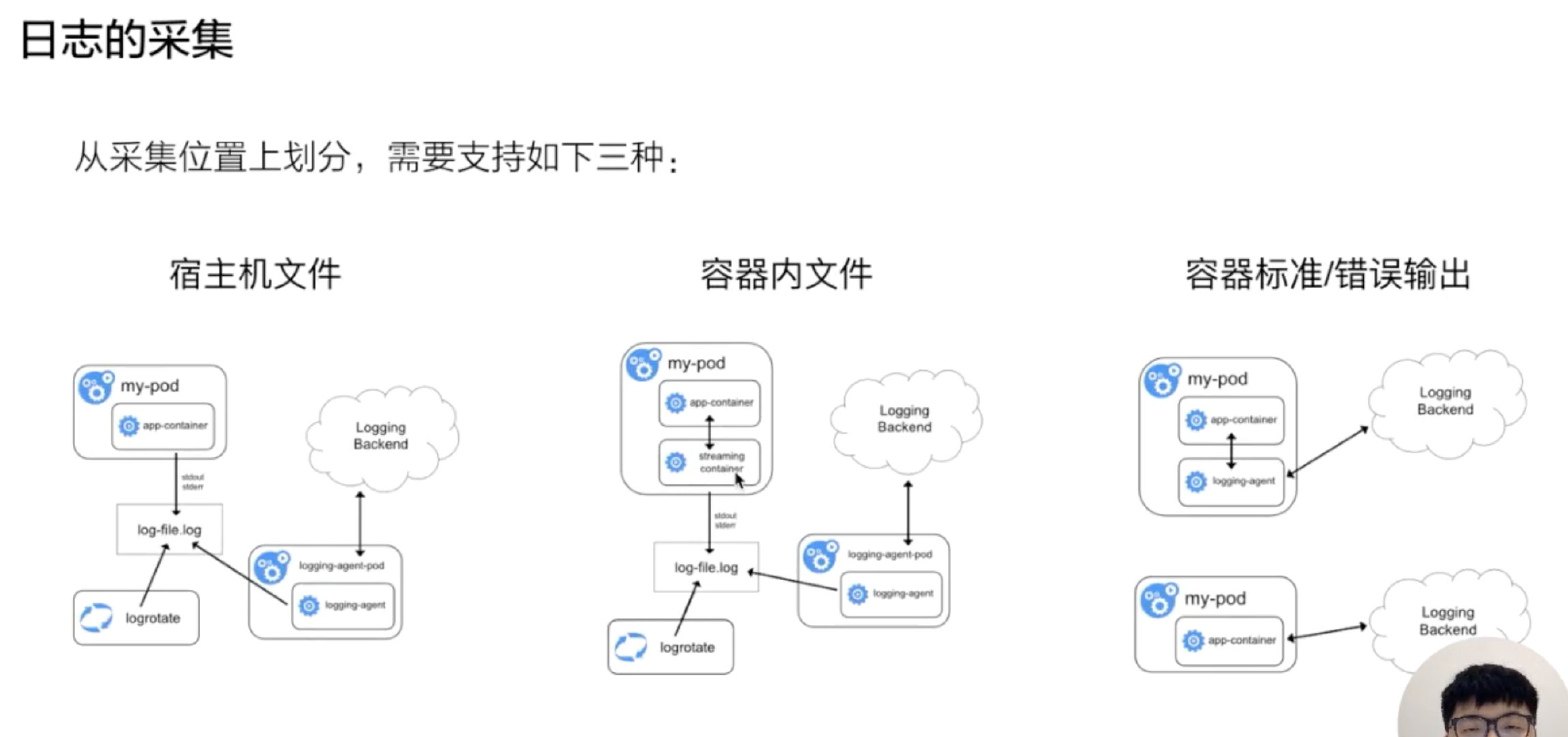
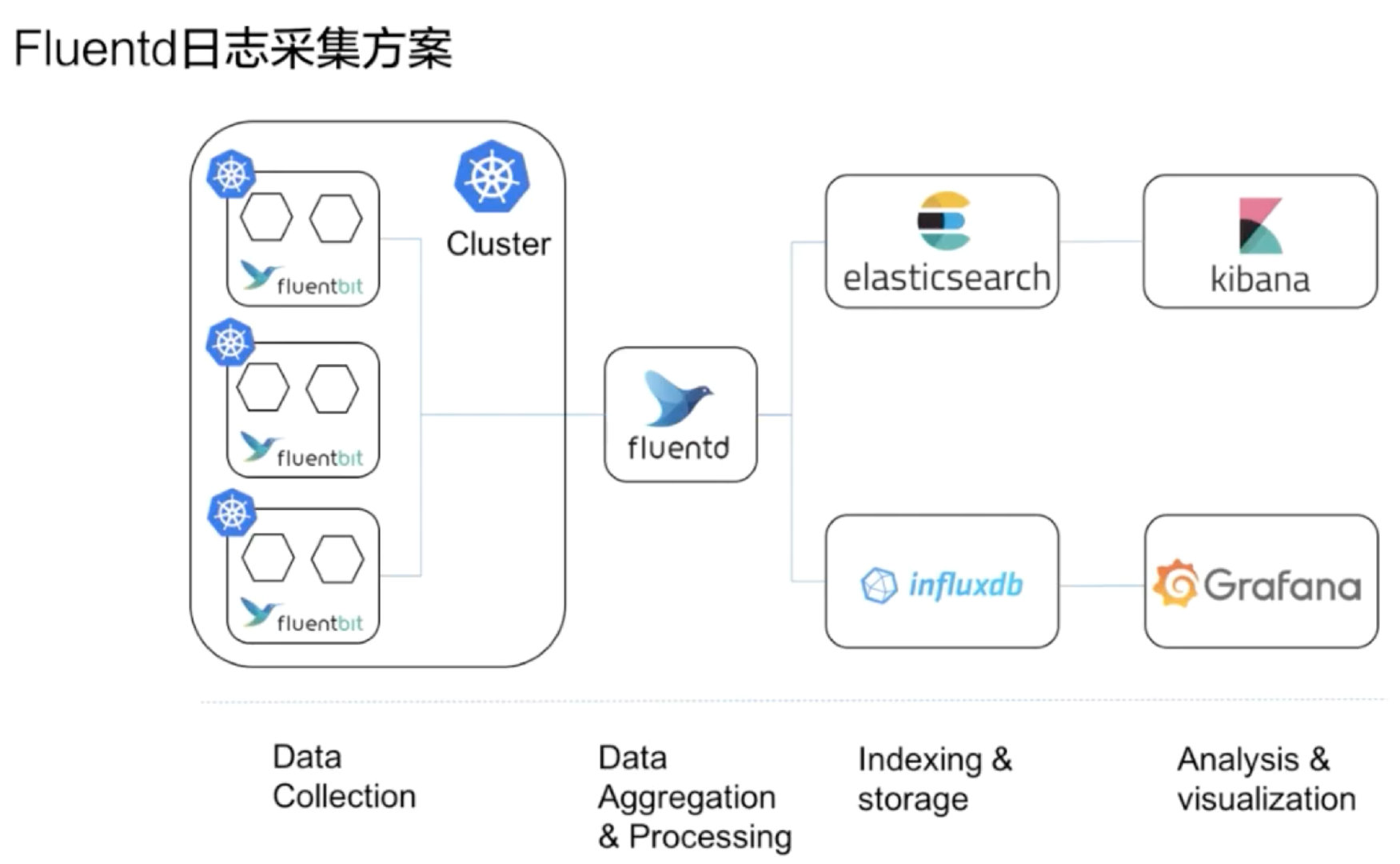
容器探针
探针是由 kubelet 对容器执行的定期诊断,主要是为了保证我们在使用容器探针来帮助我们检测和保证 Pod 中的服务正常运行。要执行诊断,kubelet 调用由容器实现的 Handler,有三种类型的处理程序:
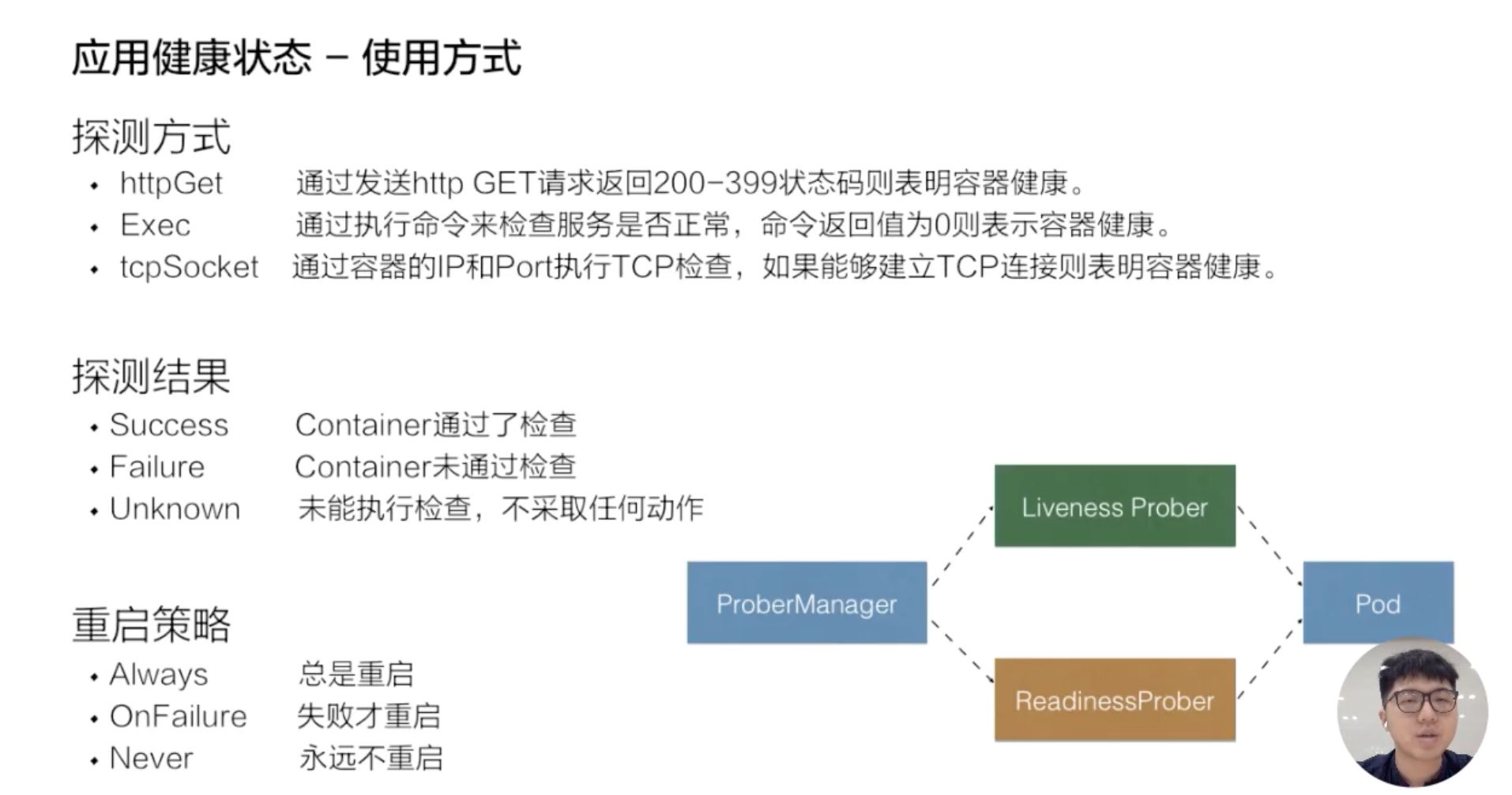
探测方式
-
ExecAction
在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
-
TCPSocketAction
对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
-
HTTPGetAction
对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。

探测结果
- Success,当状态是 success 的时候,表示 container 通过了健康检查,也就是 Liveness probe 或 Readiness probe 是正常的一个状态;
- Failure,Failure 表示的是这个 container 没有通过健康检查,如果没有通过健康检查的话,那么此时就会进行相应的一个处理,那在 Readiness 处理的一个方式就是通过 service。service 层将没有通过 Readiness 的 pod 进行摘除,而 Liveness 就是将这个 pod 进行重新拉起,或者是删除。
