self attention自注意力机制
可以考虑整个向量序列信息来计算,计算量大 Attention Is All You Need 论文
算法
https://www.youtube.com/watch?v=hYdO9CscNes&list=PLJV_el3uVTsMhtt7_Y6sgTHGHp1Vb2P2J&index=12&ab_channel=Hung-yiLee
-
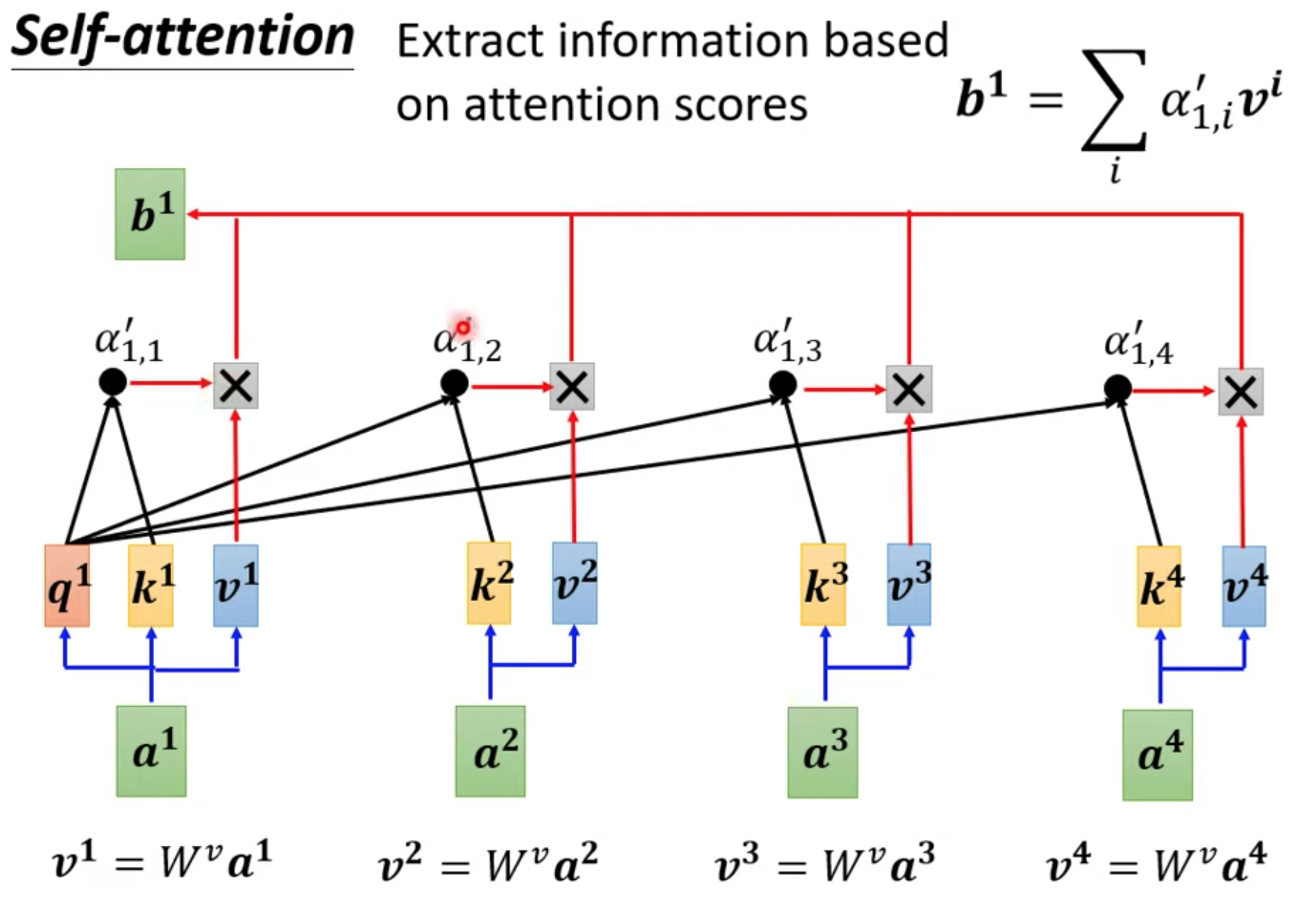
每一个output b,都是考虑所有的a 生成的
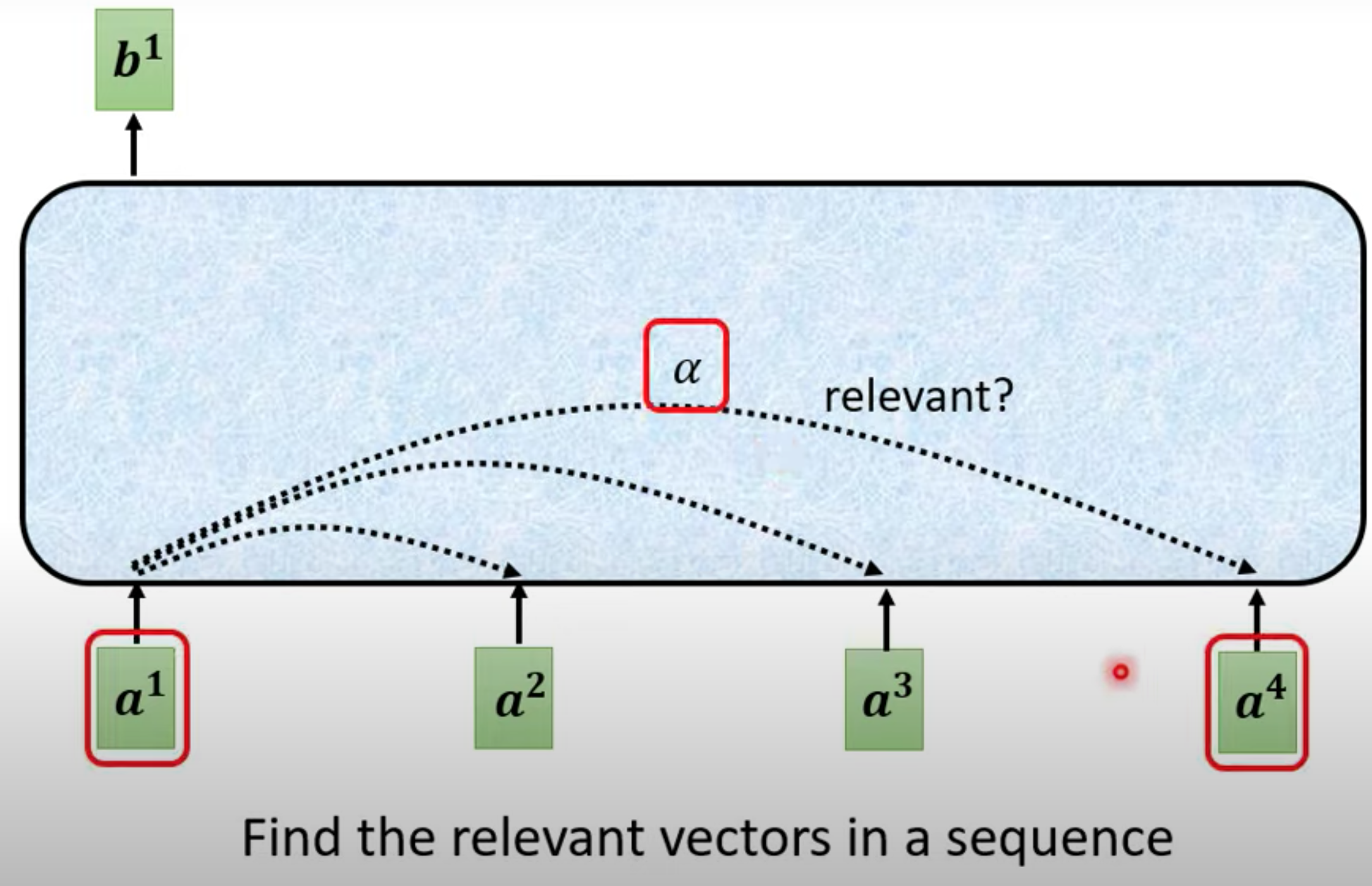
-
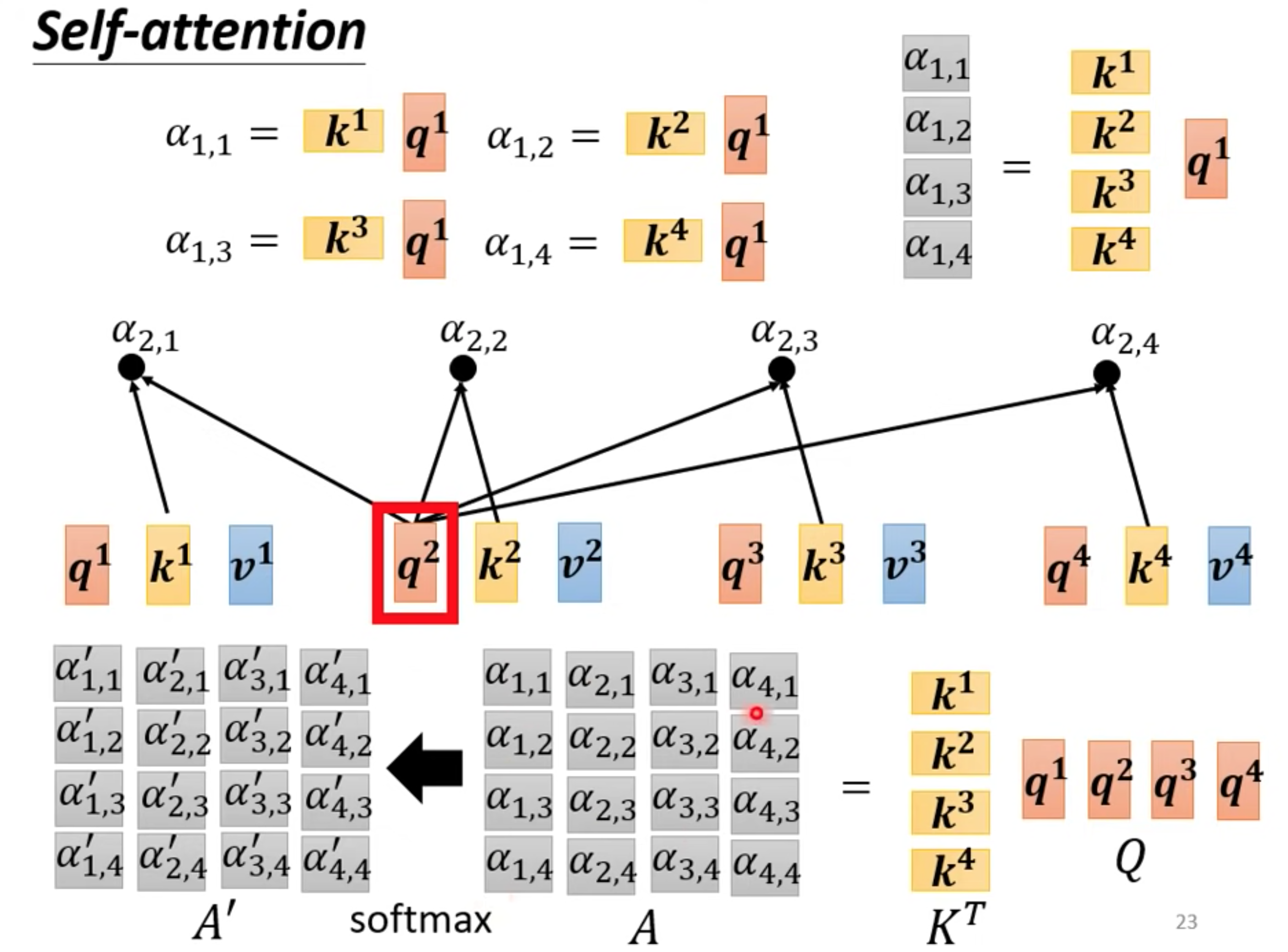
计算和a1最相关的向量,相关度由alpha表示,计算alpha的方法有很多
向量$\vec{a}=[a_{1},a_{2},\cdot\cdot\cdot,a_{n}]$和向量${\vec{b}}=[b_{1},b_{2},\cdot\cdot,b_{n}]$ 內積定義
$\vec{a}\cdot\vec{b}=\sum_{i=1}^{n}a_{i}b_{i}=a_{1}b_{1}+a_{2}b_{2}+\cdot\cdot\cdot+a_{n}b_{n}$
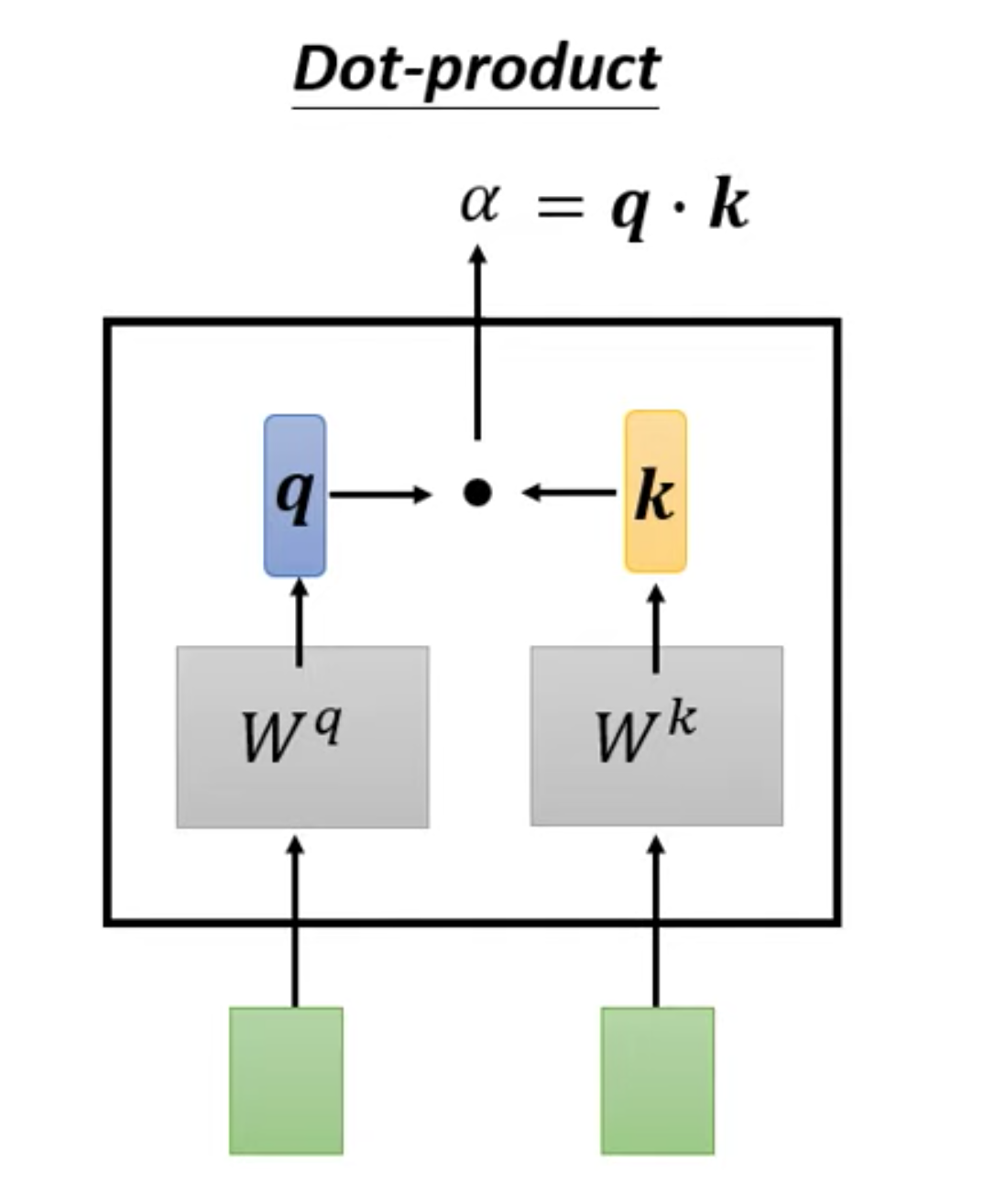
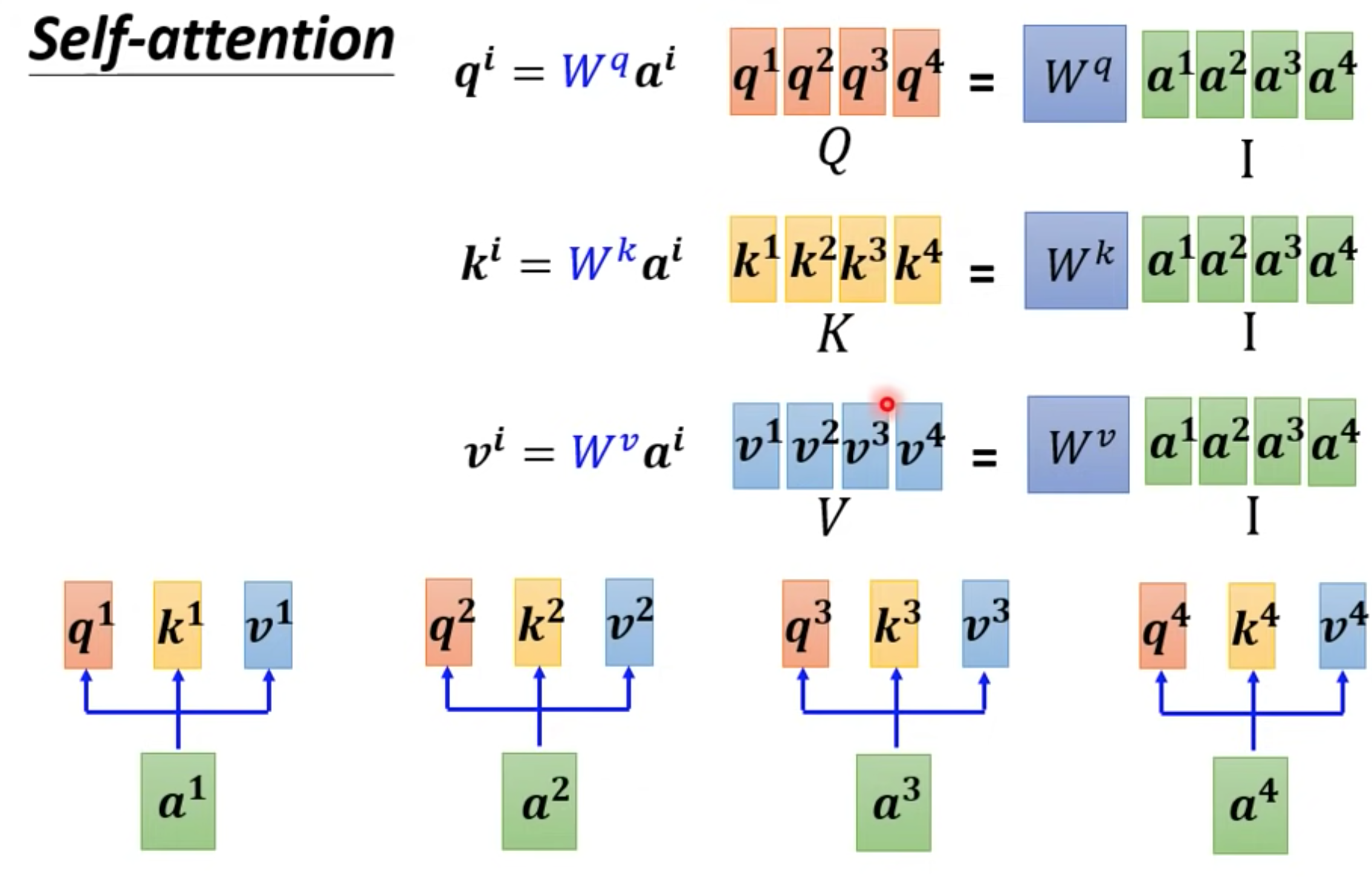
向量分别乘以对应不同的矩阵,得到q,k向量,再内积
-
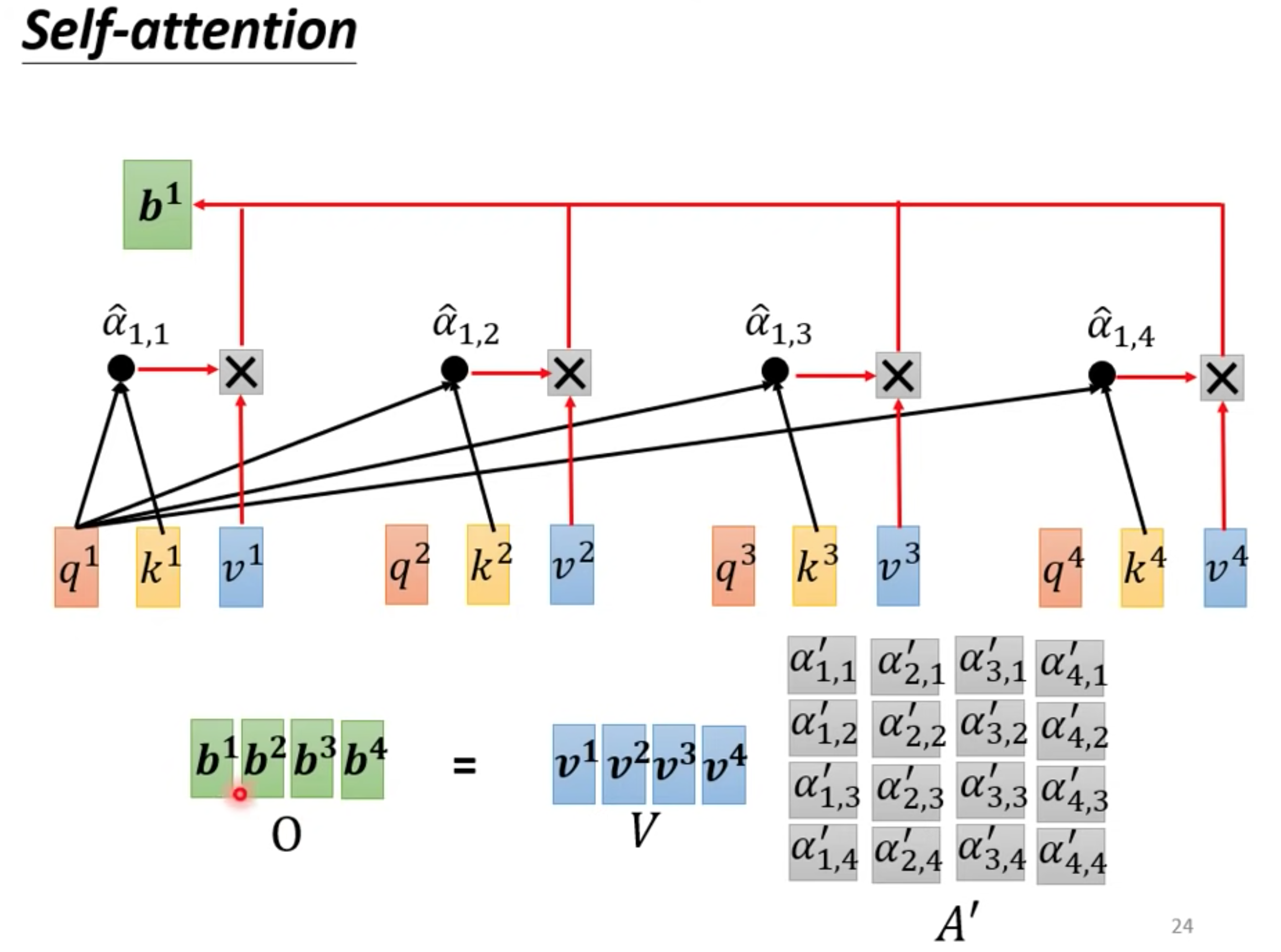
通过关联性计算output b
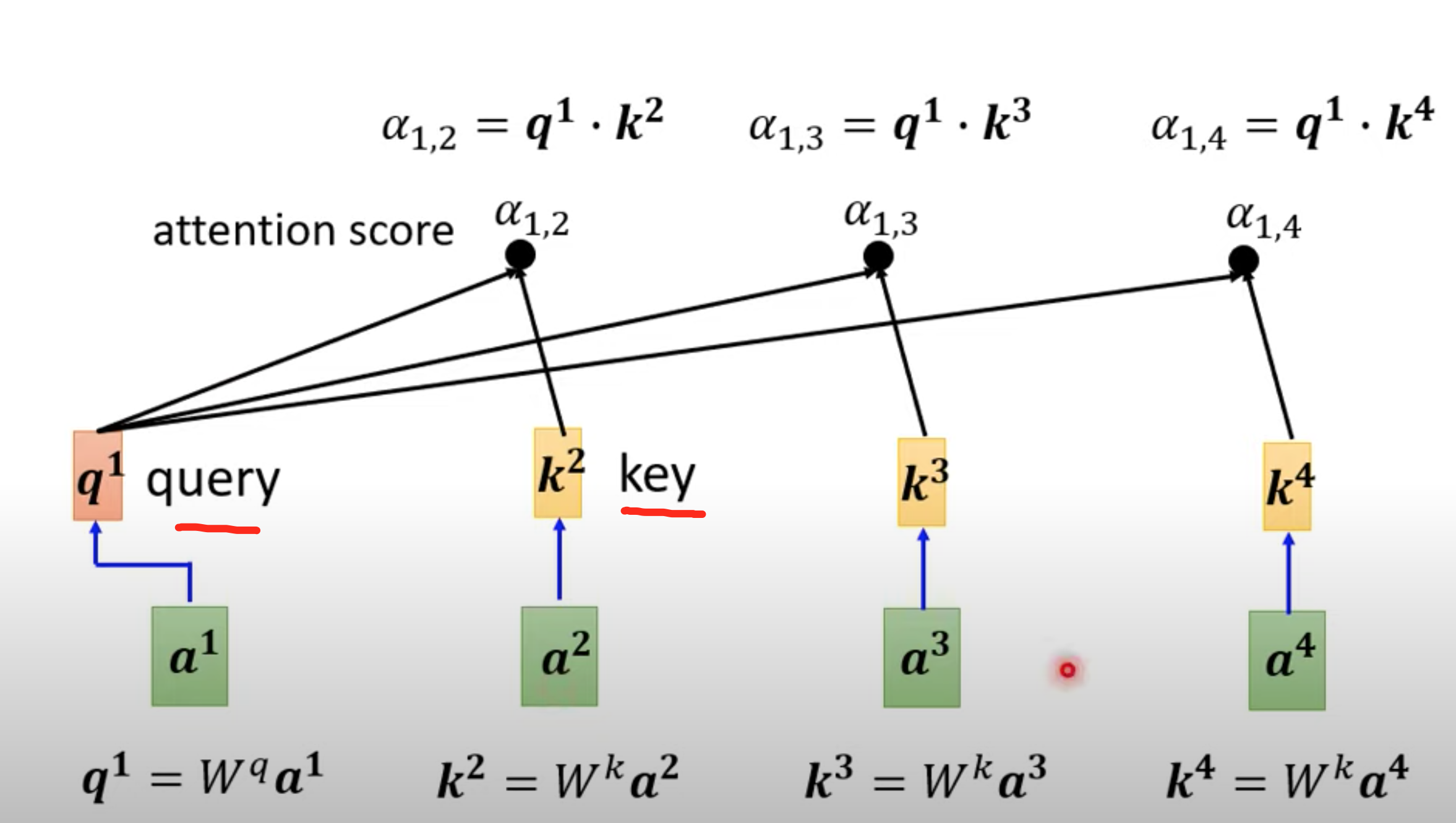
不一定是soft-max,做一个归一化处理。
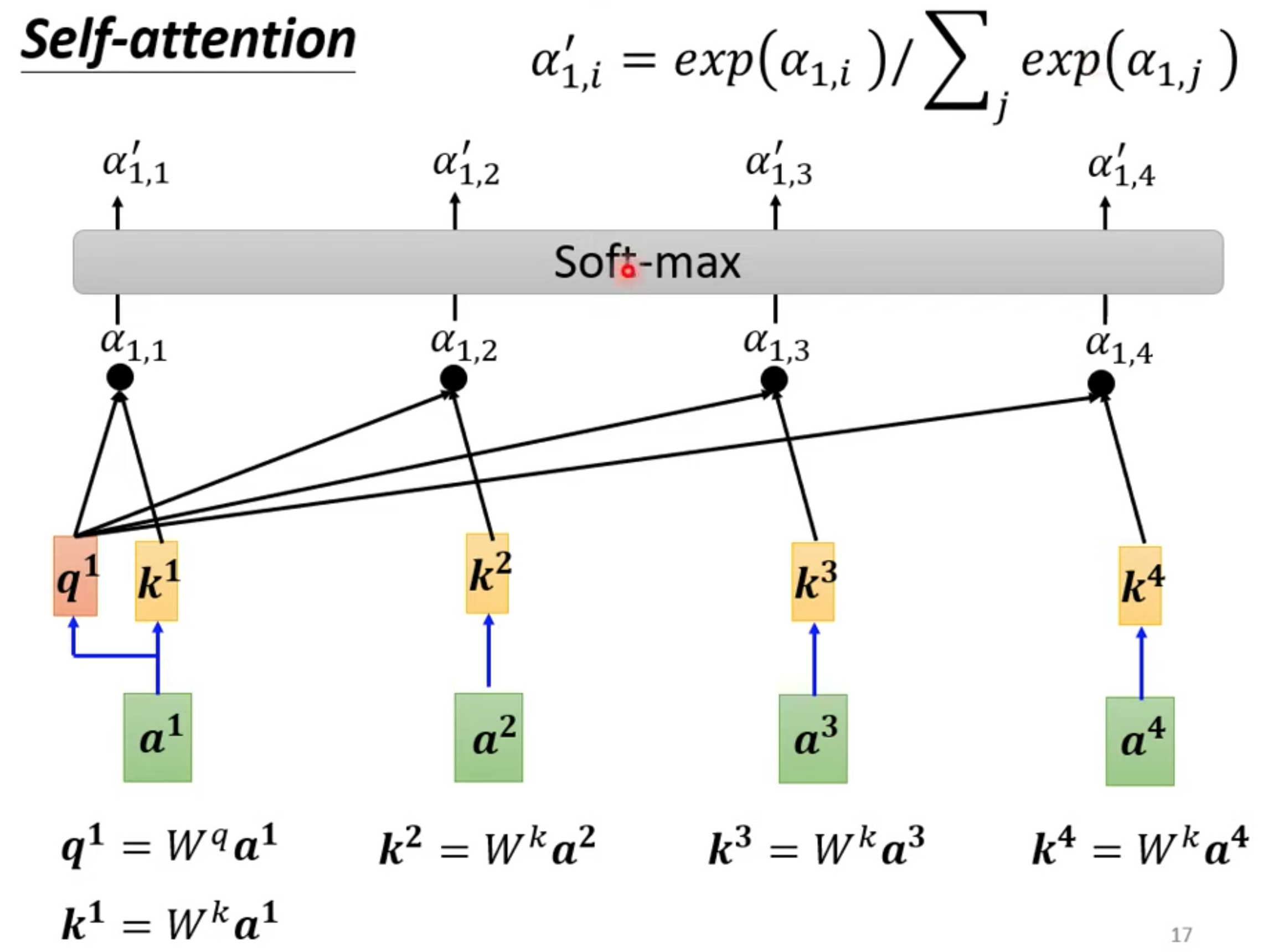
b1 到b4是并行产生的
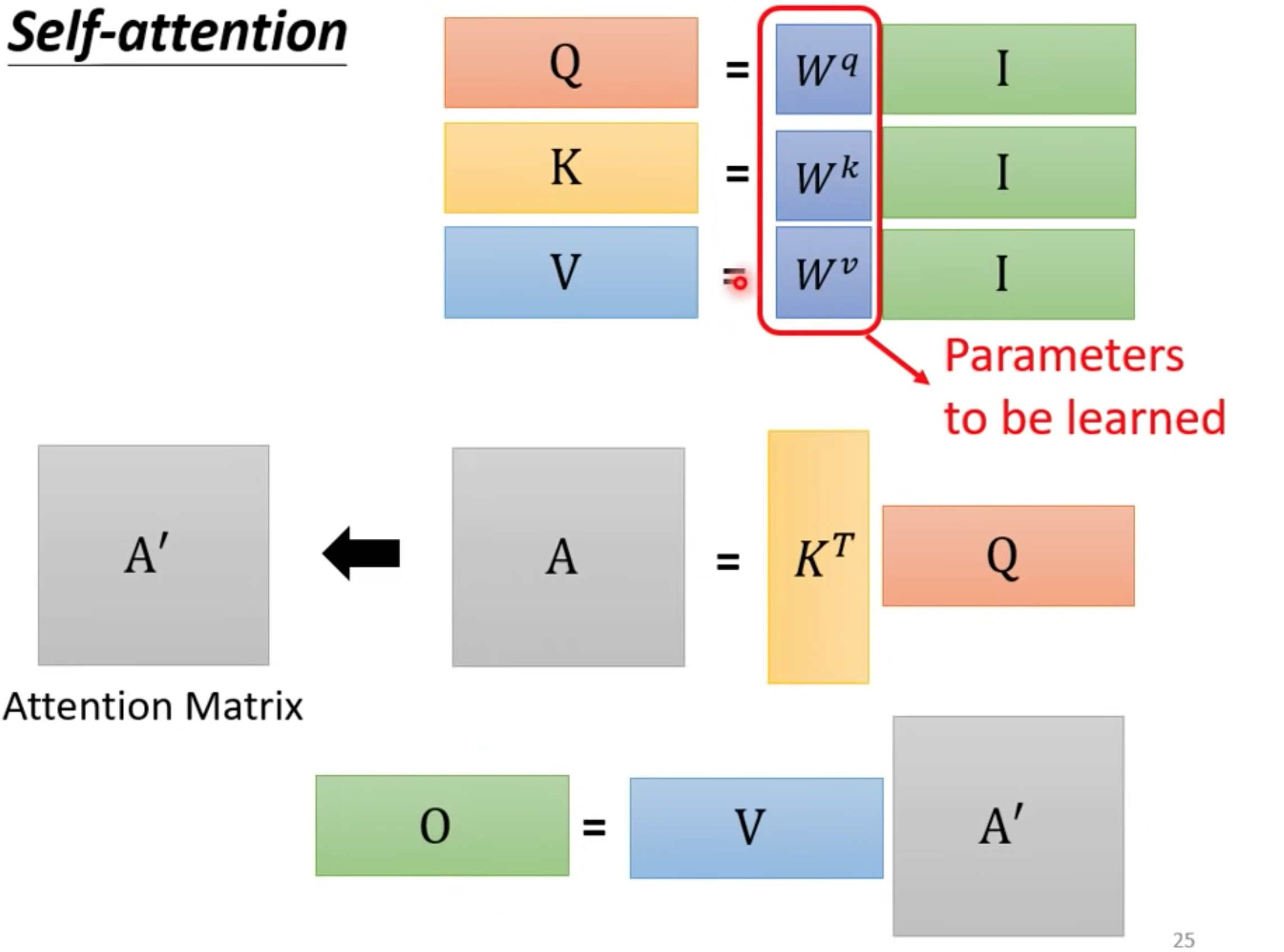
矩阵算法
可以把所有向量a 看成是一个矩阵I,得到QKV矩阵
获取alpha
