rke
安装命令
cluster.yml 是配置文件
1 | |
https://rancher.com/docs/rke/latest/en/example-yamls/ example
升级条件
RKE v0.2.0 及以上的版本使用cluster.rkestate文件管理集群状态。cluster.rkestate文件中含有集群的当前状态,包括 RKE 配置和证书等信息。
这个文件和cluster.yml位于同一目录下。
cluster.rkestate文件非常重要,控制集群和升级集群的时候都需要用到这个文件,请妥善保管该文件。
升级流程
RKE v1.1.0 及以上的版本提供了以下新功能:
- 支持不宕机升级,编辑或升级集群时,不会影响集群内的应用。
- 支持手动指定单个节点,并单独升级这个节点。
- 支持使用包含老版本的 Kubernetes 集群快照,将集群使用的 Kubernetes 恢复到先前的版本。这个功能使升级集群的过程变得更加安全。如果某次升级的过程中,集群中有些节点无法完成更新,导致该节点内的 pods 和应用无法访问,您可以将已经完成升级的集群所使用的 Kubernetes 降级为升级前使用的版本。
使用默认配置选项,输入rke up命令更新集群时,会依次触发以下事项:
- 逐个更新每个节点的 etcd plane。RKE 集群内的任何一个 etcd 节点在升级的过程中失效,会导致集群升级失败。
- 逐个更新 controlplane 节点,包括 controlplane 组件和 controlplane 节点的 worker plane 组件。
- 逐个更新每个 etcd 节点的 worker plane 组件。
- 批量更新 worker 节点,您可以配置每批更新的节点数量。在批量更新 worker 节点的过程中,可能会有部分节点不可用,为了降低这部分节点对于升级的影响,您可以配置最大不可用节点数量。默认的最大不可用节点数量是总节点数量的 10%,最小值为 1,如果是小数则向下取整至最近的一个整数,详情请参考下文。
- 更新每个插件。
升级k8s
k8s(限于同一个rke升级k8s)
输入以下命令,快速获取支持K8s版本号
1 | |
指定k8s版本安装,修改配置文件,原来是v1.19.16-rancher1-2
1 | |
升级 Kubernetes 版本,打开cluster.yml文件,找到 kubernetes_version字符串,将原有的版本号修改为新的版本号即可。重新执行安装命令。
1 | |
升级 Kubernetes 版本,打开cluster.yml文件,找到 kubernetes_version字符串,将原有的版本号修改为新的版本号即可。重新执行安装命令。
如果在kubernetes_version和system_images中都定义了 Kubernetes 版本,system_images中定义的版本会生效,而kubernetes_version中定义的版本不会生效。如果两者都没有定义 Kubernetes 版本,RKE 会使用默认的 Kubernetes 版本。
获取镜像版本
-
如果在
kubernetes_version和system_images中都定义了 Kubernetes 版本,system_images中定义的版本会生效,而kubernetes_version中定义的版本不会生效。如果两者都没有定义 Kubernetes 版本,RKE 会使用默认的 Kubernetes 版本。1
2
3
4
5
6
7
8# 打印镜像 rke config --system-images --all INFO[0000] Generating images list for version [v1.19.16-rancher1-2]: rancher/mirrored-coreos-etcd:v3.4.15-rancher1 ..... weaveworks/weave-npc:2.7.0
docker
k8s支持的docker版本
https://github.com/kubernetes/kubernetes/tree/master/CHANGELOG
1 | |
升级服务
是指cluster.yml文件里面的service
可以修改服务的对象,或添加extra_args,然后运行rke up命令,升级服务。
说明:
service_cluster_ip_range和cluster_cidr不可修改。
升级system_images
system_images更新替换对应的镜像组件,但要注意组件兼容。一般不随便替换
添加/删除节点
https://rancher.com/docs/rke/latest/en/managing-clusters/
1 | |
The cluster’s etcd snapshots are removed, including both local snapshots and snapshots that are stored on S3.
