设置外网访问
1 | |
倒排索引
文档内容被表示为一系列关键词的集合
索引 文档id 关键词(记录它在文档中的出现次数和出现位置) 描述他们之间的索引关系
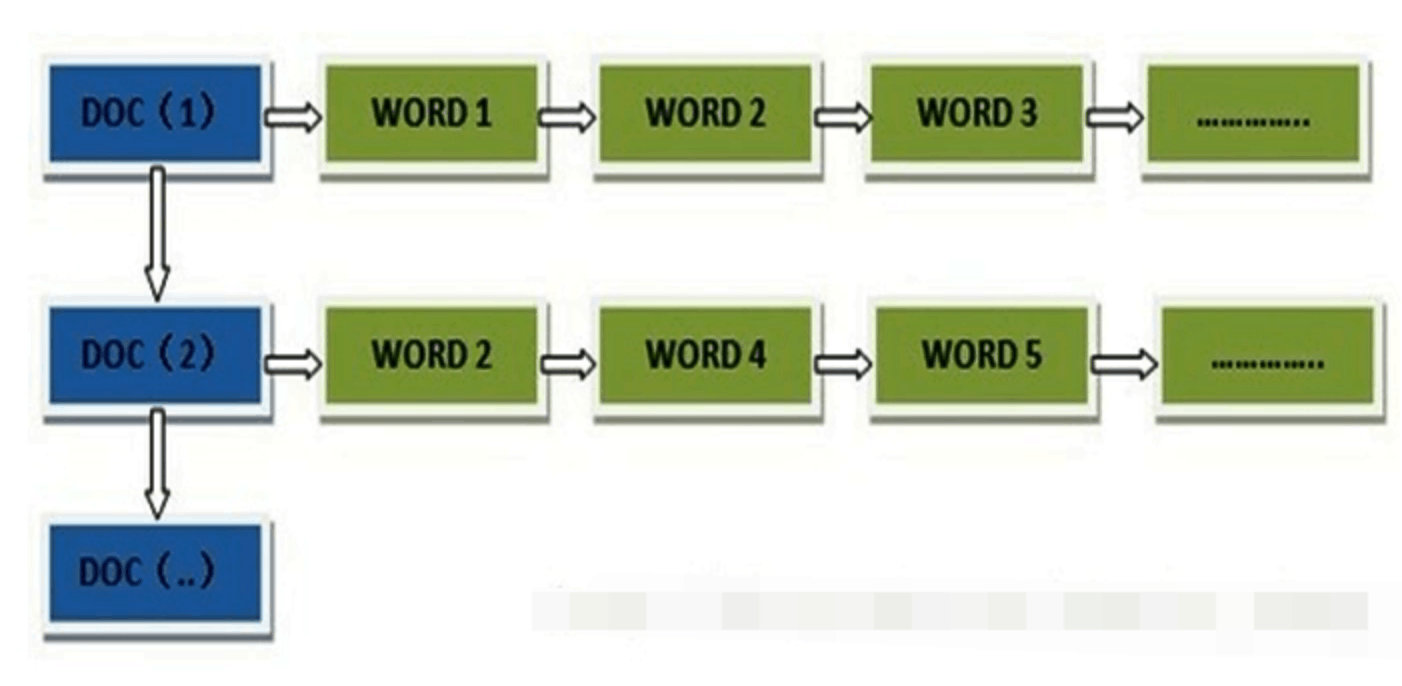
正向索引
通过关键词寻找 遍历文档 匹配关键词 打分 排序
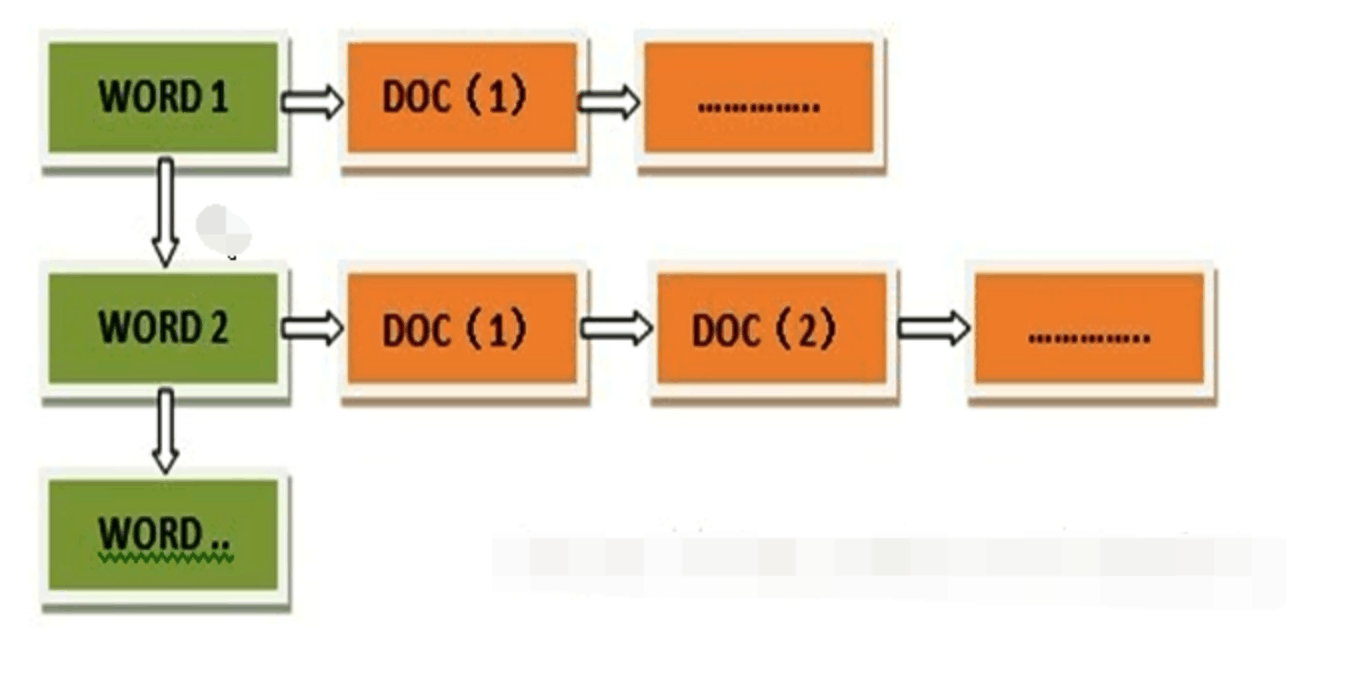
反向索引
倒排结构
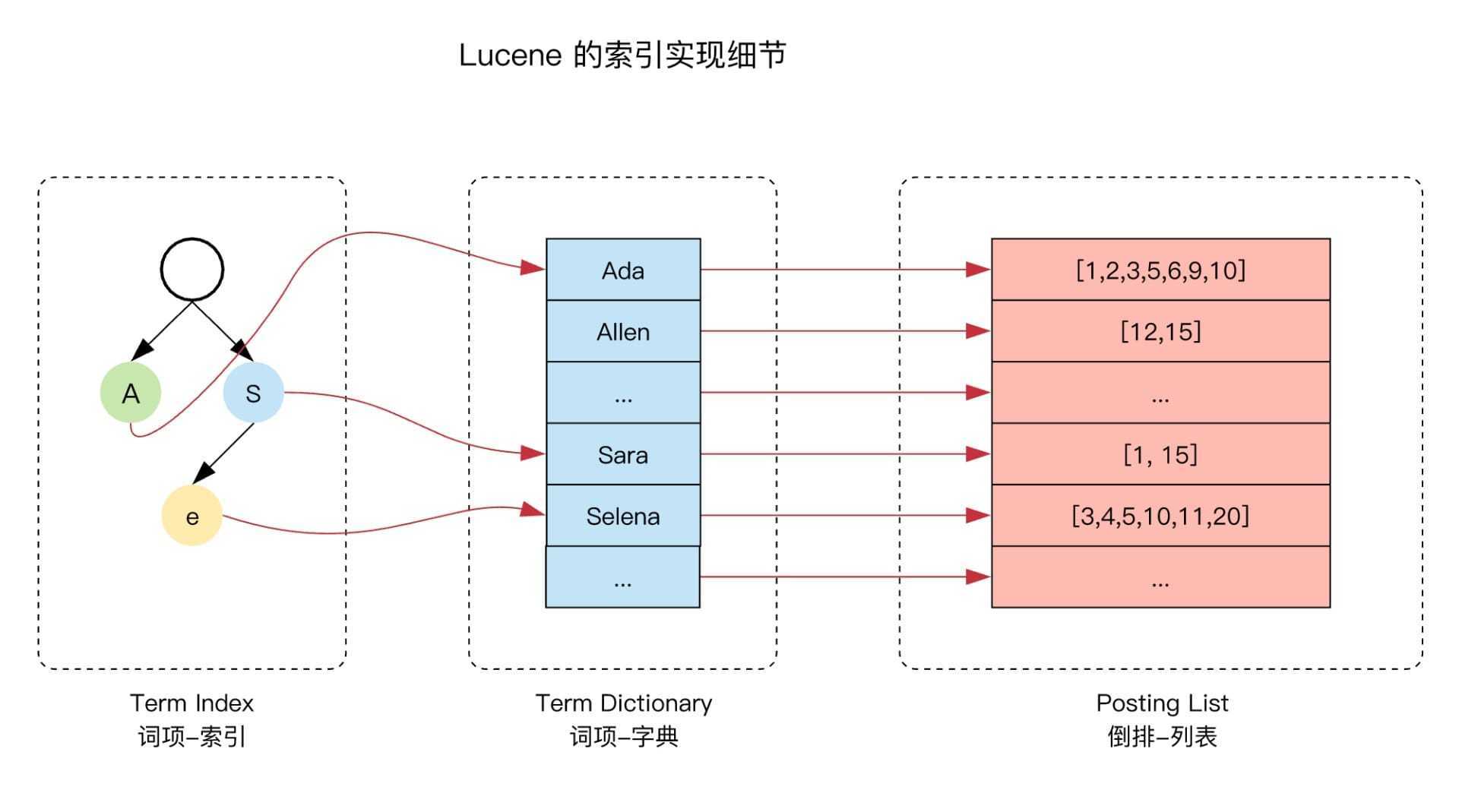
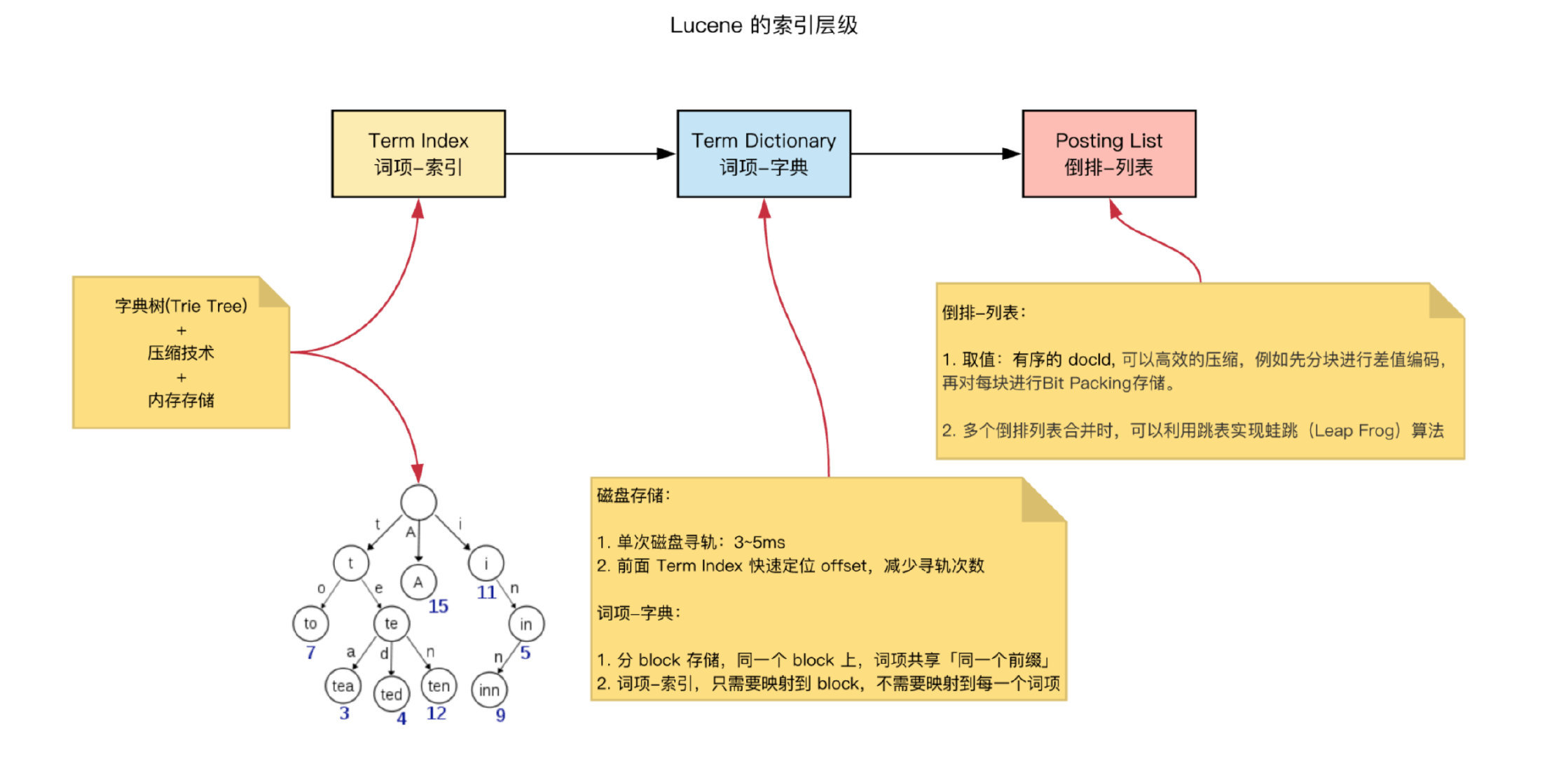
尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个 term dictionary 本身又太大了,无法完整地放到内存里。于是就有了 term index
term index 有点像一本字典的大的章节表。比如:
A 开头的 term ……………. Xxx 页
C 开头的 term ……………. Xxx 页
E 开头的 term ……………. Xxx 页
Trem index
-
term index 是一棵 trie 树(
字典树)+ 内存存储 -
它不存储所有的单词,只存储单词前缀
