。而且标签数据采用全内存的结构进行管理和维护,千万级别规模的标签数据查询可以在毫秒级别返回
存储模型与数据分区、分片
TDengine 是通过 vnode 来实现数据分片的,通过一个时间段一个数据文件来实现时序数据分区的。
分片
vnode(虚拟数据节点)负责为采集的时序数据提供写入、查询和计算功能。为便于负载均衡、数据恢复、支持异构环境,TDengine 将一个数据节点根据其计算和存储资源切分为多个 vnode。这些 vnode 的管理是TDengine 自动完成的,对应用完全透明。
对于单独一个数据采集点,无论其数据量多大,一个 vnode(或 vnode group, 如果副本数大于 1)有足够的计算资源和存储资源来处理(如果每秒生成一条 16 字节的记录,一年产生的原始数据不到 0.5G),因此 TDengine 将一张表(一个数据采集点)的所有数据都存放在一个 vnode 里,而不会让同一个采集点的数据分布到两个或多个 dnode 上。而且一个 vnode 可存储多个数据采集点(表)的数据,一个 vnode 可容纳的表的数目的上限为一百万。设计上,一个 vnode 里所有的表都属于同一个 DB。一个数据节点上,除非特殊配置,一个 DB 拥有的 vnode 数目不会超过系统核的数目。
创建 DB 时,系统并不会马上分配资源。
- 但当创建一张表时,系统将看是否有已经分配的 vnode, 且该 vnode 是否有空余的表空间,
- 如果有,立即在该有空位的 vnode 创建表。
- 如果没有,系统将从集群中,根据当前的负载情况,在一个 dnode 上创建一新的 vnode, 然后创建表。
- 如果DB有多个副本,系统不是只创建一个 vnode,而是一个 vgroup (虚拟数据节点组)。系统对 vnode 的数目没有任何限制,仅仅受限于物理节点本身的计算和存储资源。
每张表的 meta data(包含 schema, 标签等)也存放于 vnode 里,而不是集中存放于 mnode,实际上这是对 Meta 数据的分片,这样便于高效并行的进行标签过滤操作。
分区
每个数据文件只包含一个时间段的时序数据,时间段的长度由 DB 的配置参数 days 决定。这种按时间段分区的方法还便于高效实现数据的保留策略,只要数据文件超过规定的天数(系统配置参数 keep),将被自动删除。而且不同的时间段可以存放于不同的路径和存储介质,以便于大数据的冷热管理,实现多级存储。
总的来说,TDengine 是通过 vnode 以及时间两个维度,对大数据进行切分,便于并行高效的管理,实现水平扩展。
负载均衡
每个 dnode 都定时向 mnode(虚拟管理节点)报告其状态(包括硬盘空间、内存大小、CPU、网络、虚拟节点个数等),因此 mnode 了解整个集群的状态。基于整体状态,当 mnode 发现某个dnode负载过重,它会将dnode 上的一个或多个 vnode 挪到其他 dnode。在挪动过程中,对外服务继续进行,数据插入、查询和计算操作都不受影响。
如果 mnode 一段时间没有收到 dnode 的状态报告,mnode 会认为这个 dnode 已经离线。如果离线时间超过一定时长(时长由配置参数 offlineThreshold 决定),该 dnode 将被 mnode 强制剔除出集群。
该dnode 上的 vnodes 如果副本数大于 1,系统将自动在其他 dnode 上创建新的副本,以保证数据的副本数。如果该 dnode 上还有 mnode, 而且 mnode 的副本数大于1,系统也将自动在其他 dnode 上创建新的 mnode, 以保证 mnode 的副本数。
当新的数据节点被添加进集群,因为新的计算和存储被添加进来,系统也将自动启动负载均衡流程。
负载均衡过程无需任何人工干预,应用也无需重启,将自动连接新的节点,完全透明。
提示:负载均衡由参数 balance 控制,决定开启/关闭自动负载均衡。
数据写入与复制流程
如果一个数据库有 N 个副本,那一个虚拟节点组就有 N 个虚拟节点,但是只有一个是 master,其他都是 slave。当应用将新的记录写入系统时,只有 master vnode 能接受写的请求。如果 slave vnode 收到写的请求,系统将通知 taosc 需要重新定向。
-
master vnode 收到应用的数据插入请求,验证OK,进入下一步;
-
如果系统配置参数 walLevel 大于 0,vnode 将把该请求的原始数据包写入数据库日志文件 WAL。如果 walLevel 设置为 2,而且 fsync 设置为 0,TDengine 还将 WAL 数据立即落盘,以保证即使宕机,也能从数据库日志文件中恢复数据,避免数据的丢失;
-
如果有多个副本,vnode 将把数据包转发给同一虚拟节点组内的 slave vnodes, 该转发包带有数据的版本号(version);
slave vnode 收到 Master vnode 转发了的数据插入请求。检查 last version 是否与 master 一致,如果一致,进入下一步。如果不一致,需要进入同步状态。异步复制的方式进行数据同步
-
写入内存,并将记录加入到 skip list;
-
master vnode 返回确认信息给应用,表示写入成功。
-
如果第 2、3、4 步中任何一步失败,将直接返回错误给应用。
缓存与持久化
缓存
TDengine 通过查询函数向用户提供毫秒级的数据获取能力。直接将最近到达的数据保存在缓存中,可以更加快速地响应用户针对最近一条或一批数据的查询分析,整体上提供更快的数据库查询响应能力。需要注意的是,TDengine 重启以后系统的缓存将被清空,之前缓存的数据均会被批量写入磁盘,缓存的数据将不会像专门的 key-value 缓存系统再将之前缓存的数据重新加载到缓存中。
每个 vnode 有自己独立的内存,而且由多个固定大小的内存块组成,不同 vnode 之间完全隔离。数据写入时,类似于日志的写法,数据被顺序追加写入内存,但每个 vnode 维护有自己的 skip list,便于迅速查找。当三分之一以上的内存块写满时,启动落盘操作,而且后续写的操作在新的内存块进行。这样,一个 vnode 里有三分之一内存块是保留有最近的数据的,以达到缓存、快速查找的目的。一个 vnode 的内存块的个数由配置参数 blocks 决定,内存块的大小由配置参数 cache 决定。
持久化
TDengine 在数据落盘时会打开新的数据库日志文件,在落盘成功后则会删除老的数据库日志文件,避免日志文件无限制地增长。
TDengine 将一个 vnode 保存在持久化存储的数据切分成多个文件,每个文件只保存固定天数的数据,这个天数由系统配置参数 days 决定。切分成多个文件后,给定查询的起止日期,无需任何索引,就可以立即定位需要打开哪些数据文件,大大加快读取速度。
对于采集的数据,一般有保留时长,这个时长由系统配置参数 keep 决定。超过这个设置天数的数据文件,将被系统自动删除,释放存储空间。
一个典型工作状态的 vnode 中总的数据文件数为:向上取整(keep/days)+1个。总的数据文件个数不宜过大,也不宜过小。10到100以内合适。基于这个原则,可以设置合理的 days。目前的版本,参数 keep 可以修改,但对于参数 days,一旦设置后,不可修改。
在每个数据文件里,一张表的数据是一块一块存储的。一张表可以有一到多个数据文件块。在一个文件块里,数据是列式存储的,占用的是一片连续的存储空间,这样大大提高读取速度。文件块的大小由系统参数 maxRows (每块最大记录条数)决定,缺省值为 4096。这个值不宜过大,也不宜过小。过大,定位具体时间段的数据的搜索时间会变长,影响读取速度;过小,数据块的索引太大,压缩效率偏低,也影响读取速度。
数据写入磁盘时,根据系统配置参数 comp 决定是否压缩数据。TDengine 提供了三种压缩选项:无压缩、一阶段压缩和两阶段压缩,分别对应 comp 值为 0、1 和 2 的情况。一阶段压缩根据数据的类型进行了相应的压缩,压缩算法包括 delta-delta 编码、simple 8B 方法、zig-zag 编码、LZ4 等算法。二阶段压缩在一阶段压缩的基础上又用通用压缩算法进行了压缩,压缩率更高。
每个数据文件(.data 结尾)都有一个对应的索引文件(.head 结尾),该索引文件对每张表都有一数据块的摘要信息,记录了每个数据块在数据文件中的偏移量,数据的起止时间等信息,以帮助系统迅速定位需要查找的数据。每个数据文件还有一对应的 last 文件(.last 结尾),该文件是为防止落盘时数据块碎片化而设计的。如果一张表落盘的记录条数没有达到系统配置参数 minRows(每块最小记录条数),将被先存储到 last 文件,等下次落盘时,新落盘的记录将与 last 文件的记录进行合并,再写入数据文件。
企业版:配置系统参数 dataDir 让多个挂载的硬盘被系统同时使用,将不同时间段的数据存储在挂载的不同介质上的目录里,从而实现不同“热度”的数据存储在不同的存储介质上,充分利用存储,节约成本。
