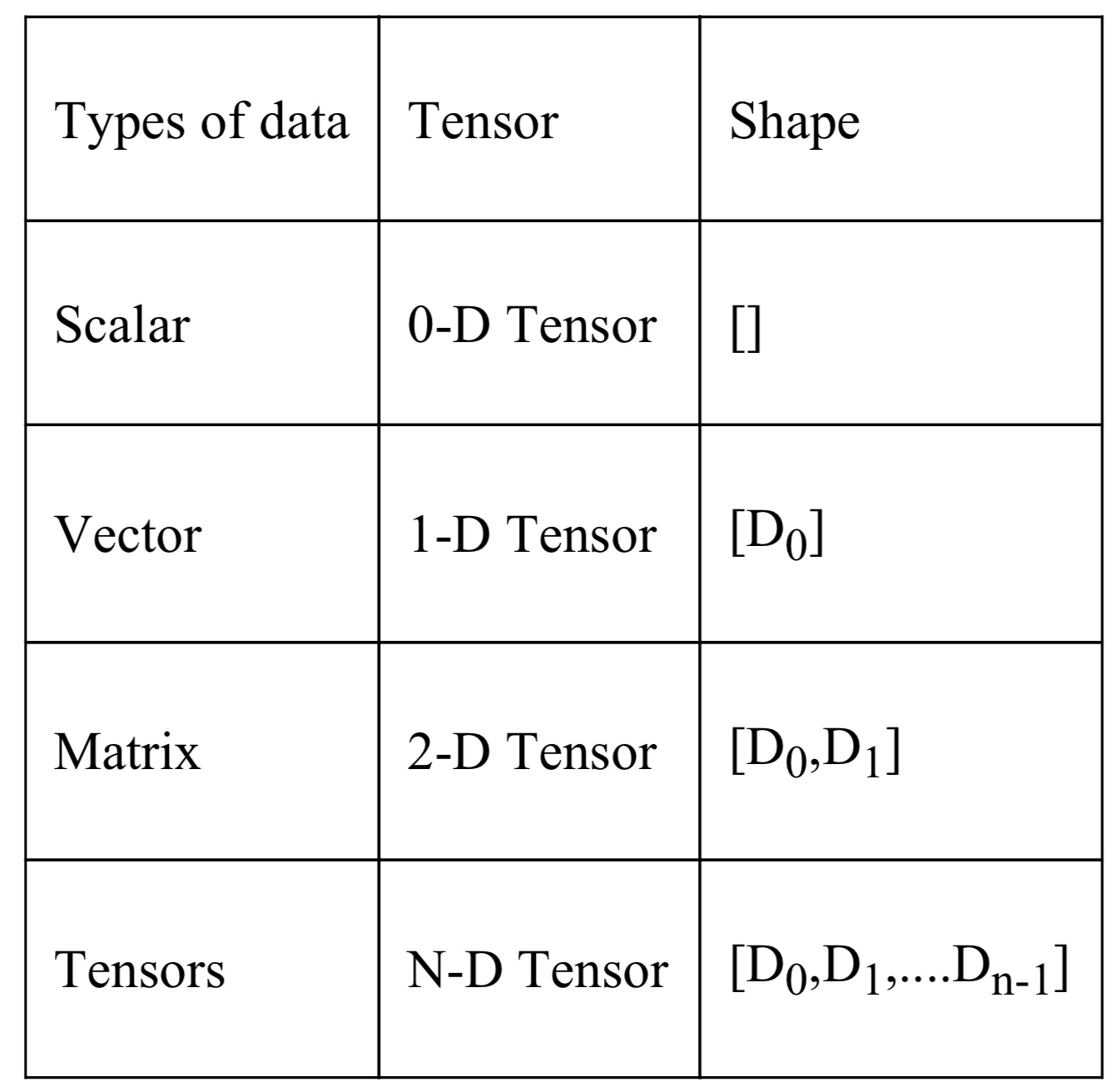
- 创建一个graph,
- TensorFlow 会话(Session)负责处理在诸如 CPU 和 GPU 之类的设备上的操作并运行它们,并且它保留所有变量值。
常量
1 | |
变量
训练过程中会不断优化 当值需要在会话中更新时,我们使用可变张量
1 | |
global_variables_initializer必须运行在所有Variable声明之后 不然报错 fuck session 和 变量初始化不能搞在一起吗?