- Unknown,Unknown 是表示说当前的执行的机制没有进行完整的一个执行,可能是因为类似像超时或者像一些脚本没有及时返回,那么此时 Readiness-probe 或 Liveness-probe 会不做任何的一个操作,会等待下一次的机制来进行检验。
那在 kubelet 里面有一个叫 ProbeManager 的组件,这个组件里面会包含 Liveness-probe 或 Readiness-probe,这两个 probe 会将相应的 Liveness 诊断和 Readiness 诊断作用在 pod 之上,来实现一个具体的判断。
Kubelet 可以选择是否执行在容器上运行的三种探针执行和做出反应:
-
livenessProbe
指示容器是否正在运行。
如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为 Success。
-
readinessProbe
指示容器是否准备好服务请求。
如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
-
startupProbe
指示容器中的应用是否已经启动。
如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success。
接下来对 Liveness 指针和 Readiness 指针进行一个简单的总结。
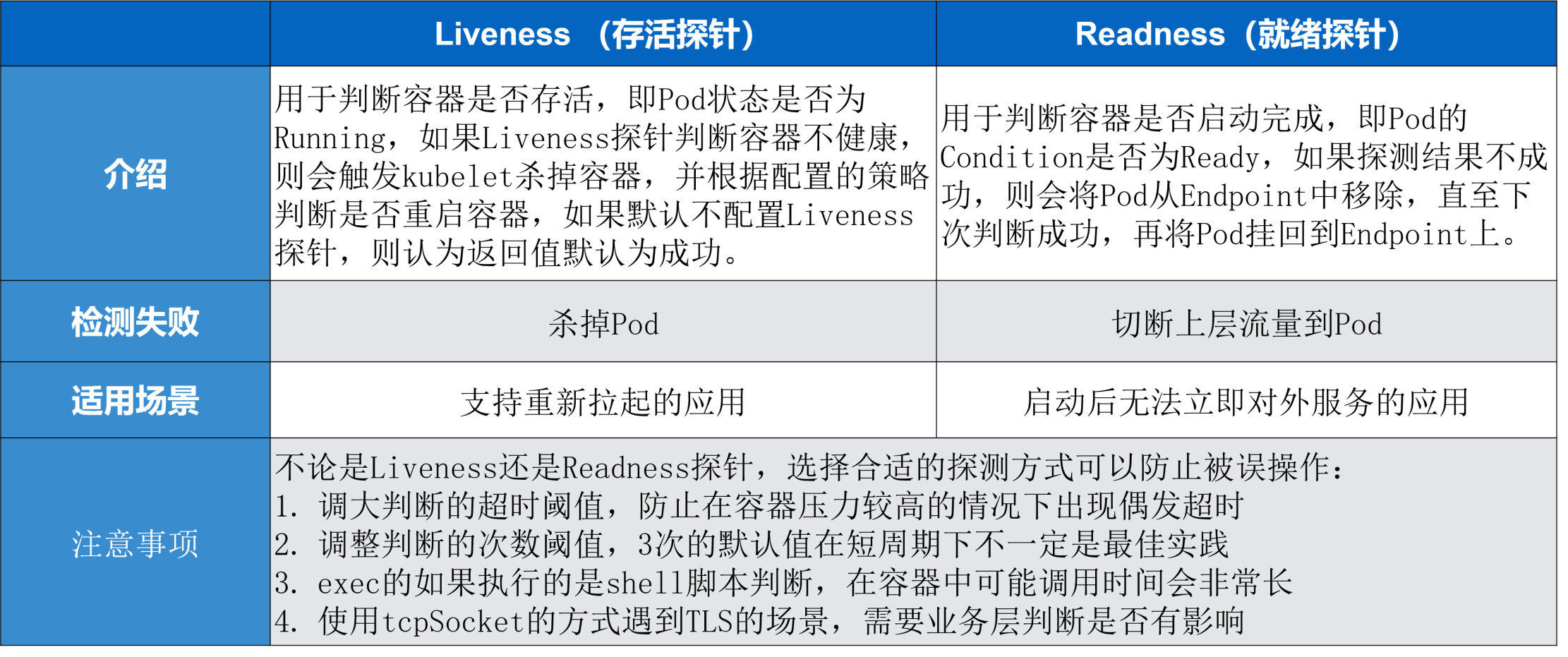
探针的区别
- ReadinessProbe: 当检测失败后,将 Pod 的 IP:Port 从对应 Service 关联的 EndPoint 地址列表中删除。
- LivenessProbe: 当检测失败后将杀死容器,并根据 Pod 的重启策略来决定作出对应的措施。
检测探针 -就绪检测Liveness probe
- readinessProbe-httpget