Pods are not removed from the nodes. If the node is re-used, the pods will automatically be removed when the new Kubernetes cluster is created.
- Clean each host from the directories left by the services:
- /etc/kubernetes/ssl
- /var/lib/etcd
- /etc/cni
- /opt/cni
- /var/run/calico
创建快照
打开命令行工具,输入rke etcd snapshot-save命令,运行后即可保存 cluster config 文件内每个 etcd 节点的快照。RKE 会将节点快照保存在/opt/rke/etcd-snapshots路径下。运行上述命令时,RKE 会创建一个用于备份快照的容器。完成备份后,RKE 会删除该容器。
https://docs.rancher.cn/docs/rke/etcd-snapshots/one-time-snapshots/_index
1 | |
保存到/opt/rke/etcd-snapshots
1 |
|
上传到minio
1 | |
恢复快照
https://docs.rancher.cn/docs/rke/etcd-snapshots/restoring-from-backup/_index
您的 Kubernetes 集群发生了灾难,您可以使用rke etcd snapshot-restore来恢复您的 etcd。这个命令可以将 etcd 恢复到特定的快照,应该在遭受灾难的特定集群的 etcd 节点上运行。
当您运行该命令时,将执行以下操作。
- 同步快照或从 S3 下载快照(如有必要)。
- 跨 etcd 节点检查快照校验和,确保它们是相同的。
- 通过运行
rke remove删除您当前的集群并清理旧数据。这将删除整个 Kubernetes 集群,而不仅仅是 etcd 集群。 - 从选择的快照重建 etcd 集群。
- 通过运行
rke up创建一个新的集群。 - 重新启动集群系统 pod。
警告:在运行
rke etcd snapshot-restore之前,您应该备份集群中的任何重要数据,因为该命令会删除您当前的 Kubernetes 集群,并用新的集群替换。
