docker run 参数补充
–pid 为容器设置pid (进程) namespace mode
-
‘container:<name id>’: joins another container’s PID namespace - ‘host’: use the host’s PID namespace inside the container
PID namespace 默认进程隔离,移除系统宿主机进程,复用pid 1。
–uts 设置hostname和downmain
- ‘host’: use the host’s UTS namespace inside the container
docker run –uts=host ubuntu hostname 创建宿主机主机名的容器
–ipc 设置共享内存
IPC (POSIX/SysV IPC) namespace provides separation of named shared memory segments, semaphores and message queues.
问答
已运行 docker run -d -t —name demo ubuntu top 和 docker run –name demo-x –pid container:demo ubuntu ps 命令,如果 demo 容器退出了,正在运行的 demo-x 容器是否会退出?
是
已知容器 Init 进程 PID,在宿主机上通过 kill -9 PID 的方式结束该进程,容器当前的状态是什么?
Exited
已运行 docker run -d -t —name demo ubuntu top 命令, 在 demo 这个容器内看到 top 命令的 PID 是什么?
1
已运行 docker run -d -t —name demo ubuntu top 命令, docker exec -it demo kill -9 1 强行给容器内一号进程发KILL信号,容器是否会退出
否
已运行 docker run -d —name demo busybox:1.25 top 命令,如何使用 docker 命令来获取容器 demo 的 Init 进程 PID?
docker inspect demo -f ''
pid 1
在Linux操作系统中,当内核初始化完毕之后,会启动一个init进程,这个进程是整个操作系统的第一个用户进程,所以它的进程ID为1,也就是我们常说的PID1进程。在这之后,所有的用户态进程都是该进程的后代进程,由此我们可以看出,整个系统的用户进程,是一棵由init进程作为根的进程树。
SIGKILL信号对它无效,很显然,如果我们将一棵树的树根砍了,那么这棵树就会分解成很多棵子树,这样的最终结果是导致整个操作系统进程杂乱无章,无法管理。
基本概念
进程表项
linux内核程序通过进程表对进程进行管理, 每个进程在进程表中占有一项,记录了进程的状态,打开的文件描述符等等一系统信息。称为进程表项。
当一个进程结束了运行或在半途中终止了运行,那么内核就需要释放该进程所占用的系统资源。这包括进程运行时打开的文件,申请的内存等。但是,进程表项并没有随着进程的退出而被清除,它会一直占用内核的内存。
这是因为在某些程序中,我们必须明确地知道进程的退出状态等信息,而这些信息的获取是由父进程调用wait/waitpid而获取的。设想这样一种场景,如果子进程在退出的时候直接清除文件表项的话,那么父进程就很可能没有地方获取进程的退出状态了,因此操作系统就会将文件表项一直保留至wait/waitpid系统调用结束。