1 | |
检测探针 - 存活检测
- livenessProbe-exec
1 | |
- livenessProbe-tcp
1 | |
- livenessProbe-httpget
1 | |
启动退出动作
我们可以设置,在 Pod 启动和停止的时候执行某些操作。
1 | |
Pod 的状态示例
Pod 中只有一个容器并且正在运行,容器成功退出
-
记录事件完成
-
如果 restartPolicy 为:
-
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:Pod phase 变成 Succeeded
- Never:Pod phase 变成 Succeeded
Pod 中只有一个容器并且正在运行,容器退出失败
-
记录失败事件
-
如果 restartPolicy 为:
-
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:重启容器;Pod phase 仍为 Running
- Never:Pod phase 变成 Failed
Pod 中有两个容器并且正在运行,容器 1 退出失败
-
记录失败事件
-
如果 restartPolicy 为:
-
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:重启容器;Pod phase 仍为 Running
- Never:不重启容器;Pod phase 仍为 Running
-
如果有容器 1 没有处于运行状态,并且容器 2 退出:
-
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:重启容器;Pod phase 仍为 Running
- Never:Pod phase 变成 Failed
- 记录失败事件
- 如果 restartPolicy 为:
Pod 中只有一个容器并处于运行状态,容器运行时内存超出限制
-
容器以失败状态终止
-
记录 OOM 事件
-
如果 restartPolicy 为 :
-
- Always:重启容器;Pod phase 仍为 Running
- OnFailure:重启容器;Pod phase 仍为 Running
- Never: 记录失败事件;Pod phase 仍为 Failed
Pod 正在运行,磁盘故障
- 杀掉所有容器。记录适当事件
- Pod phase 变成 Failed
- 如果使用控制器来运行,Pod 将在别处重建
Pod 正在运行,其节点被分段
- 节点控制器等待直到超时
- 节点控制器将 Pod phase 设置为 Failed
- 如果是用控制器来运行,Pod 将在别处重建
k8s pod 状态转换
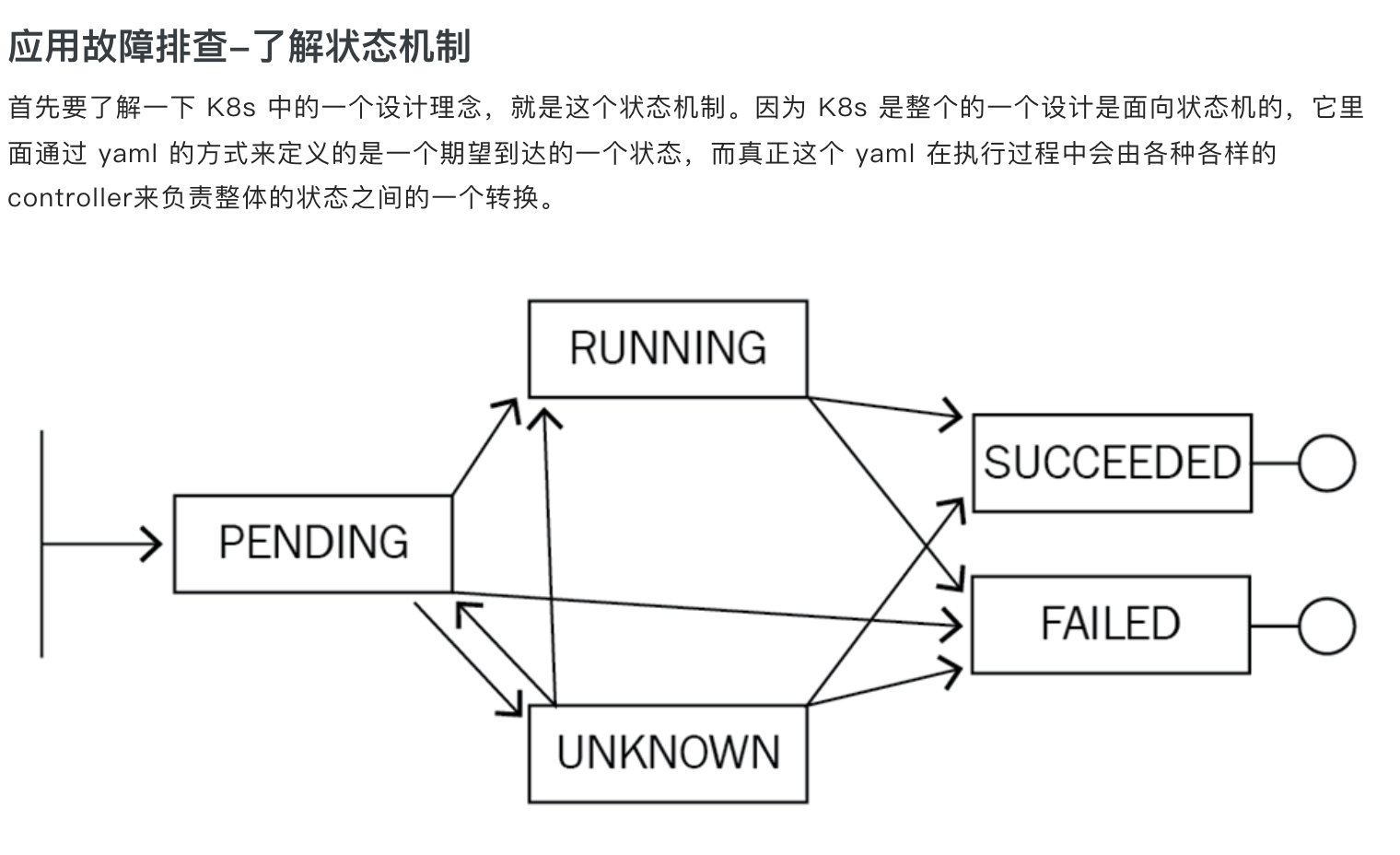

-
Pod 停留在 Pending
第一个就是 pending 状态,pending 表示调度器没有进行介入。此时可以通过 kubectl describe pod 来查看相应的事件,如果由于资源或者说端口占用,或者是由于 node selector 造成 pod 无法调度的时候,可以在相应的事件里面看到相应的结果,这个结果里面会表示说有多少个不满足的 node,有多少是因为 CPU 不满足,有多少是由于 node 不满足,有多少是由于 tag 打标造成的不满足。
-
Pod 停留在 waiting
那第二个状态就是 pod 可能会停留在 waiting 的状态,pod 的 states 处在 waiting 的时候,通常表示说这个 pod 的镜像没有正常拉取,原因可能是由于这个镜像是私有镜像,但是没有配置 Pod secret;那第二种是说可能由于这个镜像地址是不存在的,造成这个镜像拉取不下来;还有一个是说这个镜像可能是一个公网的镜像,造成镜像的拉取失败。