1 | |
有自定义配置例如
1 |
|
恢复过程中会重建/etc/kubernetes目录,然后scheduler-policy-config.json会丢失导致恢复失败,所以要在恢复过程中配好配置
轮换证书
- etcd
- kubelet (node certificate)
- kubelet(服务证书,如果启用)
- kube-apiserver
- kube-proxy
- kube-scheduler
- kube-controller-manager
/etc/kubernetes/ssl,证书目录
1 | |
因为证书改变,相应的token也会变化,所以在完成集群证书更新后,需要对连接API SERVER的 Pod 进行重建,以获取新的token。
例如:
搭建集群,添加网络后,coredns异常
1 | |
coredns日志如下
1 | |
查看api server日志
1 | |
处理方式:
删除coredns-token和pods后恢复
1 | |
原理:
一般发生在你自定义ca,或者升级集群的时候。secret保留的 仍然是依据旧的ca 生成的token,这时需要手动删除token 和pods,让集群根据新的ca重新生成新的token,新的pod 也能使用新的token去访问。
定时备份
修改配置文件cluster.yml
创建定时快照时,可配置的参数如下表所示。
| 参数 | 说明 | S3 相关 |
|---|---|---|
| interval_hours | 创建快照的间隔时间。如果您使用 RKE v0.2.0 定义了creation参数,interval_hours会覆盖这个参数。如果不输入这个值,默认间隔是 5 分钟。支持输入正整数表示小时,如 1 表示间隔时间为 1 小时,每小时会创建一个快照。(默认: 12) |
|
| retention | 快照的存活时间,当快照存活的时间超过这个限制后,会自动删除快照。如果在etcd.retention和etcd.backup_config.retention都配置了限制,RKE 会以etcd.backup_config.retention为准。(默认: 6) |
|
| bucket_name | S3 的 桶名称(bucket name) | * |
| folder | 指定 S3 存储节点快照的文件夹(可选), RKE v0.3.0 及以上版本可用 | * |