僵尸进程
监视进程:进程退出后,到其父进程还未对其调用wait/waitpid之间的这段时间所处的状态。
一般来说,这种状态持续的时间很短,所以我们一般很难在系统中捕捉到。但是,一些粗心的程序员可能会忘记调用wait/waitpid,或者由于某种原因未执行该调用等等,那么这个时候就会出现长期驻留的僵尸进程了。如果大量的产生僵尸进程,其进程号就会一直被占用,可能导致系统不能产生新的进程。 列如:父进程先于子进结束
孤儿进程
父进程先于子进程退出,那么子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)接管,并由init进程对它完成状态收集(wait/waitpid)工作。
PID 1负责清理那些被抛弃的进程所留下来的痕迹,有效的回收的系统资源,保证系统长时间稳定的运行,可谓是功不可没。
容器里的pid1
容器并不是一个完整的操作系统,它没有什么内核初始化过程。
在容器中被标志为PID 1的进程实际上就是一个普普通通的用户进程,也就是我们制作镜像时在Dockerfile中指定的ENTRYPOINT的那个进程。
这个进程在宿主机上有一个普普通通的进程ID,而在容器中之所以变成PID 1,是因为linux内核提供的PID namespaces功能,如果宿主机的所有用户进程构成了一个完整的树型结构,那么PID namespaces实际上就是将这个ENTRYPOINT进程(包括它的后代进程)从这棵大树剪下来。
1 | |
容器外部kill -9 8090,那整个容器便会处于退出状态
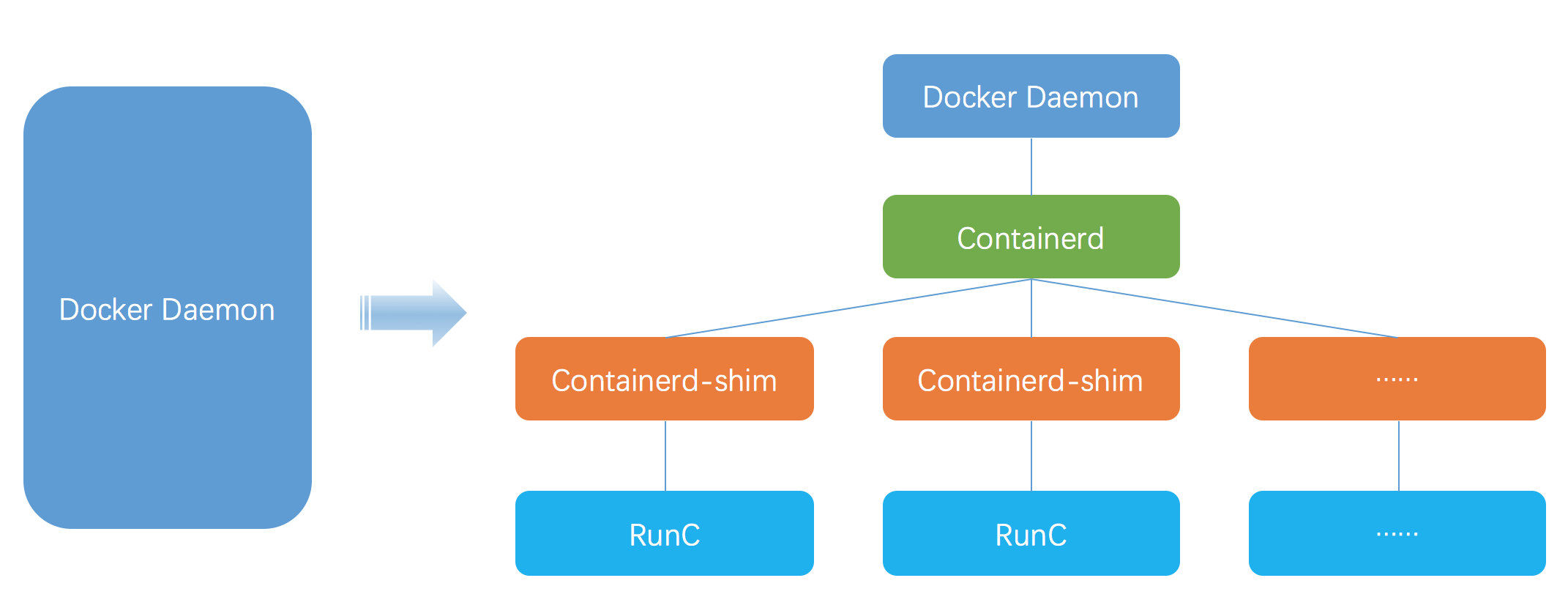
从架构图中我们可以看到shim进程下还有一个runC进程,但我们在进程树中并没有发现runC这个进程。
runC是OCI标准的一个参考实现,而OCI Open Container Initiative,是由多家公司共同成立的项目,并由linux基金会进行管理,致力于container runtime的标准的制定和runc的开发等工作。runc,是对于OCI标准的一个参考实现,是一个可以用于创建和运行容器的CLI(command-line interface)工具。runc直接与容器所依赖的cgroup/linux kernel等进行交互,负责为容器配置cgroup/namespace等启动容器所需的环境,创建启动容器的相关进程。
Docker容器的创建过程是这样子的 docker-containerd-shim –> runC –> entrypoint,而我们看到的最终状态是 docker-containerd-shim –> entrypoint,聪明的你可能已经猜到,runc进程创建完容器之后,自己就先退出去了。但是这里面其实暗藏了一个问题,按照前面提到的孤儿进程理论,entrypint进程应该由操作系统的PID 1进程接管,但为什么会被shim接管呢?
PR_SET_CHILD_SUBREAPER
linux在内核3.14以后版本支持该系统调用,它可以将调用进程标记“child subreaper”属性,而拥有该属性的进程则可以充当init(1)进程的功能,收养其后代进程中所产生的孤儿进程。我们可以从shim的源码中找到答案
2
3
4
5
6
7
8
9
10