1 | |
assign
变量的再赋值
scope
get_variable and Variable
tf.Variable必须有初始值tf.Variable始终创建一个新变量,已存在具有此类名称的变量,则可能会为变量名称添加后缀tf.get_variable从graph中获取具有这些参数的现有变量,如果它不存在,它将创建一个新变量,存在的话会报错
1 | |
name_scope and variable_scope
- 两个scope对使用
tf.Variable创建的变量具有相同的效果,即范围将作为操作或变量名称的前缀添加。 tf.variable_scope就不一样了
1 | |
scope reuse 共享变量 tf.variable_scope 和 tf.get_variable 搭配
1 | |
占位符
它们通常用于在训练期间将训练数据传递给TensorFlow 实际上不执行任何计算
1 | |
dtype
dtype 转换
1 | |
save load
默认情况下,保存器将以自己的名称保存并还原所有Variable,但如果需要更多控制,则可以指定要保存或还原的变量以及要使用的名称
1 | |
tensor board
正在定期保存检查点 可视化训练进度 checkpoint
1 | |
1 | |
必须是完整路径 fuck 不能相对路径 Pycharm 有Copy Path
1 | |
device
"/cpu:0" for the CPU devices and "/gpu:I" for the \(i^{th}\) GPU device
log_device_placement=True验证TensorFlow确实使用指定的设备,打logallow_soft_placement=True如果您不确定该设备并希望TensorFlow选择现有和支持的设备
GPU比CPU快得多,因为它们有许多小内核。然而,就计算速度而言,将GPU用于所有类型的计算并不总是有利的。 与GPU相关的开销有时在计算上比GPU提供的并行计算的优势更昂贵。为了解决这个问题, TensorFlow提供了在特定设备上进行计算的条款。默认情况下,如果CPU和GPU都存在,TensorFlow优先考虑GPU。
1 | |
optimizers
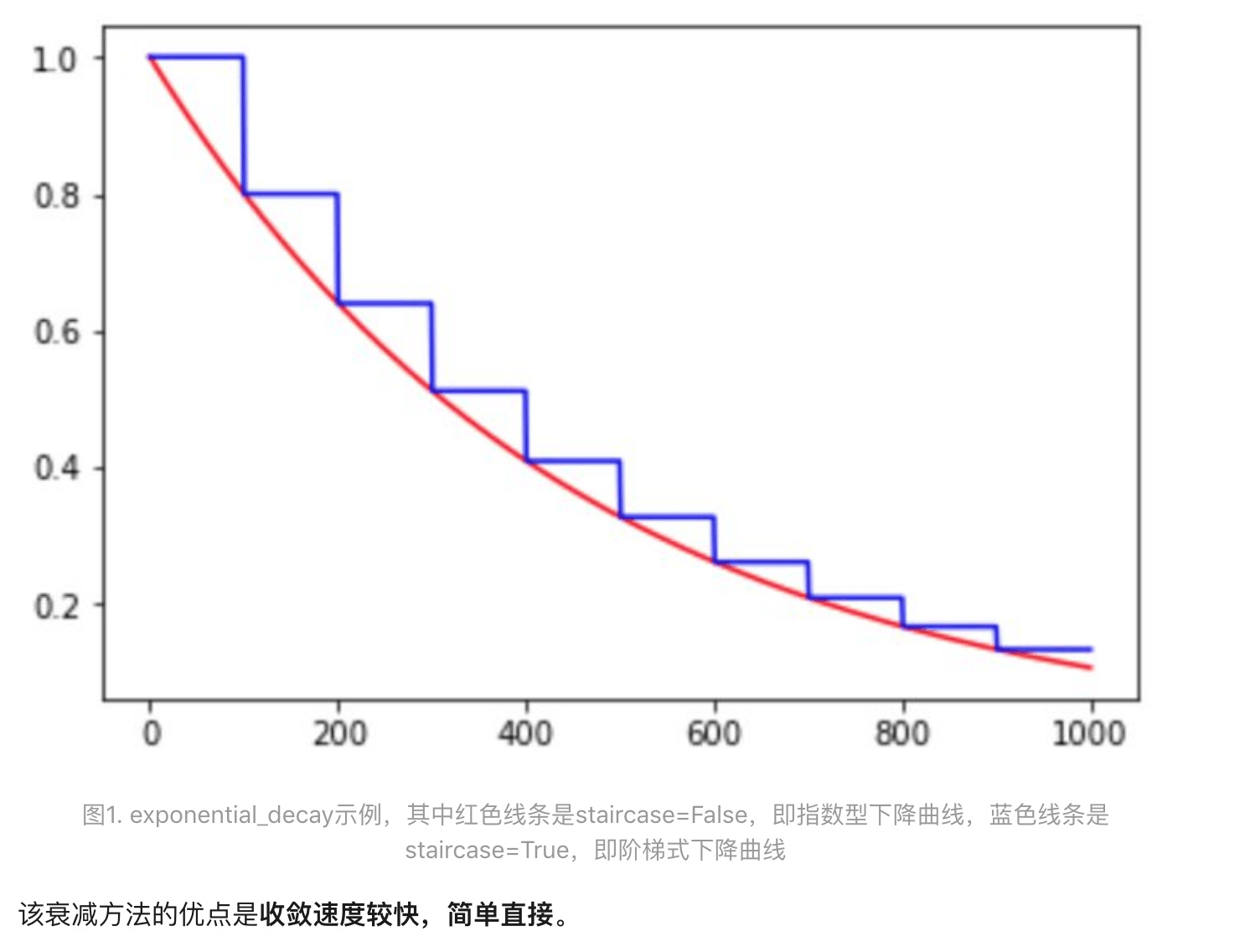
learning_rate传入初始lr值,global_step用于逐步计算衰减指数,decay_steps用于决定衰减周期,decay_rate是每次衰减的倍率, staircase若为False则是标准的指数型衰减,True时则是阶梯式的衰减方法,目的是为了在一段时间内(往往是相同的epoch内)保持相同的learning rate
其实可以直接使用一些改变learning_rate的变化的AdamOptimizer之类的
decay every 100000 steps with a base of 0.96
1 | |
1 | |
Gradient Clipping
直观作用就是让权重的更新限制在一个合适的范围
1 | |
autoencode
CAE
Convolutional Autoencoders (CAE)
transposed convolution layers tf.nn.conv2d_transpose 产生人工假象(artefacts) 使用tf.image.resize_nearest_neighbor 代替
1 | |