| access_key | S3 的 accessKey | * |
| secret_key | S3 的 secretKey | * |
| region | S3 的 桶所在的区域(可选) | * |
| endpoint | 指定 S3 端点 URL 地址,默认值为 s3.amazonaws.com | * |
| custom_ca | 自定义证书认证,用于连接 S3 端点。使用私有存储时必填,RKE v0.2.5 及以上版本可用。 | * |
1 | |
一次性快照
一次性快照参考rke官方文档
备份
1 | |
保存到/opt/rke/etcd-snapshots
1 |
|
上传到minio
1 | |
恢复
1 | |
有自定义配置例如
1 |
|
恢复过程中会重建/etc/kubernetes目录,然后scheduler-policy-config.json会丢失导致恢复失败,所以要在恢复过程中配好配置
k3s
指定配置文件启动
大于v1.19.1+k3s1支持
默认情况下,位于/etc/rancher/k3s/config.yaml的 YAML 文件中的值将在安装时使用
1 | |
对应cli参数
1 | |
可以同时使用配置文件和 CLI 参数,CLI 参数将优先,对于可重复的参数,如--node-label,CLI 参数将覆盖列表中的所有值。
配置文件的位置可以通过 cli 参数--config FILE,-c FILE或者环境变量$K3S_CONFIG_FILE来改变。
升级
首先确认当前版本 v1.19.5+k3s2
1 | |
针对版本,阅读k3s升级介绍
手动升级
停止服务
为了在升级期间实现高可用性,K3s 容器在 K3s 服务停止时继续运行。
要停止所有 K3s 容器并重置 containerd 状态,k3s-killall.sh可以使用该脚本。
killall 脚本清理容器、K3s 目录和网络组件,同时还删除 iptables 链以及所有相关规则。集群数据不会被删除。
要从服务器节点运行 killall 脚本,请运行
1 | |
安装
升级时,先逐个升级 server 节点,然后再升级其他 agent 节点。
- 从发布中下载所需版本的 K3s 二进制文件,和对应镜像
- 将下载的二进制文件复制到
/usr/local/bin/k3s(或您想要的位置) - 重启k3s服务和代理
1 | |