11func start(log *os.File) error { // start handling signals as soon as possible so that things are properly reaped // or if runtime exits before we hit the handler signals := make(chan os.Signal, 2048) signal.Notify(signals) // set the shim as the subreaper for all orphaned processes created by the container if err := osutils.SetSubreaper(1); err != nil { return err } ... }既然充当了reaper的角色,那么就应该尽到回收资源的责任:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24func start(log *os.File) error { ... switch s { case syscall.SIGCHLD: exits, _ := osutils.Reap(false) ... } ... } func Reap(wait bool) (exits []Exit, err error) { ... for { pid, err := syscall.Wait4(-1, &ws, flag, &rus) if err != nil { if err == syscall.ECHILD { return exits, nil } return exits, err } ... } }从这里我们可以看到shim的wait/waitpid系统调用。
RuningTime
OCI
Open Container Initiative,也就是常说的OCI,是由多家公司共同成立的项目,并由linux基金会进行管理,致力于container runtime的标准的制定和runc的开发等工作。
它的核心目标围绕容器的格式和运行时制定一个开放的工业化标准,并推动这个标准,保持容器的灵活性和开放性,容器能运行在任何的硬件和系统上。 容器不应该绑定到特定的客户机或编排堆栈,不应该与任何特定的供应商紧密关联,并且可以跨多种操作系统
容器镜像标准(image-spec)
容器镜像要长啥样
- 文件系统: 以layer保存的文件系统,每个layer保存了和上层之间变化的部分,layer应该保存哪些文件,怎么表示增加、修改和删除的文件等
- config文件: 保存了文件系统的层级信息(每个层级的hash值,以及历史信息)以及容器运行时需要的一些信息(比如环境变量、工作目录、命令参数、mount 列表)
- manifest文件: 镜像的config文件索引,有哪些layer,额外的annotation信息,manifest文件中保存了很多和当前平台有关的信息
- index文件: 可选的文件,指向不同平台的manifest文件,这个文件能保证一个镜像可以跨平台使用,每个平台拥有不同的manifest文件,使用index作为索引
容器运行时标准(runtime spec)
容器要需要能接收哪些指令
容器的状态包括如下属性
-
ociVersion: OCI版本
-
id: 容器的ID,在宿主机唯一
-
status:
容器运行时状态,生命周期
- creating: 使用 create 命令创建容器,这个过程称为创建中,创建包括文件系统、namespaces、cgroups、用户权限在内的各项内容
