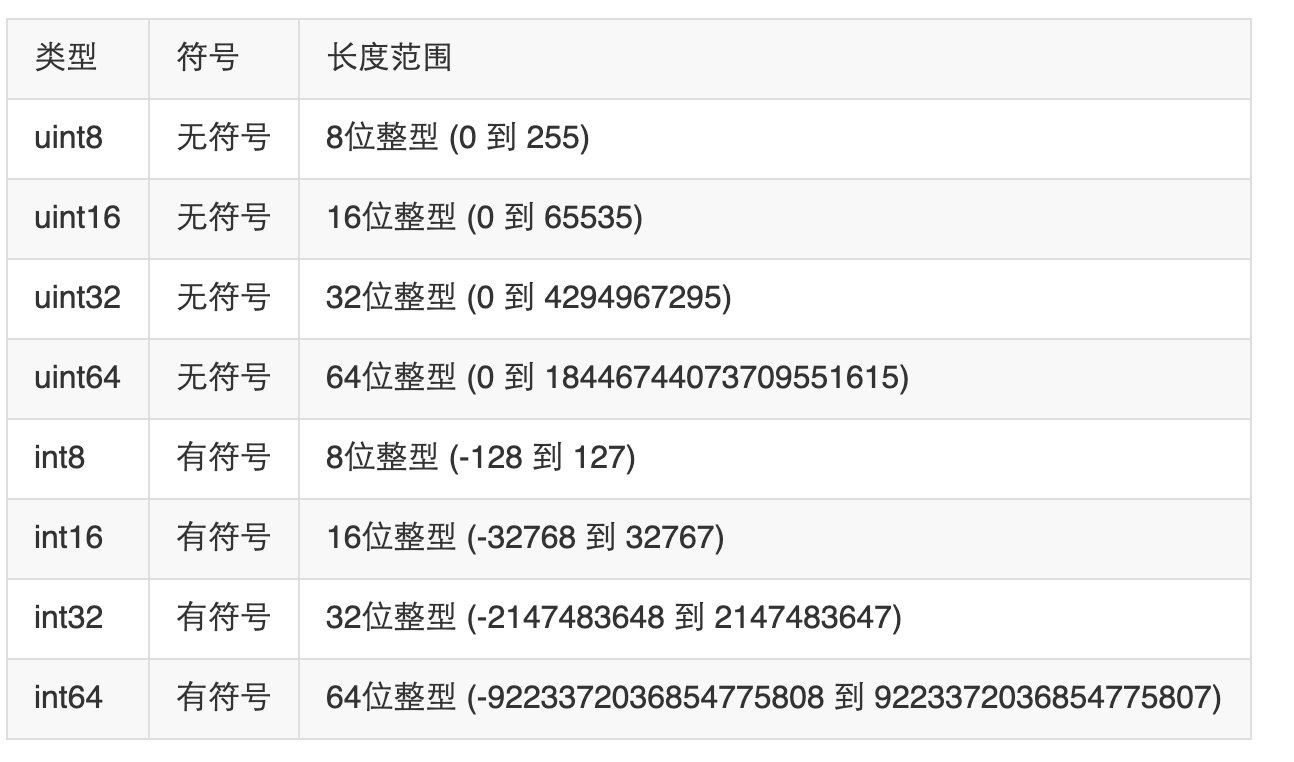
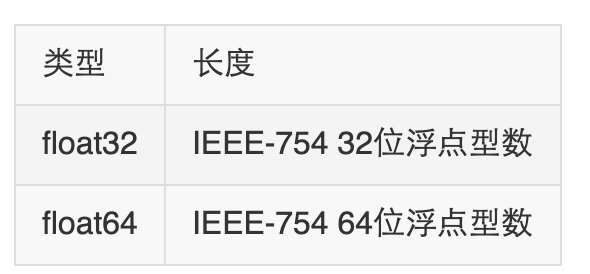
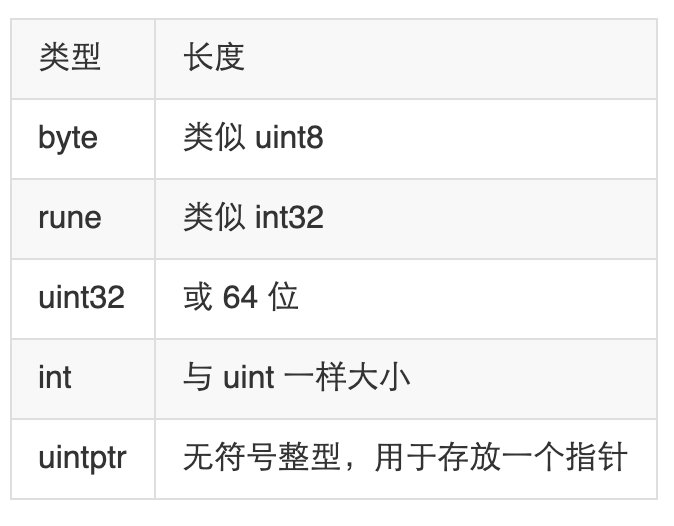
变量
Go 语言变量名由字母、数字、下划线组成,其中首个字母不能为数字。
var ( a int b bool str string ) 这种因式分解关键字的写法一般用于声明全局变量,一般在func 外定义。
当一个变量被var声明之后,系统自动赋予它该类型的零值:
int 为 0 float 为 0.0 bool 为 false string 为空字符串”” 指针为 nil 记住,这些变量在 Go 中都是经过初始化的。
声明赋值
声明
1 | |
声明赋值 := 结构不能在函数外使用
1 | |
作用域的坑
声明赋值
1 | |
表达式new(T)将创建一个T类型的匿名变量,初始化为T类型的零值,然后返回变量地址,返回的指针类型为*T。
1 | |
1 | |
生命周期
变量的生命周期指的是在程序运行期间变量有效存在的时间间隔。对于在包一级声明的变量来说,它们的生命周期和整个程序的运行周期是一致的。而相比之下,局部变量的声明周期则是动态的: 每次从创建一个新变量的声明语句开始,直到该变量不再被引用为止,然后变量的存储空间可能被回收。函数的参数变量和返回值变量都是局部变量。它们在函数每次被调用的时候创建。
常量
1 | |
枚举 从0开始 每遇到一次 const 关键字,iota 就重置为 0
1 | |
数组
数组长度也是数组类型的一部分,所以[5]int和[10]int是属于不同类型的。
1 | |
1 | |
