一般来说,智能系统和自动系统通常会通过 一个“操作系统”不断修正系统的工作状 态 。在 Kubernetes 集群中,每个 Controller 都是这样的一个“操作系统”,它们通过 API Server 提供的 (List-Watch) 接口实时监控集群中特定资源的状态变化,当发生各种故障导致某 资渥对象的状态变化时, Controller 会尝试将其状态调整为期望的状态 。
Controller Manager 是 Kubernetes 中各种操作系统的管理者,是集 群内部的管理控制中心,也是 Kubernetes 自动化功能的核心 。每种 Controller都负责一种特定资源的控制流程,而 Controller Manager 正 是这些 Controller 的核心管理者 。
Replication Controller
Replication Controller 的核心作用是确保集群中某个 RC 关联的 Pod 副本数摄在任何时 候都保待预设值已如果发现 Pod 的副 本数拯超过预设值 ,则 Replication Controller会销毁一些 Pod 副本;反之, Replication Controller 会自动创建新的 Pod 副本,直到符合条件的 Pod 副本数量达到预设值 。
需要注意:只有当 Pod 的重启策略是 Always 时 (RestartPolicy=Always), Replication Controller 才会管理该 Pod 的操作(例如创建、销毁 、 重启等 )。 在通常情况下, Pod 对象被成功创建后都不会消失,唯 一 的例外是 Pod 处于 succeeded 或 failed 状态的时间过长(超时参数由系统设定),此时该 Pod 会被系统自动回 收,管理该 Pod 的副本控制器将在其他工作节点上重新创建 、 运行 该 Pod 副本 。
随着 Kubernetes 的不断升级,旧的 RC 已不能满足需求,所以有了 Deployment。 Deployment 可被视为 RC 的替代者, RC 及对应的 Replication Controller 已不再升级 、维护, Deployment 及对应的 Deployment Controller 则不断更新、升级新特性 。 Deployment Controller 在工作过程中实际上是在控制两类相关的资源对象: Deployment 及 ReplicaSet。 在我们创建 Deployment 资源对象之后, Deployment Controller 也默默创建了对应的 ReplicaSet, Deployment 的滚动升级也是 Deployment Controller 通过自动创建新的 ReplicaSet 来支持的 。