- created: 容器创建出来,但是还没有运行,表示镜像和配置没有错误,容器能够运行在当前平台
- running: 容器的运行状态,里面的进程处于up状态,正在执行用户设定的任务
- stopped: 容器运行完成,或者运行出错或者stop命令之后,容器处于暂停状态,这个状态,容器还有很多信息保存在平台中,并没有完全被删除
-
pid: 容器进程在宿主机的进程ID
-
bundle: 容器文件目录,存放容器rootfs及相应配置的目录
-
annotations: 与容器相关的注释
container runtime
主要负责的是容器的生命周期的管理。oci的runtime spec标准中对于容器的状态描述,以及对于容器的创建、删除、查看等操作进行了定义。
runc
对于OCI标准的一个参考实现,是一个可以用于创建和运行容器的CLI(command-line interface)工具。runc直接与容器所依赖的cgroup/linux kernel等进行交互,负责为容器配置cgroup/namespace等启动容器所需的环境,创建启动容器的相关进程。
containerd
为了兼容oci标准,docker也做了架构调整。将容器运行时相关的程序从docker daemon剥离出来,形成了containerd。Containerd向docker提供运行容器的API,二者通过grpc进行交互。containerd最后会通过runc来实际运行容器。
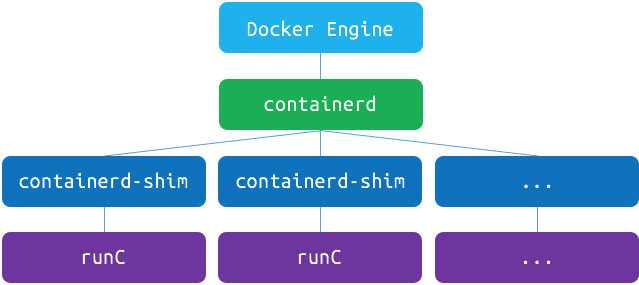
containerd-shim
containerd-shim进程由containerd进程拉起,即containerd进程是containerd-shim的父进程, 容器进程由containerd-shim进程拉起, 这样的优点比如升级,重启docker或者containerd 不会影响已经running的容器进程, 而假如这个父进程就是containerd,那每次containerd挂掉或升级,整个宿主机上所有的容器都得退出了. 而引入了 containerd-shim 就规避了这个问题(当 containerd 退出或重启时, shim 会 re-parent 到 systemd 这样的 1 号进程上)
接下来讲一下容器引擎,我们基于 CNCF 的一个容器引擎上的 containerd,来讲一下容器引擎大致的构成。下图是从 containerd 官网拿过来的一张架构图,基于这张架构图先简单介绍一下 containerd 的架构。
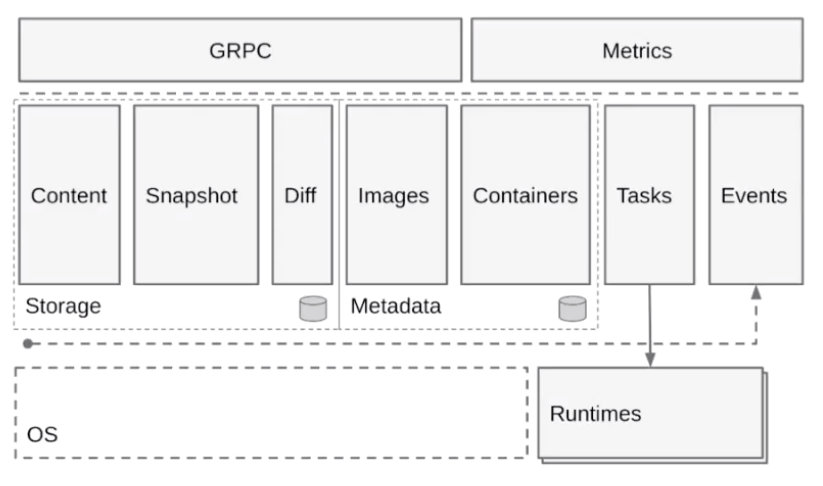
上图如果把它分成左右两边的话,可以认为 containerd 提供了两大功能。
第一个是对于 runtime,也就是对于容器生命周期的管理,左边 storage 的部分其实是对一个镜像存储的管理。containerd 会负责进行的拉取、镜像的存储。
按照水平层次来看的话:
-
第一层是 GRPC,containerd 对于上层来说是通过 GRPC serve 的形式来对上层提供服务的。Metrics 这个部分主要是提供 cgroup Metrics 的一些内容。
-
下面这层的左边是容器镜像的一个存储,中线 images、containers 下面是 Metadata,这部分 Matadata 是通过 bootfs 存储在磁盘上面的。右边的 Tasks 是管理容器的容器结构,Events 是对容器的一些操作都会有一个 Event 向上层发出,然后上层可以去订阅这个 Event,由此知道容器状态发生什么变化。
