背景
1 | |
table xx 通过消费kafka插入数据
问题一
发现前端没有数据展示,查看表只有前几天的数据
初步
初步看log,认为是数据是没有,或者程序哪里有bug
-
看后台log
-
clickhouse log
/var/log/clickhouse-server/clickhouse-server.loglog路径1
2
32020.04.23 15:20:02.326403 [ 34194 ] {} <Trace> StorageKafka (kafka_xx): Polled batch of 100 messages. Offset position: [ xx[0:7223895730] ] 。。。。 2020.04.23 15:20:02.851093 [ 34195 ] {} <Trace> StorageKafka (kafka_xx): Committed offset 7223895830 (topic: xx, partition: 0)发现clickhouse在消费kafka 瞄了下消费记录大概200 rows/sec
-
使用kafka命令
查看 consumer-groups list
1
bin/kafka-consumer-groups.sh --list --bootstrap-server localhost:9092 --command-config config/client_security.propertiesssl 消费某个topic
1
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic xx --consumer.config config/client_security.properties发现有数据可以消费,从数据带有的时间戳是今天的,那clickhouse消费了啥
1
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group group1 --command-config config/client_security.properties- CURRENT-OFFSET 消费到哪个offset
- LOG-END-OFFSET 最新的offset
- LAG offset相差
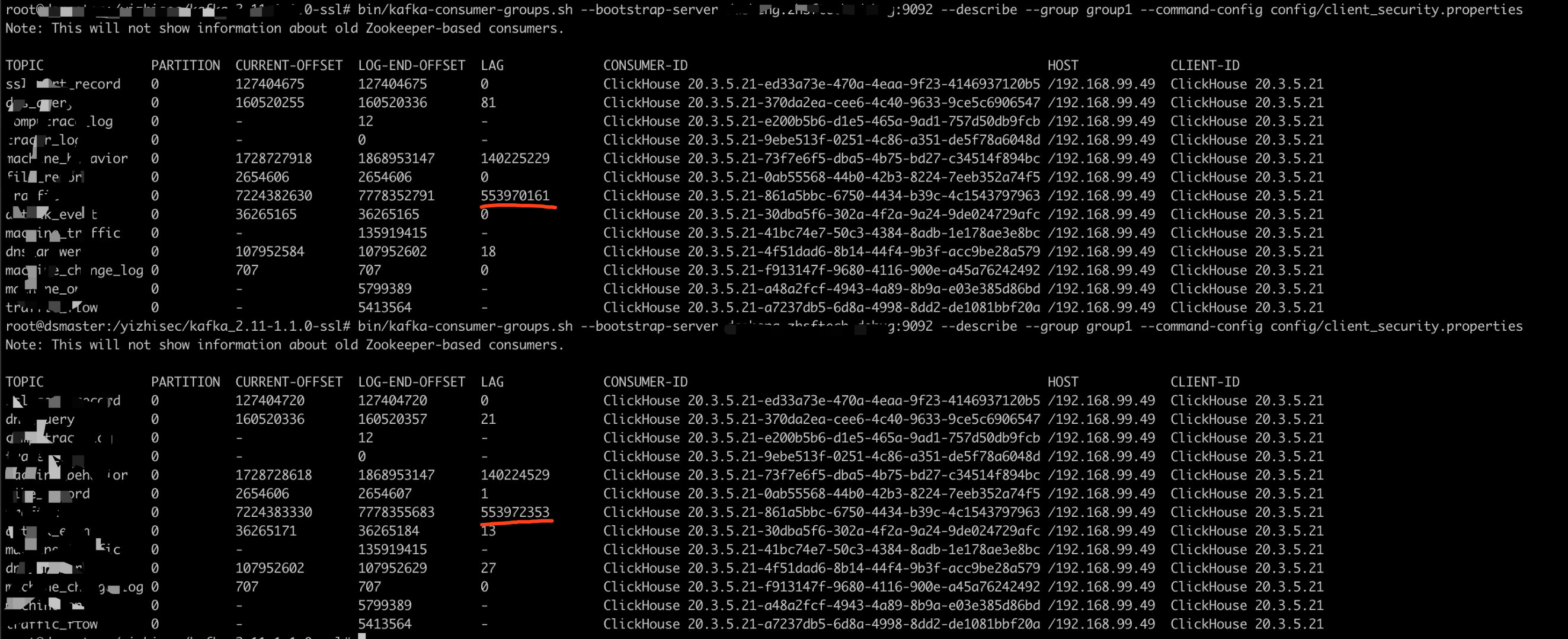
原因找到了clickhouse消费速度跟不上生产速度,差距还越拉越大
解决
-
加大消费力
增大kafka_max_block_size,可以直接drop table再重建, 不会影响offset
-
参数优化
https://clickhouse.tech/docs/en/engines/table_engines/integrations/kafka/#description

engine 改变
1 | |
问题二
数据库没有缺数据查不出来
背景
配置文件
1 | |
因为数据量比较大在users.xml设置了几个user,然后里面设置了max_rows_to_read <max_rows_to_read>20000000</max_rows_to_read>
-
clickhouse查询会使用多线程,没有使用PARTITION key,会有多个线程一起查,到了max_rows_to_read就停止了。
这样会导致一种境况,可能每次查询到的结果都有些不一样
-
使用了PARTITION key可以限制查询分区,按月分区
如果分区里面的数量太大,也可能查询不了,应该再细分分区按日,减少分区数据量,但是这样会使磁盘空间变大,提高按日的性能。