查询
查询流程
SQL 语句的解析和校验工作在客户端完成。解析 SQL 语句并生成抽象语法树(Abstract Syntax Tree, AST),然后对其进行校验和检查。以及向管理节点(mnode)请求查询中指定表的元数据信息(table metadata)。
根据元数据信息中的 End Point 信息,将查询请求序列化后发送到该表所在的数据节点(dnode)。dnode 接收到查询请求后,识别出该查询请求指向的虚拟节点(vnode),将消息转发到 vnode 的查询执行队列。vnode 的查询执行线程建立基础的查询执行环境,并立即返回该查询请求,同时开始执行该查询。
客户端在获取查询结果的时候,dnode 的查询执行队列中的工作线程会等待 vnode 执行线程执行完成,才能将查询结果返回到请求的客户端。
采样、插值
在 TDengine 中引入关键词 interval 来进行时间轴上固定长度时间窗口的切分,并按照时间窗口对数据进行聚合,对窗口范围内的数据按需进行聚合。例如:
1 | |
针对 d1001 设备采集的数据,按照1小时的时间窗口返回每小时存储的记录数量。
在需要连续获得查询结果的应用场景下,如果给定的时间区间存在数据缺失,会导致该区间数据结果也丢失。TDengine 提供策略针对时间轴聚合计算的结果进行插值,通过使用关键词 fill 就能够对时间轴聚合结果进行插值。例如:
1 | |
针对 d1001 设备采集数据统计每小时记录数,如果某一个小时不存在数据,则返回之前一个小时的统计数据。TDengine 提供前向插值(prev)、线性插值(linear)、NULL值填充(NULL)、特定值填充(value)。
不同的采集点数据进行聚合
TDengine 引入超级表(STable)的概念。超级表用来代表一特定类型的数据采集点,它是包含多张表的表集合,集合里每张表的模式(schema)完全一致,但每张表都带有自己的静态标签,标签可以有多个,可以随时增加、删除和修改。应用可通过指定标签的过滤条件,对一个 STable 下的全部或部分表进行聚合或统计操作,这样大大简化应用的开发。其具体流程如下图所示:
- 应用将一个查询条件发往系统;
- taosc 将超级表的名字发往 meta node(管理节点);
- 管理节点将超级表所拥有的 vnode 列表发回 taosc;
- taosc 将计算的请求连同标签过滤条件发往这些 vnode 对应的多个数据节点;
- 每个 vnode 先在内存里查找出自己节点里符合标签过滤条件的表的集合,然后扫描存储的时序数据,完成相应的聚合计算,将结果返回给 taosc;
- taosc 将多个数据节点返回的结果做最后的聚合,将其返回给应用。
由于 TDengine 在 vnode 内将标签数据与时序数据分离存储,通过在内存里过滤标签数据,先找到需要参与聚合操作的表的集合,将需要扫描的数据集大幅减少,大幅提升聚合计算速度。同时,由于数据分布在多个 vnode/dnode,聚合计算操作在多个 vnode 里并发进行,又进一步提升了聚合的速度。 对普通表的聚合函数以及绝大部分操作都适用于超级表,语法完全一样,细节请看 TAOS SQL。
预计算
在数据块头部记录该数据块中存储数据的统计信息:包括最大值、最小值、和。我们称之为预计算单元。如果查询处理涉及整个数据块的全部数据,直接使用预计算结果,完全不需要读取数据块的内容。由于预计算数据量远小于磁盘上存储的数据块数据的大小,对于磁盘 I/O 为瓶颈的查询处理,使用预计算结果可以极大地减小读取 I/O 压力,加速查询处理的流程。
容灾
基本概念和定义
版本(version):
一个虚拟节点组里多个虚拟节点互为备份,来保证数据的有效与可靠,是依靠虚拟节点组的数据版本号来维持的。TDengine2.0设计里,对于版本的定义如下:客户端发起增加、删除、修改的流程,无论是一条记录还是多条,只要是在一个请求里,这个数据更新请求被TDengine的一个虚拟节点收到后,经过合法性检查后,可以被写入系统时,就会被分配一个版本号。这个版本号在一个虚拟节点里从1开始,是单调连续递增的。无论这条记录是采集的时序数据还是meta data, 一样处理。当Master转发一个写入请求到slave时,必须带上版本号。一个虚拟节点将一数据更新请求写入WAL时,需要带上版本号。
不同虚拟节点组的数据版本号是完全独立的,互不相干的。版本号本质上是数据更新记录的transaction ID,但用来标识数据集的版本。
角色(role):
一个虚拟节点可以是master, slave, unsynced或offline状态。
- master: 具有最新的数据,容许客户端往里写入数据,一个虚拟节点组,至多一个master.
- slave:与master是同步的,但不容许客户端往里写入数据,根据配置,可以容许客户端对其进行查询。
- unsynced: 节点处于非同步状态,比如虚拟节点刚启动、或与其他虚拟节点的连接出现故障等。处于该状态时,该虚拟节点既不能提供写入,也不能提供查询服务,自己设置的。
- offline: 由于宕机或网络原因,无法访问到某虚拟节点时,其他虚拟节点将该虚拟节点标为离线。但请注意,该虚拟节点本身的状态可能是unsynced或其他,但不会是离线。
Quorum:
指数据写入成功所需要的确认数。对于异步复制,quorum设为1,具有master角色的虚拟节点自己确认即可。对于同步复制,需要至少大于等于2。原则上,Quorum >=1 并且 Quorum <= replication(副本数)。这个参数在启动一个同步模块实例时需要提供。
WAL:
TDengine的WAL(Write Ahead Log)与cassandra的commit log, mySQL的bin log, Postgres的WAL没本质区别。没有写入数据库文件,还保存在内存的数据都会先存在WAL。当数据已经成功写入数据库数据文件,相应的WAL会被删除。但需要特别指明的是,在TDengine系统里,有几点:
- 每个虚拟节点有自己独立的wal
- WAL里包含而且仅仅包含来自客户端的数据更新操作,每个更新操作都会被打上一个版本号
异地容灾、IDC迁移
从上述 master 和 slave 流程可以看出,TDengine 采用的是异步复制的方式进行数据同步。这种方式能够大幅提高写入性能,网络延时对写入速度不会有大的影响。通过配置每个物理节点的IDC和机架号,可以保证对于一个虚拟节点组,虚拟节点由来自不同 IDC、不同机架的物理节点组成,从而实现异地容灾。因此 TDengine 原生支持异地容灾,无需再使用其他工具。
另一方面,TDengine 支持动态修改副本数,一旦副本数增加,新加入的虚拟节点将立即进入数据同步流程,同步结束后,新加入的虚拟节点即可提供服务。而在同步过程中,master 以及其他已经同步的虚拟节点都可以对外提供服务。利用这一特性,TDengine 可以实现无服务中断的 IDC 机房迁移。只需要将新 IDC 的物理节点加入现有集群,等数据同步完成后,再将老的 IDC 的物理节点从集群中剔除即可。
但是,这种异步复制的方式,存在极小的时间窗口,丢失写入的数据。具体场景如下:
- master vnode 完成了它的 5 步操作,已经给 APP 确认写入成功,然后宕机
- slave vnode 收到写入请求后,在第 2 步写入日志之前,处理失败
- slave vnode 将成为新的 master,从而丢失了一条记录
理论上,只要是异步复制,就无法保证 100% 不丢失。但是这个窗口极小,master 与 slave 要同时发生故障,而且发生在刚给应用确认写入成功之后。
主从选择
Vnode 会保持一个数据版本号(version),对内存数据进行持久化存储时,对该版本号也进行持久化存储。每个数据更新操作,无论是采集的时序数据还是元数据,这个版本号将增加 1。
一个 vnode 启动时,角色(master、slave) 是不定的,数据是处于未同步状态,它需要与虚拟节点组内其他节点建立 TCP 连接,并互相交换 status,其中包括 version 和role。通过 status 的交换,系统进入选主流程,规则如下:
- 如果只有一个副本,该副本永远就是 master
- 所有副本都在线时,版本最高的被选为 master
- 在线的虚拟节点数过半,而且有虚拟节点是 slave 的话,该虚拟节点自动成为 master
- 对于 2 和 3,如果多个虚拟节点满足成为 master 的要求,那么虚拟节点组的节点列表里,最前面的选为 master
选主流程
- 同一组的两个虚拟节点之间(vnode A, vnode B)建立连接,中断,vnode A将立即把vnode B的role设置为offline
- 如果检测到在线的节点数没有超过一半,则将自己的状态设置为unsynced.
