扩展模式
Kubernetes 是一个强大的并且内聚的可扩展系统。 常用的有如下扩展点:
- 二进制
kubelet插件,如 网络 (CNI)、设备、存储 (CSI)、容器运行时 (CRI) - 二进制
kubectl插件 - API server 中的访问扩展,例如 webhooks 的动态准入控制
- 自定义资源(CRD)和自定义 controller
- 自定义 API servers
- 调度器扩展,例如使用 webhook 来实现自己的调度决策
- 通过 webhook 进行 身份验证
Kubernetes 提供了很强的扩展能力,其本身的很多组件也是使用了这种扩展能力来实现的。controller 模式是 Kubernetes 编程中通用性最强,使用最多的扩展能力。
控制循环
Controller 实现控制循环,通过 API Server 监听集群的共享状态,根据资源的当前状态做出反应更改真实世界,使将资源更接近期望状态。
所有的控制器都按照以下逻辑运行:
-
由事件驱动来读取资源 (resources) 的状态 (state)。
-
更改集群内或集群外对象的状态 (state)。比如,启动一个 Pod,创建 Endpoint。
-
通过 API server 更新步骤 1 中的资源状态(status),存储到 etcd 中。
-
重复循环,返回步骤 1。
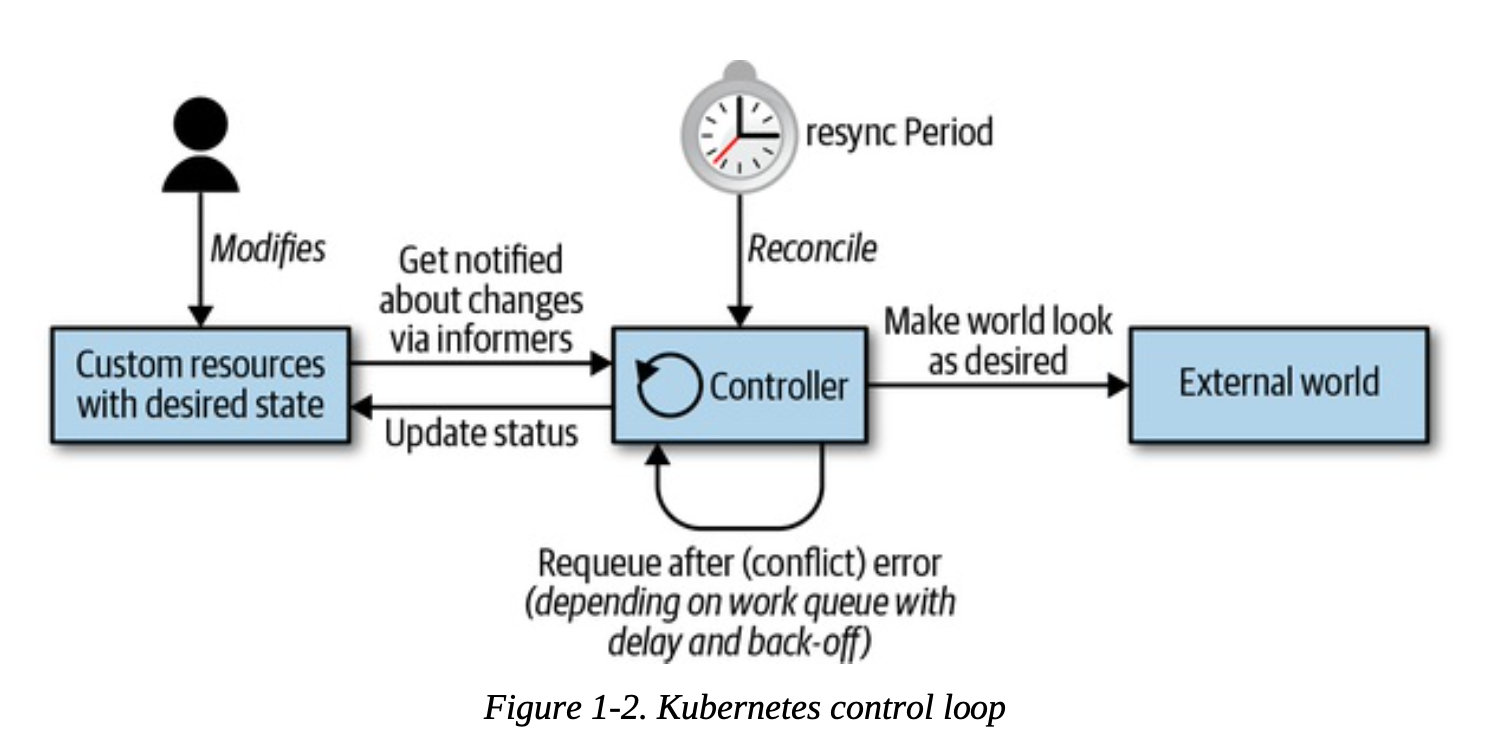
修改状态使用**Optimistic Concurrency,通过对比resource version,拒绝修改 **
1 | |
资源版本实际上是 etcd 键/值版本。每个对象的资源版本是 Kubernetes 中一个包含整数的字符串。这个整数直接来自 etcd。 etcd 维护计数器value每次增加,key由保存对象的序列化。
conflict errors are totally normal in controllers. Always expect them and handle them gracefully.