-
最下层是 Runtimes 层,这个 Runtimes 可以从类型区分,比如说 runC 或者是安全容器之类的。
shim v1/v2 是什么
接下来讲一下 containerd 在 runtime 这边的大致架构。下面这张图是从 kata 官网拿过来的,上半部分是原图,下半部分加了一些扩展示例,基于这张图我们来看一下 containerd 在 runtime 这层的架构。
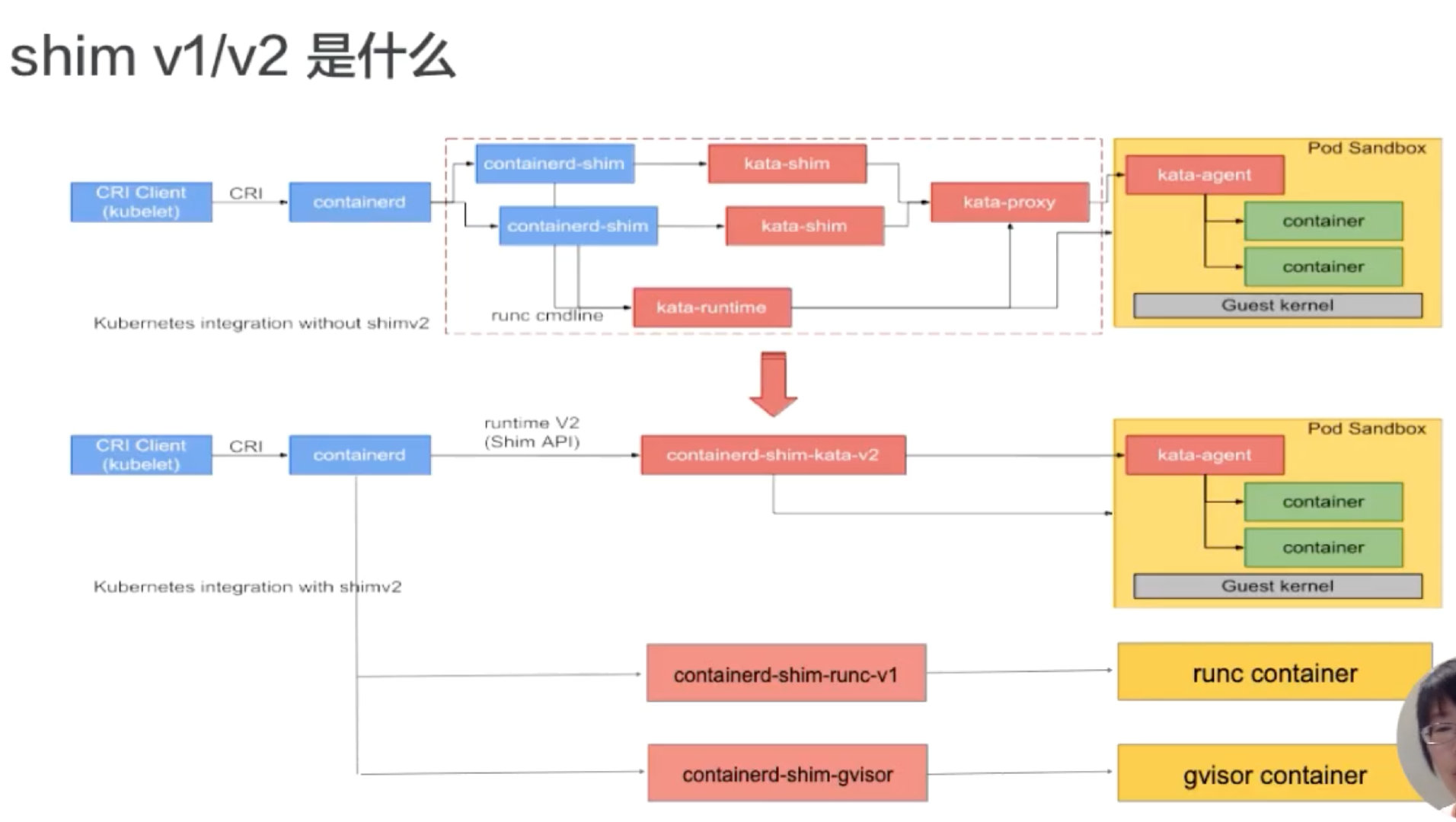
如图所示:按照从左往右的一个顺序,从上层到最终 runtime 运行起来的一个流程。
我们先看一下最左边,最左边是一个 CRI Client。一般就是 kubelet 通过 CRI 请求,向 containerd 发送请求。containerd 接收到容器的请求之后,会经过一个 containerd shim。containerd shim 是管理容器生命周期的,它主要负责两方面:
- 第一个是它会对 io 进行转发。
- 第二是它会对信号进行传递。
图的上半部分画的是安全容器,也就是 kata 的一个流程,这个就不具体展开了。下半部分,可以看到有各种各样不同的 shim。下面介绍一下 containerd shim 的架构。
一开始在 containerd 中只有一个 shim,也就是蓝色框框起来的 containerd-shim。这个进程的意思是,不管是 kata 容器也好、runc 容器也好、gvisor 容器也好,上面用的 shim 都是 containerd。
后面针对不同类型的 runtime,containerd 去做了一个扩展。这个扩展是通过 shim-v2 这个 interface 去做的,也就是说只要去实现了这个 shim-v2 的 interface,不同的 runtime 就可以定制不同的自己的一个 shim。比如:runC 可以自己做一个 shim,叫 shim-runc;gvisor 可以自己做一个 shim 叫 shim-gvisor;像上面 kata 也可以自己去做一个 shim-kata 的 shim。这些 shim 可以替换掉上面蓝色框的 containerd-shim。
这样做的好处有很多,举一个比较形象的例子。可以看一下 kata 这张图,它上面原先如果用 shim-v1 的话其实有三个组件,之所以有三个组件的原因是因为 kata 自身的一个限制,但是用了 shim-v2 这个架构后,三个组件可以做成一个二进制,也就是原先三个组件,现在可以变成一个 shim-kata 组件,这个可以体现出 shim-v2 的一个好处。
containerd 容器架构详解 - 容器流程示例
接下来我们以两个示例来详细解释一下容器的流程是怎么工作的,下面的两张图是基于 containerd 的架构画的一个容器的工作流程。
start 流程
先看一下容器 start 的流程:
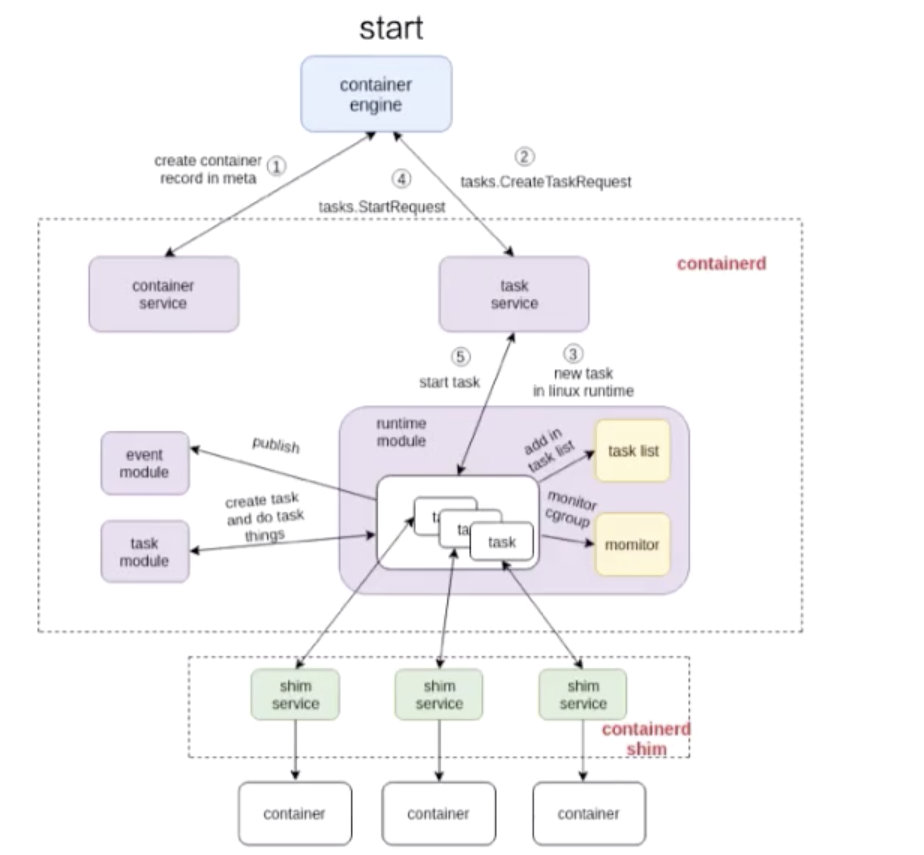
这张图由三个部分组成:
- 第一个部分是容器引擎部分,容器引擎可以是 docker,也可以是其它的。
- 两个虚线框框起来的 containerd 和 containerd-shim,它们两个是属于 containerd 架构的部分。
- 最下面就是 container 的部分,这个部分是通过一个 runtime 去拉起的,可以认为是 shim 去操作 runC 命令创建的一个容器。