获取ouput
模型需要训练QKV
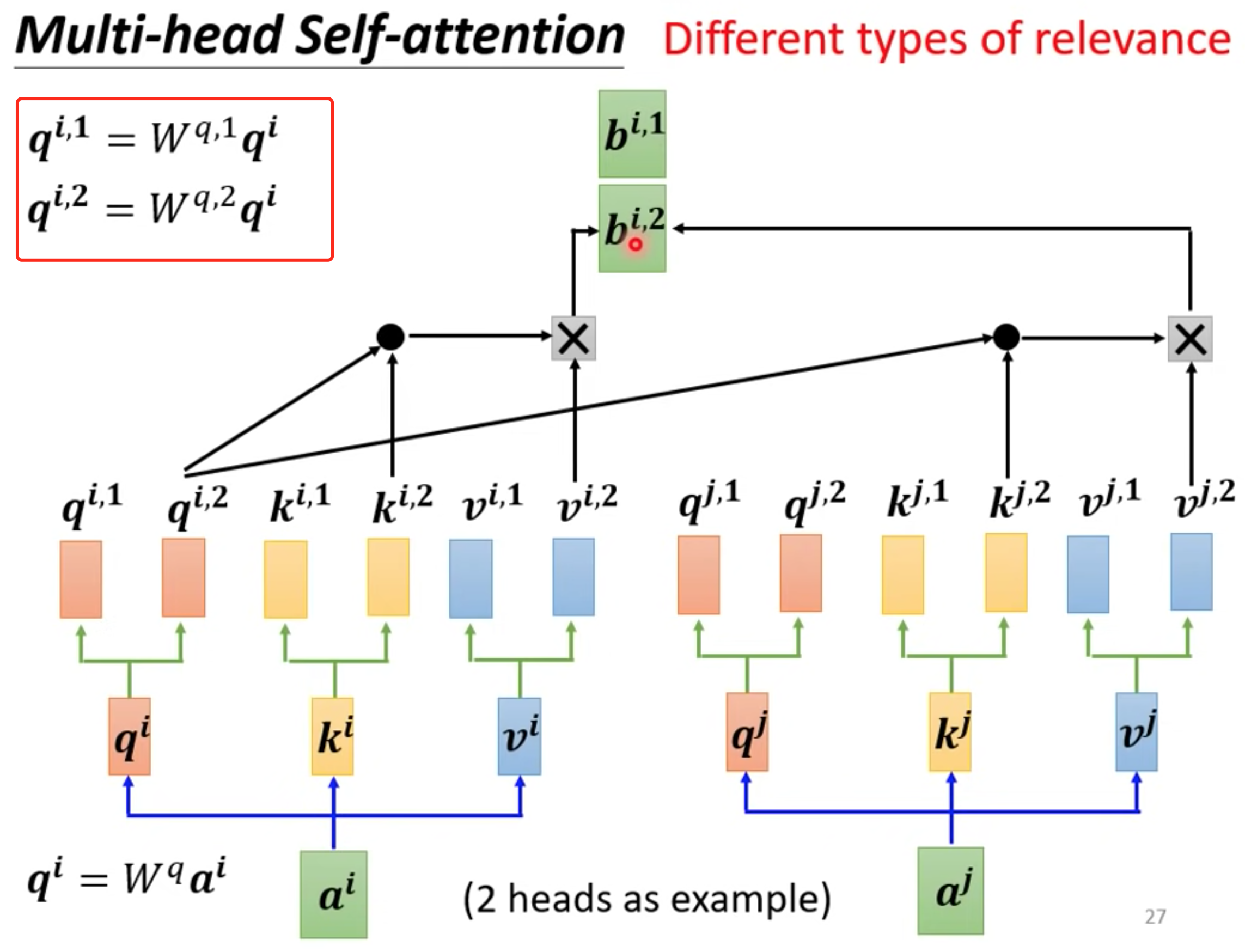
multi-head
一个q代表一种相关性,需要多种就要多个q,超参数
q 分别乘以不同矩阵得到不同的q,独立计算就行和one head一样
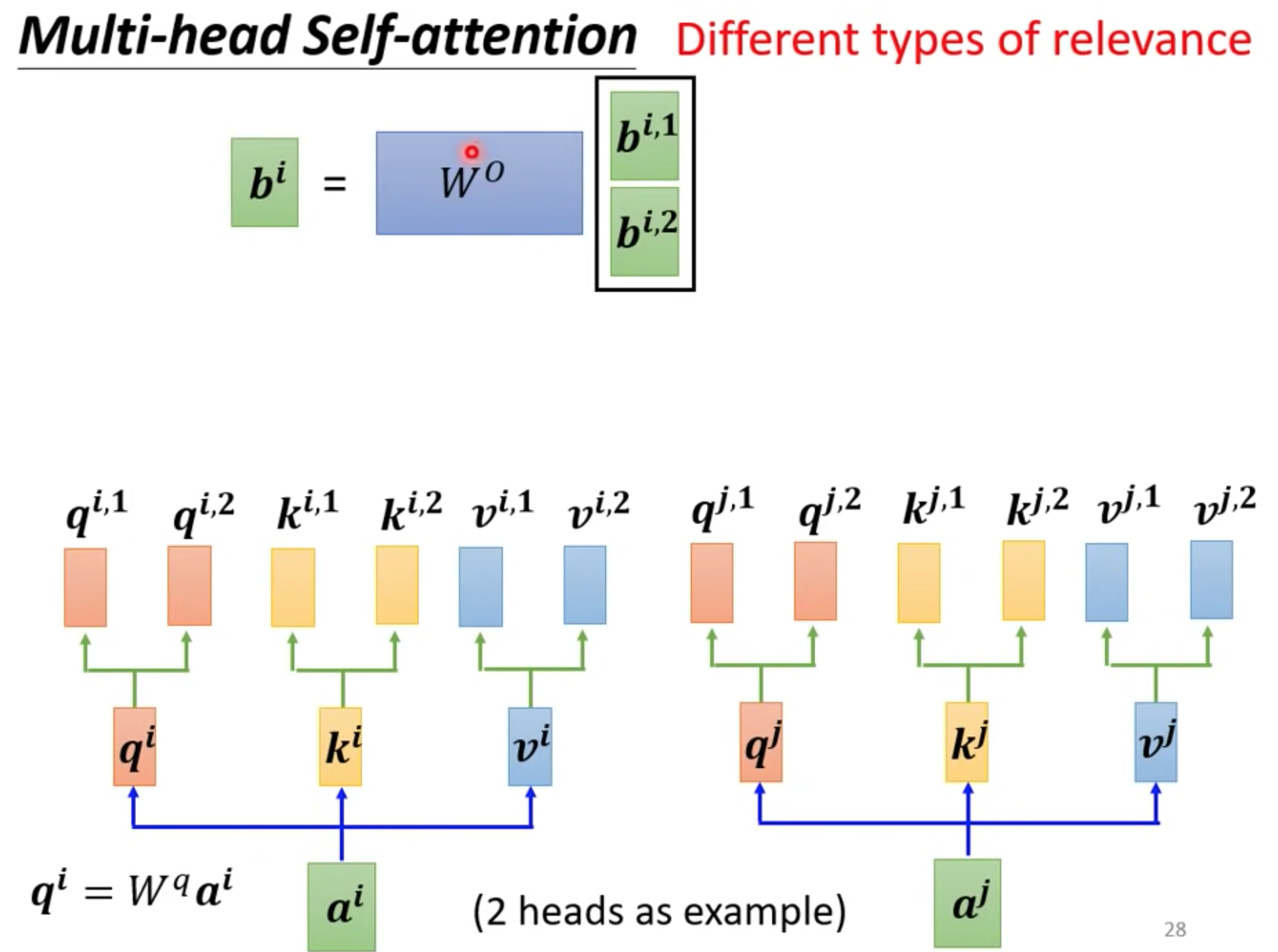
等到output
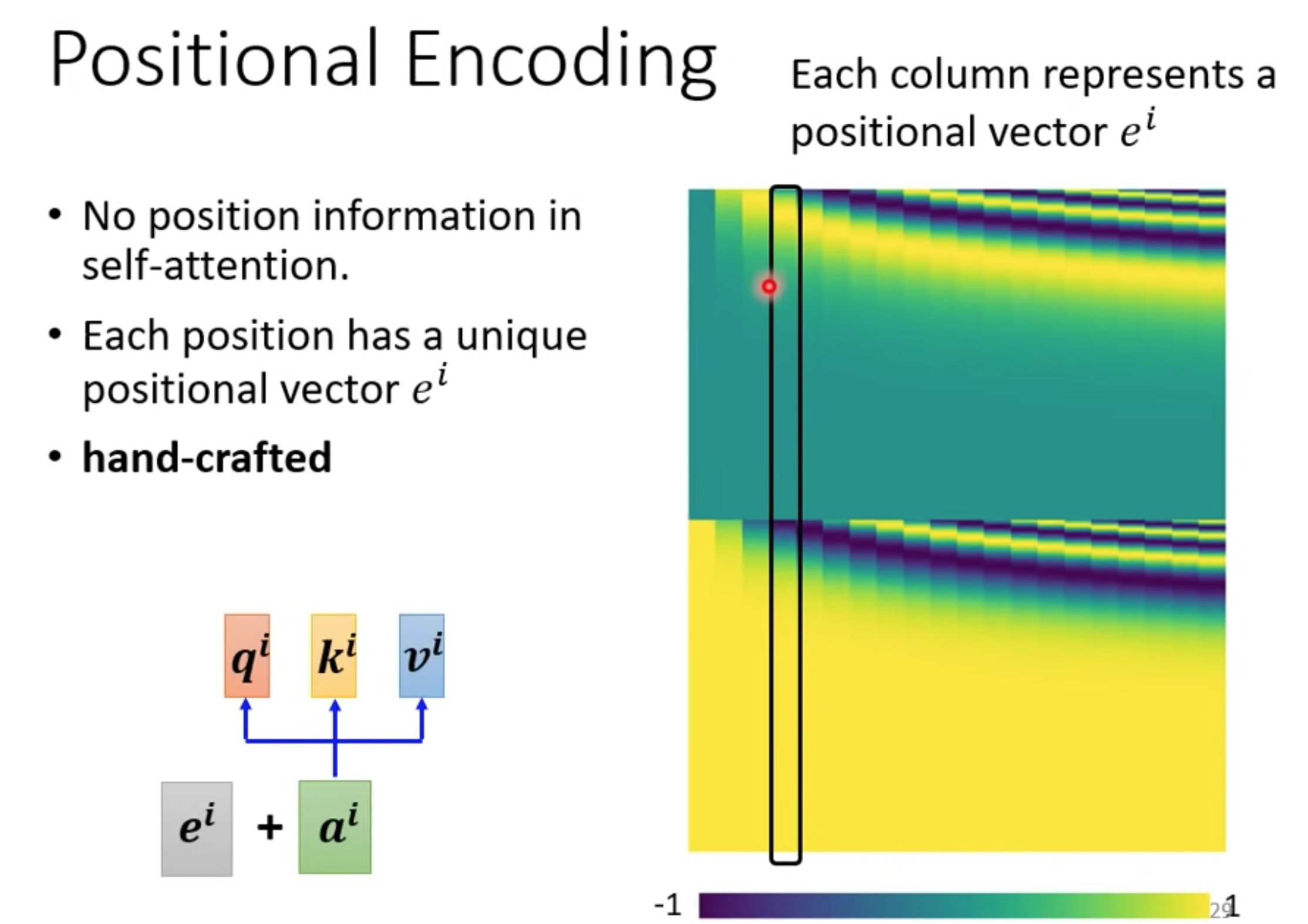
位置信息
self-attention没有位置信息,可以用
与CNN RNN对比
CNN
self-attention是更复杂的CNN

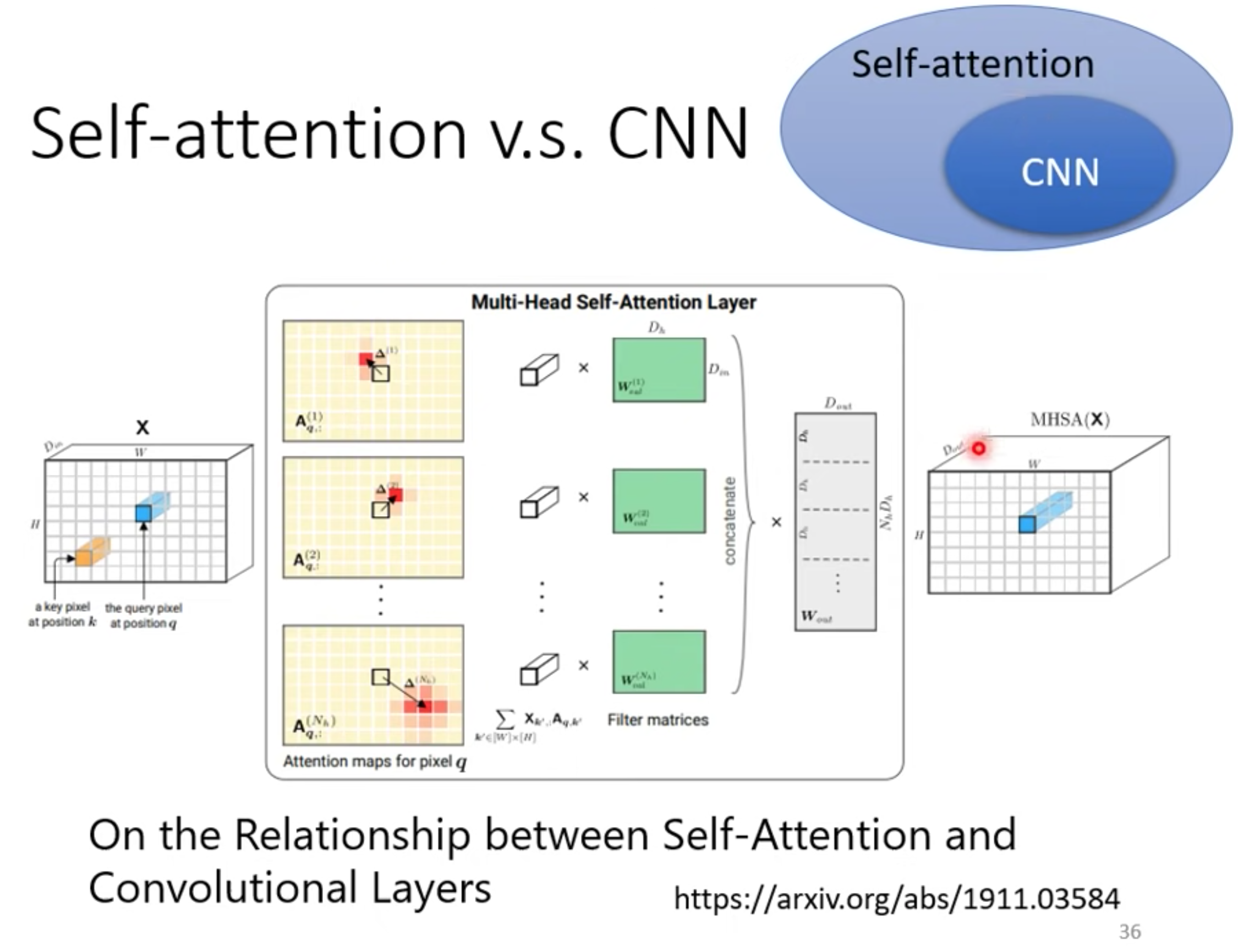
RNN
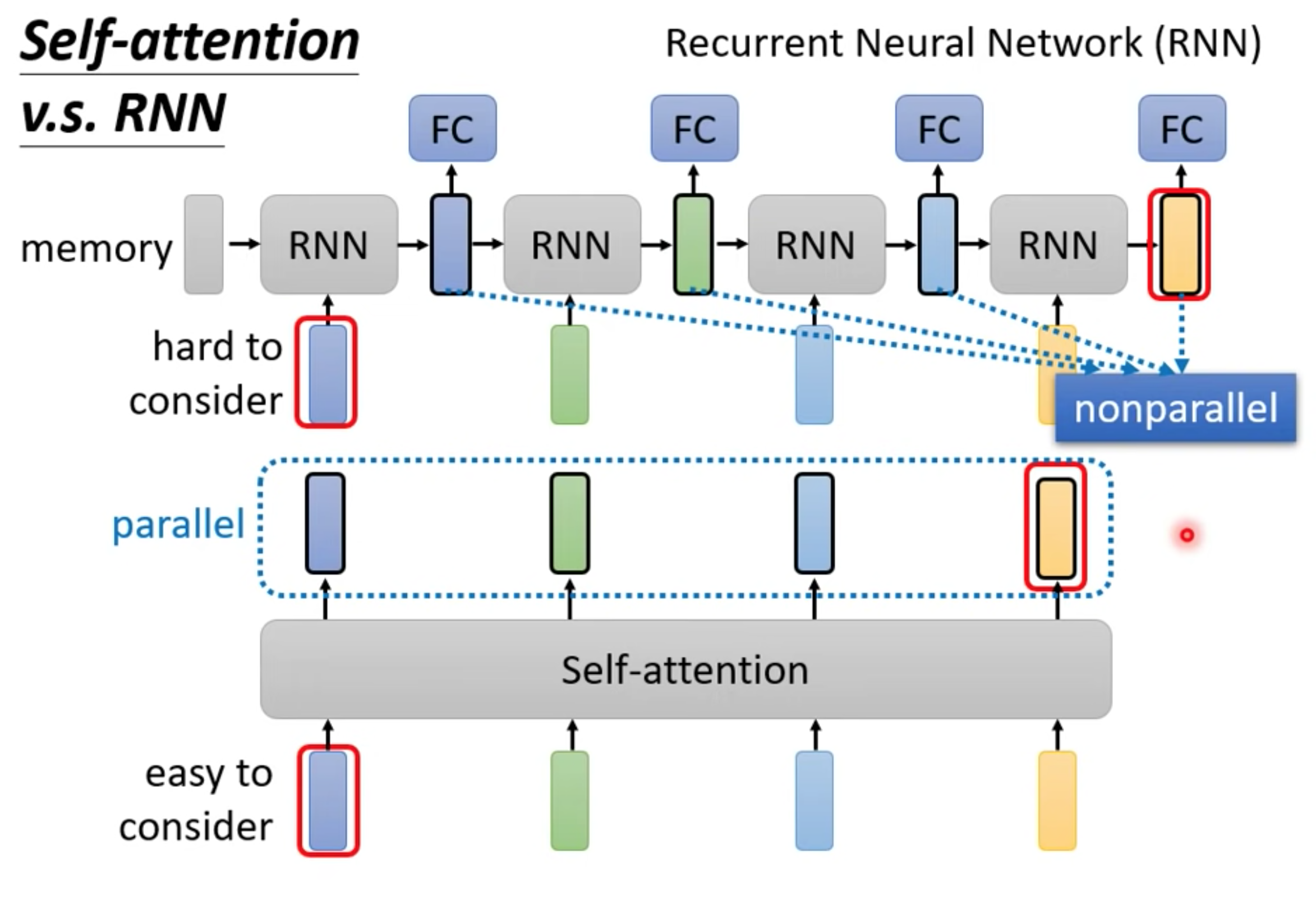
主要两个不同
- 单向RNN只能考虑最先输入的向量,而不是整个句子。双向RNN,最右边的黄色output,很容易忘记最左边的蓝色input。但是self-attention可以通过QK联系起来。
- self-attention可以并行计算,RNN只能等上一个向量处理完后的输出才作为下一个的输入,不能并行计算。
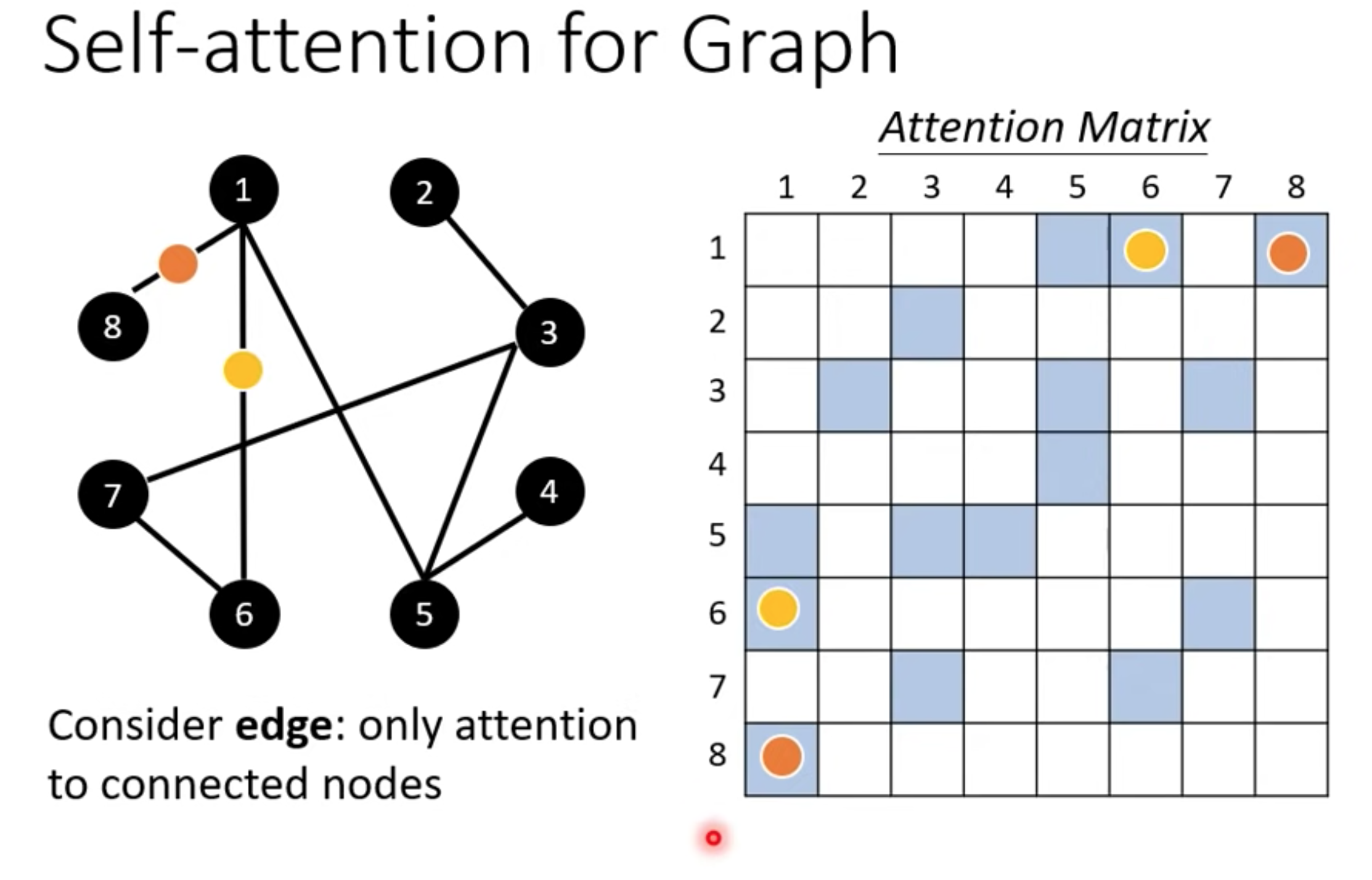
图GNN
图的节点也可以当成向量,计算alpha矩阵时候可以只计算有边连接的节点
Transformer
seq2seq,output的长度由model决定。通常有两步份组成。 encoder , decoder
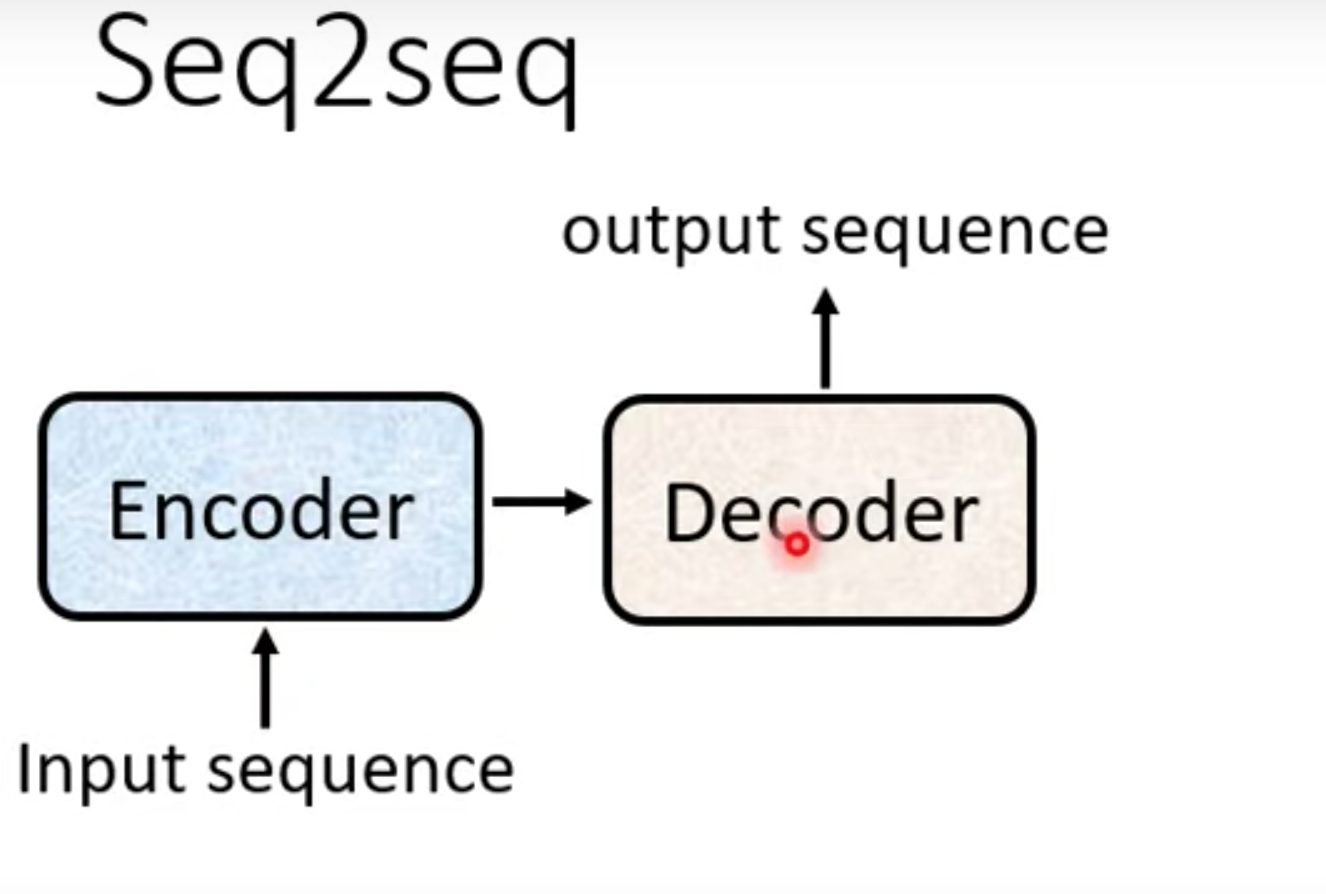
Encoder 原始结构
x是输入,h是输出,每个block,由不同layer构成。
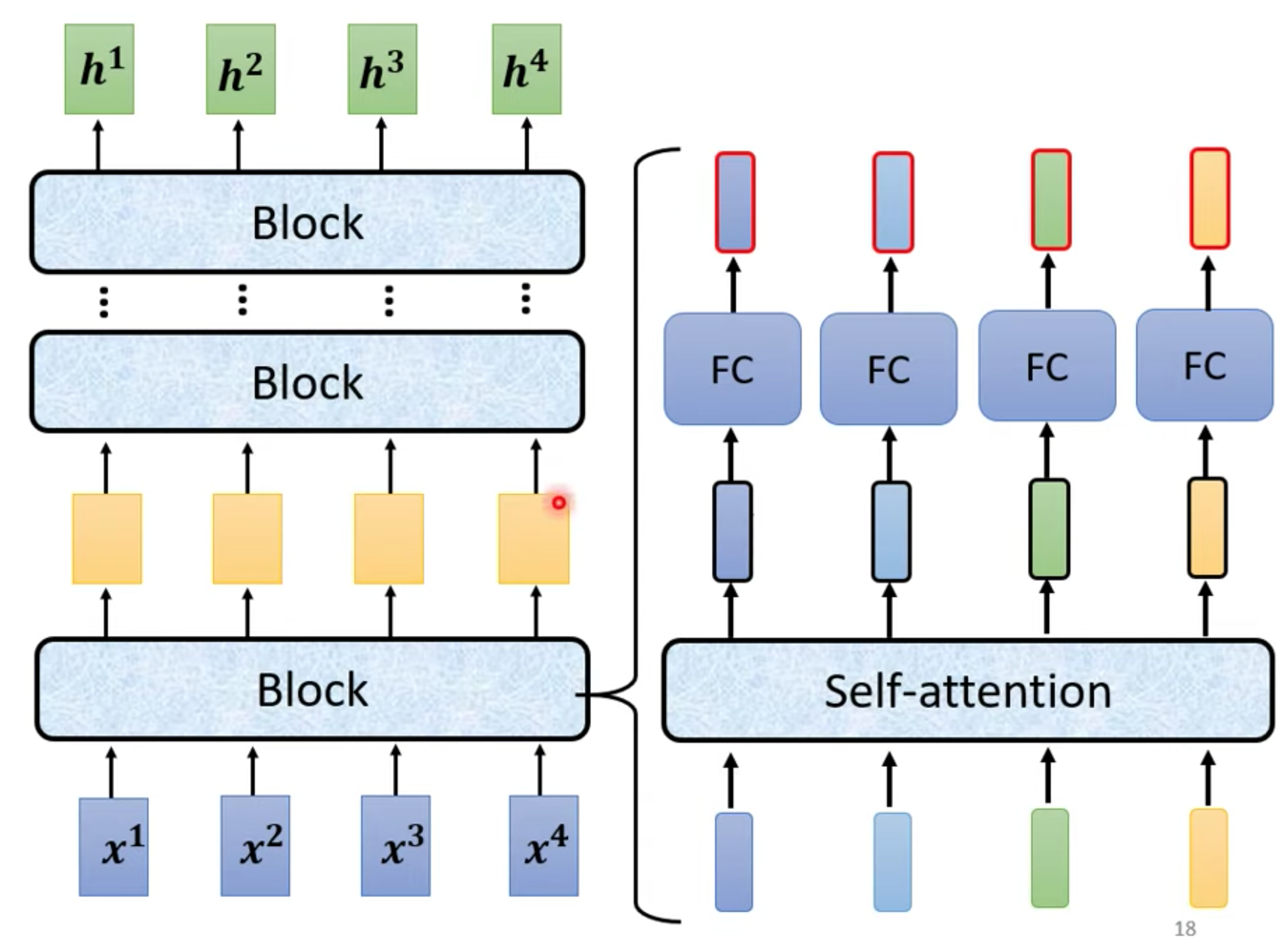
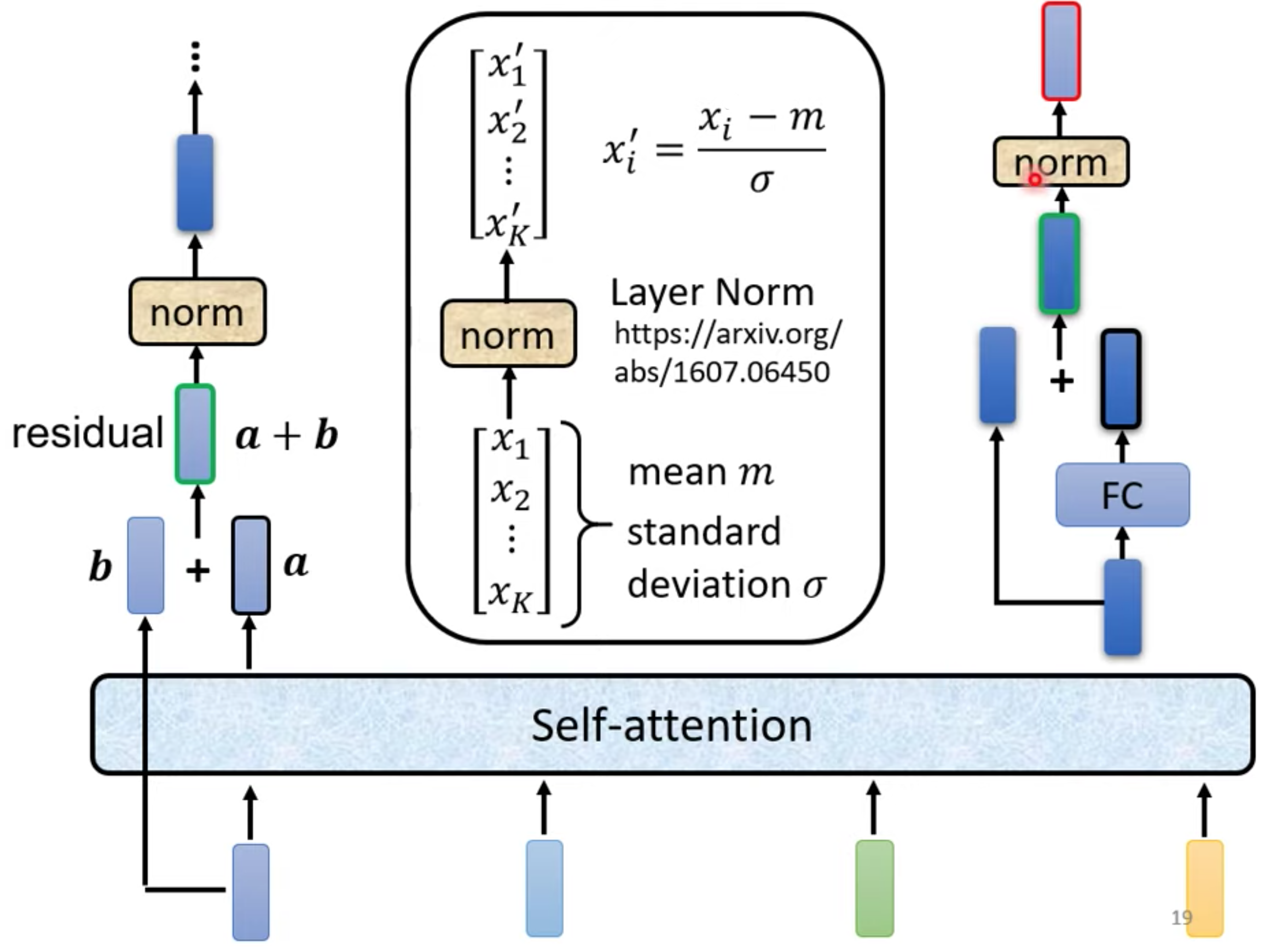
Transformer使用不同的方法,block详解。使用residual(input + output 作为下一层input) + layer norm