更新Traefik1.7to2.x
原理介绍
里面涉及到Traefik的迁移,1.20+的版本会有开始使用Traefik2,然后和Traefik1差别好大,强行升级会报错Failed to list *v1beta1.Ingress: the server could not find the requested resource (get ingresses.extensions) ,不要看Traefik官方的迁移文档,参考这个K3s:将 Traefik 入口控制器升级到版本 2
traefik的启动其实依赖于/var/lib/rancher/k3s/server/manifests里面的yaml
1 | |
里面相当于helm安装 /var/lib/rancher/k3s/server/static/charts里面的charts
解决方法
更新完k3s后,会更新charts里面的内容,但是没有更新manifests里面的yaml,可以通过doker ps/docker images定位到更新完,Traefik还在应用旧镜像。所以要找到k3s对应版本的traefik.yaml,做相应的替换。
最后
1 | |
备份
存放数据的目录由k3s server --data-dir ${data-dir} 确定
${data-dir} 默认 /var/lib/rancher/k3s or ${HOME}/.rancher/k3s(如果不是root用户)
快照目录默认为 ${data-dir}/server/db/snapshots
完整快照目录默认
1 | |
k3s 默认每12hour备份一次,保留5个备份分别用--etcd-snapshot-schedule-cron和 --etcd-snapshot-retention定义,都是k3s server 的子命令
| 参数 | 描述 |
|---|---|
--etcd-disable-snapshots |
禁用自动 etcd 快照 |
--etcd-snapshot-schedule-cron |
以 Cron 表达式的形式配置触发定时快照的时间点,例如:每 5 小时触发一次0 */5 * * *,默认值为每 12 小时触发一次:0 */12 * * * |
--etcd-snapshot-retention |
保留的快照数量,默认值为 5。 |
--etcd-snapshot-dir |