把一个大数组传递给函数会消耗很多内存。有两种方法可以避免这种现象:
- 传递数组的指针
- 使用数组的切片
切片
一直觉得这是定义数组另一种方式
切片是引用,本身就是一个指针。所以它们不需要使用额外的内存并且比使用数组更有效率,所以在 Go 代码中切片比数组更常用
多个切片如果表示同一个数组的片段,它们可以共享数据;因此一个切片和相关数组的其他切片是共享存储的
一个slice由三个部分构成:指针、长度和容量。
1 | |
1 | |
1 | |
Go 中切片扩容的策略是这样的:
- 首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)
- 否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap)
- 否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的 1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
- 如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)
- 新切片指向的数组是一个全新的数组。并且 cap 容量也发生了变化
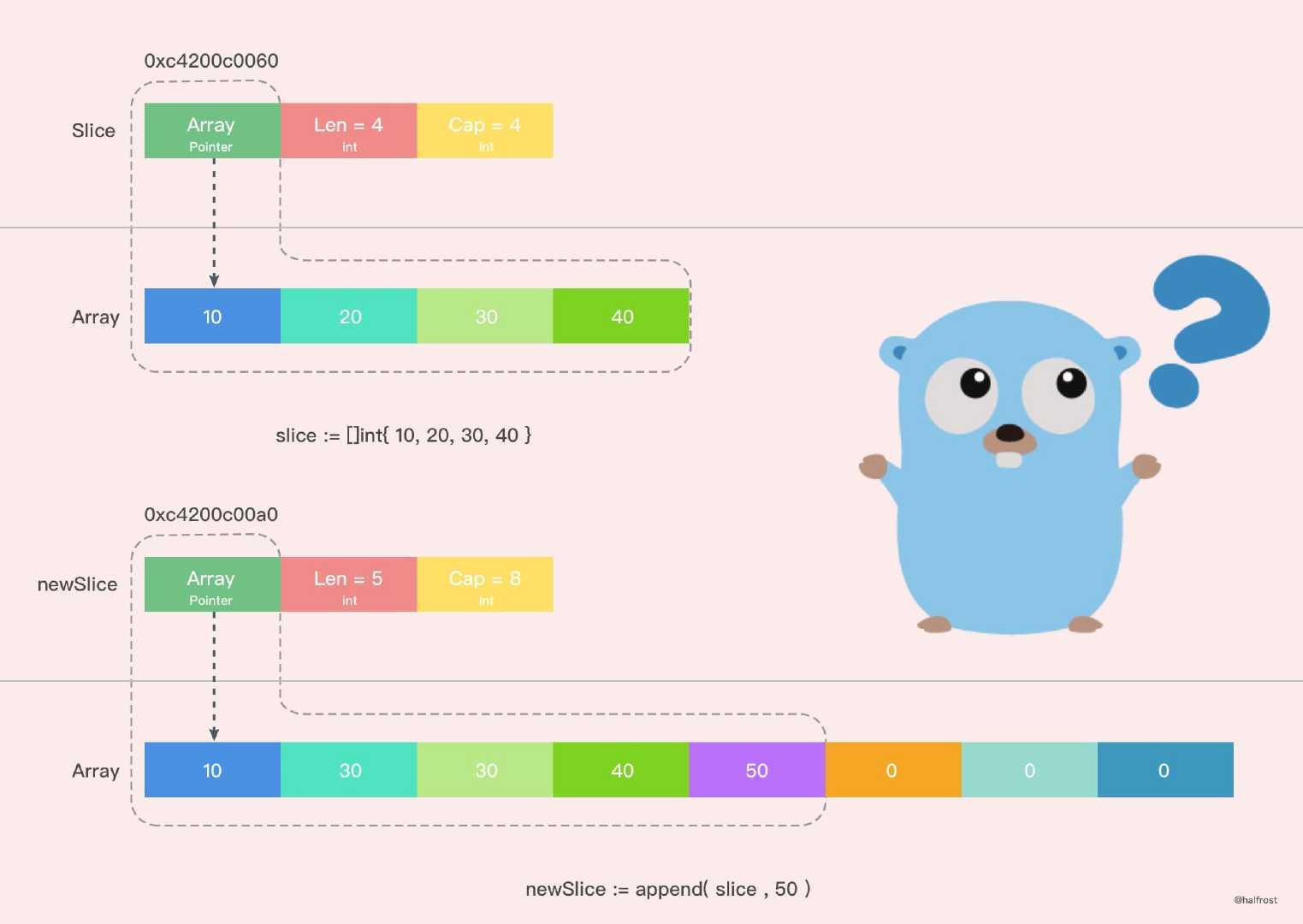
append 操作
- slice底层数组是否有足够的容量来保存新添加的元素。如果有足够空间的话,直接扩展slice
- 没有足够的增长空间的话,会先分配一个足够大的slice用于保存新的结果,先将输入的x复制到新的空间,然后添加y元素
和数组不同的是,slice之间不能比较,因此我们不能使用==操作符来判断两个slice是否含有全部相等元素