下面总结 Deployment Controller 的作用,如下所述 。
- 确保在当前集群中有且仅有 N 个 Pod 实例, N 是在 RC 中定义的 Pod 副本数晕 。
- 通过调整 spec.replicas 属性的值来实现系统扩容或者缩容 。
- 通过改变 Pod 模板 ( 主要是镜像版本 ) 来实现系统的滚动升级 。
最后总结 Deployment Controller 的典型使用场景,如下所述 。
-
重新调度 (Rescheduling)。 如前面所述,不管想运行 1 个副本还是 1000 个副本, 副本控制器都能确保指定数量的副本存在千集群中,即使发生节点故障或 Pod 副本被终止 运行 等意 外状况 。
-
弹性伸缩 (Scaling)。 手动或者通过自动扩容代理修改副本控制器 spec.replicas 属性的值 , 非常容易实现增加或减少副本的数量。
-
滚动更新 (Rolling Updates)。 副本控制器被设计成通过逐个 替换 Pod 来 辅 助服 务
的 滚动更 新 。
Node Controller
kubelet 进程在启动时通过 API Server 注册自身节点信息,并定时向 API Server 汇报 状 态信息, API Sen·er 在接收到这些信息后,会将这些信息更新到 etcd 中 。 在 etcd 中存储的 节点信息包括节 点健 康状况、节点资源 、 节点名称 、 节点地址信息 、操作 系统版本、 Docker 版本、 kubelet 版本等。节点健康状况包含就绪 (True)、未就绪 (False)、未知 (Unknown ) 三种 。
-
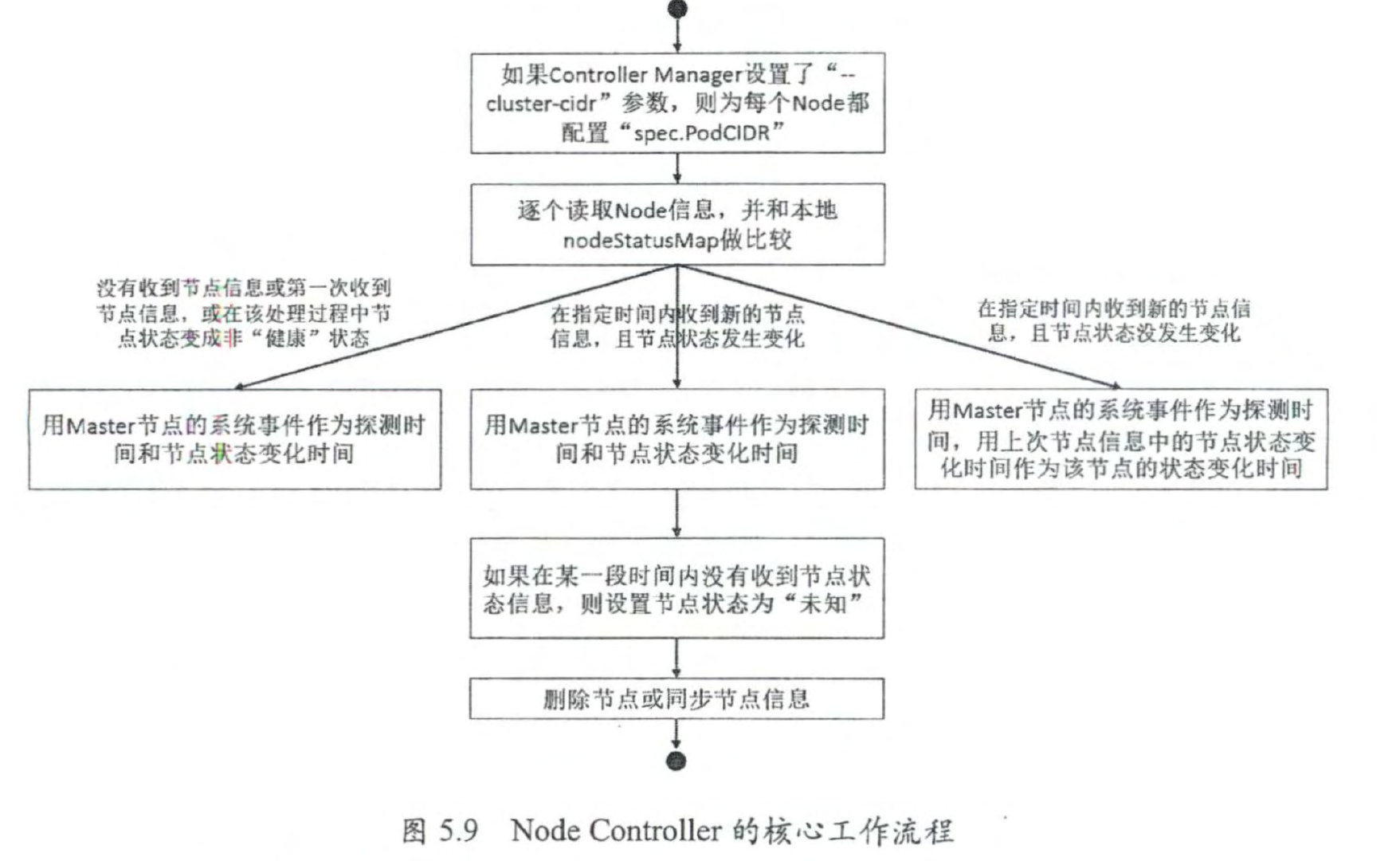
为每个没有设置 Spec.PodCIDR的 Node都生成一个 CIDR地址,并用该 CIDR地址设置节点的 Spec.PodCIDR属性,这样做的目的是防止不同节点的 CIDR 地址发生冲突 。
-
