我们知道, Kubemetes Scheduler是负责 Pod 调度的进程(组件 ),随着 Kubemetes 功 能的不断增强和完善, Pod 调 度也变得越来越复杂 , Kubemetes Scheduler 内部的 实现机制 也在不断优化,从最初的两阶段调度机制 (Predicates & Prior山es) 发展到后来的升级版的 调度框架 (SchedulingFramework),以满足越来越复杂的调度场景。
为什么 Kubemetes里的 Pod调度会如此复杂?这主要是因为 Kubernetes要努力满足各 种类型应用的不同需求并且努力”让大家和平共处” 。 Kubernetes 集群里的 Pod 有无状 态 服务类、有状态集群类及批处理类三大类,不同类型的 Pod对资源占用的需求不同,对节 点故陓引发的中断/恢复及节点迁移方面的容忍度都不同,如果再考虑到业务方面不同服 务的 Pod 的优先级不同带来的额外约束和限制 , 以及从租户(用户)的角度希望占据更多 的资源增加稳定性和集群拥有者希望调度更多的 Pod 提升资源使用率两者之间的矛盾,则 当这些相互冲突的调度因素都被考虑到时, 如何进 行 Pod 调度就变成 一 个很棘手的问题了 。
调度流程
Kubernetes Scheduler 的作用是将待调度的 Pod (API 新创建的 Pod、 Controller Manager 为补足副本而创建的 Pod 等)按照特定的调度算法和调度策略绑定 ( Binding) 到 集群中某个合适的 Node 上, 并将绑定信息 写入 etcd 中 。在整个调度过程 中涉及 三个对象, 分别是待调度 Pod 列表、可用 Node 列表及调度算法和策略。简单地说,就是通过调度算 法为待调度 Pod 列表中的每 个 Pod 都从 Node 列 表 中选择一个最适合的 Node。
随后,目标节点上的 kubelet 通过 API Server 监听到 Kubemetes Scheduler 产生的 Pod 绑 定事件,然后获取对应的 Pod清单,下载 Image镜像并启动容器。
- 过滤阶段
通过 一系列特定的 Filter 对每个 Node 都进行筛选,筛选完成后通常会有 多个候选节点供调度, 从而进入打分阶段。