slice唯一合法的比较操作是和nil比较
1 | |
如果用 range 的方式去遍历一个切片,拿到的 Value 其实是切片里面的值拷贝。所以每次打印 Value 的地址都不变。通过 &slice[index] 获取真实的地址
map
map 是引用类型 未初始化的 map 的值是 nil
1 | |
key可以用 == 或者 != 操作符比较的类型
数组、切片和结构体不能作为 key (含有数组切片的结构体不能作为 key,只包含内建类型的 struct 是可以作为 key 的)
value 可以是任意类型的;通过使用空接口类型,我们可以存储任意值
通过 key 在 map 中寻找值是很快的,比线性查找快得多,但是仍然比从数组和切片的索引中直接读取要慢 100 倍;所以如果你很在乎性能的话还是建议用切片来解决问题。
Go 语言中,通过哈希查找表实现 map,用链表法解决哈希冲突。
通过 key 的哈希值将 key 散落到不同的桶中,每个桶中有 8 个 cell。哈希值的低位决定桶序号,高位标识同一个桶中的不同 key。
当向桶中添加了很多 key,造成元素过多,或者溢出桶太多,就会触发扩容。扩容分为等量扩容和 2 倍容量扩容。扩容后,原来一个 bucket 中的 key 一分为二,会被重新分配到两个桶中。
扩容过程是渐进的,主要是防止一次扩容需要搬迁的 key 数量过多,引发性能问题。触发扩容的时机是增加了新元素,bucket 搬迁的时机则发生在赋值、删除期间,每次最多搬迁两个 bucket。
查找、赋值、删除的一个很核心的内容是如何定位到 key 所在的位置,需要重点理解。一旦理解,关于 map 的源码就可以看懂了。
struct