这个逻辑适合level-based logic,下一次循环会用最新的状态,自动从失败中恢复。
Events
通过 deployment 来启动 pod,就涉及到许多 controller 和其他控制平面组件协同工作:
- Deployment controller(在 kube-controller-manager 内部)感知到(通过 deployment informer)用户创建了一个 deployment。根据其业务逻辑,它将创建一个 replica set。
- Replica set controller(同样在 kube-controller-manager 内部)感知到(通过 replica set informer)新的 replica set 被创建了。并随后运行其业务逻辑,它将创建一个 pod 对象。
- Scheduler(在 kube-scheduler 二进制文件内部)——同样是一个 controller,感知到(通过 pod informer)pod 设置了一个空的 spec.nodeName 字段。根据其业务逻辑,它将该 pod 放入其调度队列中。
- 与此同时,另一个 controller kubelet(通过其 pod informer)感知到有新的 pod 出现,但是新 pod 的 spec.nodeName 字段为空,因此与 kubelet 的 node name 不匹配。它会忽视该 pod 并返回休眠状态(直到下一个事件)。
- Scheduler 更新 pod 中的 spec.nodeName 字段,并将该字段写入 API server,由此将 pod 从工作队列中移出,并调度到具有足够可用资源的 node 上。
- 由于 pod 的更新事件,kubelet 将被再次唤醒,这次再将 pod 的 spec.nodeName 与自己的 node name 进行比较,会发现是匹配的,接着 kubelet 将启动 pod 中的容器,并将容器已启动的信息写入 pod status 中, 由此上报给 API server。
- Replica set controller 会感知到已更新的 pod,但并不会做什么。
- 如果 pod 终止,kubelet 将感知到该事件,进而从 API server 获取 pod 对象,并把 pod status 设置为 “terminated”,然后将其写回到 API server。
- Replica set controller 会感知到终止的 pod,并决定必须更换此 pod。它将在 API server 上删除终止了的 pod,然后创建一个新的 pod。
- 依此类推。
许多独立的控制循环只通过 API server 上对象的变化进行通信,这些变化通过 informer 触发事件。
- 边缘触发(edge-triggered) 每当状态变化时,触发一个事件
- 水平触发(level-triggered,也被称为条件触发)只要满足条件,就触发一个事件