- 如果在线的虚拟节点数超过一半,会检查master节点是否存在
- 存在,则会决定是否将自己状态改为slave或启动数据恢复流程。
- 不存在,则会检查自己保存的各虚拟节点的状态信息与从另一节点接收到的是否一致,
- 如果一致,说明节点组里状态已经稳定一致,则会触发选举流程。
- 如果不一致,说明状态还没趋于一致,即使master不存在,也不进行选主。由于要求状态信息一致才进行选举,每个虚拟节点根据同样的信息,会选出同一个虚拟节点做master,无需投票表决。
- 自己的状态是根据规则自己决定并修改的,并不需要其他节点同意,包括成为master。一个节点无权修改其他节点的状态。
- 如果一个虚拟节点检测到自己或其他虚拟节点的role发生改变,该节点会广播它自己保存的各个虚拟节点的状态信息(role和version)。
与RAFT相比的异同
数据一致性协议流行的有两种,Paxos与Raft. 本设计的实现与Raft有很多类同之处,下面做一些比较
相同之处:
- 三大流程一致:Raft里有Leader election, replication, safety,完全对应TDengine的选举、数据转发、数据恢复三个流程。
- 节点状态定义一致:Raft里每个节点有Leader, Follower, Candidate三个状态,TDengine里是Master, Slave, Unsynced, Offline。多了一个offlince, 但本质上是一样的,因为offline是外界看一个节点的状态,但该节点本身是处于master, slave 或unsynced的。
- 数据转发流程完全一样,Master(leader)需要等待回复确认。
- 数据恢复流程几乎一样,Raft没有涉及历史数据同步问题,只考虑了WAL数据同步。
不同之处:
- 选举流程不一样:Raft里任何一个节点是candidate时,主动向其他节点发出vote request,如果超过半数回答Yes,这个candidate就成为Leader,开始一个新的term。而TDengine的实现里,节点上线、离线或角色改变都会触发状态消息在节点组内传播,等节点组里状态稳定一致之后才触发选举流程,因为状态稳定一致,基于同样的状态信息,每个节点做出的决定会是一致的,一旦某个节点符合成为master的条件,无需其他节点认可,它会自动将自己设为master。TDengine里,任何一个节点检测到其他节点或自己的角色发生改变,就会向节点组内其他节点进行广播。Raft里不存在这样的机制,因此需要投票来解决。
- 对WAL的一条记录,Raft用term + index来做唯一标识。但TDengine只用version(类似index),在TDengine实现里,仅仅用version是完全可行的, 因为TDengine的选举机制,没有term的概念。
如果整个虚拟节点组全部宕机,重启,但不是所有虚拟节点都上线,这个时候TDengine是不会选出master的,因为未上线的节点有可能有最高version的数据。而RAFT协议,只要超过半数上线,就会选出Leader。
同步复制
对于数据一致性要求更高的场景,异步数据复制无法满足要求,因为有极小的概率丢失数据,因此 TDengine 提供同步复制的机制供用户选择。在创建数据库时,除指定副本数 replica 之外,用户还需要指定新的参数 quorum。如果 quorum 大于1,它表示每次master转发给副本时,需要等待 quorum-1 个回复确认,才能通知应用,数据在 slave 已经写入成功。如果在一定的时间内,得不到 quorum-1 个回复确认,master vnode 将返回错误给应用。
采用同步复制,系统的性能会有所下降,而且 latency 会增加。因为元数据要强一致,mnode 之间的数据同步缺省就是采用的同步复制。
复制实例:
复制模块只是一可执行的代码,复制实例是指正在运行的复制模块的一个实例,一个节点里,可以存在多个实例。原则上,一个节点有多少虚拟节点,就可以启动多少实例。对于副本数为1的场景,应用可以决定是否需要启动同步实例。应用启动一个同步模块的实例时,需要提供的就是虚拟节点组的配置信息,包括:
- 虚拟节点个数,即replication number
- 各虚拟节点所在节点的信息,包括node的end point
- quorum, 需要的数据写入成功的确认数
- 虚拟节点的初始版本号
数据复制模块的基本工作原理
TDengine采取的是Master-Slave模式进行同步,与流行的RAFT一致性算法比较一致。总结下来,有几点:
- 一个vgroup里有一到多个虚拟节点,每个虚拟节点都有自己的角色
- 客户端只能向角色是master的虚拟节点发起数据更新操作,因为master具有最新版本的数据,如果向非Master发起数据更新操作,会直接收到错误
- 客户端可以向master, 也可以向角色是Slave的虚拟节点发起查询操作,但不能对unsynced的虚拟节点发起任何操作
- 如果master不存在,这个vgroup是不能对外提供数据更新和查询服务的
- master收到客户端的数据更新操作时,会将其转发给slave节点