先看一下这个流程是怎么工作的,图里面也标明了 1、2、3、4。这个 1、2、3、4 就是 containerd 怎么去创建一个容器的流程。
首先它会去创建一个 matadata,然后会去发请求给 task service 说要去创建容器。通过中间一系列的组件,最终把请求下发到一个 shim。containerd 和 shim 的交互其实也是通过 GRPC 来做交互的,containerd 把创建请求发给 shim 之后,shim 会去调用 runtime 创建一个容器出来,以上就是容器 start 的一个示例。
exec 流程
接下来看下面这张图,是怎么去 exec 一个容器的。和 start 流程非常相似,结构也大概相同,不同的部分其实就是 containerd 怎么去处理这部分流程。和上面的图一样,我也在图中标明了 1、2、3、4,这些步骤就代表了 containerd 去做 exec 的一个先后顺序。
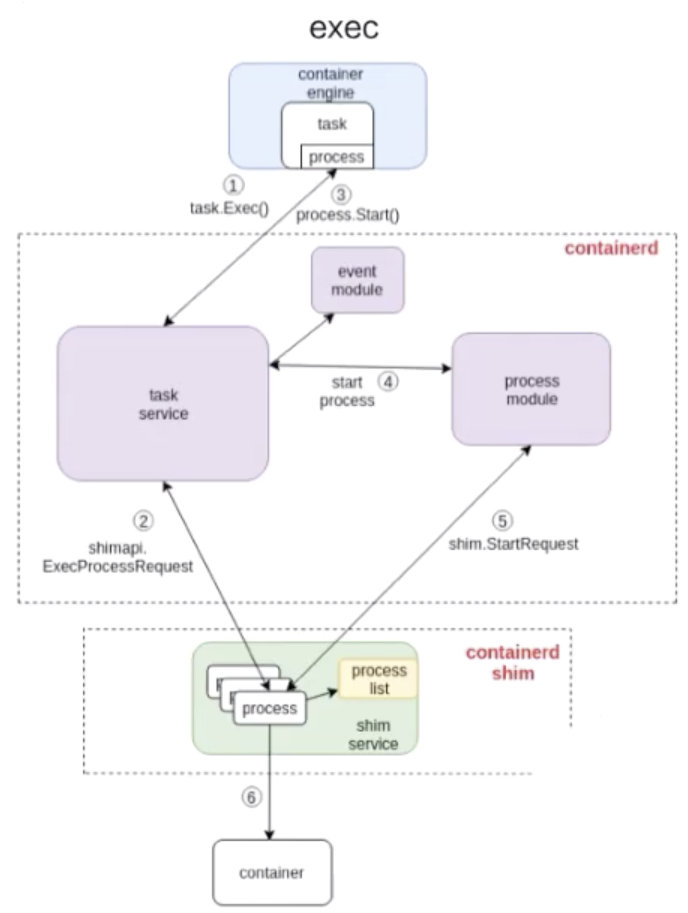
由上图可以看到,exec 的操作还是发给 containerd-shim 的。对容器来说,去 start 一个容器和去 exec 一个容器,其实并没有本质的区别。
最终的一个区别无非就是,是否对容器中跑的进程做一个 namespace 的创建:
- exec 的时候,需要把这个进程加入到一个已有的 namespace 里面;
- start 的时候,容器进程的 namespace 是需要去专门创建。
容器引擎
容器引擎,不仅包含对于容器的生命周期的管理,还包括了对于容器生态的管理。
docker可以分为两个阶段来理解。
- docker版本为1.2,当时的docker的主要作用是容器的生命周期管理和镜像管理,当时的docker在功能上更趋近于现在的container runtime。
- 而后来,随着docker的发展,docker就不再局限于容器的管理,还囊括了存储(volume)、网络(net)等的管理,因此后来的docker更多的是一个容器及容器生态的管理平台。
kubernetes与容器
kubernetes在初期版本里,就对多个容器引擎做了兼容,因此可以使用docker、rkt对容器进行管理。以docker为例,kubelet中会启动一个docker manager,通过直接调用docker的api进行容器的创建等操作。
在k8s 1.5版本之后,kubernetes推出了自己的运行时接口api–CRI(container runtime interface)。cri接口的推出,隔离了各个容器引擎之间的差异,而通过统一的接口与各个容器引擎之间进行互动。
与oci不同,cri与kubernetes的概念更加贴合,并紧密绑定。cri不仅定义了容器的生命周期的管理,还引入了k8s中pod的概念,并定义了管理pod的生命周期。在kubernetes中,pod是由一组进行了资源限制的,在隔离环境中的容器组成。而这个隔离环境,称之为PodSandbox。在cri开始之初,主要是支持docker和rkt两种。其中kubelet是通过cri接口,调用docker-shim,并进一步调用docker api实现的。
到kubernetes1.11版本Kubelet内置的rkt代码删除,CNI的实现迁移到dockers-shim之内,,除了docker之外,其他的容器运行时都通过CRI接入。
外部的容器运行时一般称为CRI shim,它除了实现CRI接口外,也要负责为容器配置网络,即CNI,有了CNI可以支持社区内的众多网络插件.