逐个读取 Node 信息,多次尝试修改 nodeStatusMap 中的节点状态信息 , 将该节点 信息和在 Node Controller 的 nodeStatusMap 中保存的节点信息做比较 。
如果判断出没有收 到 kubelet 发送的节点信息 、 第 1 次收到节点 kubelet 发送的节点信息,或在该处理过程中 节点状态变成非健康状态,则在 nodeStatusMap 中保存该节点的状态信息,并用 Node Controller 所在节点的系统时间作为探测时间和节点状态变化时间 。
如果判断出在指定时 间内收到新的节点信息,且节点状态发生变化,则在 nodeStatusMap 中保存该节点的状态 信息,并用 Node Controller 所在节点的系统时间作为探测时间和节点状态变化时间 。 如果 判断出在指定时间内收到新的节点信息,但节点状态没发生变化,则在 nodeStatusMap 中 保存该节点的状态信息,并用 Node Controller 所在节点的系统时间作为探测时间,将上次 节点信息中的节点状态变化时间作为该节点的状态变化时间 。 如果判断出在某段时间 (gracePeriod) 内没有收到节点状态信息,则设置节点状态为“未知” , 并且通过 API Server 保存节点状态 。
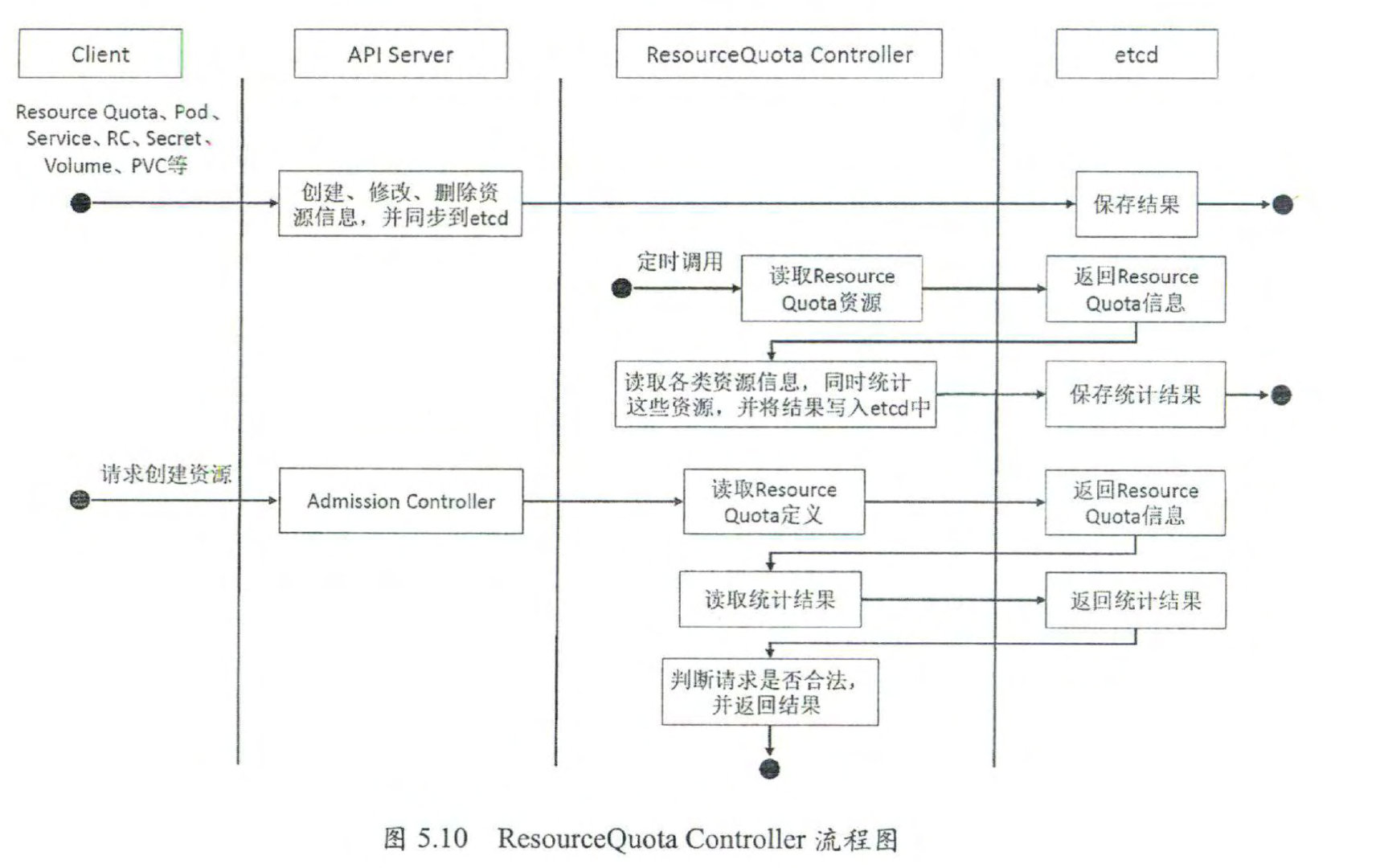
ResourceQuota Controller
目前 Kubernetes 支持如下三个层次的资源配额管理。
- 容器级别,可以对 CPU 和 Memory 进行限制 。
- Pod 级别,可以对一个 Pod 内所有容器的可用资源进行限制 。
- Namespace 级别,为 Namespace (多租户)级别的资源限制,包括: Pod 数量、 ReplicationController数量、 Service数量、 ResourceQuota数量、 Secret数量和可持有的 PV 数量 。
Kubernetes 的配额管理是通过 Admission Control (准入控制 )来控制的, Admission Control 当前提供了两种方式的配额约束,分别是 LimitRanger 与 ResourceQuota, 其中 L画 tRanger 作 用 千 Pod 和 Container; ResourceQuota 则作用 千 Namespace, 限定一个 Namespace 里各类资源的使用总额 。