- 一个虚拟节点的版本号比master低的时候,会发起数据恢复流程,成功后,才会成为slave
少数虚拟节点写入成功的问题
写入成功的确认数大于0,但小于配置的Quorum, 虽然有虚拟节点数据更新成功,master仍然会认为数据更新失败,并通知客户端写入失败
已经成功写入数据的虚拟节点将成为新的master,组内的其他虚拟节点将从master那里恢复数据。
因为写入失败,客户端会重新写入数据。但对于TDengine而言,是OK的。因为时序数据都是有时间戳的,时间戳相同的数据更新操作,第一次会执行,但第二次会自动扔掉。对于Meta Data(增加、删除库、表等等)的操作,也是OK的。一张表、库已经被创建或删除,再创建或删除,不会被执行的。
在TDengine的设计里,虚拟节点与虚拟节点之间,是一个TCP连接,是一个pipeline,数据块一个接一个按顺序在这个pipeline里等待处理。一旦某个数据块的处理失败,这个连接会被重置,后续的数据块的处理都会失败。因此不会存在Pipeline里一个数据块更新失败,但下一个数据块成功的可能。
虚拟节点之间的网络连接
-
peerFd 节点之间的状态交换、数据包的转发
两个虚拟节点之间的TCP连接,总是由IP地址(UINT32)小的节点作为TCP客户端发起。一旦TCP连接被中断,虚拟节点能通过TCP socket自动检测到,将对方标为offline。如果监测到任何错误(比如数据恢复流程),虚拟节点将主动重置该连接。
一旦作为客户端的节点连接不成或中断,它将周期性的每隔一秒钟去试图去连接一次。因为TCP本身有心跳机制,虚拟节点之间不再另行提供心跳。
-
syncFd 发起数据恢复流程,它与Master将建立起专有的TCP连接
数据恢复完成后,该连接会被关闭。而且为限制资源的使用,系统只容许一定数量(配置参数tsMaxSyncNum)的数据恢复的socket存在。如果超过这个数字,系统会将新的数据恢复请求延后处理。
任意一个节点,无论有多少虚拟节点,都会启动而且只会启动一个TCP server, 来接受来自其他虚拟节点的上述两类TCP的连接请求。当TCP socket建立起来,客户端侧发送的消息体里会带有vgId(全局唯一的vgroup ID), TCP 服务器侧会检查该vgId是否已经在该节点启动运行。如果已经启动运行,就接受其请求。如果不存在,就直接将连接请求关闭。在TDengine代码里,mnode group的vgId设置为1。
数据恢复流程
一虚拟节点(vnode B) 处于unsynced状态,master存在(vnode A),而且其版本号比master的低,它将立即启动数据恢复流程。
先恢复archived data(file), 然后恢复wal
archived data
- 通过已经建立的TCP连接,发送sync req给master节点
- master收到sync req后,以client的身份,向vnode B主动建立一新的专用于同步的TCP连接(syncFd)
- 新的TCP连接建立成功后,master将开始retrieve流程,对应的,vnode B将同步启动restore流程
- Retrieve/Restore流程里,先处理所有archived data (vnode里的data, head, last文件),后处理WAL data。
- 对于archived data,master将通过回调函数getFileInfo获取数据文件的基本信息,包括文件名、magic以及文件大小。
- master 将获得的文件名、magic以及文件大小发给vnode B
- vnode B将回调函数getFile获得magic和文件大小,如果两者一致,就认为无需同步,如果两者不一致 ,就认为需要同步。vnode B将结果通过消息FileAck发回master
- 如果文件需要同步,master就调用sendfile把整个文件发往vnode B
- 如果文件不需要同步,master(vnode A)就重复5,6,7,8,直到所有文件被处理完
WAL
从同步文件启动起,sync模块会通过inotify监控所有处理过的file以及wal。一旦发现被处理过的文件有更新变化,同步流程将中止,会重新启动。因为有可能落盘操作正在进行(比如历史数据导入,内存数据落盘),把已经处理过的文件进行了修改,需要重新同步才行。
- master节点调用回调函数getWalInfo,获取WAL的文件名。
- 如果getWalInfo返回值大于0,表示该文件还不是最后一个WAL,因此master调用sendfile一下把该文件发送给vnode B
- 如果getWalInfo返回时为0,表示该文件是最后一个WAL,因为文件可能还处于写的状态中,sync模块要根据WAL Head的定义逐条读出记录,然后发往vnode B。
- vnode A读取TCP连接传来的数据,按照WAL Head,逐条读取,如果版本号比现有的大,调用回调函数writeToCache,交给应用处理。如果小,直接扔掉。