FC是Fully Connected Neural Network 全连接神经网络 也叫前馈神经网络(Feedforward Neural Network,FFN)
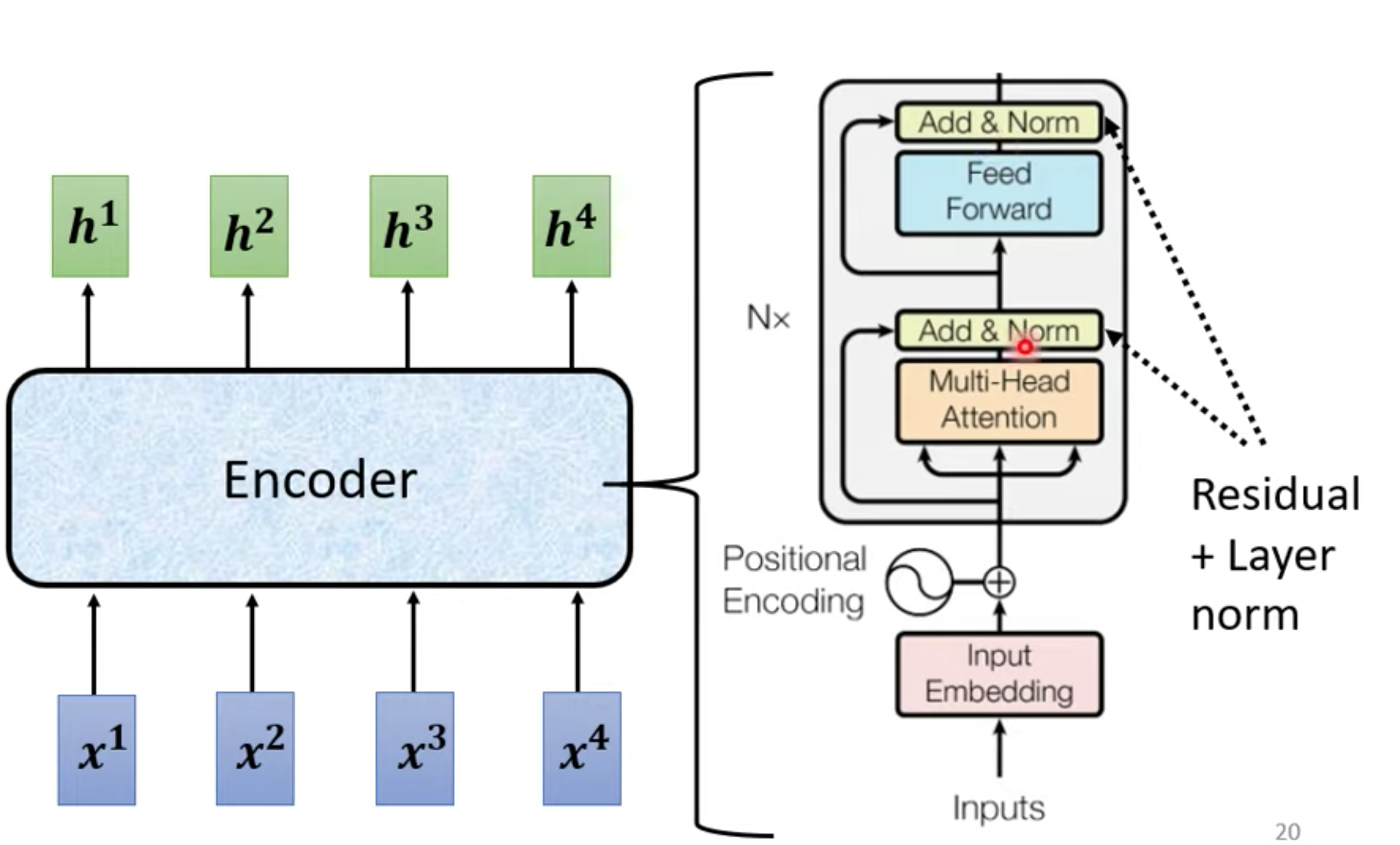
完整Transformer encode, 使用 block 会重复N遍
Decoder
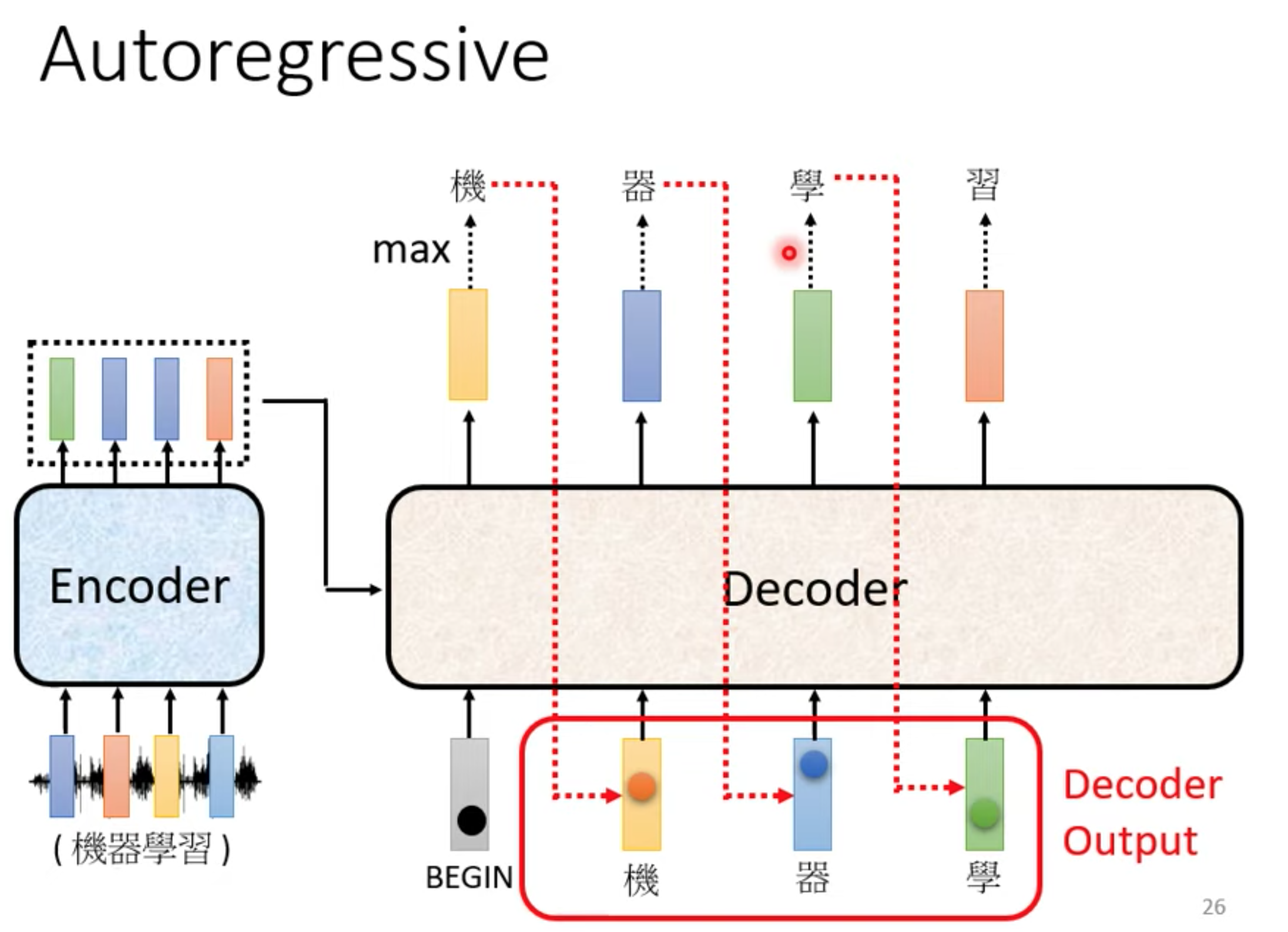
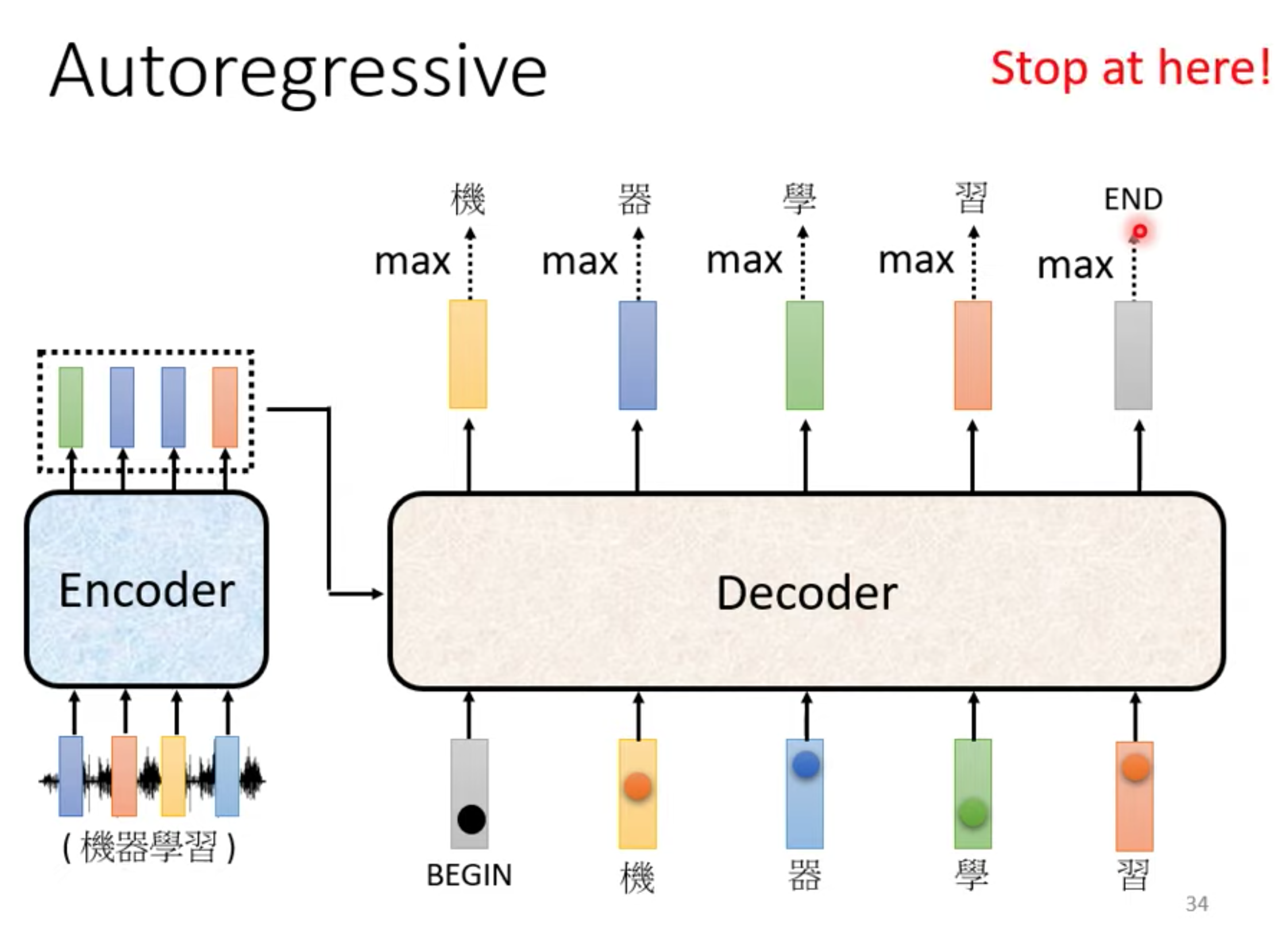
autoregressive
先忽略encoder input
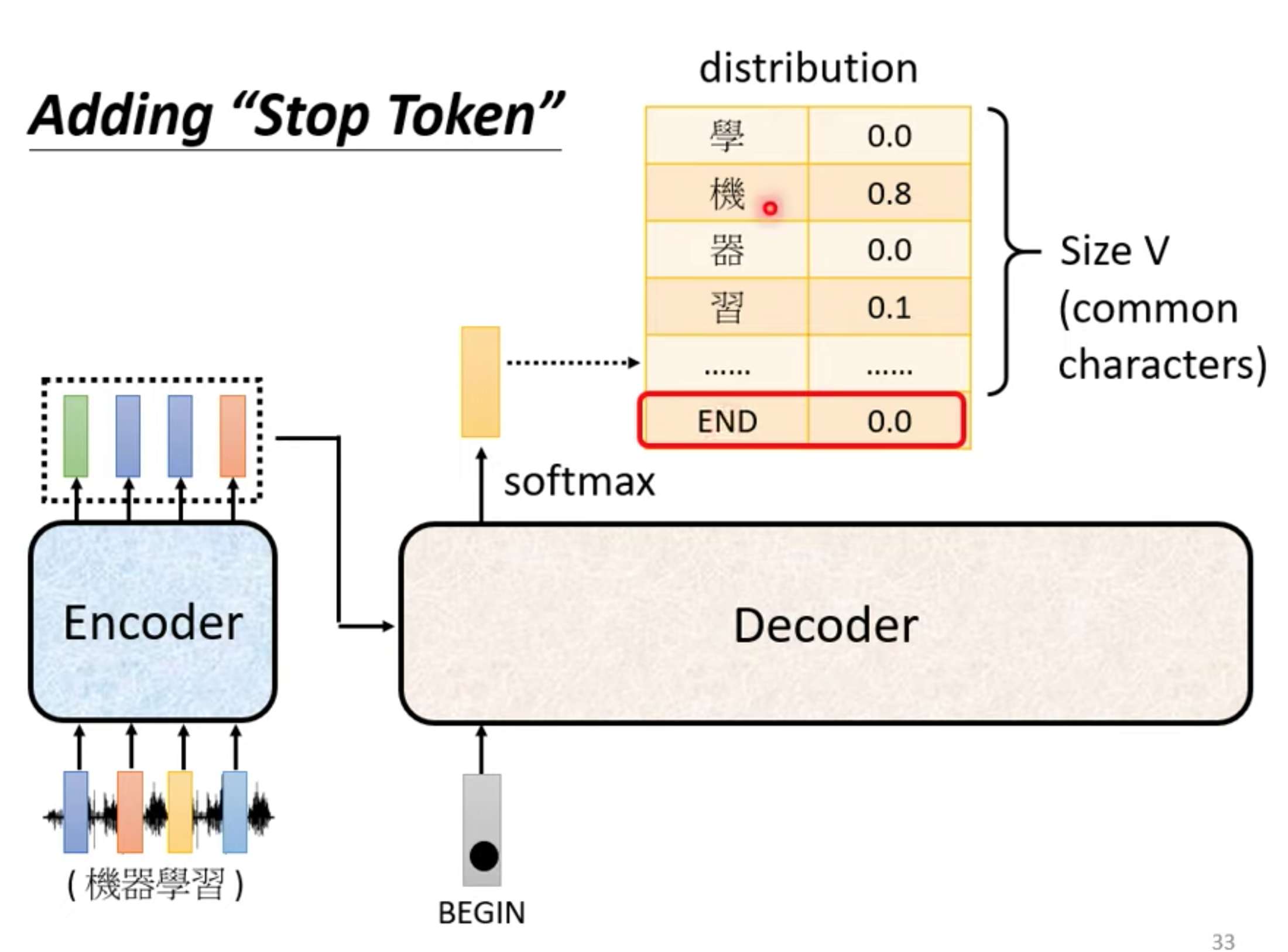
在encoder输出里面加一个BOS(begin special token) , 输出常见字表,取softamx后的最大值的那个字。
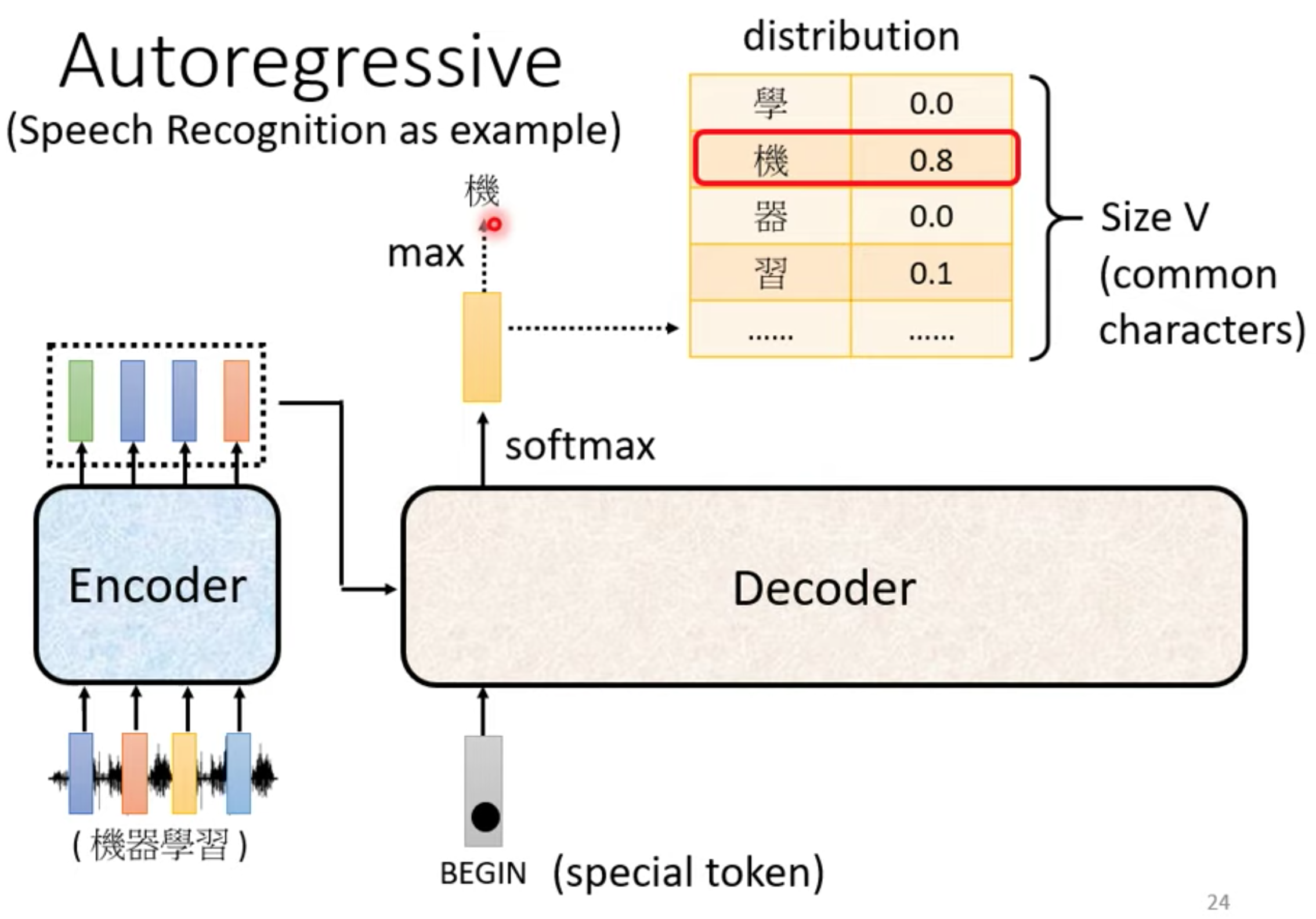
这个字作为下一个输入
decoder大概结构,与encoder非常相似,但是decoder 多了一个Masked multi-head self-attention
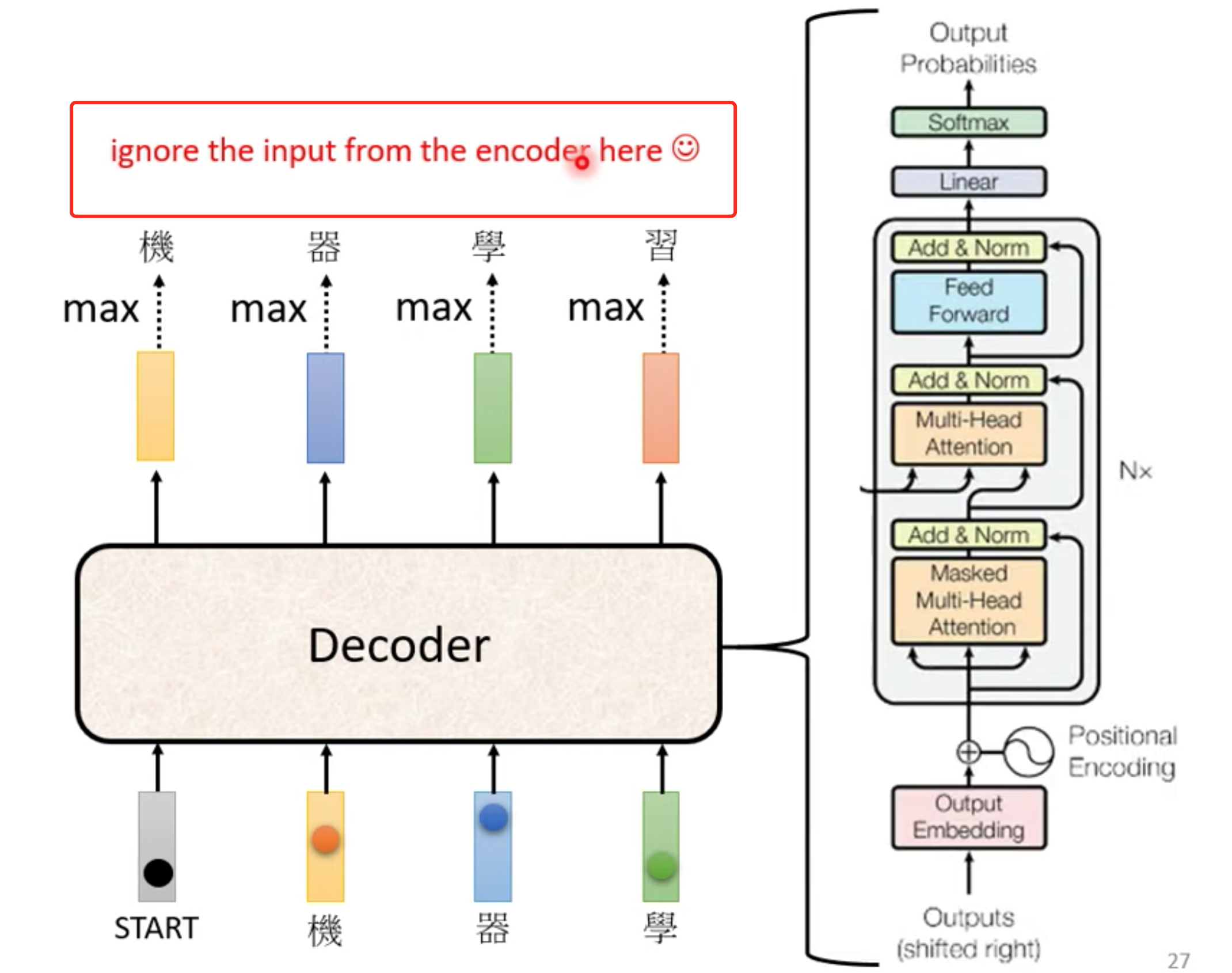
Masked multi-head self-attention
一般的self-attention生成b,要考虑整个seq的信息。
但是masked 只考虑比它前的向量信息(生成b3,只考虑a1~a3)
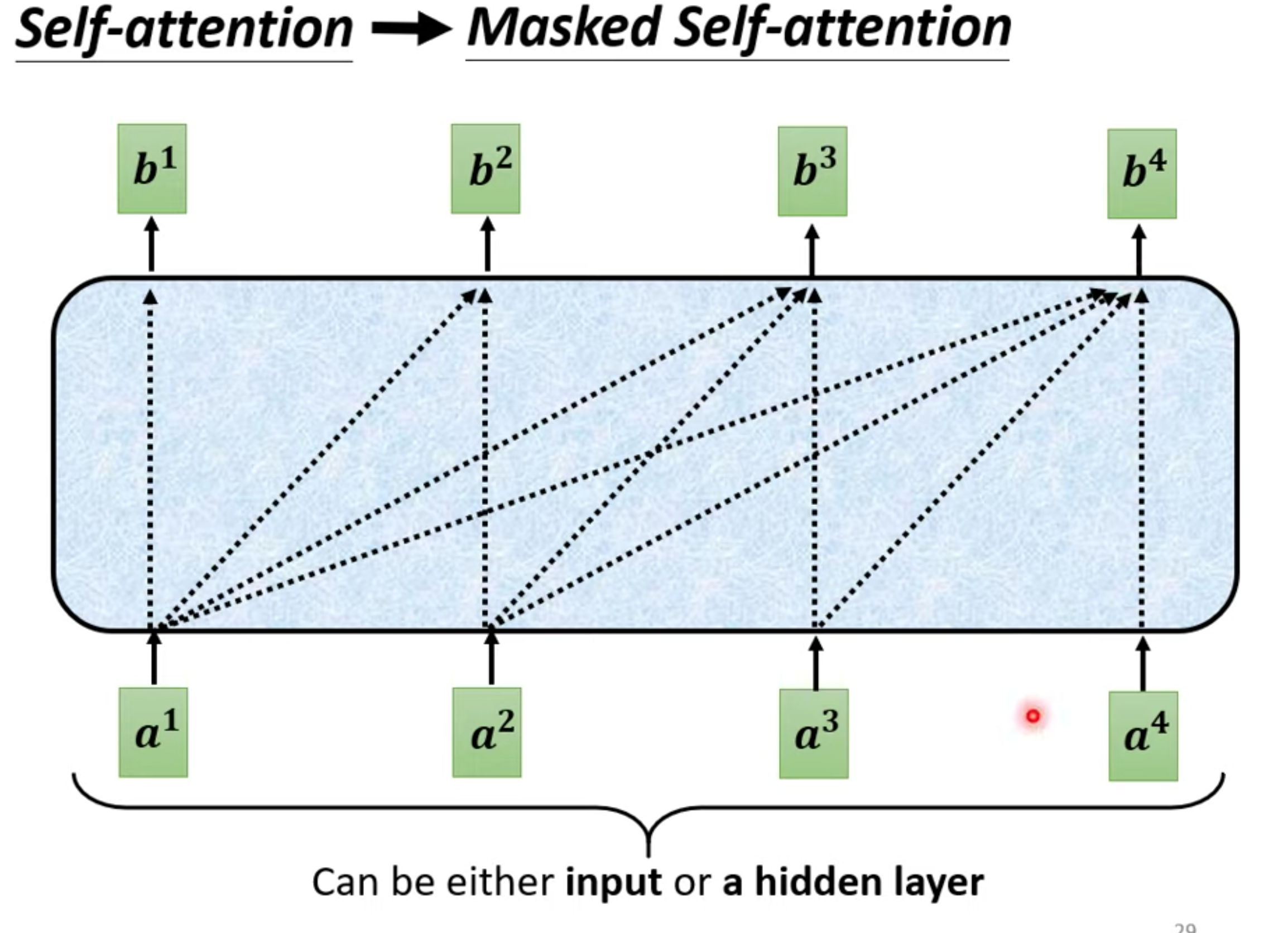
Why Masked : 因为decoder的input决定这样,输入也是一个个进来,不可能考虑到后面的向量。
decoder 什么时候停
output seq 长度由model自己决定。 在vocabulary 加入stop token , 和begin token一样不一样都可以。
Non autoregressive
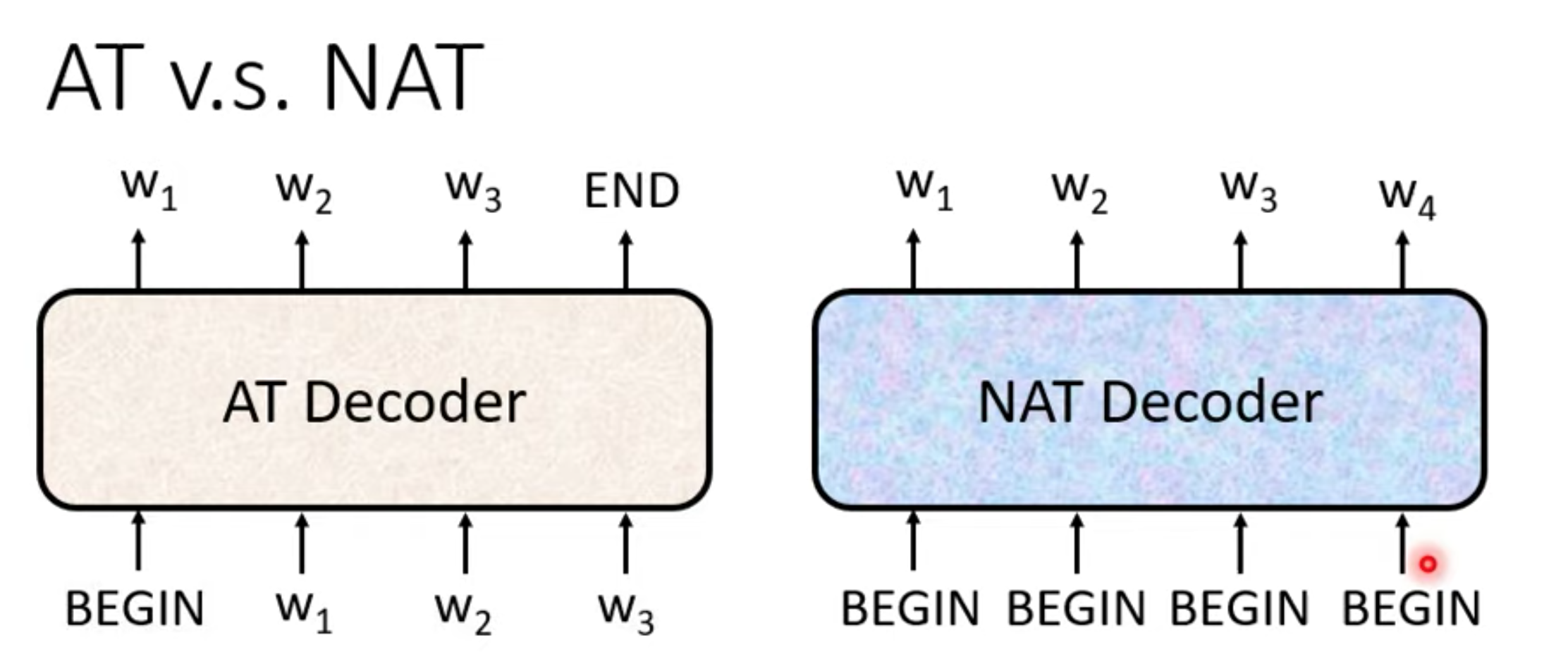
NAT input一堆begin,output整句输出。
when stop,(output 长度)