-
Pod 不断被拉取并且可以看到 crashing
第三种是 pod 不断被拉起,而且可以看到类似像 backoff。这个通常表示说 pod 已经被调度完成了,但是启动失败,那这个时候通常要关注的应该是这个应用自身的一个状态,并不是说配置是否正确、权限是否正确,此时需要查看的应该是 pod 的具体日志。
-
Pod 处在 Runing 但是没有正常工作
第四种 pod 处在 running 状态,但是没有正常对外服务。那此时比较常见的一个点就可能是由于一些非常细碎的配置,类似像有一些字段可能拼写错误,造成了 yaml 下发下去了,但是有一段没有正常地生效,从而使得这个 pod 处在 running 的状态没有对外服务,那此时可以通过 apply-validate-f pod.yaml 的方式来进行判断当前 yaml 是否是正常的,如果 yaml 没有问题,那么接下来可能要诊断配置的端口是否是正常的,以及 Liveness 或 Readiness 是否已经配置正确。
-
Service 无法正常的工作
最后一种就是 service 无法正常工作的时候,该怎么去判断呢?那比较常见的 service 出现问题的时候,是自己的使用上面出现了问题。因为 service 和底层的 pod 之间的关联关系是通过 selector 的方式来匹配的,也就是说 pod 上面配置了一些 label,然后 service 通过 match label 的方式和这个 pod 进行相互关联。如果这个 label 配置的有问题,可能会造成这个 service 无法找到后面的 endpoint,从而造成相应的 service 没有办法对外提供服务,那如果 service 出现异常的时候,第一个要看的是这个 service 后面是不是有一个真正的 endpoint,其次来看这个 endpoint 是否可以对外提供正常的服务。