如上文所述,docker独立出来了containerd。kubernetes也顺应潮流,孵化了cri-containerd项目,用以将containerd接入到cri的标准中。
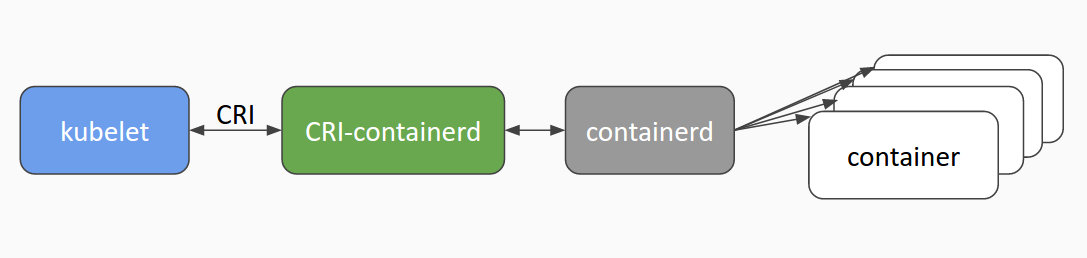
为了进一步与oci进行兼容,kubernetes还孵化了cri-o,成为了架设在cri和oci之间的一座桥梁。通过这种方式,可以方便更多符合oci标准的容器运行时,接入kubernetes进行集成使用。可以预见到,通过cri-o,kubernetes在使用的兼容性和广泛性上将会得到进一步加强。
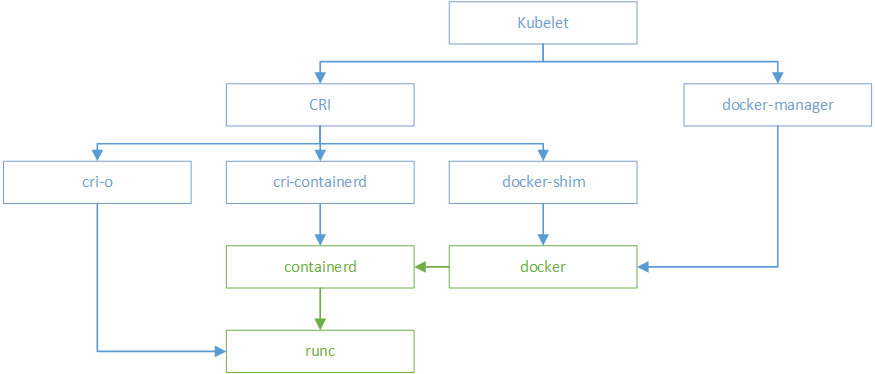
kubelet拉起一个容器的过程
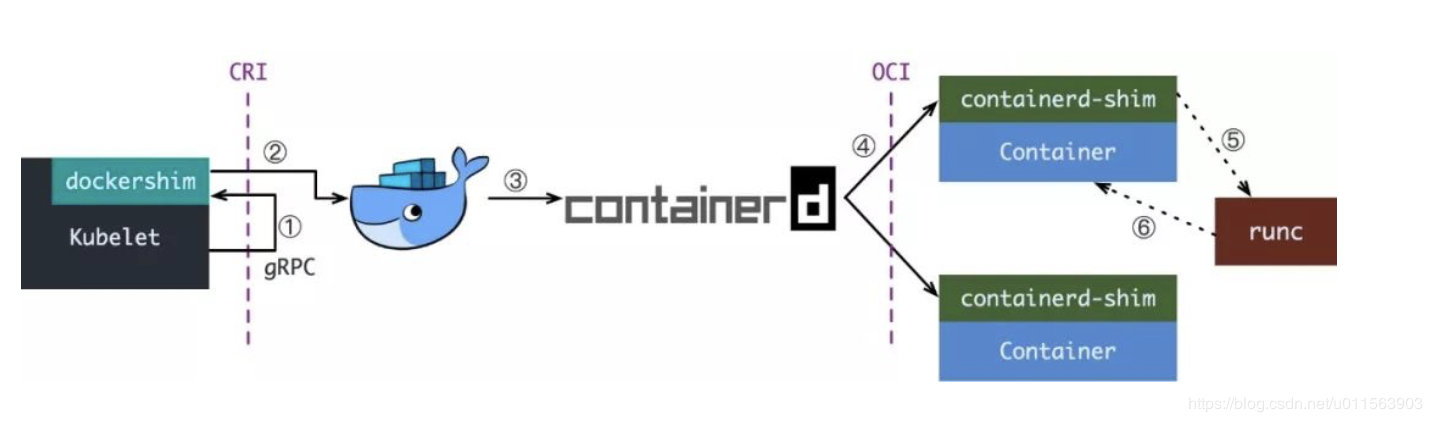
-
Kubelet 通过 CRI 接口(gRPC)调用 dockershim,请求创建一个容器。CRI 即容器运行时接口(Container Runtime Interface),这一步中,Kubelet 可以视作一个简单的 CRI Client,而 dockershim 就是接收请求的 Server。目前 dockershim 的代码其实是内嵌在 Kubelet 中的,所以接收调用的凑巧就是 Kubelet 进程;
-
docker-shim收到请求后,转化成Docker Daemon能听懂的请求,发到Docker Daemon上请求创建一个容器
-
Docker Daemon 早在 1.12 版本中就已经将针对容器的操作移到另一个守护进程——containerd 中了,因此 Docker Daemon 仍然不能帮我们创建容器,而是要请求 containerd 创建一个容器
- containerd 收到请求后,并不会自己直接去操作容器,而是创建一个叫做 containerd-shim 的进程,让 containerd-shim 去操作容器。这是因为容器进程需要一个父进程来做诸如收集状态,维持 stdin 等 fd 打开等工作。而假如这个父进程就是 containerd,那每次 containerd 挂掉或升级,整个宿主机上所有的容器都得退出了。而引入了 containerd-shim 就规避了这个问题(containerd 和 shim 并不是父子进程关系);
-