前者效率更高,时延主要取决于控制器处理事件中工作线程的数量
后者就是轮询,时延发生在轮询间隔和api server响应速度,它不能随着对象的数量很好地扩展,由于涉及许多异步控制器,需要很长时延
k8s主要基于edge-driven triggers
k8s怎样应付错误(网络原因,controller bug,远程服务挂了)
-
只有边缘触发,state有可能丢
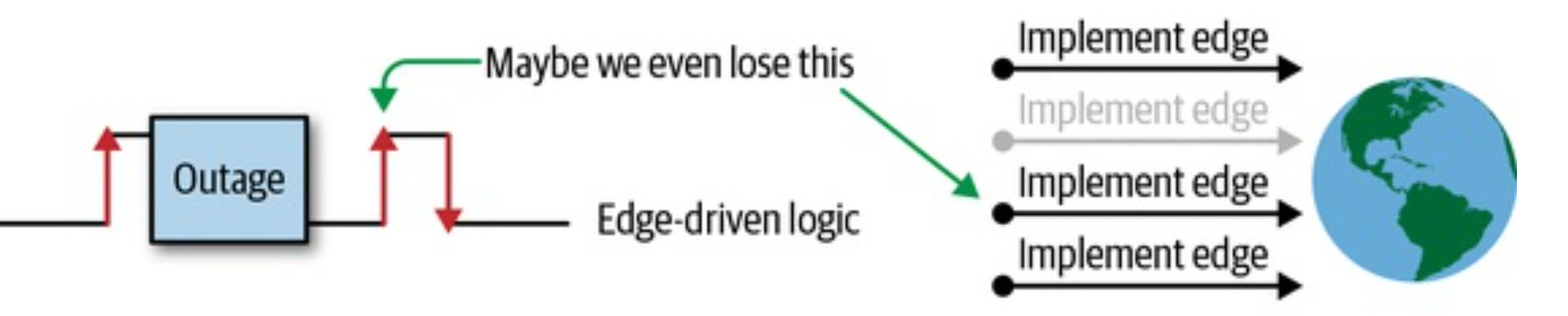
丢了的event不管它,会造成一些组件无法达到理想状态
-
边缘触发,通过轮询获取最新状态

当收到另一个事件时可以从错误中恢复,因它根据集群中的最新状态实现其逻辑。
-
加入定时resync
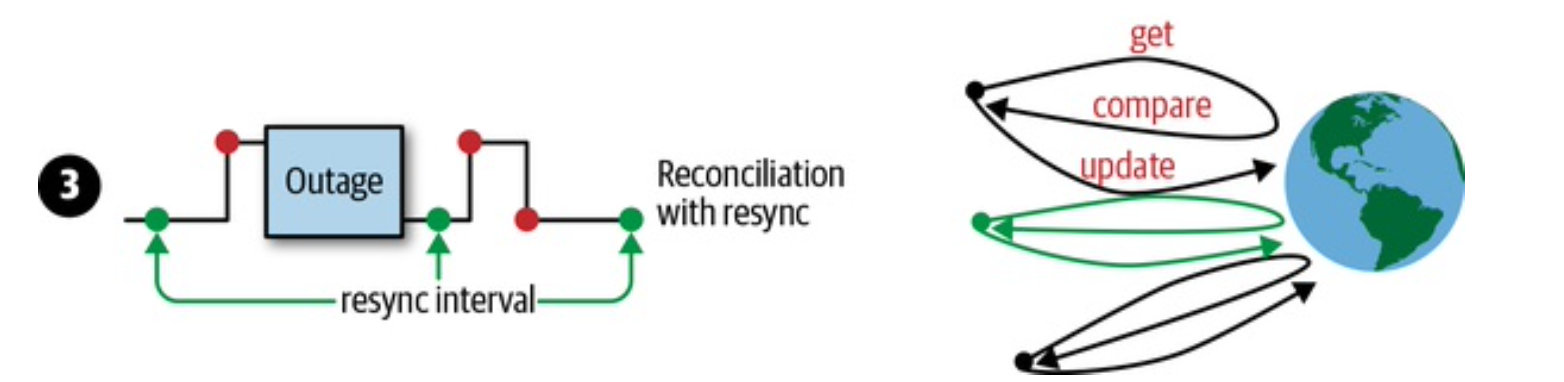
如果最后一个事件丢失了,后面没有事件来了,所以也不会去触发(Level-driven triggers),这个时候需要借助resync来得到最新的状态。k8s通常执行这个策略
Operators
就是自定义的controller
xxxxx
The API Server
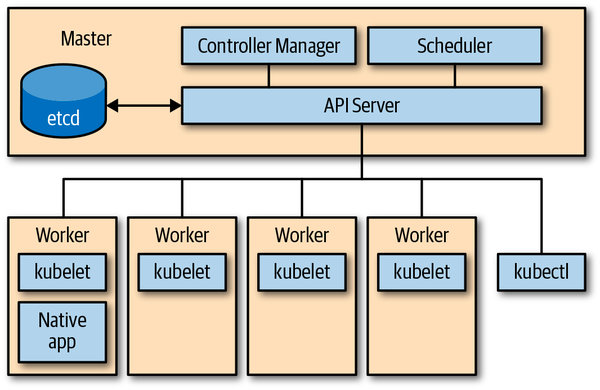
Kubernetes 由一堆不同角色的节点(集群中机器)组成,如下图所示:主节点的控制面由 API Server,controller manager 和 scheduler 组成。API Server 是系统的中央管理实体(central management entity),它是系统中唯一个与分布式存储组件 etcd 进行直接交互的组件。
主要完成以下任务:
- 所有的组件通过API Server来解耦,通过API Server来产生事件和消费事件。
- 负责对象的存储和读取,API Server最终还会和底层的etcd交互
- API Server负责给集群内部的组件做代理,例如对Kubernetes dashboard、strea logs、service ports、以及kubectl exec等
API Server HTTP 协议接口
- API server 使用 RESTful HTTP API
- 外部请求正常使用 json 格式
- 内部调用使用 protocol buffer ,为了更高的性能
- 使用 API 路径参数,如
GET /api/v1/namespaces/{namespace}/pods
使用 kubectl 指令列出当前命名空间下的 pods,kubectl -n *THENAMESPACE* get pods。实际上会发出 GET /api/v1/namespaces/THENAMESPACE/pods 的 HTTP 请求,通过 -v 6 参数能看到 HTTP 请求的 log。
I0804 10:55:47.463928 23997 loader.go:375] Config loaded from file: /root/.kube/config
...