- 进一步节省内存,Lucene 还用了 FST(Finite State Transducers)对 Term Index 做进一步压缩
- 为
O(m),其中m为关键字的字符数量,定位Term dictionary对应 block 的 offset
Term dictionary
- 分 block 存储,同一个 block 上,词项共享(同一个前缀,都是 Ab 开头的单词就可以把 Ab 省去),节约磁盘空间
- 其为有序的字典,正常情况,二分查找,查询效率 O(logN)
- 定位到最终的 term
Posting list 文档id
-
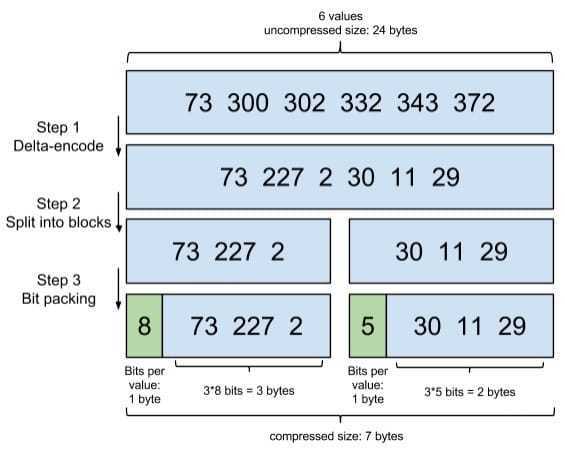
分块差值编码,再对每块进行 bit 压缩存储
1
[73, 300, 302, 332, 343, 372]增量编码
1
[73, 227, 2, 30, 11, 29] # 数据只记录元素与元素之间的增量用了 FOR(Frame Of Reference) 编码进行压缩
快速求交集
Roaring Bitmaps
Lucene Posting List 的每个 Segement 最多放 65536 个文档ID
1个id
-
使用 bitmap 表示 需要 65536 个 bit,65536/8 = 8192 bytes
-
Integer 数组,只需要 2 = 2 bytes