- 上述流程循环,直到所有WAL文件都被处理完。处理完后,master就会将新来的数据包通过Forward消息转发给slave。
对于最后一个WAL (LastWal)的处理逻辑有点复杂,因为这个文件往往是打开写的状态,有很多场景需要考虑,比如:
- LastWal文件size在增长,需要重新读;
- LastWal文件虽然已经打开写,但内容为空;
- LastWal文件已经被关闭,应用生成了新的Last WAL文件;
- LastWal文件没有被关闭,但数据落盘的原因,没有读到完整的一条记录;
- LastWal文件没有被关闭,但数据落盘的原因,还有部分记录暂时读取不到;
sync模块通过inotify监控LastWal文件的更新和关闭操作。而且在确认已经尽可能读完LastWal的数据后,会将对方同步状态设置为SYNC_CACHE。该状态下,master节点会将新的记录转发给vnode B,而此时vnode B并没有完成同步,需要把这些转发包先存在recv buffer里,等WAL处理完后,vnode A再把recv buffer里的数据包通过回调writeToCache交给应用处理。
等vnode B把这些buffered forwards处理完,同步流程才算结束,vnode B正式变为slave。
Master分布均匀性
因为Master负责写、转发,消耗的资源会更多,因此Master在整个集群里分布均匀比较理想。
给一个具体例子,系统里仅仅有三个节点,IP地址分别为IP1, IP2, IP3. 在各个节点上,TDengine创建了多个虚拟节点组,每个虚拟节点组都有三个副本。如果三个副本的顺序在所有虚拟节点组里都是IP1, IP2, IP3, 那毫无疑问,master将集中在IP1这个节点,这是我们不想看到的。
但是,如果在创建虚拟节点组时,增加随机性,这个问题就不存在了。比如在vgroup 1, 顺序是IP1, IP2, IP3, 在vgroup 2里,顺序是IP2, IP3, IP1, 在vgroup 3里,顺序是IP3, IP1, IP2。最后master的分布会是均匀的。
因此在创建一个虚拟节点组时,应用需要保证节点的顺序是round robin或完全随机。
Split Brain
TDengine提供Arbitrator的解决方法。Arbitrator是一个节点,它的任务就是接受任何虚拟节点的连接请求,并保持它。
选举流程中,有个强制要求,那就是一定有超过半数的虚拟节点在线。但是如果replication正好是偶数,这个时候,完全可能存在splt brain问题。
在配置参数中,应用可以提供Arbitrator的IP地址。如果是奇数个副本,复制模块不会与这个arbitrator去建立连接,但如果是偶数个副本,就会主动去建立连接。
高级功能
连续查询
连续查询是TDengine定期自动执行的查询,采用滑动窗口的方式进行计算,是一种简化的时间驱动的流式计算。针对库中的表或超级表,TDengine可提供定期自动执行的连续查询,用户可让TDengine推送查询的结果,也可以将结果再写回到TDengine中。每次执行的查询是一个时间窗口,时间窗口随着时间流动向前滑动。在定义连续查询的时候需要指定时间窗口(time window, 参数interval)大小和每次前向增量时间(forward sliding times, 参数sliding)。
TDengine提供的连续查询与普通流计算中的时间窗口计算具有以下区别:
- 不同于流计算的实时反馈计算结果,连续查询只在时间窗口关闭以后才开始计算。例如时间周期是1天,那么当天的结果只会在23:59:59以后才会生成。
- 如果有历史记录写入到已经计算完成的时间区间,连续查询并不会重新进行计算,也不会重新将结果推送给用户。对于写回TDengine的模式,也不会更新已经存在的计算结果。(只计算新的记录)
- 使用连续查询推送结果的模式,服务端并不缓存客户端计算状态,也不提供Exactly-Once的语意保证。如果用户的应用端崩溃,再次拉起的连续查询将只会从再次拉起的时间开始重新计算最近的一个完整的时间窗口。如果使用写回模式,TDengine可确保数据写回的有效性和连续性。
例子
下面以智能电表场景为例介绍连续查询的具体使用方法。假设我们通过下列SQL语句创建了超级表和子表:
1 | |
我们已经知道,可以通过下面这条SQL语句以一分钟为时间窗口、30秒为前向增量统计这些电表的平均电压。
1 | |
只要在最初的查询语句前面加上 create table {tableName} as 就可以了,例如:
1 | |
会自动创建一个名为 avg_vol 的新表,然后每隔30秒,TDengine会增量执行 as 后面的 SQL 语句,并将查询结果写入这个表中,用户程序后续只要从 avg_vol 中查询数据即可。例如:

需要注意,查询时间窗口的最小值是10毫秒,没有时间窗口范围的上限。
为了尽量避免原始数据延迟写入导致的问题,TDengine中连续查询的计算有一定的延迟。也就是说,一个时间窗口过去后,TDengine并不会立即计算这个窗口的数据,所以要稍等一会(一般不会超过1分钟)才能查到计算结果。
数据订阅