我们知道创建容器需要做一些设置 namespaces 和 cgroups,挂载 root filesystem 等等操作,而这些事该怎么做已经有了公开的规范了,那就是 OCI(Open Container Initiative,开放容器标准)。它的一个参考实现叫做 runC。于是,containerd-shim 在这一步需要调用 runC 这个命令行工具,来启动容器
- runC 启动完容器后本身会直接退出,containerd-shim则会成为容器进程的父进程,负责收集容器进程的状态,上报给containerd,并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理,确保不会出现僵尸进程。
CRI
kubelet通过CRI(container runtime interface)的标准来与外部容器运行时进行交互。
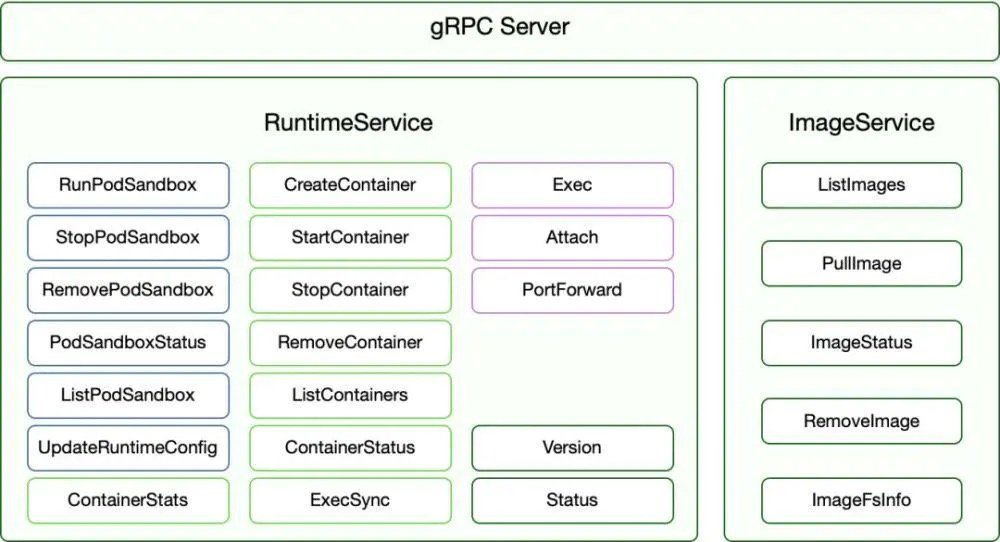 CRI主要定义两个接口, ImageService和RuntimeService。
CRI主要定义两个接口, ImageService和RuntimeService。
ImageService:负责镜像的生命管理周期
- 查询镜像列表
- 拉取镜像到本地
- 查询镜像状态
- 删除本地镜像
- 查询镜像占用空间
RuntimeService:负责管理Pod和容器的生命周期
- PodSandbox 的管理接口 PodSandbox是对kubernete Pod的抽象,用来给容器提供一个隔离的环境(比如挂载到相同的cgroup下面)并提供网络等共享的命名空间.PodSandbox通常对应到一个Pause容器或者一台虚拟机
- Container 的管理接口 在指定的 PodSandbox 中创建、启动、停止和删除容器。
- Streaming API接口 包括Exec、Attach和PortForward 等三个和容器进行数据交互的接口,这三个接口返回的是运行时Streaming Server的URL,而不是直接跟容器交互
- 状态接口 包括查询API版本和查询运行时状态
总结
容器生态可以下面的三层抽象:
Orchestration API -> Container API -> Kernel API
- Orchestration API: kubernetes API标准就是这层的标准,无可非议
- Container API: 标准就是CRI
- Kernel API: 标准就是OCI