- 需要另外一个predictor预测
- 直接输出一个很长的output,出现stop token就忽略的output token
优点:
- 生成速度快比AT,可以output可以并行生成
- 可以很好控制输出长度
缺点
- 没有AT的表现好(why multi-modality)
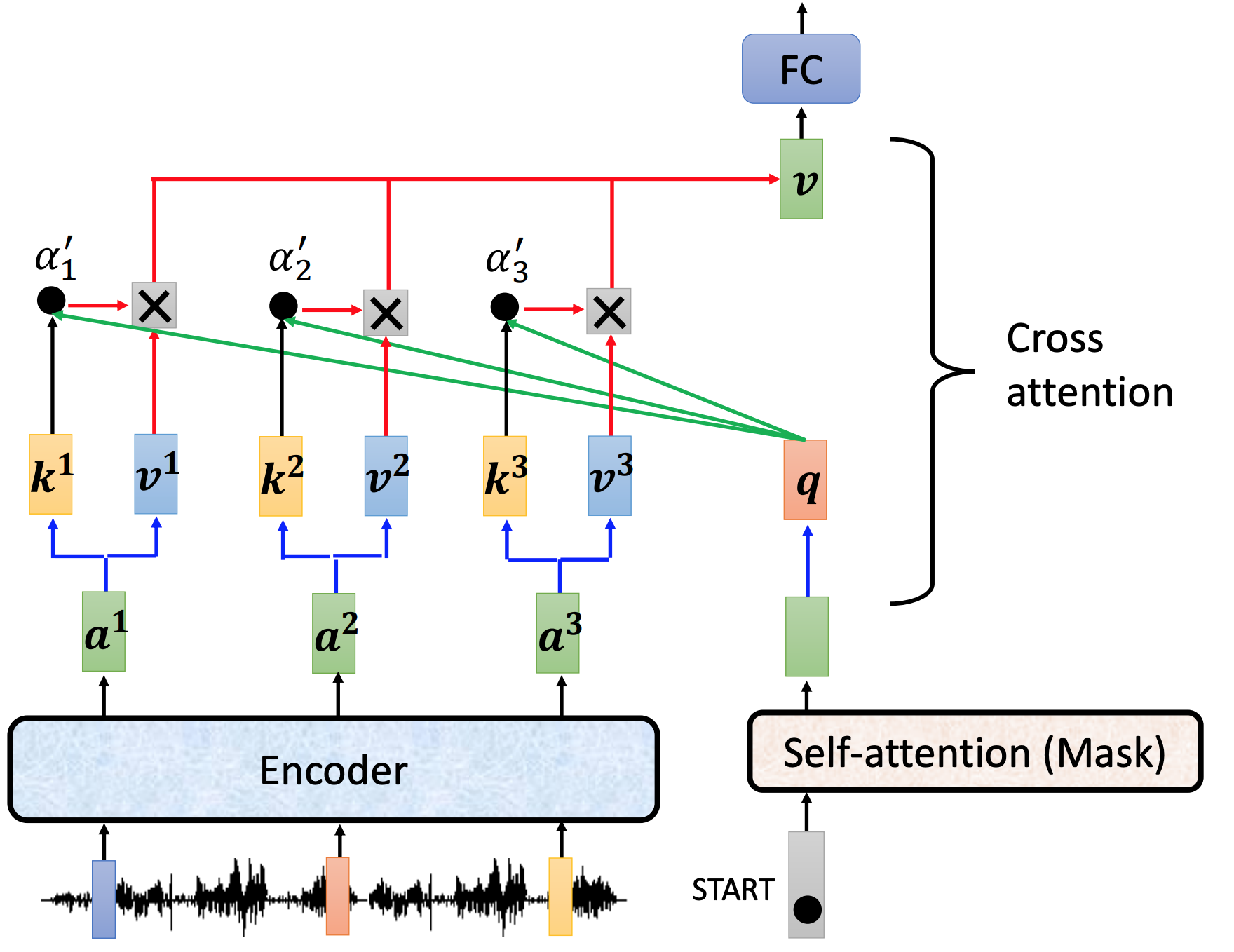
Transformer的endcoder和decoder结合 cross attention
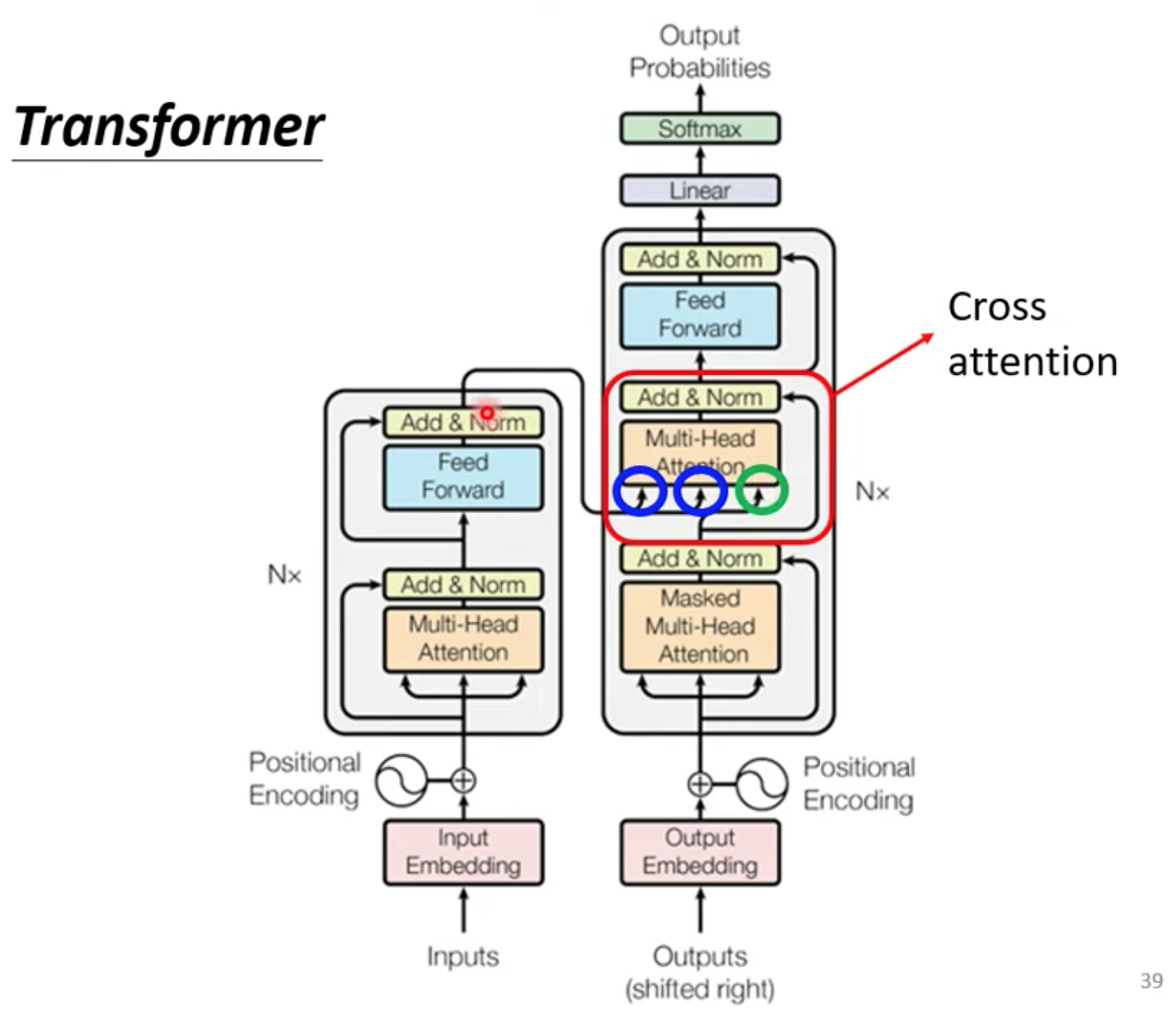
cross attention 做了什么。用endoder的output和mask的output,计算出来的V作为下一层(FC层)的input
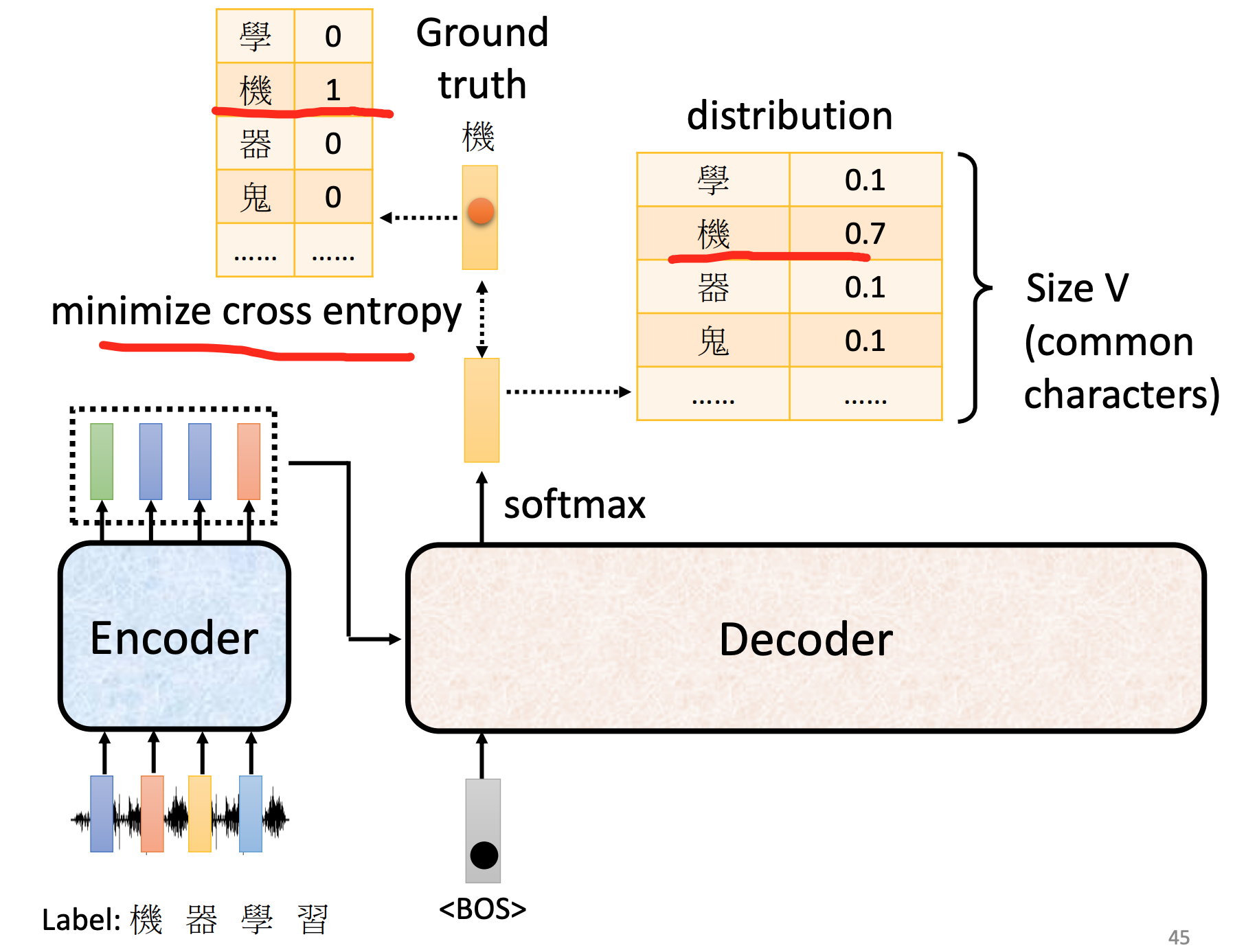
train loss
每次decoder的output,都是对vocabulary(词汇表)的一次分类问题
每一个output,都要和其正确答案(vocabulary one-hot vector)进行cross entropy ,所有的cross entropy总和最小。
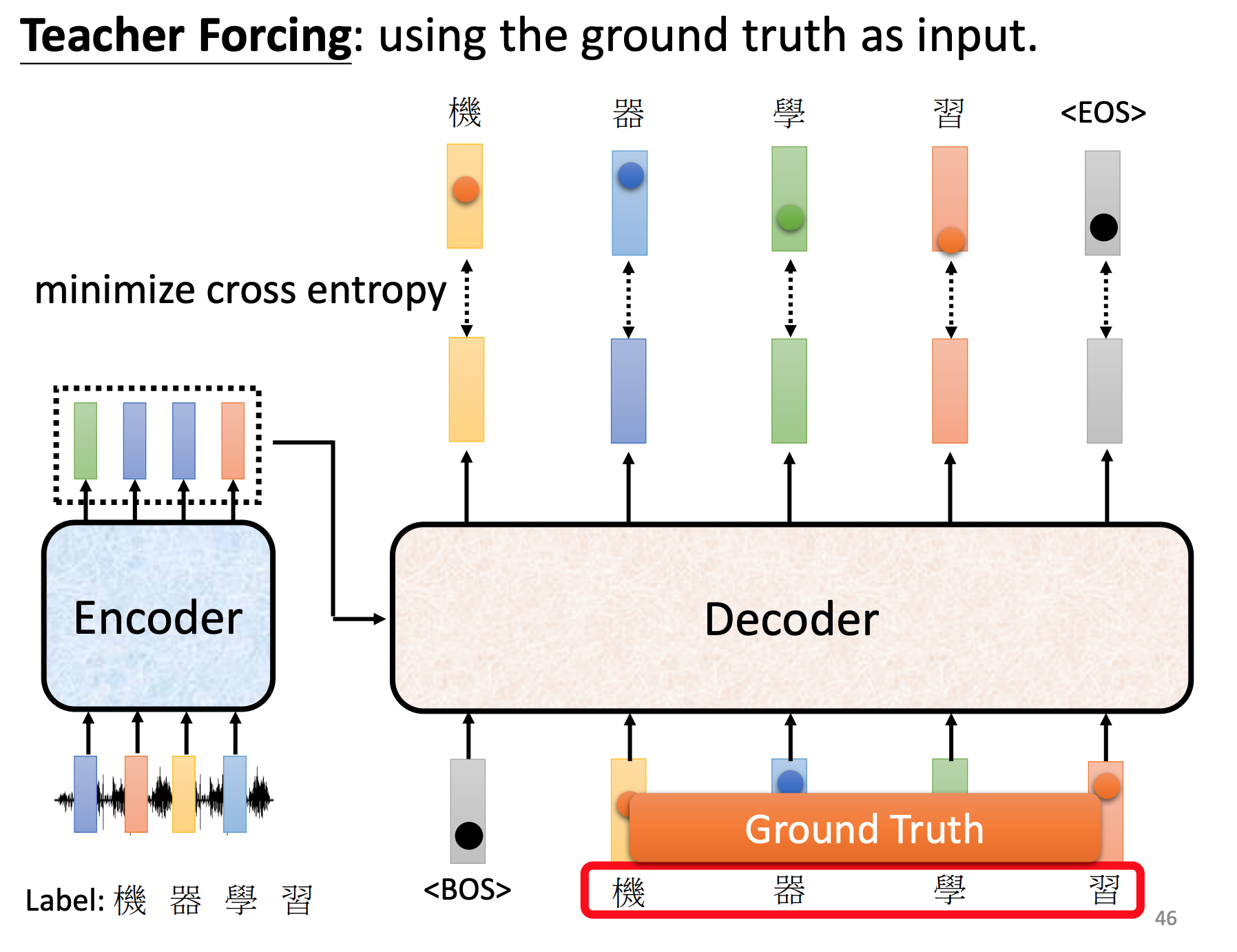
训练时候,decoder给正确答案。
tips
-
Copy Mechanism 从input复制某些词汇到output 场景: 翻译,chat,summary
-
Guided Attention 强迫Attention有固定模式,Attention不能漏,语序不能错 场景:语音识别、TTS Monotonic Attention ,Location-aware attention
-
Beam Search decoder的output,不一定选最大可能那个,帮助寻找较好路径 (对需要创造性的任务效果不好,有确切答案的任务效果好)
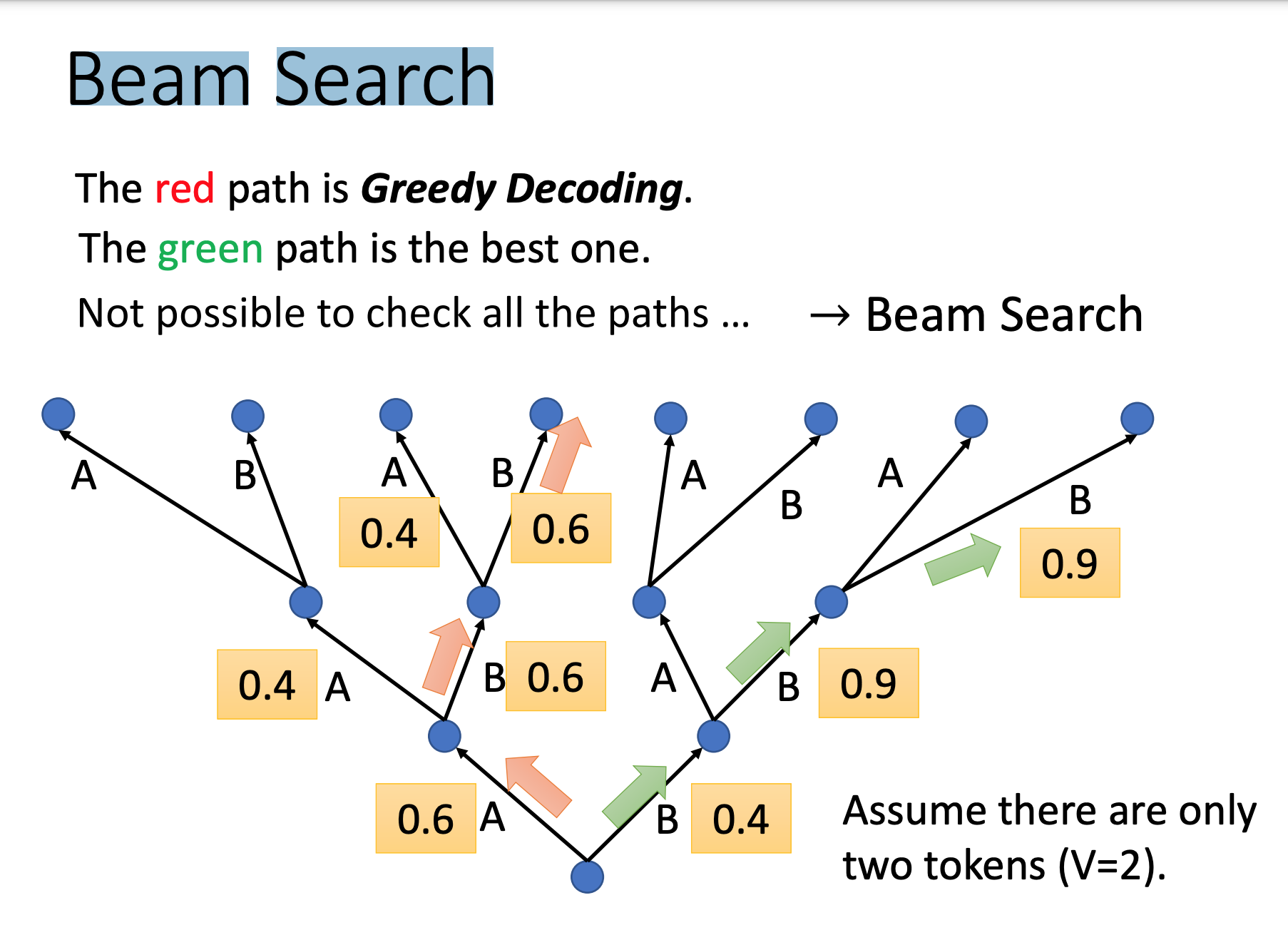
-
Scheduled Sampling 训练测试要加入一些错误的列子,效果会更好
MOE