用户可使用普通查询语句订阅数据库中的一张或多张表。TDengine的订阅与推送服务的状态是客户端维持,TDengine服务器并不维持。因此如果应用重启,从哪个时间点开始获取最新数据,由应用决定。客户端定时轮询服务器是否有新的记录到达,有新的记录到达就会将结果反馈到客户。
场景
如果我们希望当某个电表的电流超过一定限制(比如10A)后能得到通知并进行一些处理, 有两种方法:
-
一是分别对每张子表进行查询,每次查询后记录最后一条数据的时间戳,后续只查询这个时间戳之后的数据(电表数量的增加,查询数量也会增加,客户端和服务端的性能都会受到影响)
1
2
3
4select * from D1001 where ts > {last_timestamp1} and current > 10; select * from D1002 where ts > {last_timestamp2} and current > 10; ... -
对超级表进行查询。这样,无论有多少电表,都只需一次查询(last_timestamp的选取有问题,不同电表的数据到达TDengine的时间也会有差异,数据的产生时间(也就是数据时间戳)和数据入库的时间一般并不相同)
1
select * from meters where ts > {last_timestamp} and current > 10;
订阅的topic实际上是它的名字,因为订阅功能是在客户端API中实现的,所以没必要保证它全局唯一,但需要它在一台客户端机器上唯一。
报警
它要求程序从最近一段时间的数据中筛选出符合一定条件的数据,并基于这些数据根据定义好的公式计算出一个结果,当这个结果符合某个条件且持续一定时间后,以某种形式通知用户。
请参考博客 使用 TDengine 进行报警监测
数据库操作
该超级表下有 1 万张表,表名为 “d0” 到 “d9999”,每张表有 1 万条记录,每条记录有 (ts, current, voltage, phase) 四个字段,时间戳从 “2017-07-14 10:40:00 000” 到 “2017-07-14 10:40:09 999”,每张表带有标签 location 和 groupId,groupId 被设置为 1 到 10, location 被设置为 “beijing” 或者 “shanghai”。
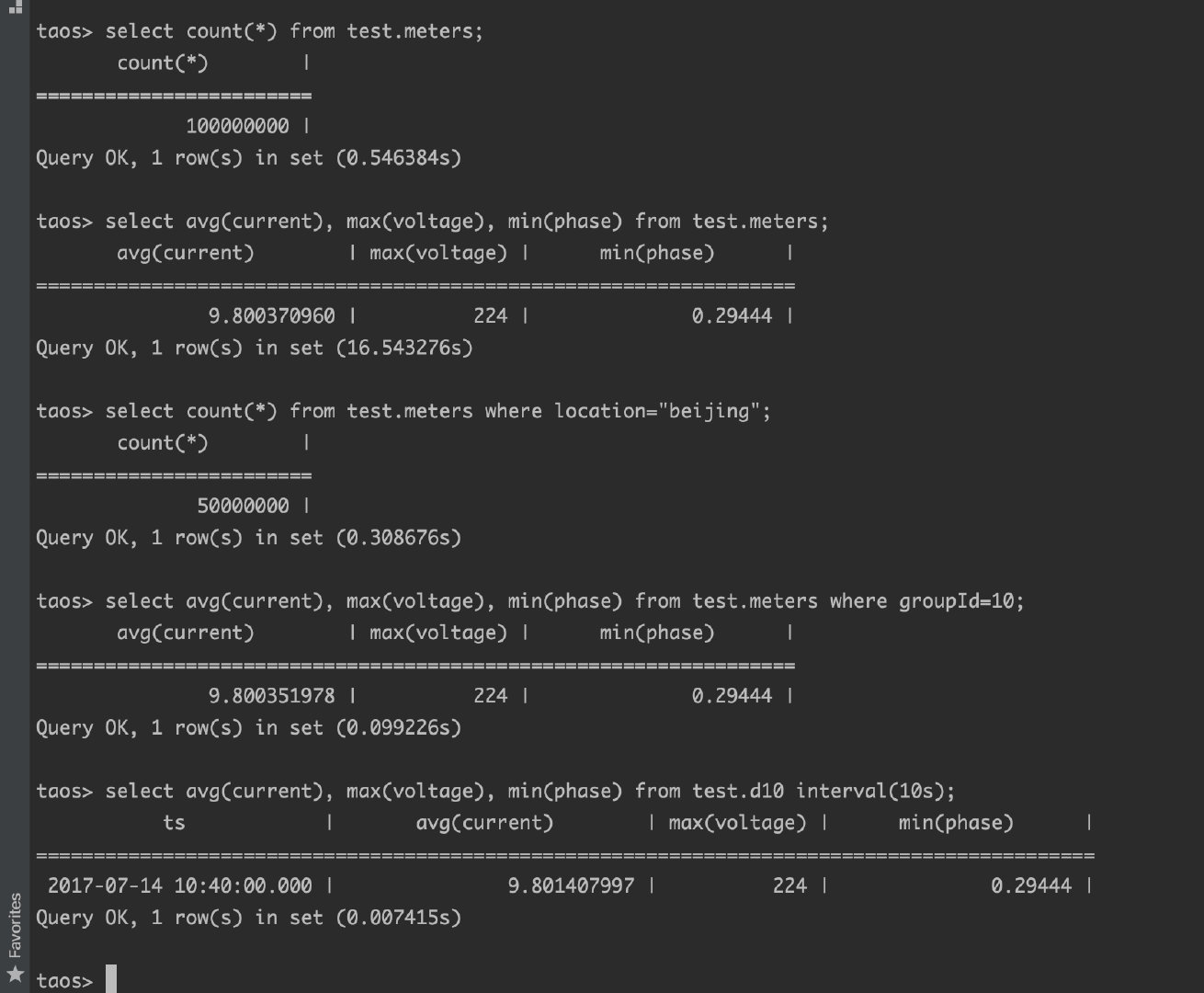
1 | |
1 | |
EMQX连接TDengine
docker 准备
1 | |
验证方式
-
tdengine
1
2
3
4
5
6
7
8curl -u root:taosdata -d 'show databases' 127.0.0.1:6041/rest/sql curl -X POST 'http://127.0.0.1:6041/rest/sql' \ -H 'Authorization: Basic cm9vdDp0YW9zZGF0YQ==' \ --data-raw 'show databases' {"status":"succ","head":["name","created_time","ntables","vgroups","replica","quorum","days","keep","cache(MB)","blocks","minrows","maxrows","wallevel","fsync","comp","cachelast","precision","update","status"],"column_meta":[["name",8,32],["created_time",9,8],["ntables",4,4],["vgroups",4,4],["replica",3,2],["quorum",3,2],["days",3,2],["keep",8,24],["cache(MB)",4,4],["blocks",4,4],["minrows",4,4],["maxrows",4,4],["wallevel",2,1],["fsync",4,4],["comp",2,1],["cachelast",2,1],["precision",8,3],["update",2,1],["status",8,10]],"data":[["test","2021-11-15 02:47:43.093",10000,4,1,1,10,"3650",16,6,100,4096,1,3000,2,0,"ms",0,"ready"],["log","2021-11-15 02:46:35.231",4,1,1,1,10,"30",1,3,100,4096,1,3000,2,0,"us",0,"ready"]],"rows":2}
-
emqx
http://127.0.0.1:18083/ admin\public
配置EMQX
使用规则引擎
添加资源
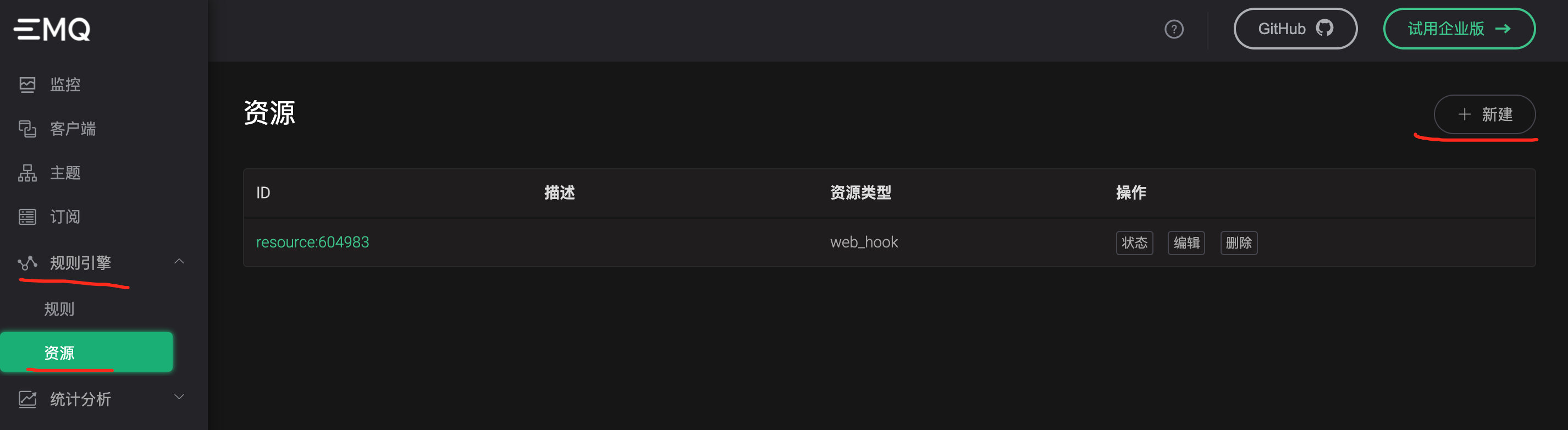
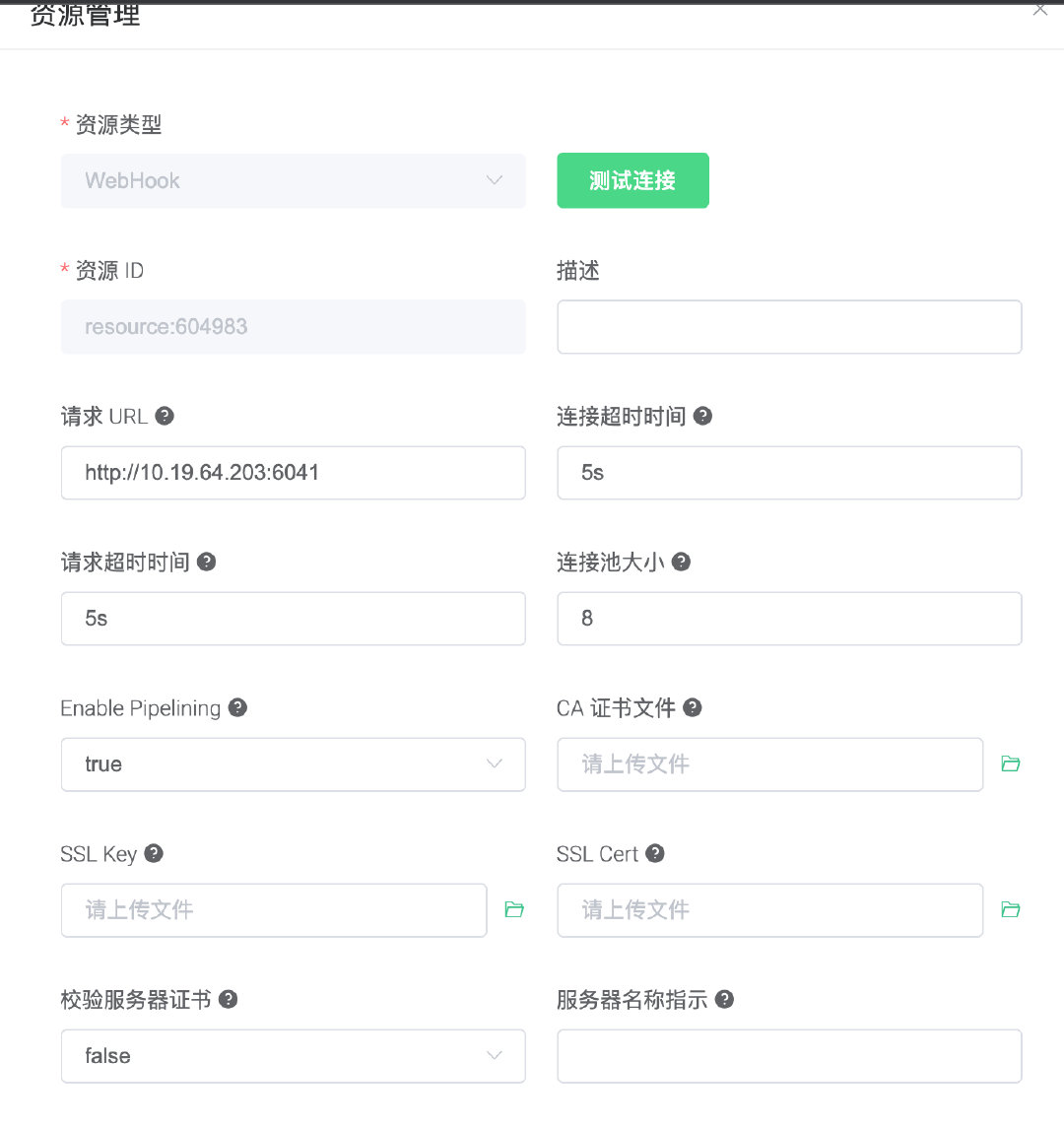