结果集为空,则表示当前还没有符合条件的 Node 节点, Pod 会 维持在 Pending 状态。
- 打分阶段
在过滤阶段的基础上,采用优选策略 (xxx Priorities ) 计算出每个候 选节点的积分,积分最高者胜出,因为积分最高者表示枭佳人选 。 挑选出最佳节点后, Scheduler 会把目标 Pod 安置到此节点上,调度完成 。
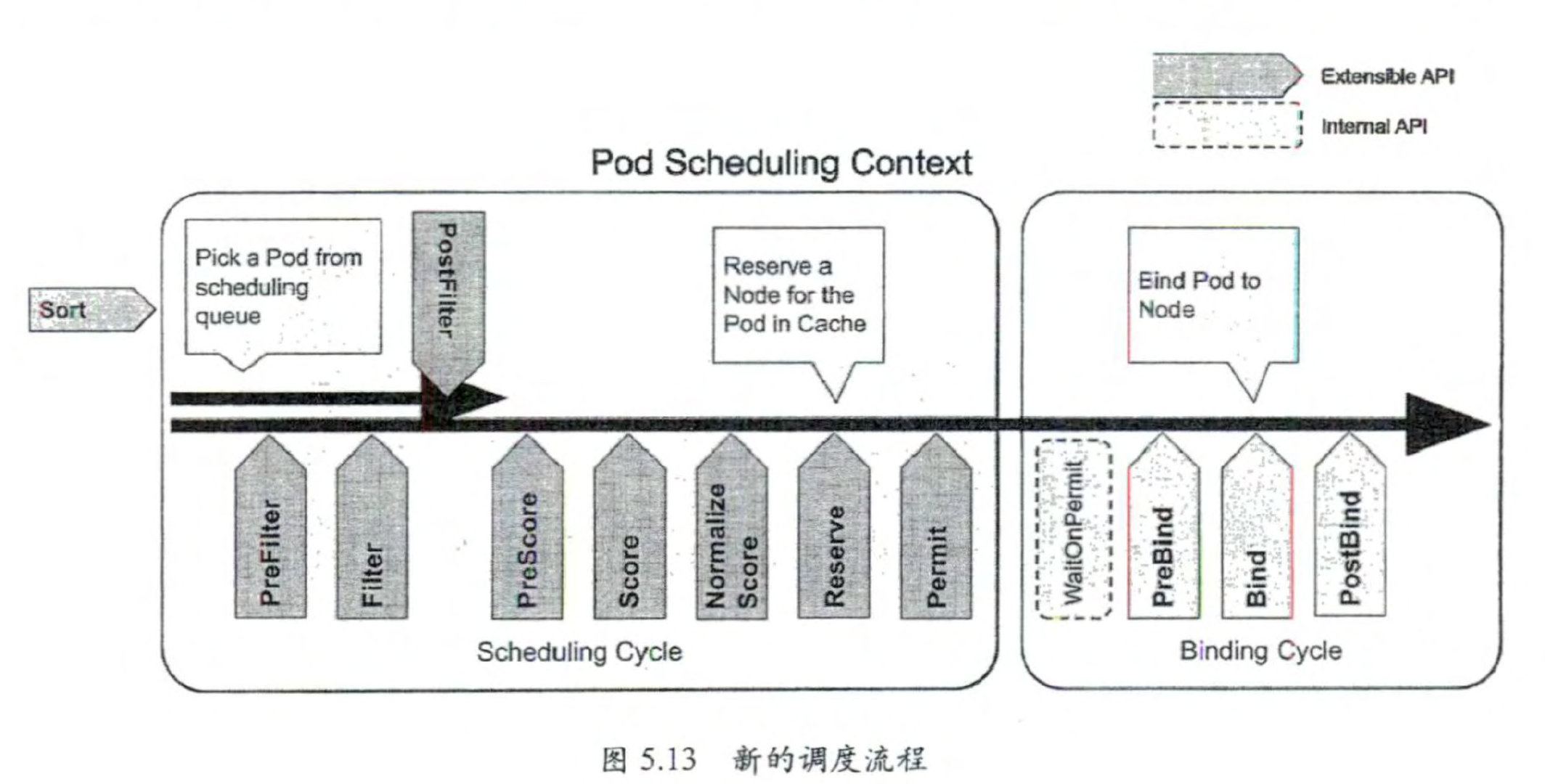
考虑到旧版本的 Kubernetes Scheduler 不足以支持更复杂 和 灵活的调度场景,因此在 Kubernetes 1.5 版本中出现一个新的调度机制一 Scheduler Framework。 从整个调度流程来 看,新的 Scheduler Framework 是在旧流程的基础上增加了 一些扩展点(基于调度 Stage 的 扩展点),同时支持用户以插件的方式 (Plugin) 进行扩展 。
-
QueueSort: 对调度队列中待调度的 Pod 进行排序,一次只能启用一个队列排序插件 。
-
PreFilter: 在过滤之前预处理或检查 Pod 或集群的信息,可以将 Pod 标记为不可调度。
-
Filter: 相当千调度策略中的 Predicates, 用千过滤不能运行 Pod 的节点 。 过滤器的
调用顺序是可配翌的,如果没有 一 个节点通过所有过滤器的筛选, Pod 则将被标
记为不可调度 。
-
PreScore: 是一个信息扩展点,可用千预打分工作。
-
Score: 给完成过滤阶段的节点打分,调度器会选择 得分最高的节点。
-
Reserve: 是一个信息扩展点,当资源已被预留给 Pod 时,会通知插件 。 这些插件
还实现了 Unreserve 接口,在 Reserve 期间或之后出现故障时调用 。
-
Permit:可以阻止或延迟 Pod绑定。
-
PreBind: 在 Pod 绑定节点之前执行 。
-
Bind: 将 Pod 与节点绑 定。绑定插 件是按顺序调用的,只 要有一个插件完成了绑 定,其余插件就都会跳过 。 绑定插件至少需要一个 。
-
PostBind: 是一个信息扩展点 ,在 Pod 绑定节点之后调用 。