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
稀疏门控专家混合模型 ( Sparsely-Gated MoE):旨在实现条件计算,即神经网络的某些部分以每个样本为基础进行激活,作为一种显著增加模型容量和能力而不必成比例增加计算量的方法。
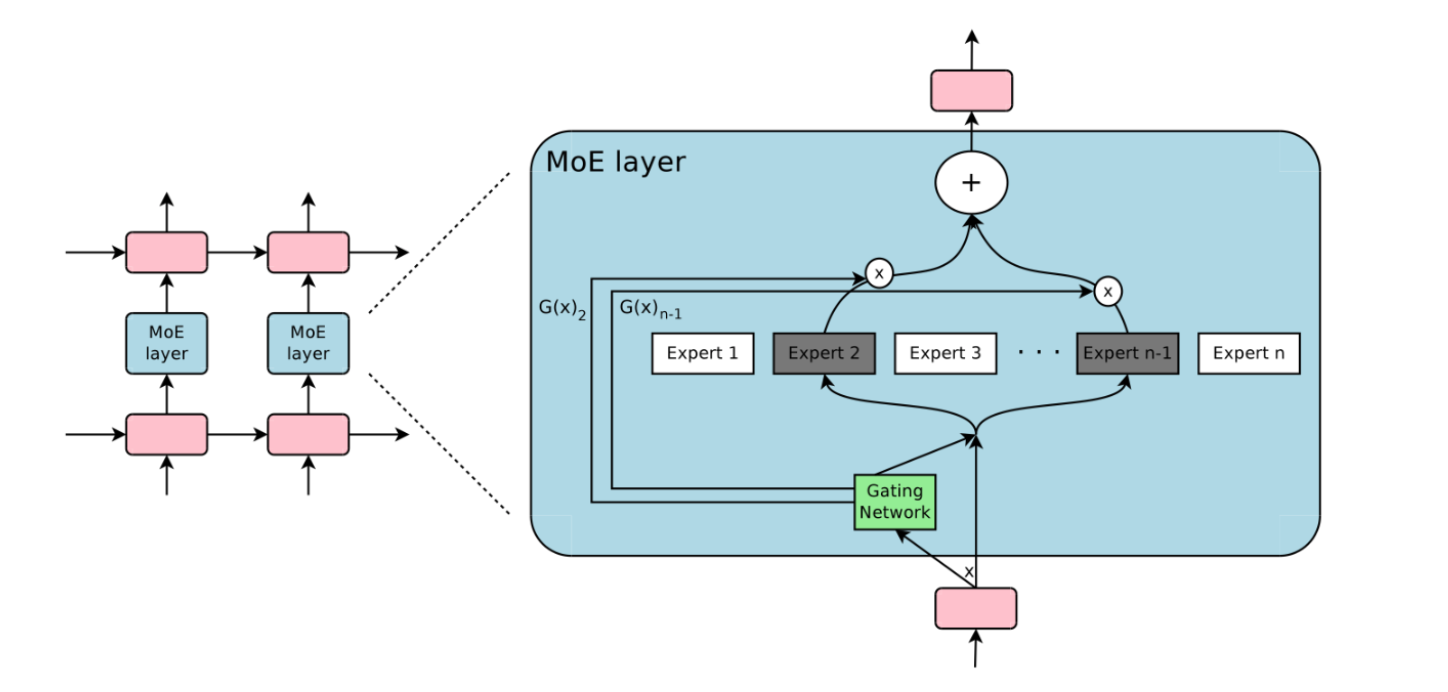
为了保证稀疏性和均衡性(为了不让某个expert专家权重特别大),对softmax做了如下处理 :
- 引入KeepTopk,这是个离散函数,将top-k之外的值强制设为负无穷大,从而softmax后的值为0。(合理听取某些专家建议,其他就不学习)
- 加noise,这个的目的是为了做均衡,这里引入了一个Wnoise的参数,后面还会在损失函数层面进行改动。

将大模型拆分成多个小模型(每个小模型就是一个专家),对于一个样本来说,无需经过所有的小模型去计算,而只是激活一部分小模型进行计算这样就节省了计算资源。稀疏门控 MOE,实现了模型容量超过1000倍的改进,并目在现代 GPU 集群的计算效率损失很小
Flash Attention
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
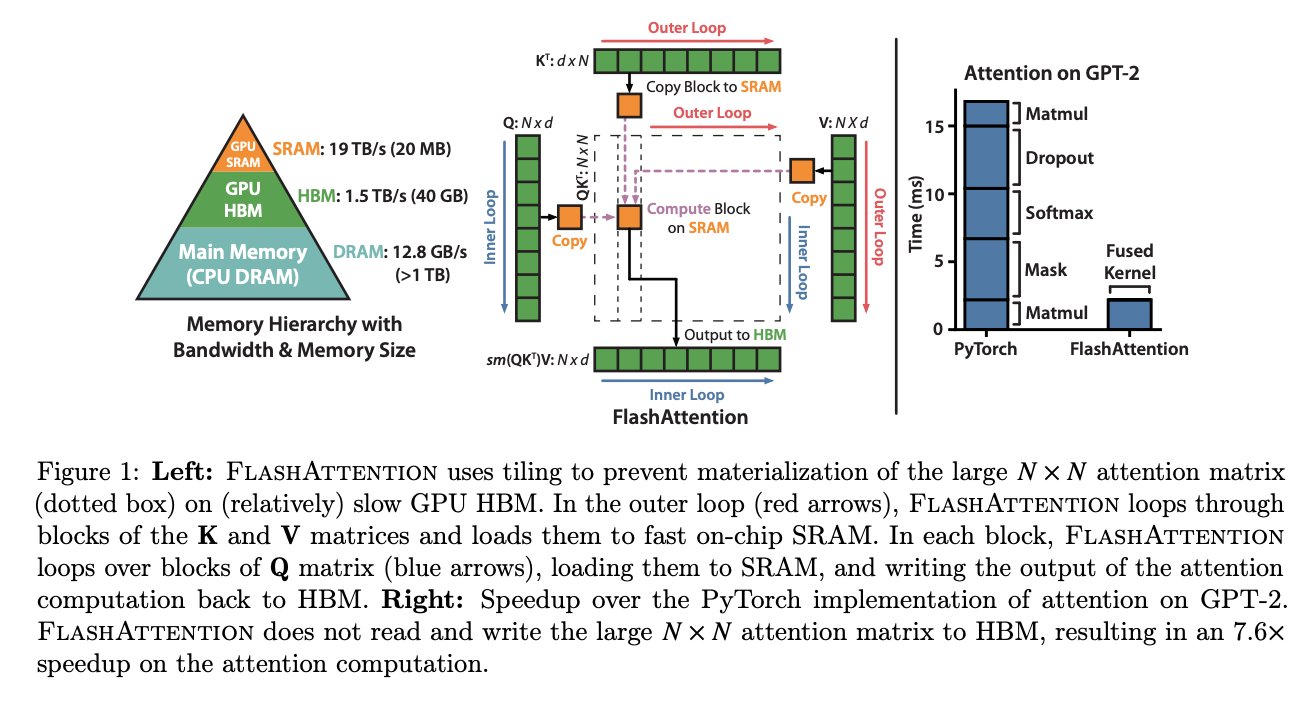
- SRAM的IO速度远大于GPU HBM的IO速度,在SRAM做运算搬运结果更快
- 将长度为N的句子的Q和{K,V}对分成诸多小块,外循环和内循环在长度轴N上进行,循环计算
materialization “材料化”指的是将 N x N 的注意力矩阵存储或表示在内存中,特别是存储在GPU的高带宽内存(HBM)上的过程。通过平铺注意力矩阵并将其加载到片上SRAM(快速的片上内存)中,避免了在相对较慢的GPU HBM上完全材料化整个注意力矩阵。这种方法有助于提高FLASHATTENTION实现中注意力计算的效率和速度。
Vision Transformer(VIT)
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
