调度过程
默认情况下,kube-scheduler 提供的默认调度器能够满足我们绝大多数的要求,我们前面和大家接触的示例也基本上用的默认的策略,都可以保证我们的 Pod 可以被分配到资源充足的节点上运行。但是在实际的线上项目中,可能我们自己会比 kubernetes 更加了解我们自己的应用,比如我们希望一个 Pod 只能运行在特定的几个节点上,或者这几个节点只能用来运行特定类型的应用,这就需要我们的调度器能够可控。
kube-scheduler 的主要作用就是根据特定的调度算法和调度策略将 Pod 调度到合适的 Node 节点上去,是一个独立的二进制程序,启动之后会一直监听 API Server,获取到 PodSpec.NodeName 为空的 Pod,对每个 Pod 都会创建一个 binding。
这个过程在我们看来好像比较简单,但在实际的生产环境中,需要考虑的问题就有很多了:
- 如何保证全部的节点调度的公平性?要知道并不是所有节点资源配置一定都是一样的
- 如何保证每个节点都能被分配资源?
- 集群资源如何能够被高效利用?
- 集群资源如何才能被最大化使用?
- 如何保证 Pod 调度的性能和效率?
- 用户是否可以根据自己的实际需求定制自己的调度策略?
考虑到实际环境中的各种复杂情况,kubernetes 的调度器采用插件化的形式实现,可以方便用户进行定制或者二次开发,我们可以自定义一个调度器并以插件形式和 kubernetes 进行集成。
自定义调度器方法
- 调度器扩展程序,这个方案目前是一个可行的方案,可以和上游调度程序兼容,所谓的调度器扩展程序其实就是一个可配置的 Webhook 而已,里面包含
过滤器和优先级两个端点,分别对应调度周期中的两个主要阶段(过滤和打分)。 - 通过调度框架(Scheduling Framework),Kubernetes v1.15 版本中引入了可插拔架构的调度框架,使得定制调度器这个任务变得更加的容易。调库框架向现有的调度器中添加了一组插件化的 API,该 API 在保持调度程序“核心”简单且易于维护的同时,使得大部分的调度功能以插件的形式存在,而且在我们现在的 v1.16 版本中上面的
调度器扩展程序也已经被废弃了,所以以后调度框架才是自定义调度器的核心方式。
Scheduler Extender
在进入调度器扩展程序之前,我们再来了解下 Kubernetes 调度程序是如何工作的
- 默认调度器根据指定的参数启动(我们使用 kubeadm 搭建的集群,启动配置文件位于
/etc/kubernetes/manifests/kube-schdueler.yaml) - watch apiserver,将
spec.nodeName为空的 Pod 放入调度器内部的调度队列中 - 从调度队列中 Pop 出一个 Pod,开始一个标准的调度周期
- 从 Pod 属性中检索“硬性要求”(比如 CPU/内存请求值,nodeSelector/nodeAffinity),然后过滤阶段发生,在该阶段计算出满足要求的节点候选列表
- 从 Pod 属性中检索“软需求”,并应用一些默认的“软策略”(比如 Pod 倾向于在节点上更加聚拢或分散),最后,它为每个候选节点给出一个分数,并挑选出得分最高的最终获胜者
- 和 apiserver 通信(发送绑定调用),然后设置 Pod 的
spec.nodeName属性以表示将该 Pod 调度到的节点。
我们可以通过查看官方文档,可以通过 --config 参数指定调度器将使用哪些参数,该配置文件应该包含一个 KubeSchedulerConfiguration 对象,如下所示格式:(/etc/kubernetes/scheduler-extender.yaml)