保存数据库快照的目录路径。(默认位置:${data-dir}/db/snapshots) |
--cluster-reset |
忘记所有的对等体,成为新集群的唯一成员,也可以通过环境变量[$K3S_CLUSTER_RESET]进行设置。 |
--cluster-reset-restore-path |
要恢复的快照文件的路径 |
1 | |
恢复
当 K3s 从备份中恢复时,旧的数据目录将被移动到 ${data-dir}/server/db/etcd-old/。然后 K3s 会尝试通过创建一个新的数据目录来恢复快照,然后从一个带有一个 etcd 成员的新 K3s 集群启动 etcd。
1 | |
成功结果
1 | |
启动k3s
1 | |
旧数据
1 | |
rancher使用rke添加集群
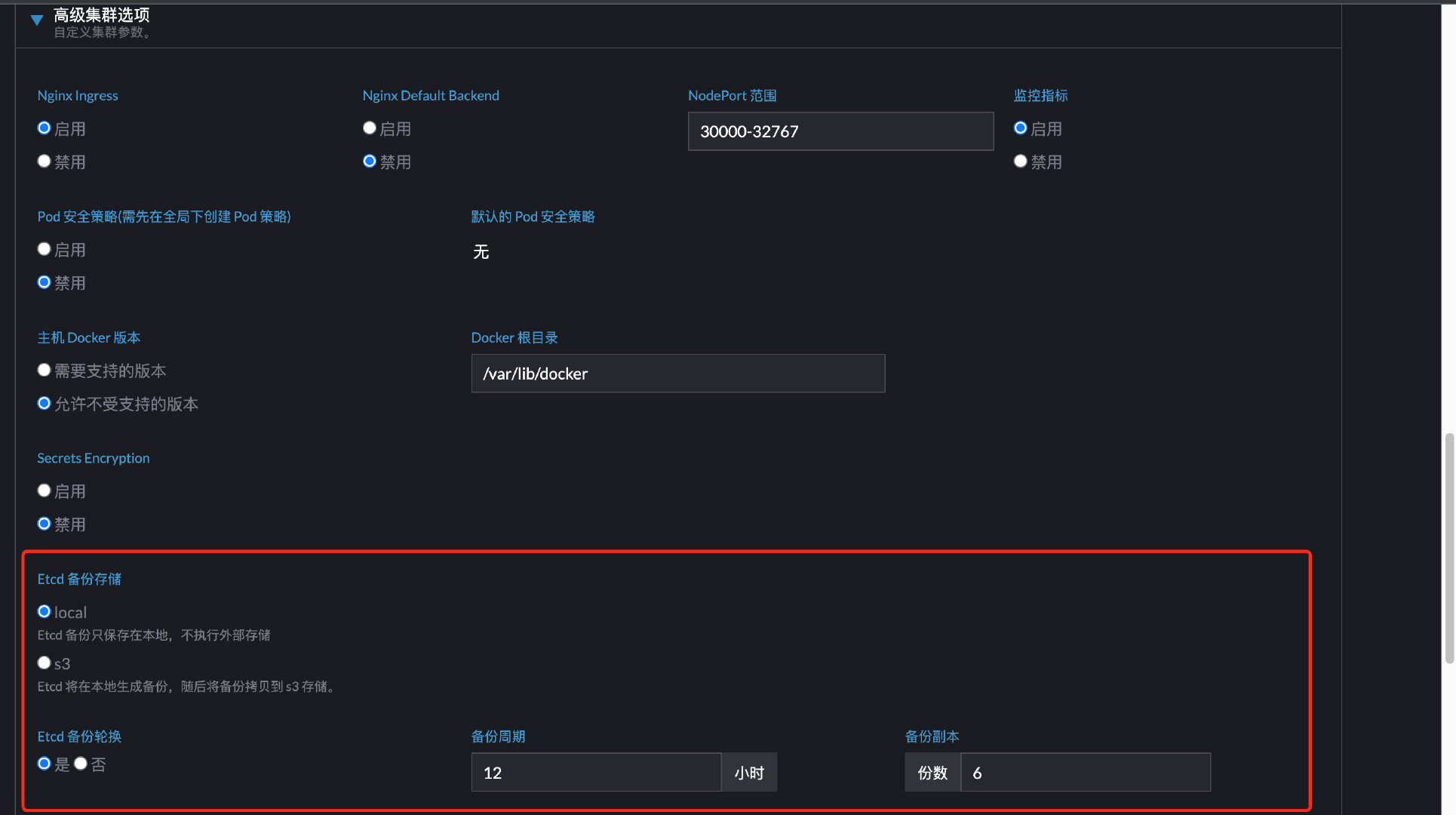
设置备份etcd
高级选项可以设置备份,默认会设置备份
修改集群配置
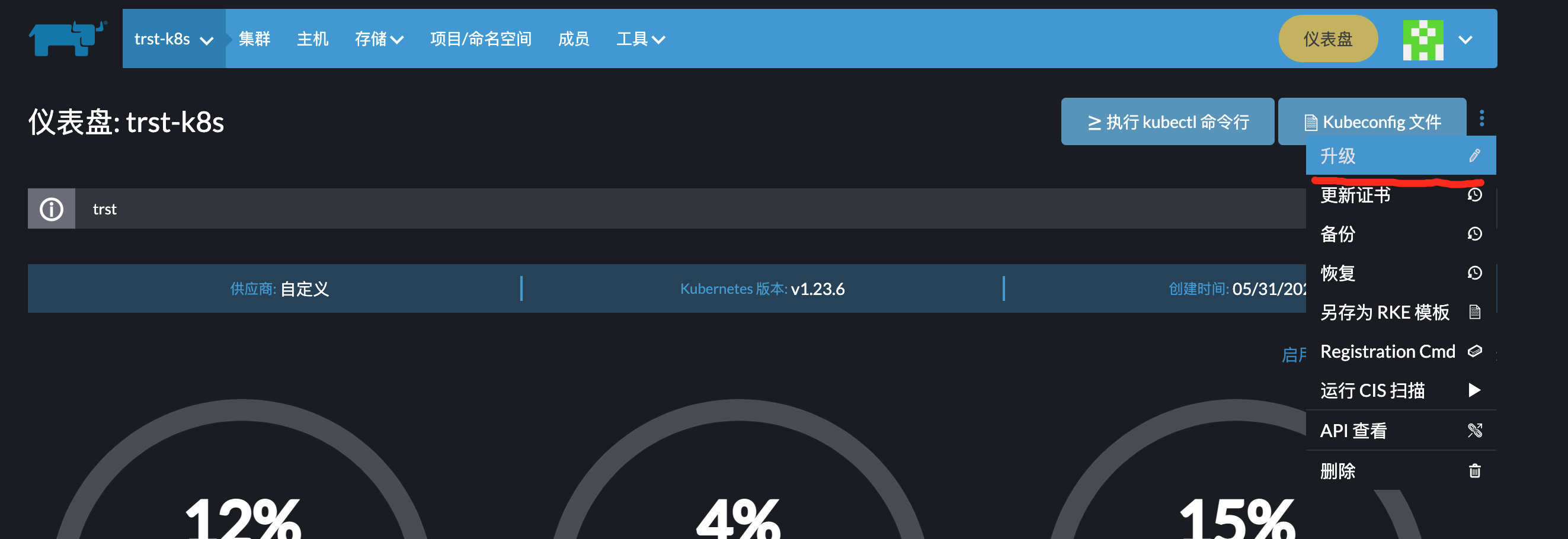
集群升级
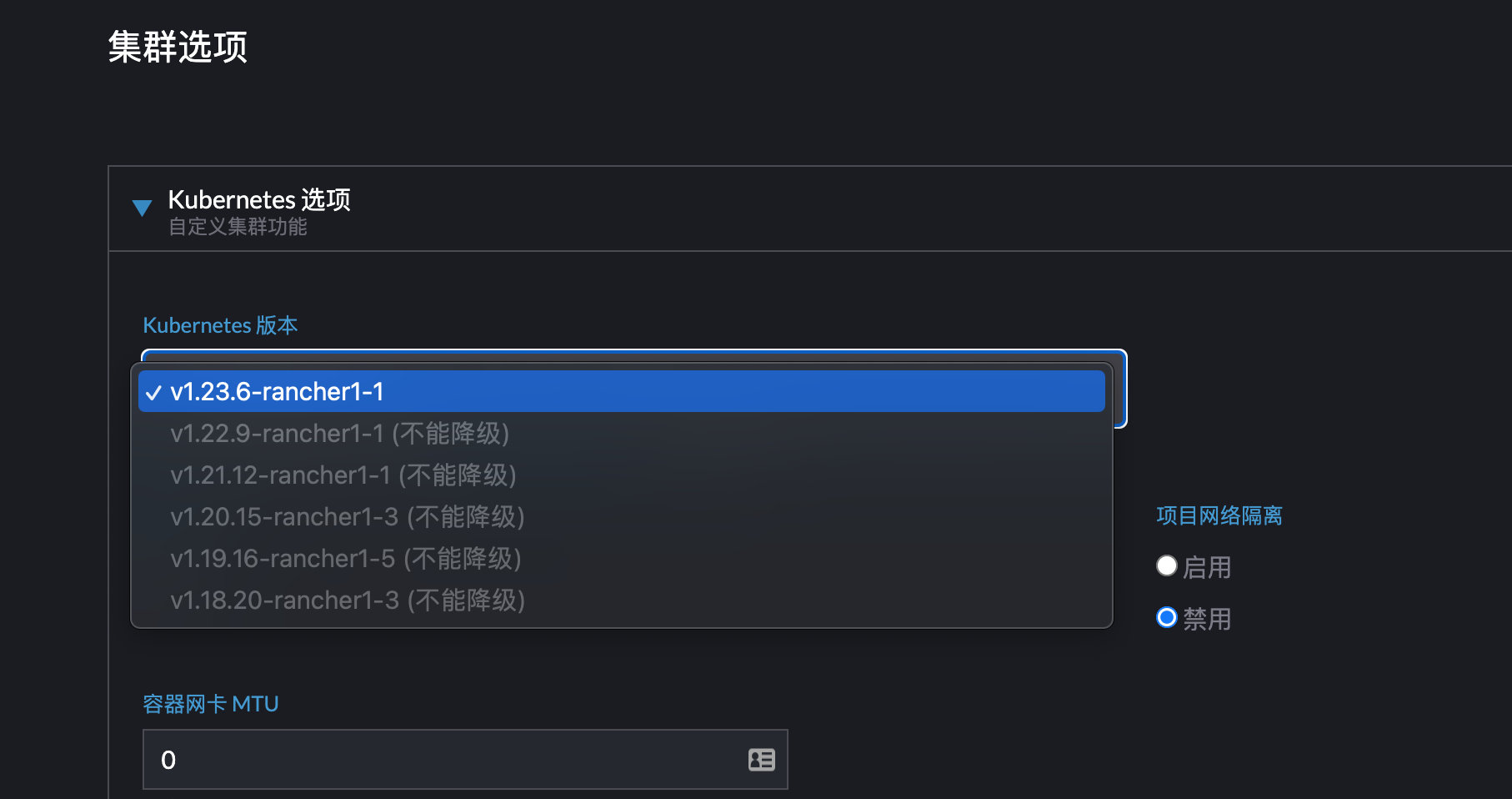
备份配置
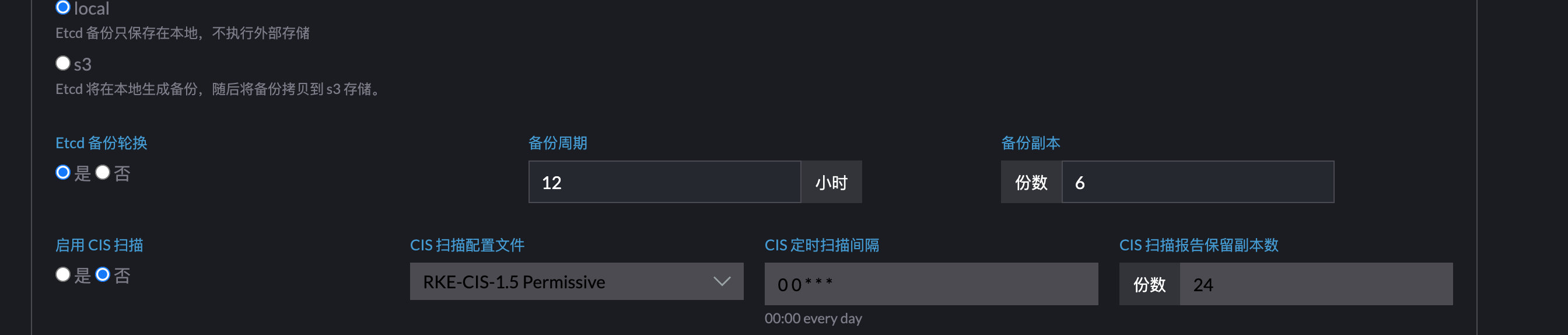
还原
选择集群
选择工具-> 备份,可以手动备份新的,或者根据时间选择还原
kubeadm创建的k8s
备份
安装etcd-client
1 | |
获得 trusted-ca-file、cert-file 和 key-file。通过etcd pod describe获得
1 | |
1 | |
最终
1 | |
-
最好不好直接复制${data-dir}/member/snap/db文件,还原时验证快照完整性,用命令会计算hash供恢复时候校验用。
-
不要轻易使用status check,会破坏数据库完整性
不然恢复时候报错
1
Error: expected sha256 [192 34 116 2 72 172 108 91 102 14 204 205 193 70 163 254 156 27 205 148 190 171 99 63 234 149 201 220 37 154 105 68], got [178 153 122 181 91 182 33110 230 141 239 175 40 71 74 48 165 184 179 124 41 121 133 130 18 145 113 190 86 163 186 184]