...
I0804 10:55:51.689482 23997 round_trippers.go:443] GET https://172.24.28.3:6443/api/v1/namespaces/default/pods?limit=500 200 OK in 36 milliseconds
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 119 4d23h
redis-cli 1/1 Running 303 12d
API 术语
弄清楚什么是 RESTful 架构 就很容易理解和区分 Kubernetes API Server 里面这些概念。 如果一个架构符合 REST 原则,就称它为 RESTful 架构,REST 是 Representational State Transfer 的缩写,可以翻译为 “表现层状态转化”,这里省略了主语 “资源”(Resources)。 核心在于 “资源”,它是一种信息实体,可以有很多种外在表现形式,我们把 “资源” 具体呈现出来的形式,叫做它的 “表现层”(Representation)。
RESTful API 是基于 HTTP 协议且符合 REST 原则的软件架构,controller 架构也符合 REST 原则。在 Kubernetes 中同时使用了这两种架构,所以弄出来了一些术语来区分指代实体,其实都是 “资源” 这一信息实体在不同上下文中的不同表示形态。
| RESTful API | controller 架构 | |
|---|---|---|
| 实体类型 | Resource | Kind |
| 实现方式 | http | controller |
| 资源定位 | URL Path | GroupVersionKind |
Kind
表示实体的类型。每个对象都有一个字段 Kind(JSON 中的小写 kind,Golang 中的首字母大写 Kind),该字段告诉如 kubectl 之类的客户端它表示什么类型。
API group
在逻辑上相关的一组 Kind 集合。 如 Job 和 ScheduledJob 都在 batch API group 里。
Version
标示 API group 的版本更新, API group 会有多个版本 (version)。
- v1alpha1: 初次引入
- v1beta1: 升级改进
- v1: 开发完成毕业
在持续开发中,对象会发生变化,便用 Version 来标示版本变化。 对象会存储所有版本的对象属性的并集。但是在取出时指定版本,即只会取出这个版本所需要的对象定义。
Resource
通常是小写的复数词(例如,pod),用于标识一组 HTTP 端点(路径),来对外暴露 CURD 操作。
GVR
Resource 和 API group、Version 一起称为 GroupVersionResource(GVR),来唯一标示一个 HTTP 路径。

声明式状态管理
controller 模式能运作的另一大原因是声明式状态管理,它规定资源必须要有在 spec 中定义的期望状态(desired state), 和由 controller 补充的当前状态(current status),填写在 status 中。
spec 定义的期望状态提供了实现 “infrastructure-as-code” 的基础,让 controller 可以在 event 触发、水平获取、定时同步的时候都可以获取到资源的期望状态。另一方面 status 的设计让 controller 了解到资源当前状态,进而作出操作来调协资源的当前状态与期望状态,再将调协后的当前状态写入 status。这种设计完全可以仍受因网络分区等原因造成的数据短暂不一致问题。
举个例子,在一个 deployment 里你可能指定想要 20 个应用程序的副本(replicas)持续运行。deployment controller 作为控制面中 controller manager 的一部分,将读取你提供的 deployment spec,并创建一个 replica set 用于管理这些副本,再由 replicat set 来负责创建对应数量的 pods,最终结果是在工作节点上启动容器。如果任何的副本挂了,deployment controller 让你通过 status 可以感知到。这就是我们说的声明式状态管理(declarative state management),简而言之,就是声明期望的状态,剩下的交给 Kubernetes。