1 | |
new 函数给一个新的结构体变量分配内存,它返回指向已分配内存的指针:var t *T =
new(T) 表达式 new(Type) 和 &Type{} 是等价的。
匿名成员
匿名成员的数据类型必须是命名的类型或指向一个命名的类型的指针
1 | |
但是构造时还是要写清楚
1 | |
实际上,外层的结构体不仅仅是获得了匿名成员类型的所有成员,而且也获得了该类型导出的全部的方法。
错误处理
自定义错误
1 | |
错误处理
- 失败的原因只有一个/没有失败时,不使用error
- error应放在返回值类型列表的最后
- 错误值统一定义,方便上层函数要对特定错误value进行统一处理
- 当上层函数不关心错误时,建议不返回error
- 当尝试几次可以避免失败时,不要立即返回错误
- 在程序部署后,应恢复异常避免程序终止 recover
panic 处理
1 | |
- A call to
recoverstops the unwinding and returns the argument passed topanic. - If the goroutine is not panicking,
recoverreturnsnil.
The only code that runs while unwinding is inside deferred functions, recover is only useful inside such functions. 只能在 defer 中发挥作用的函数,在其他作用域中调用不会发挥作用。
panic只会触发当前 Goroutine 的deferrecover只有在defer中调用才会生效,recover只有在发生panic之后调用才会生效