图像任务直接作用Transformer上面
把图片所有像素拉成一维数组放到Transformer,图片尺寸(224*224=507776),远远超过大模型可接受的序列长度。
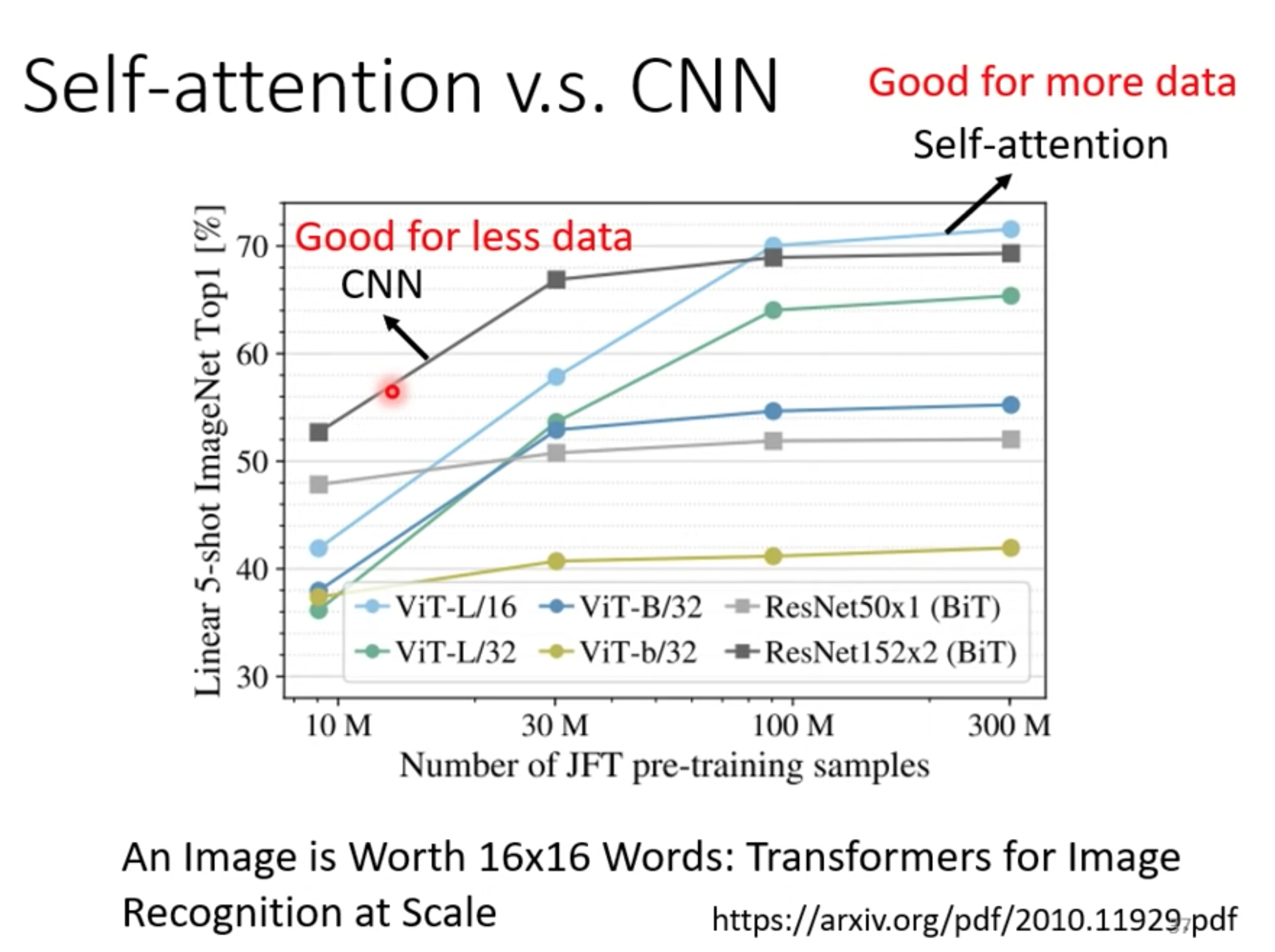
VIT有足够规模的数据预训练效果比现有的残差网络效果接近甚至更好。除了抽取图像块和位置编码用了一些图像特有的这个归纳偏置,然后就可以使用和NLP一样的Transformer。
和CNN相比,要少很多这种图像特有的归纳偏置。在中小数据集上的表现不如CNN。
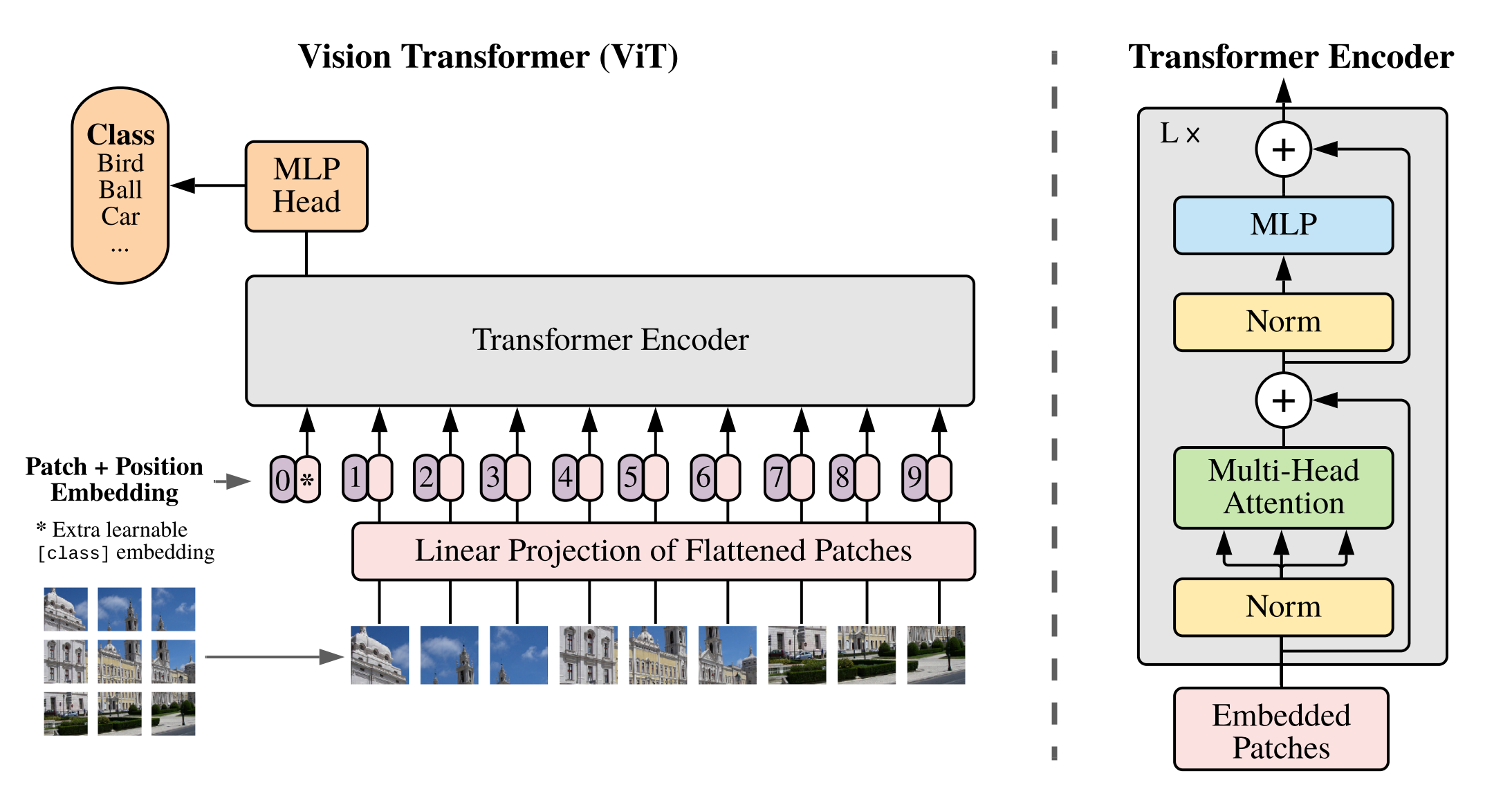
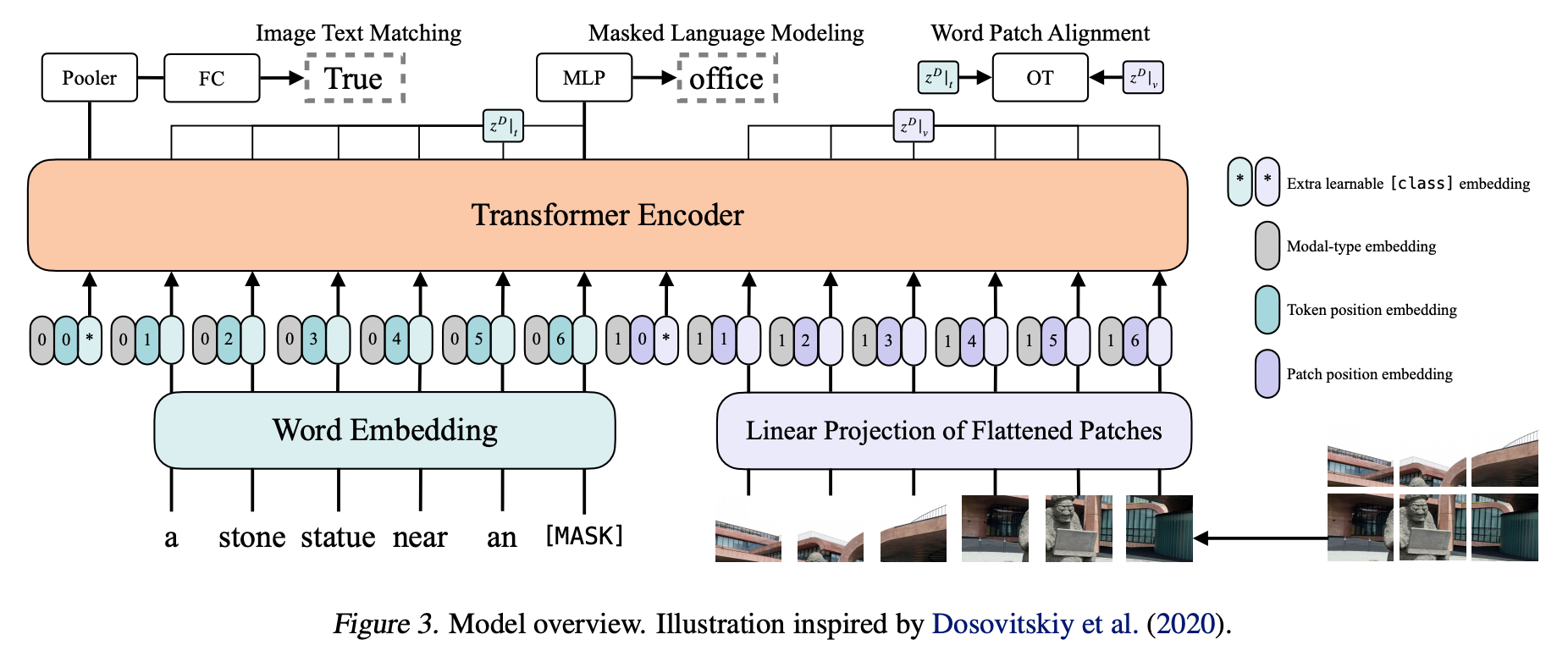
patch+位置信息
ViT的首要任务是将图转换成词的结构,将图片分割成小块,每个小块就相当于句子里的一个词。这里把每个小块称作Patch。
假设:patch 16x16,224/16 = 14 序列长度=14x14=196
而Patch Embedding就是把每个Patch再经过一个全连接网络压缩成一定维度的向量。
假设:原图224x224x3(RGB channel) 转换成一个patch 的维度(16x16x3=768) 总共196个,通过一个全连接层(768x768),最终向量Patch(196x768) x 全连接层(768x768)= 向量(196x768) + cls_token(1x768) = embedding(197x168)
加入cls_token永远放在位置0,由于所有token之间都交换信息,其他的embedding表达的都是不同的patch的特征,而cls_token是要综合所有patch的信息,产生一个新的embedding,来表达整个图的信息。
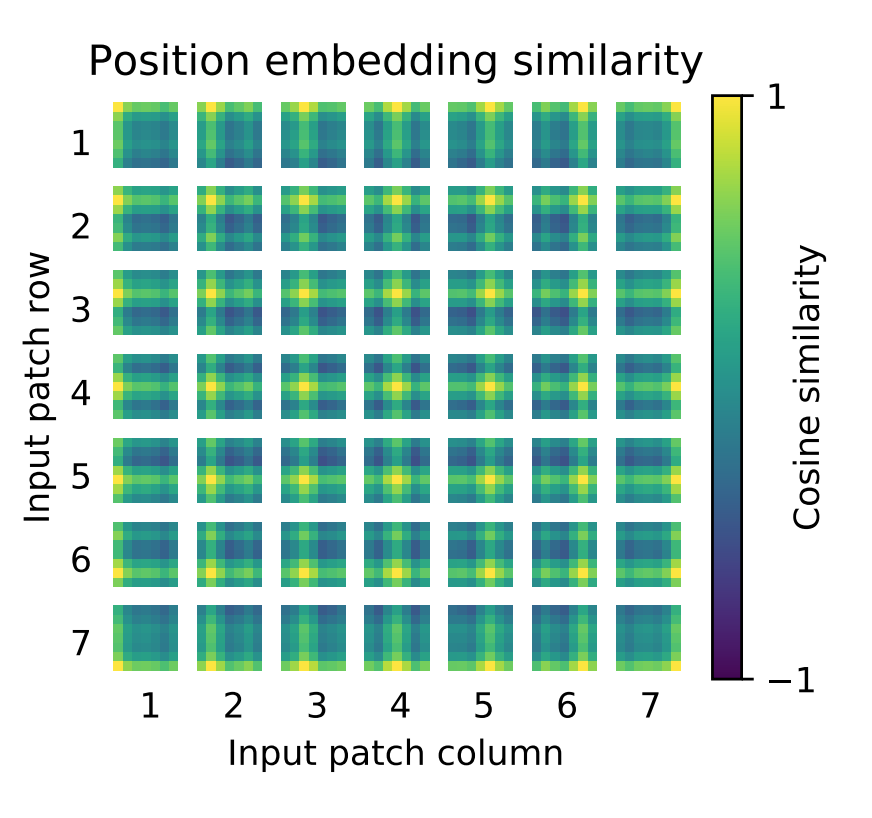
位置信息
和向量维度都是一样的,直接和embedding(197x168)相加 = Embedded Patches(197x168)
图片尺寸改变会影响,patch size 和位置编码,使用更大尺寸图片微调有局限性。位置编码可以学习到2d信息。