1 | |
该策略文件 /etc/kubernetes/scheduler-extender-policy.yaml 应该遵循 kubernetes/pkg/scheduler/apis/config/legacy_types.go#L28 的要求,在我们这里的 v1.16.2 版本中已经支持 JSON 和 YAML 两种格式的策略文件,下面是我们定义的一个简单的示例,可以查看 Extender 描述了解策略文件的定义规范:
1 | |
我们这里的 Policy 策略文件是通过定义 extenders 来扩展调度器的,有时候我们不需要去编写代码,可以直接在该配置文件中通过指定 predicates 和 priorities 来进行自定义,如果没有指定则会使用默认的 DefaultProvier:
1 | |
改策略文件定义了一个 HTTP 的扩展程序服务,该服务运行在 127.0.0.1:8888 下面,并且已经将该策略注册到了默认的调度器中,这样在过滤和打分阶段结束后,可以将结果分别传递给该扩展程序的端点 <urlPrefix>/<filterVerb> 和 <urlPrefix>/<prioritizeVerb>,在扩展程序中,我们可以进一步过滤并确定优先级,以适应我们的特定业务需求。
- https://github.com/Huang-Wei/sample-scheduler-extender 代码示例
- https://github.com/AliyunContainerService/gpushare-scheduler-extender/blob/master/docs/install.md 配置用例
sheduler参数
1 | |
1 | |
对于多调度器的使用可以查看官方文档 配置多个调度器。
调度器扩展程序可能是在一些情况下可以满足我们的需求,但是他仍然有一些限制和缺点:
- 通信成本:数据在默认调度程序和调度器扩展程序之间以
http(s)传输,在执行序列化和反序列化的时候有一定成本 - 有限的扩展点:扩展程序只能在某些阶段的末尾参与,例如
“ Filter”和“ Prioritize”,它们不能在任何阶段的开始或中间被调用 - 减法优于加法:与默认调度程序传递的节点候选列表相比,我们可能有一些需求需要添加新的候选节点列表,但这是比较冒险的操作,因为不能保证新节点可以通过其他要求,所以,调度器扩展程序最好执行
“减法”(进一步过滤),而不是“加法”(添加节点) - 缓存共享:上面只是一个简单的测试示例,但在真实的项目中,我们是需要通过查看整个集群的状态来做出调度决策的,默认调度程序可以很好地调度决策,但是无法共享其缓存,这意味着我们必须构建和维护自己的缓存
由于这些局限性,Kubernetes 调度小组就提出了上面第四种方法来进行更好的扩展,也就是调度框架(Scheduler Framework),它基本上可以解决我们遇到的所有难题,现在也已经成官方推荐的扩展方式,所以这将是以后扩展调度器的最主流的方式。
Scheduler Framework
用户可以实现扩展点定义的接口来定义自己的调度逻辑(我们称之为扩展),并将扩展注册到扩展点上,调度框架在执行调度工作流时,遇到对应的扩展点时,将调用用户注册的扩展。调度框架在预留扩展点时,都是有特定的目的,有些扩展点上的扩展可以改变调度程序的决策方法,有些扩展点上的扩展只是发送一个通知。
我们知道每当调度一个 Pod 时,都会按照两个过程来执行:调度过程和绑定过程。
调度过程为 Pod 选择一个合适的节点,绑定过程则将调度过程的决策应用到集群中(也就是在被选定的节点上运行 Pod),将调度过程和绑定过程合在一起,称之为调度上下文(scheduling context)。需要注意的是调度过程是同步运行的(同一时间点只为一个 Pod 进行调度),绑定过程可异步运行(同一时间点可并发为多个 Pod 执行绑定)。