defer
1 | |
defer、return、返回值三者的执行顺序应该是:return最先给返回值赋值;接着defer开始执行一些收尾工作;最后RET指令携带返回值退出函数。
控制结构
if
| &&、 | 或 ! |
1 | |
switch
1 | |
for
1 | |
函数
new make 区别
new 和 make 均是用于分配内存:new 用于值类型和用户定义的类型,如自定义结构,
- make 用于内置引用类型(切片、map 和通道)。它们的用法就像是函数,但是将类型作为参数:new(type)、make(type)。
- new(T) 分配类型 T 的零值并返回其地址,也就是指向类型 T 的指针。它也可以被用于基本类型:v := new(int)。
make(T) 返回类型 T 的初始化之后的值,因此它比 new 进行更多的工作。 new() 是一个函数,不要忘记它的括号。二者都是内存的分配(堆上), 但是make只用于slice、map以及channel的初始化(非零值);而new用于类型的内存分配,并且内存置为零。
函数作为参数
1 | |
闭包
1 | |
可变参数
参数列表的最后一个参数类型之前加上省略符号...,这表示该函数会接收任意数量的该类型参数
1 | |
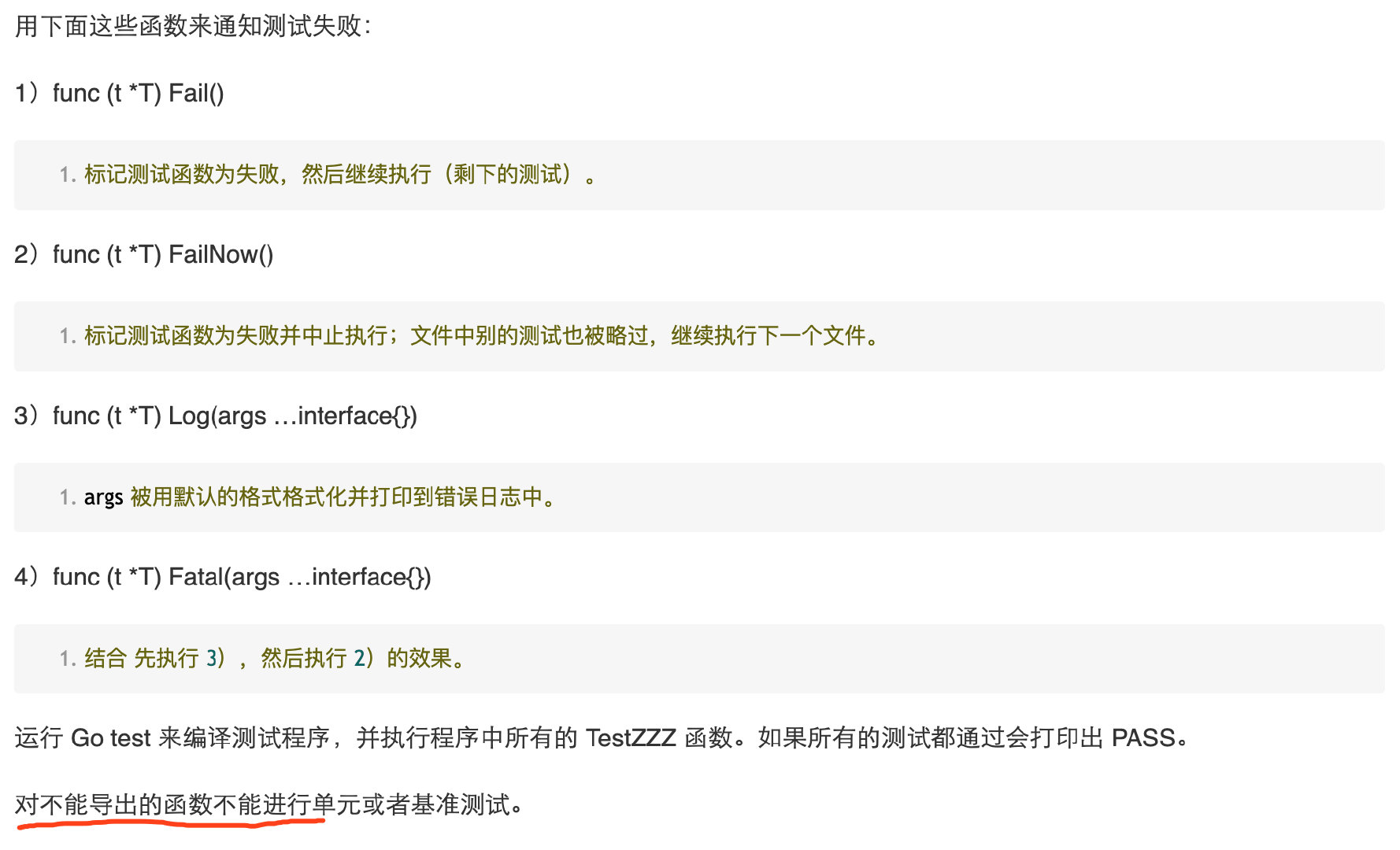
测试
测试程序必须属于被测试的包 文件名 *_test.go 不会被普通的 Go 编译器编译,
所以当放应用部署到生产环境时它们不会被部署;只有 Gotest 会编译所有的程序:普通程序和测试程序
必须导入 testing 包,并写一些名字以 TestZzz 打头的全局函数
1 | |