监控类型
-
资源监控
比较常见的像 CPU、内存、网络这种资源类的一个指标,通常这些指标会以数值、百分比的单位进行统计,是最常见的一个监控方式。这种监控方式在常规的监控里面,类似项目 zabbix telegraph,这些系统都是可以做到的。
-
性能监控
性能监控指的就是 APM 监控,也就是说常见的一些应用性能类的监控指标的检查。通常是通过一些 Hook 的机制在虚拟机层、字节码执行层通过隐式调用,或者是在应用层显示注入,获取更深层次的一个监控指标,一般是用来应用的调优和诊断的。比较常见的类似像 jvm 或者 php 的 Zend Engine,通过一些常见的 Hook 机制,拿到类似像 jvm 里面的 GC 的次数,各种内存代的一个分布以及网络连接数的一些指标,通过这种方式来进行应用的性能诊断和调优。
-
安全监控
安全监控主要是对安全进行的一系列的监控策略,类似像越权管理、安全漏洞扫描等等。
-
事件监控
事件监控是 K8s 中比较另类的一种监控方式。在上一节课中给大家介绍了在 K8s 中的一个设计理念,就是基于状态机的一个状态转换。从正常的状态转换成另一个正常的状态的时候,会发生一个 normal 的事件,而从一个正常状态转换成一个异常状态的时候,会发生一个 warning 的事件。通常情况下,warning 的事件是我们比较关心的,而事件监控就是可以把 normal 的事件或者是 warning 事件离线到一个数据中心,然后通过数据中心的分析以及报警,把相应的一些异常通过像钉钉或者是短信、邮件的方式进行暴露,弥补常规监控的一些缺陷和弊端。