调度过程和绑定过程遇到如下情况时会中途退出:
- 调度程序认为当前没有该 Pod 的可选节点
- 内部错误
这个时候,该 Pod 将被放回到 待调度队列,并等待下次重试。
扩展点(Extension Points)
调度框架中的调度上下文及其中的扩展点,一个扩展可以注册多个扩展点,以便可以执行更复杂的有状态的任务。
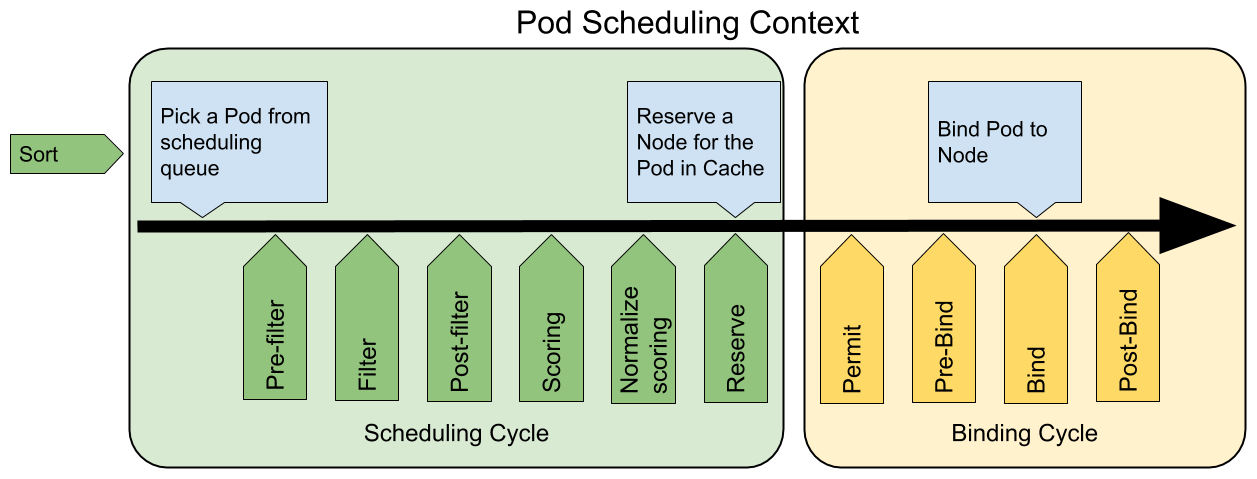
QueueSort扩展用于对 Pod 的待调度队列进行排序,以决定先调度哪个 Pod,QueueSort扩展本质上只需要实现一个方法Less(Pod1, Pod2)用于比较两个 Pod 谁更优先获得调度即可,同一时间点只能有一个QueueSort插件生效。Pre-filter扩展用于对 Pod 的信息进行预处理,或者检查一些集群或 Pod 必须满足的前提条件,如果pre-filter返回了 error,则调度过程终止。Filter扩展用于排除那些不能运行该 Pod 的节点,对于每一个节点,调度器将按顺序执行filter扩展;如果任何一个filter将节点标记为不可选,则余下的filter扩展将不会被执行。调度器可以同时对多个节点执行filter扩展。Post-filter是一个通知类型的扩展点,调用该扩展的参数是filter阶段结束后被筛选为可选节点的节点列表,可以在扩展中使用这些信息更新内部状态,或者产生日志或 metrics 信息。Scoring扩展用于为所有可选节点进行打分,调度器将针对每一个节点调用Soring扩展,评分结果是一个范围内的整数。在normalize scoring阶段,调度器将会把每个scoring扩展对具体某个节点的评分结果和该扩展的权重合并起来,作为最终评分结果。Normalize scoring扩展在调度器对节点进行最终排序之前修改每个节点的评分结果,注册到该扩展点的扩展在被调用时,将获得同一个插件中的scoring扩展的评分结果作为参数,调度框架每执行一次调度,都将调用所有插件中的一个normalize scoring扩展一次。Reserve是一个通知性质的扩展点,有状态的插件可以使用该扩展点来获得节点上为 Pod 预留的资源,该事件发生在调度器将 Pod 绑定到节点之前,目的是避免调度器在等待 Pod 与节点绑定的过程中调度新的 Pod 到节点上时,发生实际使用资源超出可用资源的情况。(因为绑定 Pod 到节点上是异步发生的)。这是调度过程的最后一个步骤,Pod 进入 reserved 状态以后,要么在绑定失败时触发 Unreserve 扩展,要么在绑定成功时,由 Post-bind 扩展结束绑定过程。Permit扩展用于阻止或者延迟 Pod 与节点的绑定。Permit 扩展可以做下面三件事中的一项:- approve(批准):当所有的 permit 扩展都 approve 了 Pod 与节点的绑定,调度器将继续执行绑定过程
- deny(拒绝):如果任何一个 permit 扩展 deny 了 Pod 与节点的绑定,Pod 将被放回到待调度队列,此时将触发
Unreserve扩展 - wait(等待):如果一个 permit 扩展返回了 wait,则 Pod 将保持在 permit 阶段,直到被其他扩展 approve,如果超时事件发生,wait 状态变成 deny,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展