url必须是ip:port这种,不然请求会报错
1 | |
添加规则和响应动作
规则
1 | |
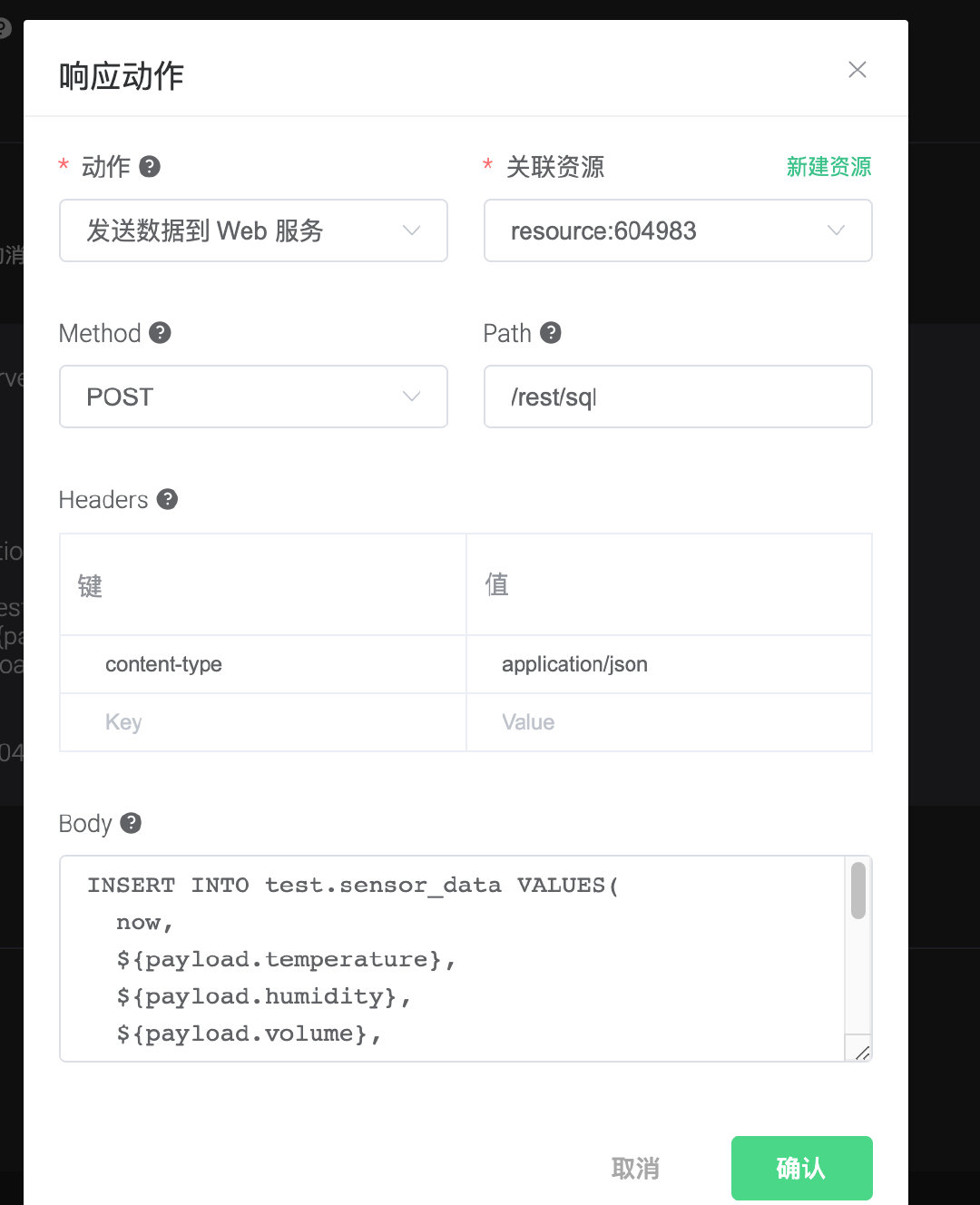
1 | |
这个还有个关于pm2.5的问题emq的payload字段不要带 . 关键字,不然会规则引擎会有意外
1 | |
报错
1 | |
配置tdengine
1 | |
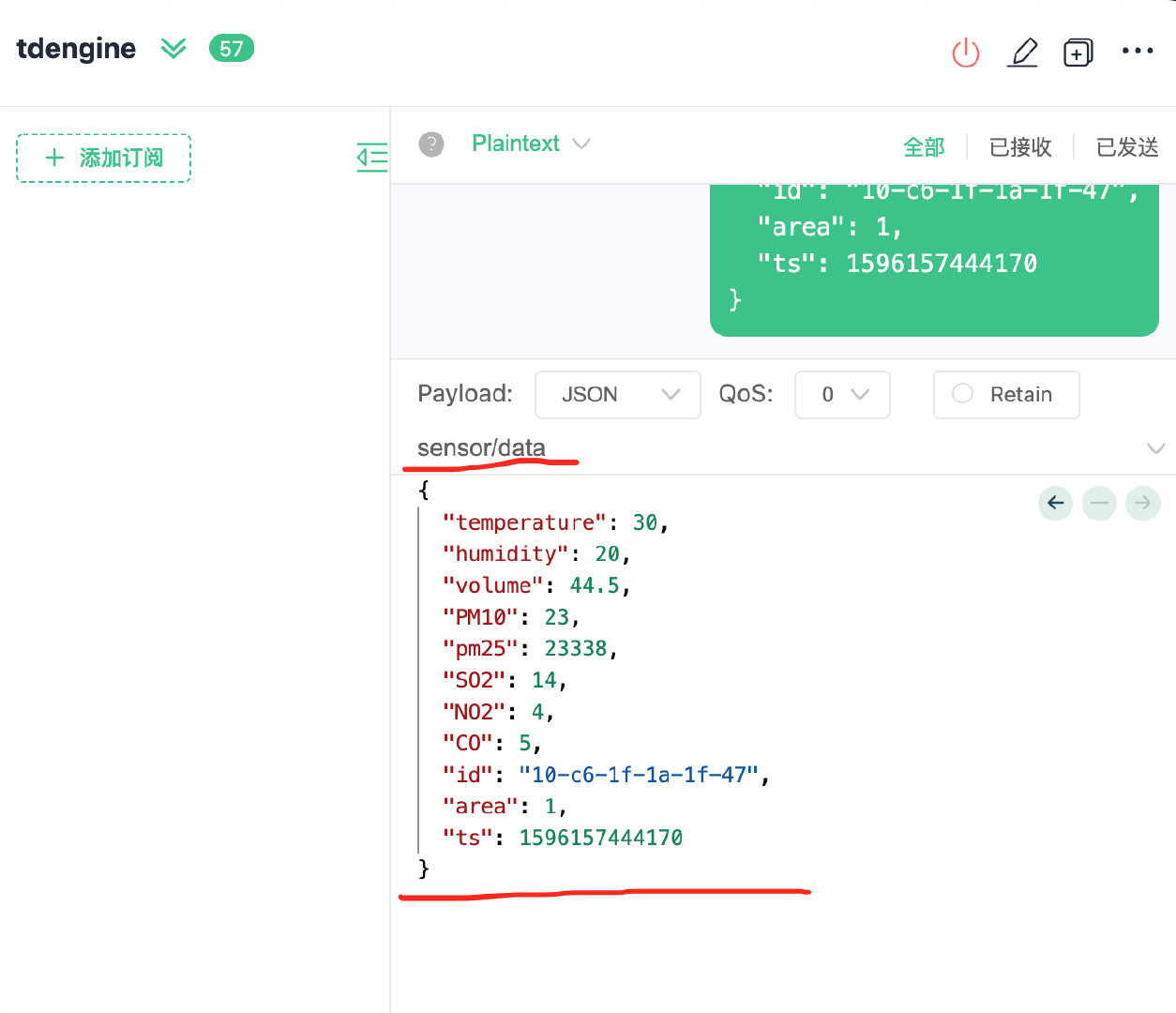
模拟push payload
k8s 部署
修改helm chart文件
由于FQDN设置的问题,需要对helm chart文件进行修改,以保证不同的数据节点之间可以相互连接。
templates/statefulset.yaml文件中:
1 | |
修改为
1 | |
TAOS_NUM_OF_MNODES报错
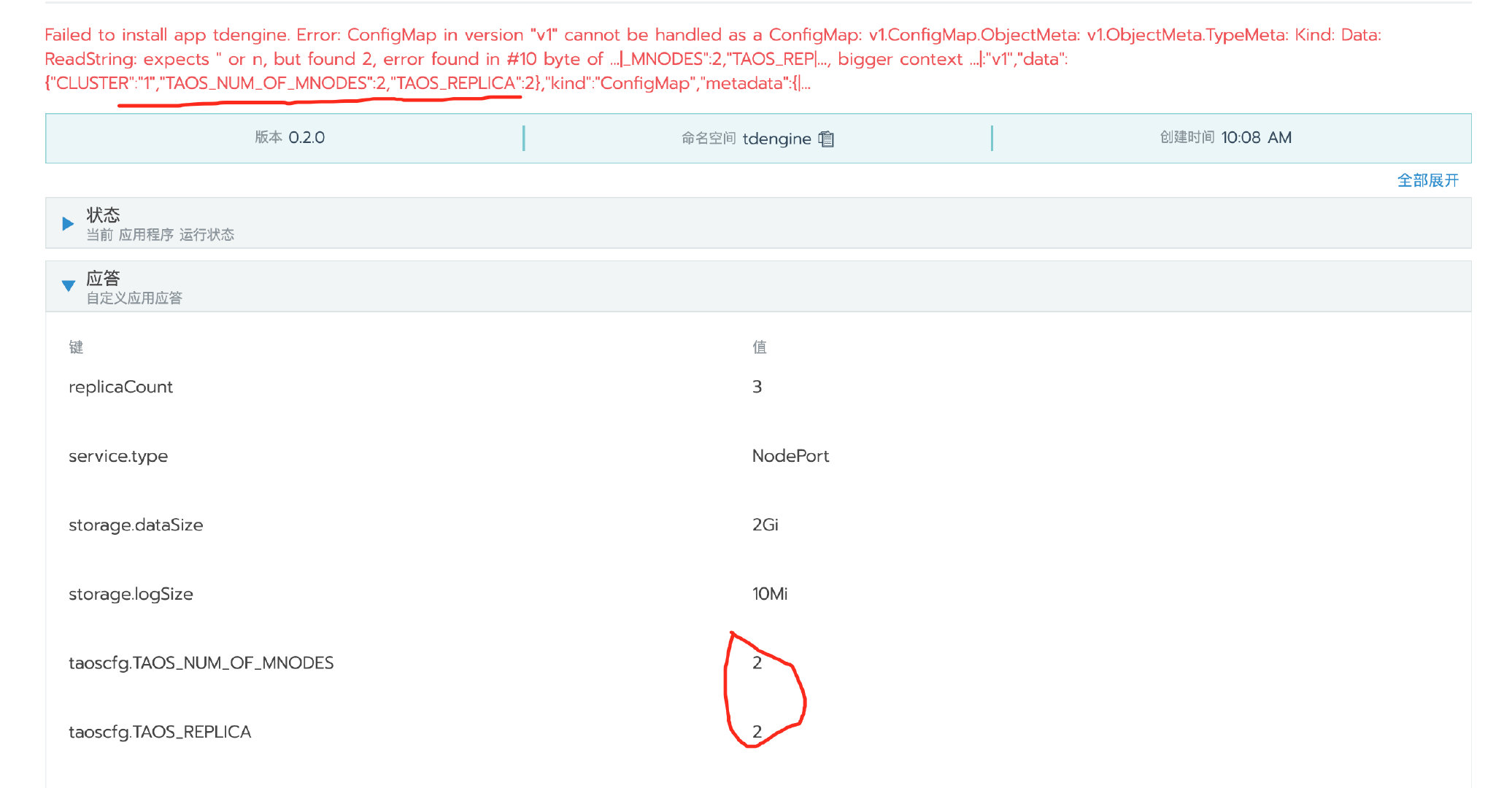
TAOS_NUM_OF_MNODES 要用字符串形式
应答
安装TDengine时需要设置以下应答:
storage.className=nfs-client指定存储类的名称service.port=NodePort方便进行外部访问
还有一些可选的应答:
replicaCount=3设置数据节点的数量taoscfg.TAOS_REPLICA=2.0设置副本数,小于等于replicaCounttaoscfg.TAOS_NUM_OF_MNODES=2.0设置管理节点数
使用以上的应答进行安装,我们可以得到一个拥有三个数据节点,副本数为2,管理节点数为2的集群。
TDengine中使用的端口
| 协议 | 默认端口 | 用途说明 | 修改方法 |
|---|---|---|---|
| TCP | 6030 | 客户端与服务端之间通讯。 | 由配置文件设置 serverPort 决定。 |
| TCP | 6035 | 多节点集群的节点间通讯。 | 随 serverPort 端口变化。 |
| TCP | 6040 | 多节点集群的节点间数据同步。 | 随 serverPort 端口变化。 |
| TCP | 6041 | 客户端与服务端之间的 RESTful 通讯。 | 随 serverPort 端口变化。 |
| TCP | 6042 | Arbitrator 的服务端口。 | 随 Arbitrator 启动参数设置变化。 |
| TCP | 6043 | TaosKeeper 监控服务端口。 | 随 TaosKeeper 启动参数设置变化。 |
| TCP | 6044 | 支持 StatsD 的数据接入端口。 | 随 taosadapter 启动参数设置变化(2.3.0.1+以上版本)。 |
| TCP | 6045 | 支持 collectd 数据接入端口。 | 随 taosadapter 启动参数设置变化(2.3.0.1+以上版本)。 |
| TCP | 6060 | 企业版内 Monitor 服务的网络端口。 | |
| UDP | 6030-6034 | 客户端与服务端之间通讯。 | 随 serverPort 端口变化。 |
| UDP | 6035-6039 | 多节点集群的节点间通讯。 | 随 serverPort 端口变化。 |
FQDN配置
1 | |
Java Connector
总体介绍
taos-jdbcdriver 的实现包括 2 种形式: JDBC-JNI 和 JDBC-RESTful(taos-jdbcdriver-2.0.18 开始支持 JDBC-RESTful)。 JDBC-JNI 通过调用客户端 libtaos.so(或 taos.dll )的本地方法实现, JDBC-RESTful 则在内部封装了 RESTful 接口实现。
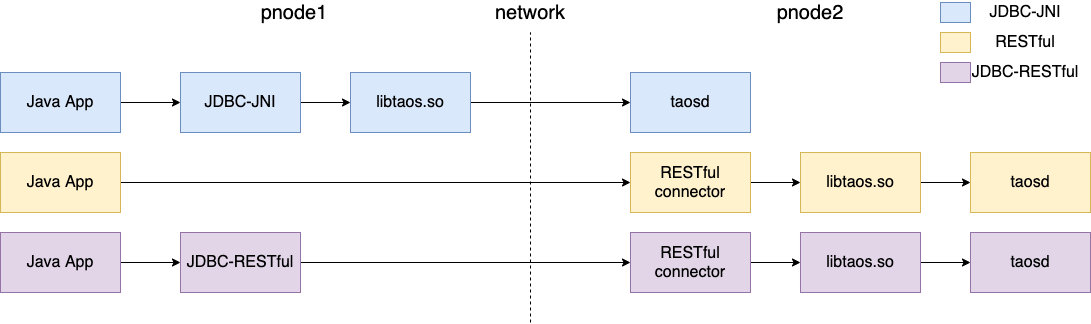
上图显示了 3 种 Java 应用使用连接器访问 TDengine 的方式:
- JDBC-JNI:Java 应用在物理节点1(pnode1)上使用 JDBC-JNI 的 API ,直接调用客户端 API(libtaos.so 或 taos.dll)将写入和查询请求发送到位于物理节点2(pnode2)上的 taosd 实例。
- RESTful:应用将 SQL 发送给位于物理节点2(pnode2)上的 RESTful 连接器,再调用客户端 API(libtaos.so)。
- JDBC-RESTful:Java 应用通过 JDBC-RESTful 的 API ,将 SQL 封装成一个 RESTful 请求,发送给物理节点2的 RESTful 连接器。
TDengine 的 JDBC 驱动实现尽可能与关系型数据库驱动保持一致,但TDengine与关系对象型数据库的使用场景和技术特征存在差异,导致 taos-jdbcdriver 与传统的 JDBC driver 也存在一定差异。在使用时需要注意以下几点:
- TDengine 目前不支持针对单条数据记录的删除操作。
- 目前不支持事务操作。
JDBC-JNI和JDBC-RESTful的对比