监控接口标准
第一类 Resource Metrice
对应的接口是 metrics.k8s.io,主要的实现就是 metrics-server,它提供的是资源的监控,比较常见的是节点级别、pod 级别、namespace 级别、class 级别。这类的监控指标都可以通过 metrics.k8s.io 这个接口获取到。
第二类 Custom Metrics
对应的 API 是 custom.metrics.k8s.io,主要的实现是 Prometheus。它提供的是资源监控和自定义监控,资源监控和上面的资源监控其实是有覆盖关系的,而这个自定义监控指的是:比如应用上面想暴露一个类似像在线人数,或者说调用后面的这个数据库的 MySQL 的慢查询。这些其实都是可以在应用层做自己的定义的,然后并通过标准的 Prometheus 的 client,暴露出相应的 metrics,然后再被 Prometheus 进行采集。
而这类的接口一旦采集上来也是可以通过类似像 custom.metrics.k8s.io 这样一个接口的标准来进行数据消费的,也就是说现在如果以这种方式接入的 Prometheus,那你就可以通过 custom.metrics.k8s.io 这个接口来进行 HPA,进行数据消费。
第三类 External Metrics
External Metrics 其实是比较特殊的一类,因为我们知道 K8s 现在已经成为了云原生接口的一个实现标准。很多时候在云上打交道的是云服务,比如说在一个应用里面用到了前面的是消息队列,后面的是 RBS 数据库。那有时在进行数据消费的时候,同时需要去消费一些云产品的监控指标,类似像消息队列中消息的数目,或者是接入层 SLB 的 connection 数目,SLB 上层的 200 个请求数目等等,这些监控指标。