CLIP
Learning Transferable Visual Models From Natural Language Supervision
真正把视觉和文字上语义联系到一起,做到zero shot推理,泛化性能远比有监督训练出来的模型厉害
-
利用文本监督信号,而不是N选一这样的标签,训练集必须够大(WebImageText WIT)
-
给定图片去逐字逐句预测文本,而且对同一张图描述会很多,所以简化成衡量文字信息和图片是否配对,可以提高训练效率
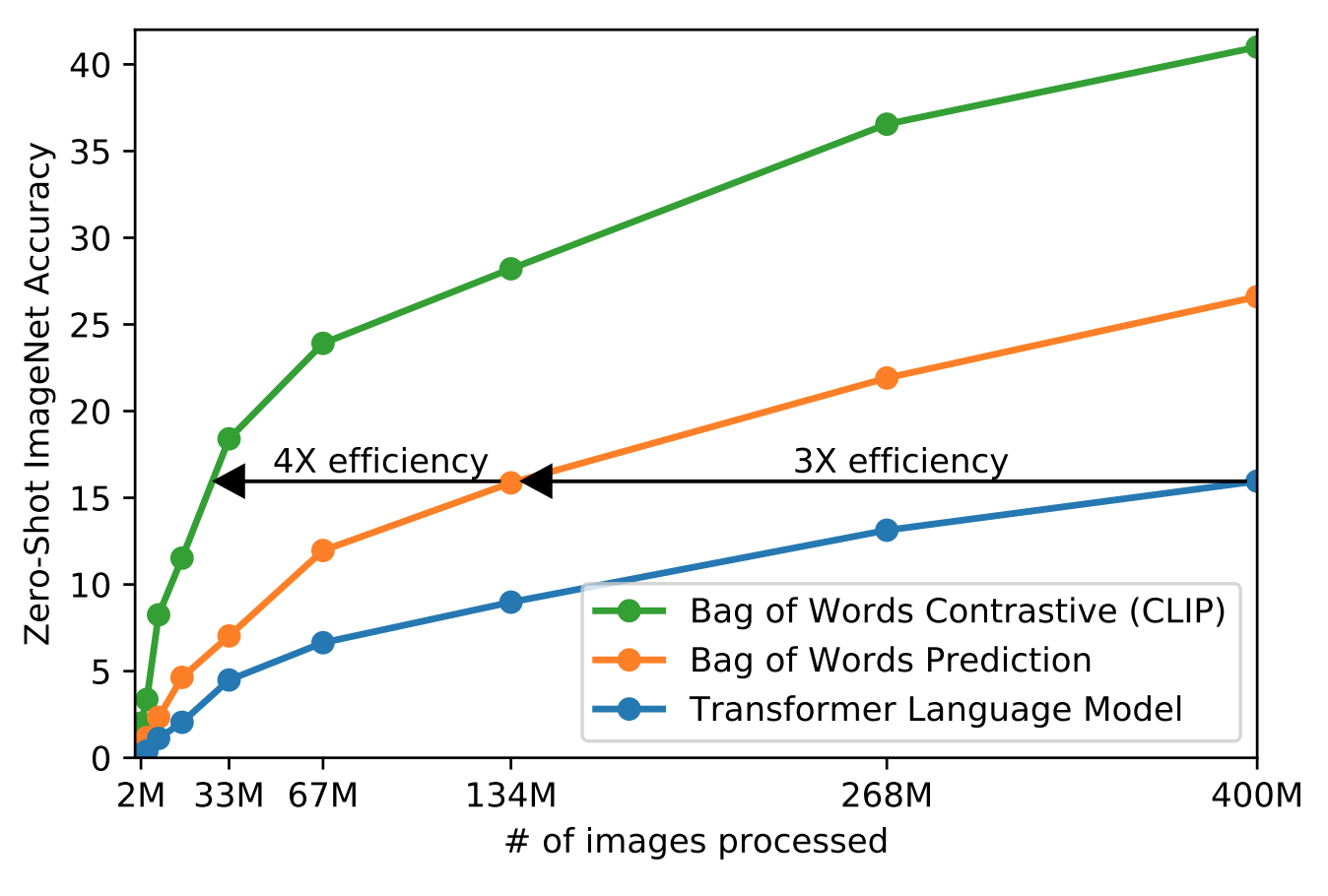
-
传统模型主要研究特征学习的能力,学习泛化性较好的特征,应用到下游任务时还需要微调,所以需要zero shot 迁移
预训练
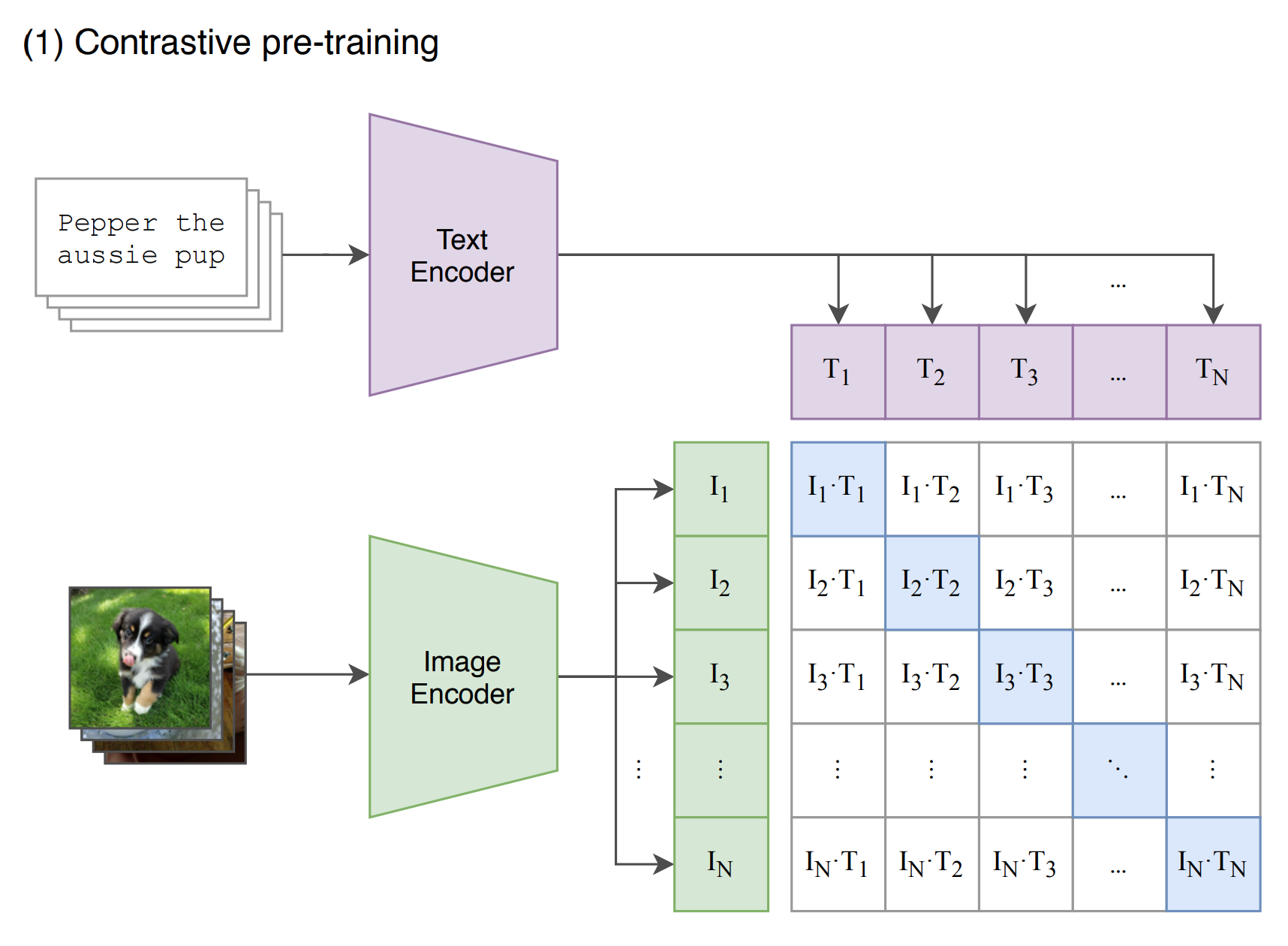
通过各自的Encoder得到N个特征,CLIP通过这些特征进行对比学习(对角线是正样本,白色底是负样本)
1 | |
学习的目标是学习这样一个嵌入空间,其中相似的样本对彼此靠近,而不相似的样本对相距很远。对比学习可以应用于有监督和无监督的环境。在处理无监督数据时,对比学习是自监督学习中最强大的方法之一。
在对比学习的损失函数的早期版本中,仅涉及一个正样本和一个负样本。最近训练目标的趋势是在一批中包含多个正负对。
推理
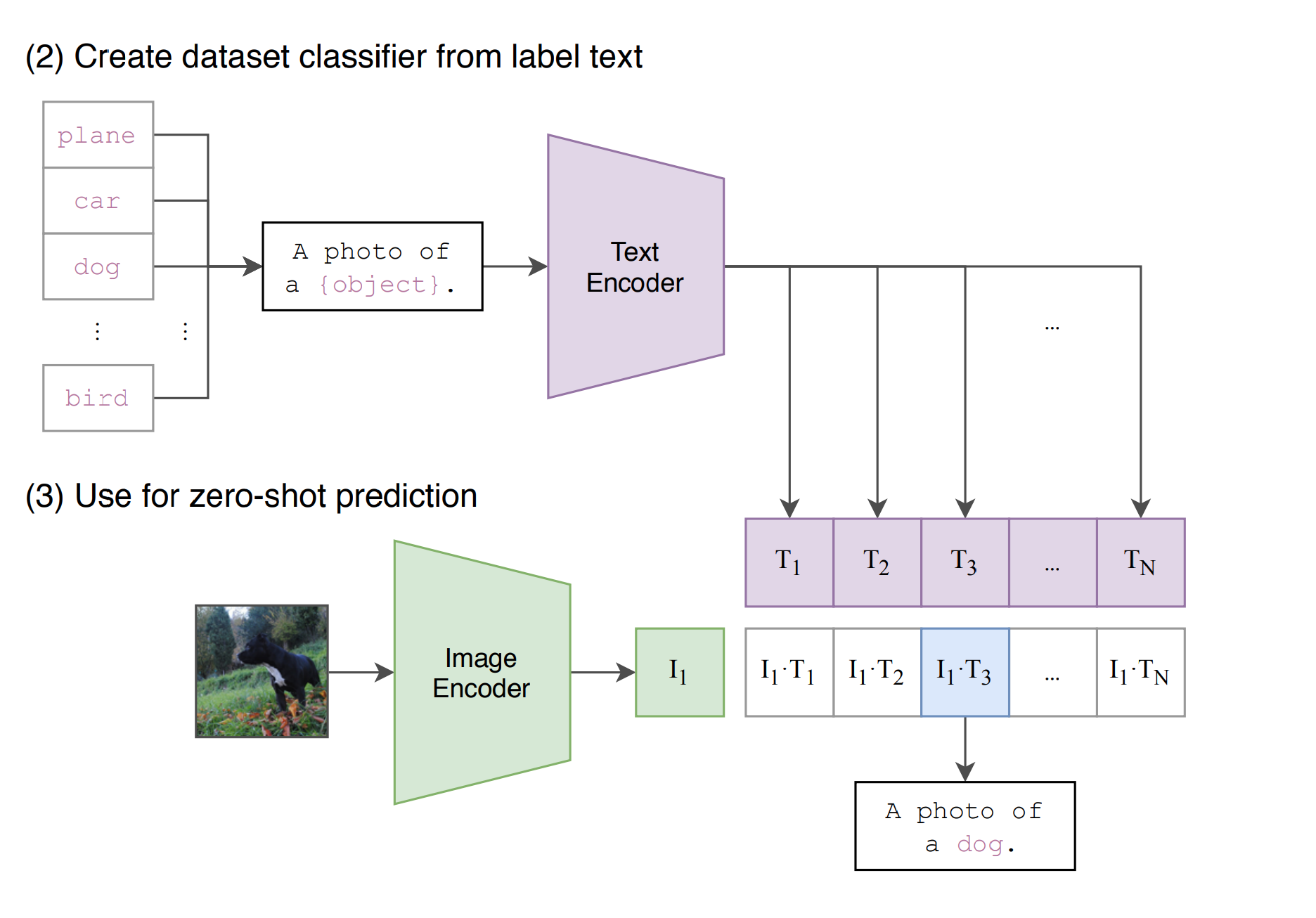
怎样推理分类
- 把所有的分类套入到prompt template,变成一个句子,然后和训练好的编码器进行encoder,得到N个文本特征。
- 将图片和训练好的编码器进行encoder,得到图片特征。和所有的文本特征,计算相似度
- 根据相似度可以得到分类
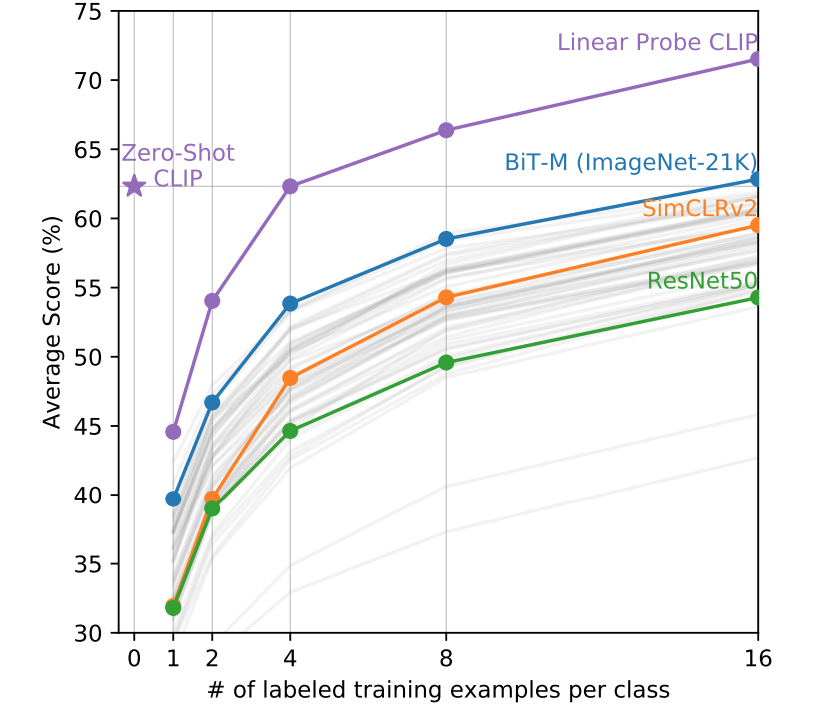
真正使用的时候,object可以换成其他从来没有训练的单词,图片也可以随便,CLIP可以做到zeor shot,普通的分类模型固定类别N选一
局限性
-
扩大CLIP规模无法扩大性能
-
不擅长细分类,抽象概念
-
图片和训练图集差得远一样表现差
-