Pre-bind扩展用于在 Pod 绑定之前执行某些逻辑。例如,pre-bind 扩展可以将一个基于网络的数据卷挂载到节点上,以便 Pod 可以使用。如果任何一个pre-bind扩展返回错误,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展。Bind扩展用于将 Pod 绑定到节点上:- 只有所有的 pre-bind 扩展都成功执行了,bind 扩展才会执行
- 调度框架按照 bind 扩展注册的顺序逐个调用 bind 扩展
- 具体某个 bind 扩展可以选择处理或者不处理该 Pod
- 如果某个 bind 扩展处理了该 Pod 与节点的绑定,余下的 bind 扩展将被忽略
Post-bind是一个通知性质的扩展:- Post-bind 扩展在 Pod 成功绑定到节点上之后被动调用
- Post-bind 扩展是绑定过程的最后一个步骤,可以用来执行资源清理的动作
Unreserve是一个通知性质的扩展,如果为 Pod 预留了资源,Pod 又在被绑定过程中被拒绝绑定,则 unreserve 扩展将被调用。Unreserve 扩展应该释放已经为 Pod 预留的节点上的计算资源。在一个插件中,reserve 扩展和 unreserve 扩展应该成对出现。
我们要实现自己的插件,必须向调度框架注册插件并完成配置,另外还必须实现扩展点接口,对应的扩展点接口我们可以在源码 pkg/scheduler/framework/v1alpha1/interface.go 文件中找到,如下所示:
1 | |
对于调度框架插件的启用或者禁用,我们同样可以使用上面的 KubeSchedulerConfiguration 资源对象来进行配置。下面的例子中的配置启用了一个实现了 reserve 和 preBind 扩展点的插件,并且禁用了另外一个插件,同时为插件 foo 提供了一些配置信息:
1 | |
扩展的调用顺序如下:
- 如果某个扩展点没有配置对应的扩展,调度框架将使用默认插件中的扩展
- 如果为某个扩展点配置且激活了扩展,则调度框架将先调用默认插件的扩展,再调用配置中的扩展
- 默认插件的扩展始终被最先调用,然后按照
KubeSchedulerConfiguration中扩展的激活enabled顺序逐个调用扩展点的扩展 - 可以先禁用默认插件的扩展,然后在
enabled列表中的某个位置激活默认插件的扩展,这种做法可以改变默认插件的扩展被调用时的顺序
假设默认插件 foo 实现了 reserve 扩展点,此时我们要添加一个插件 bar,想要在 foo 之前被调用,则应该先禁用 foo 再按照 bar foo 的顺序激活。示例配置如下所示:
1 | |
在源码目录 pkg/scheduler/framework/plugins/examples 中有几个示范插件,我们可以参照其实现方式。
- https://github.com/cnych/sample-scheduler-framework 示例代码
- https://github.com/volcano-sh/volcano 示例应用
然后我们就可以当成普通的应用用一个 Deployment 控制器来部署即可,由于我们需要去获取集群中的一些资源对象,所以当然需要申请 RBAC 权限,然后同样通过 --config 参数来配置我们的调度器,同样还是使用一个 KubeSchedulerConfiguration 资源对象配置,可以通过 plugins 来启用或者禁用我们实现的插件,也可以通过 pluginConfig 来传递一些参数值给插件
1 | |
直接部署上面的资源对象即可,这样我们就部署了一个名为 sample-scheduler 的调度器了,接下来我们可以部署一个应用来使用这个调度器进行调度:
1 | |