spark on yarn
example
1 | |
-
deploy-mode
In cluster mode, the Spark driver runs inside an application master process which is managed by YARN on the cluster, and the client can go away after initiating the application. (部署完看log没啥问题就可以ctrl-c, application自动在后台跑)
In client mode, the driver runs in the client process, and the application master is only used for requesting resources from YARN
-
supervise
make sure that the driver is automatically restarted if it fails with a non-zero exit code
-
num-executors
多少个executor进程来执行 (不设定,默认只会启动非常少的Executor。如果设得太小,无法充分利用计算资源。设得太大的话,又会抢占集群或队列的资源,导致其他作业无法顺利执行。)
-
executor-cores
每个个executor上的core数 一次能同时运行的task数。一个Spark应用最多可以同时运行的task数为num-executors*executor-cores
-
executor-memory
每个Executor的内存量
指标来源
- 通过ES API获取index详情 docs.count
1 | |
- spark kafka 处理过的offset
通过kafka脚本获取不到consumer的offset,因为没有自动commit

最后通过checkpointLocation读取offset,读取hadoop文件
spark概念

使用yarn application --list通过Tracking-URL查看spark application工作情况

测试
4核+16G 服务器
- 推荐 task数量 = 设置成spark Application 总cpu core = (num-executors * executor-cores)数量的2~3倍
- 分区
这里只是针对处理流程分区
partition 约等于等于task数量
1 | |
partition=1000 kafka偏移很少去到3000
1 | |
partition=10
1 | |
partition=30
task 比较平均分配到各个executors
1 | |
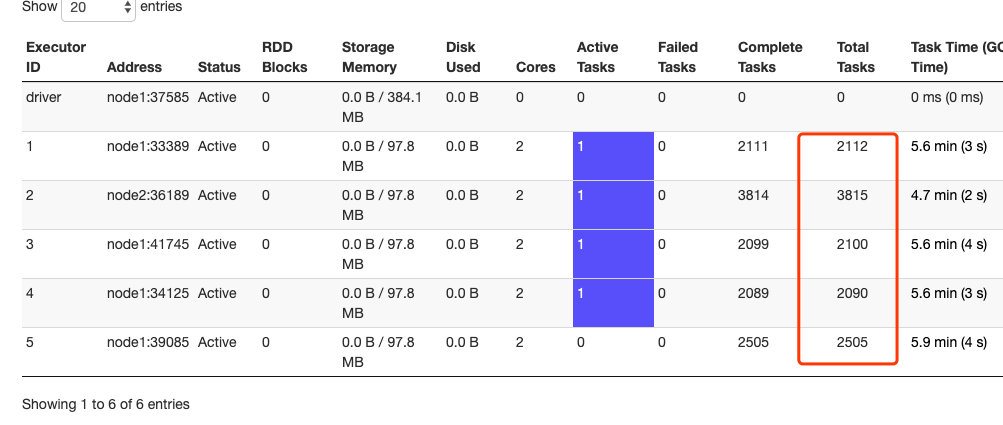
- 提高num-executors
内存从873.3M提高到2.5G
1 | |
partition=3000
1 | |
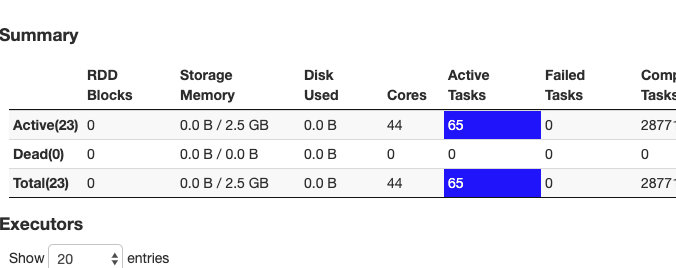
不能完全发挥理论上 cores = 2 * 500 上面的测试达到了