只能从给定的类比判断是否类似,不能好像生成式那样生成新输出
-
数据利用率不高,需要太多数据
-
数据没有太多清洗,有数据偏见
-
few shot效果反而不好
ViLT
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
图像相关的模态,以前的模型通过区域特征的抽取,相当于目标检测任务,输出一些离散序列看出单词,输入到transformer和NLP模型做模态融合。
但是模型在运行时间方面浪费好多。去掉卷积特征(预训练好的一个分类模型抽出来的特征图)和区域特征(根据特征图做的目标检测的那些框所带来的特征)带来的监督信号,加快运行时间。但是性能没有使用特征的强 先预训练,再微调。
使用特征带来的坏处
- 运行效率不行。(抽出特征的时间比模态融合的时间长)
- 模型表达能力受限,因为预训练好的目标检测器,规模不大,用的数据集也小类别数不多,因为文本是没有限制的。
为什么用目标检测
- 需要语义强离散的特征表现形式,每个区域可以看出单词。
- 和下游任务有关(某个物体是否存在,物体在哪),和物体有强关联性
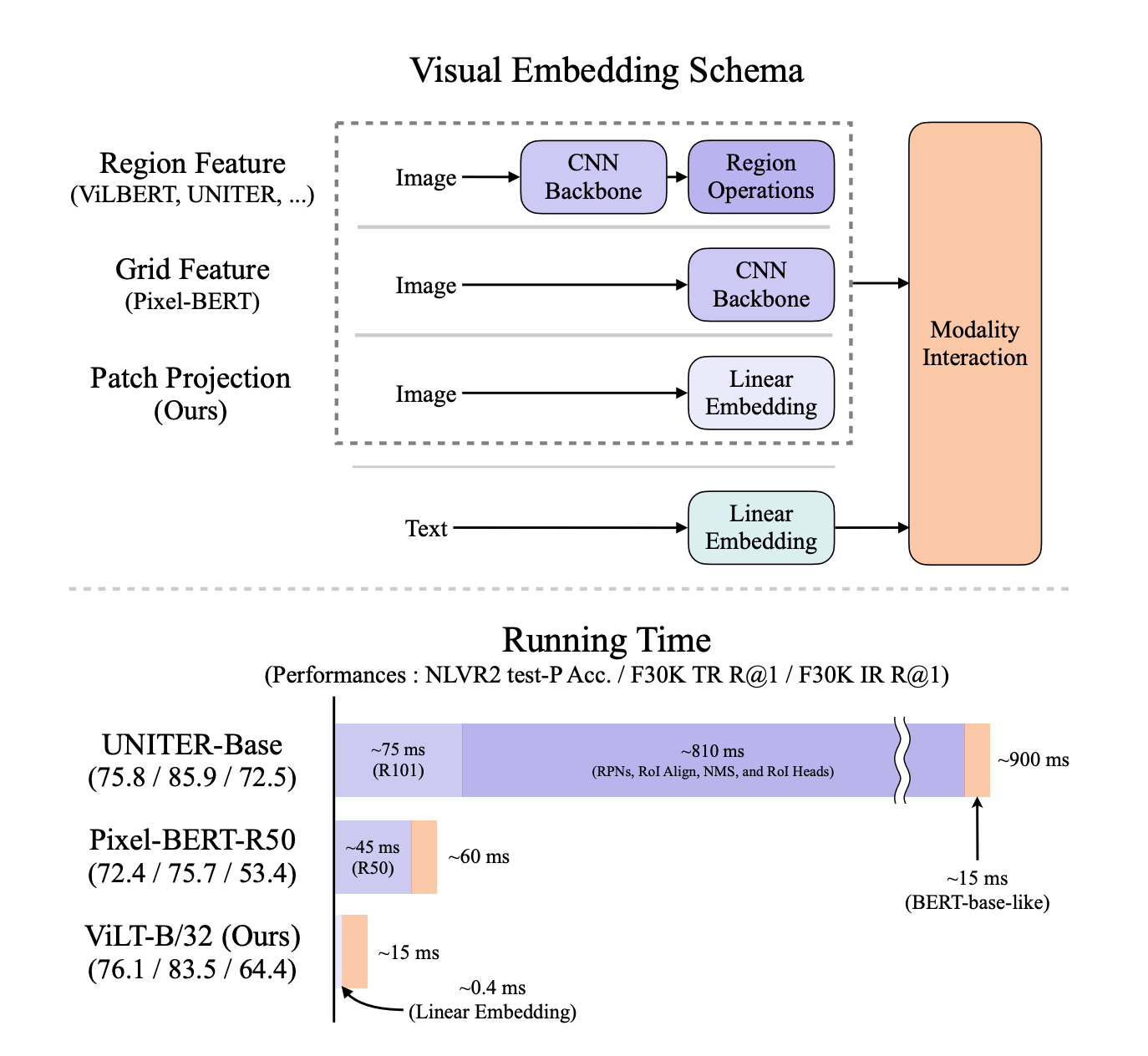
改进
受到VIT启发。
- 使用patch emedding简化计算复杂度,保持性能
- 使用数据增强(image-text pair 对应的语义),尽量保证可以对应上
- NLP整个词mask调,(当时CV的完形填空的方法还没正式有)
衡量模型
- 图像和文本表达能力是否平衡(之前图像训练贵很多),参数量
- 模态的融合(做得不好,影响下游任务)
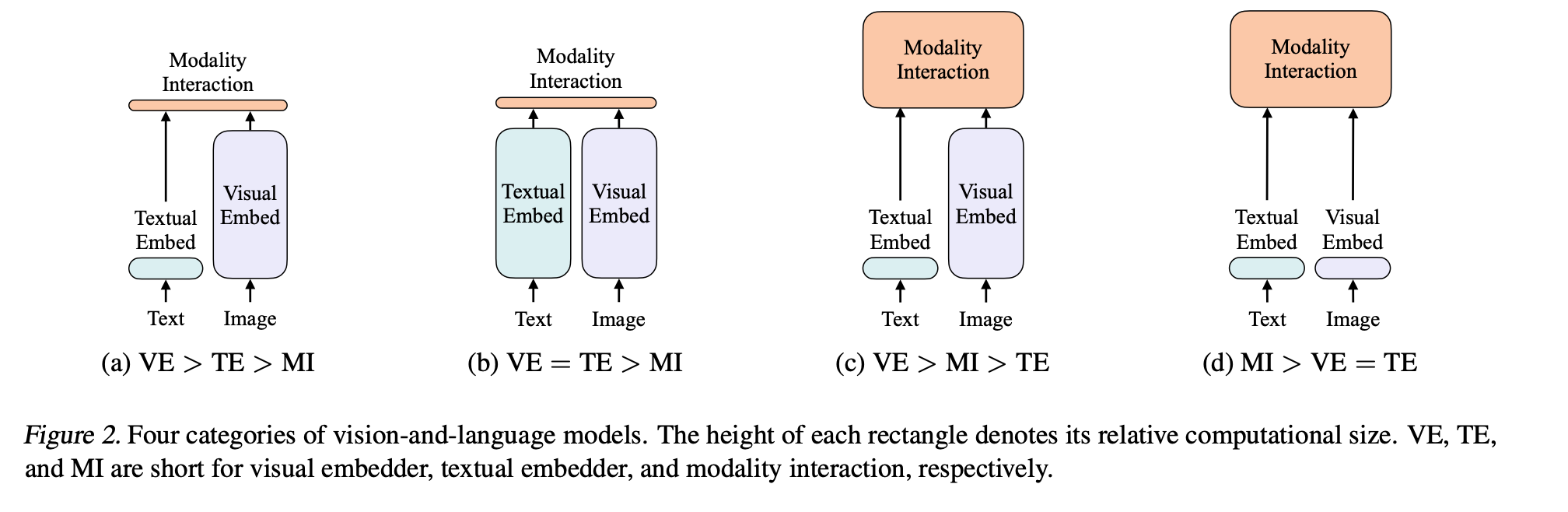
对现有领域的信息,进行分类。加深对领域的理解。
模态融合
效果各有千秋
-
single-stream approaches
只用一个模型处理两个输入(图像和文本),直接向量串联,让transformer自己去学 (使用了这个)
-
dual-stream approaches
使用两个模型,对各自的输入,充分去挖掘单独模态里包含的信息,在某个时间点用transformer融合。引入更多参数,成本贵。
1 | |