| 对比项 | JDBC-JNI | JDBC-RESTful |
|---|---|---|
| 支持的操作系统 | linux、windows | 全平台 |
| 是否需要安装 client | 需要 | 不需要 |
| server 升级后是否需要升级 client | 需要 | 不需要 |
| 写入性能 | JDBC-RESTful 是 JDBC-JNI 的 50%~90% | |
| 查询性能 | JDBC-RESTful 与 JDBC-JNI 没有差别 |
注意:与 JNI 方式不同,RESTful 接口是无状态的。在使用JDBC-RESTful时,需要在sql中指定表、超级表的数据库名称。(从 TDengine 2.2.0.0 版本开始,也可以在 RESTful url 中指定当前 SQL 语句所使用的默认数据库名。)
安装Java Connector
安装前准备
使用Java Connector连接数据库前,需要具备以下条件:
- Linux或Windows操作系统
- Java 1.8以上运行时环境
- TDengine-client(使用JDBC-JNI时必须,使用JDBC-RESTful时非必须)
注意:由于 TDengine 的应用驱动是使用C语言开发的,使用 taos-jdbcdriver 驱动包时需要依赖系统对应的本地函数库。
- libtaos.so 在 Linux 系统中成功安装 TDengine 后,依赖的本地函数库 libtaos.so 文件会被自动拷贝至 /usr/lib/libtaos.so,该目录包含在 Linux 自动扫描路径上,无需单独指定。
- taos.dll 在 Windows 系统中安装完客户端之后,驱动包依赖的 taos.dll 文件会自动拷贝到系统默认搜索路径 C:/Windows/System32 下,同样无需要单独指定。
注意:在 Windows 环境开发时需要安装 TDengine 对应的 windows 客户端,Linux 服务器安装完 TDengine 之后默认已安装 client,也可以单独安装 Linux 客户端 连接远程 TDengine Server。
通过maven获取JDBC driver
目前 taos-jdbcdriver 已经发布到 Sonatype Repository 仓库,且各大仓库都已同步。
maven 项目中,在pom.xml 中添加以下依赖:
1 | |
通过源码编译获取JDBC driver
可以通过下载TDengine的源码,自己编译最新版本的java connector
1 | |
编译后,在target目录下会产生taos-jdbcdriver-2.0.XX-dist.jar的jar包。
Java Connector的使用
获得连接
有三种方式获得连接
- 指定URL获得连接
-
指定URL和Properties获取连接
- 使用客户端配置文件建立连接
这三者的区别就是配置信息的位置,指定URL是将配置信息写在URL中,指定Properties是将配置信息写在Properties中,指定客户端配置文件则是将配置信息写在客户端配置文件中,如:
1 | |
在配置文件中指定 firstEp 和 secondEp
1 | |
TDengine 的 JDBC URL 规范格式为: jdbc:[TAOS|TAOS-RS]://[host_name]:[port]/[database_name]?[user={user}|&password={password}|&charset={charset}|&cfgdir={config_dir}|&locale={locale}|&timezone={timezone}]
配置参数的优先级
通过以上 3 种方式获取连接,如果配置参数在 url、Properties、客户端配置文件中有重复,则参数的优先级由高到低分别如下:
- JDBC URL 参数,如上所述,可以在 JDBC URL 的参数中指定。
- Properties connProps
- 客户端配置文件 taos.cfg
例如:在 url 中指定了 password 为 taosdata,在 Properties 中指定了 password 为 taosdemo,那么,JDBC 会使用 url 中的 password 建立连接。
数据库操作
创建数据库和表
1 | |
注意:如果不使用
use db指定数据库,则后续对表的操作都需要增加数据库名称作为前缀,如 db.tb。
插入数据
1 | |
now 为系统内部函数,默认为客户端所在计算机当前时间。
now + 1s代表客户端当前时间往后加 1 秒,数字后面代表时间单位:a(毫秒),s(秒),m(分),h(小时),d(天),w(周),n(月),y(年)。
查询数据
1 | |
查询和操作关系型数据库一致,使用下标获取返回字段内容时从 1 开始,建议使用字段名称获取。
使用Spring boot和MyBatis
配置application.propertise
1 | |
主要功能
创建数据库和表
1 | |
插入单条记录
1 | |
插入多条记录
1 | |
分页查询
1 | |