以上可以在恢复时候添加–skip-hash-check=true 参数
恢复
- 优先停掉所有api-server
- 恢复etcd
- 重启api-server
其实迁移重启所有的 组件 (e.g. kube-scheduler, kube-controller-manager, kubelet) ,以确保它们不依赖于一些陈旧的数据
停止前
1 | |
停止后

1 | |
恢复步骤
1 | |
升级
https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/ ,里面有旧版本的升级
升级工作的基本流程如下:
-
升级主控制平面节点
-
升级其他控制平面节点
-
升级工作节点
确定升级版本
1 | |
update control plane node
1 | |
其它控制面节点
1 | |
不需要执行 kubeadm upgrade plan 和更新 CNI 驱动插件的操作。
1 | |
update worker node
1 | |
工作原理
kubeadm upgrade apply 做了以下工作:
- 检查你的集群是否处于可升级状态:
- API 服务器是可访问的
- 所有节点处于
Ready状态 - 控制面是健康的
- 强制执行版本偏差策略。
- 确保控制面的镜像是可用的或可拉取到服务器上。
- 如果组件配置要求版本升级,则生成替代配置与/或使用用户提供的覆盖版本配置。
- 升级控制面组件或回滚(如果其中任何一个组件无法启动)。
- 应用新的
CoreDNS和kube-proxy清单,并强制创建所有必需的 RBAC 规则。 - 如果旧文件在 180 天后过期,将创建 API 服务器的新证书和密钥文件并备份旧文件。
kubeadm upgrade node 在其他控制平节点上执行以下操作:
- 从集群中获取 kubeadm
ClusterConfiguration。 - (可选操作)备份 kube-apiserver 证书。
- 升级控制平面组件的静态 Pod 清单。
- 为本节点升级 kubelet 配置
kubeadm upgrade node 在工作节点上完成以下工作:
- 从集群取回 kubeadm
ClusterConfiguration。 - 为本节点升级 kubelet 配置。