文档数量不多的时候,使用 Integer 数组更加节省内存
当文档数量少于 8192/2=4096 时,用 Integer 数组,否则,用 bitmap。


-
-
Frame Of Reference 是压缩数据,减少磁盘占用空间,所以当我们从磁盘取数据时,也需要一个反向的过程,即解压,解压后才有我们文档ID数组,对数据进行处理,求交集或者并集,这时候数据是需要放到内存进行处理的,更强有力的压缩算法,同时还要有利于快速的求交并集,于是有了Roaring Bitmaps 算法。

Mysql 是以 b-tree 排序的方式存储在磁盘上的。检索一个 term 需要若干次随机 IO 的磁盘操作。而 Lucene 在 term dictionary 的基础上添加了term index来加速检索,term index 以树的形式缓存在内存中。从 term index 查到对应的 term dictionary 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘的随机IO次数。
概念
Elasticsearch使用称为倒排索引的数据结构,该结构支持非常快速的全文本搜索。默认情况下,Elasticsearch对每个字段中的所有数据建立索引
Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写 Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。 同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
Document 可以分组 Type,它是虚拟的逻辑分组,用来过滤 Document
请求 /Index/Type
- POST _id字段就是一个随机字符串 可以不指定id 新增
- PUT 指定_id 新增 更新
- DELETE 指定_id
- GET 指定_id
批量
批量批处理1,000至5,000个文档,总有效负载在5MB至15MB之间
/Index/Type/_bulk
格式
1 | |
Example
1 | |
- index 和 create 第二行是source数据体
- delete 没有第二行
- update 第二行可以是partial doc,upsert或者是script
修改操作
- index 添加新数据,同时替换(重新索引)现有数据(基于其ID)
- create 添加新数据-如果数据已经存在(基于其ID),则会引发异常
- update 更新现有数据(基于其ID)。如果找不到数据,则引发异常
- upsert 如果数据不存在,则 称为合并或插入;如果数据存在(根据其ID),则更新
1 | |
query
/Index/Type/_search返回所有记录- took 操作的耗时(单位为毫秒)
- Communication time between the coordinating node and data nodes
- Time the request spends in the search thread pool, queued for execution
- Actual execution time
- timed_out字段表示是否超时
- hits字段表示命中的记录
- max_score:最高的匹配程度,本例是1.0。
- took 操作的耗时(单位为毫秒)
body search
1 | |
offset 0 limit x
1 | |
or关系
1 | |
and关系
1 | |
title= and content= and status contains the exact word and publish_date field contains a date from 1 Jan 2015
1 | |
bool
q Lucene query string syntax
1 | |
1 | |
1 | |
1 | |
1 | |
support
1 | |
search
1 | |
title or summary contains kw