api 处理过程
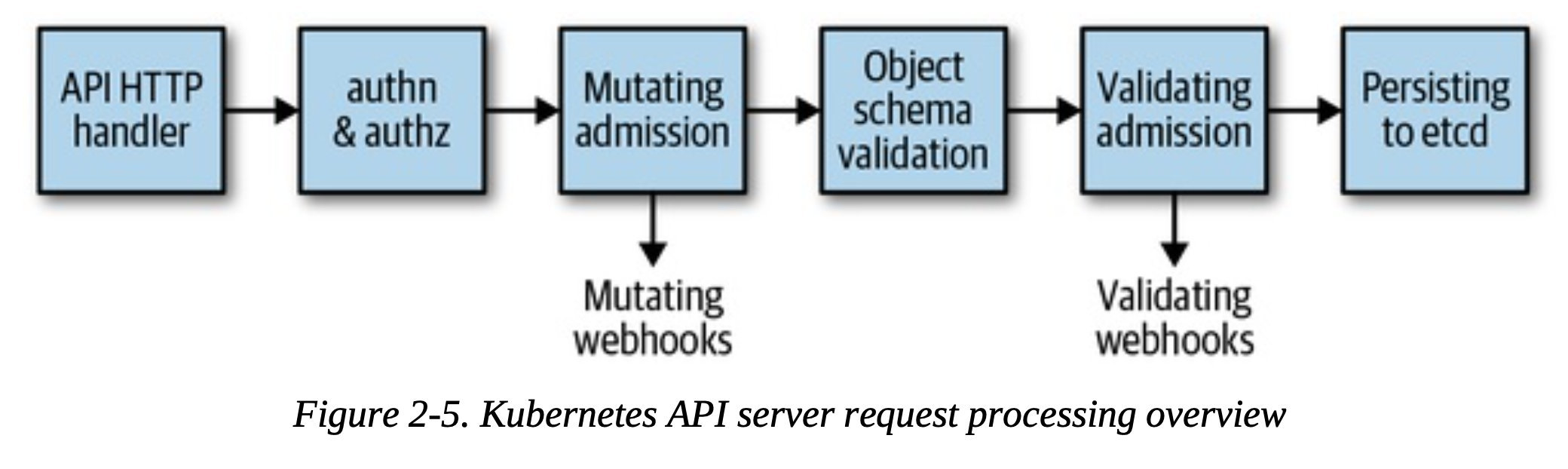
-
http request 会被DefaultBuildHandlerChain()里面的一系列过滤条件,failed return 401
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15func DefaultBuildHandlerChain(apiHandler http.Handler, c *Config) http.Handler { h := WithAuthorization(apiHandler, c.Authorization.Authorizer, c.Serializer) h = WithMaxInFlightLimit(h, c.MaxRequestsInFlight, c.MaxMutatingRequestsInFlight, c.LongRunningFunc) h = WithImpersonation(h, c.Authorization.Authorizer, c.Serializer) h = WithAudit(h, c.AuditBackend, c.AuditPolicyChecker, LongRunningFunc) ... h = WithAuthentication(h, c.Authentication.Authenticator, failed, ...) h = WithCORS(h, c.CorsAllowedOriginList, nil, nil, nil, "true") h = WithTimeoutForNonLongRunningRequests(h, LongRunningFunc, RequestTimeout) h = WithWaitGroup(h, c.LongRunningFunc, c.HandlerChainWaitGroup) h = WithRequestInfo(h, c.RequestInfoResolver) h = WithPanicRecovery(h) return h } - 根据HTTP path走到分发器,通过分发器来路由到最终的handler
- 每个API group注册一个handler
Informers and Caching
SharedInformerFactory
Informers通过watch接口实现Cachae和增量更新。并能够很好的处理网络抖动,断网等场景。尽可能的每一种资源类型只创建一个Informers,否则会导致资源的浪费。
一个GroupVersionResource一个informer,为了Shared Informer,使用SharedInformerFactory创建informer。
SharedInformerFactory允许informer 在应用程序中共享相同的资源,换句话说,不同的控制循环可以在后台使用相同的监视连接到 API 服务器,即使有若干个ctronller,每种resource只有一个informer。
尽量使用SharedInformerFactory,不然可能会在某处为同一资源打开多个监视连接。
1 | |
在改变一个对象之前,总是问自己谁拥有这个对象或其中的数据结构
- Informers and listers 拥有他们返回的对象,所以consumers在改变前要先deep-copy
- Clients返回的新对象归调用者拥有。
- Conversions返回共享对象。如果调用者确实拥有输入对象,则它不拥有输出。
不要直接用poll watch
内存cache,为了缓解controller每次修改对象访问api server产生的高负载,此外,informers 可以几乎实时地对对象的变化做出反应,而不需要轮询请求。
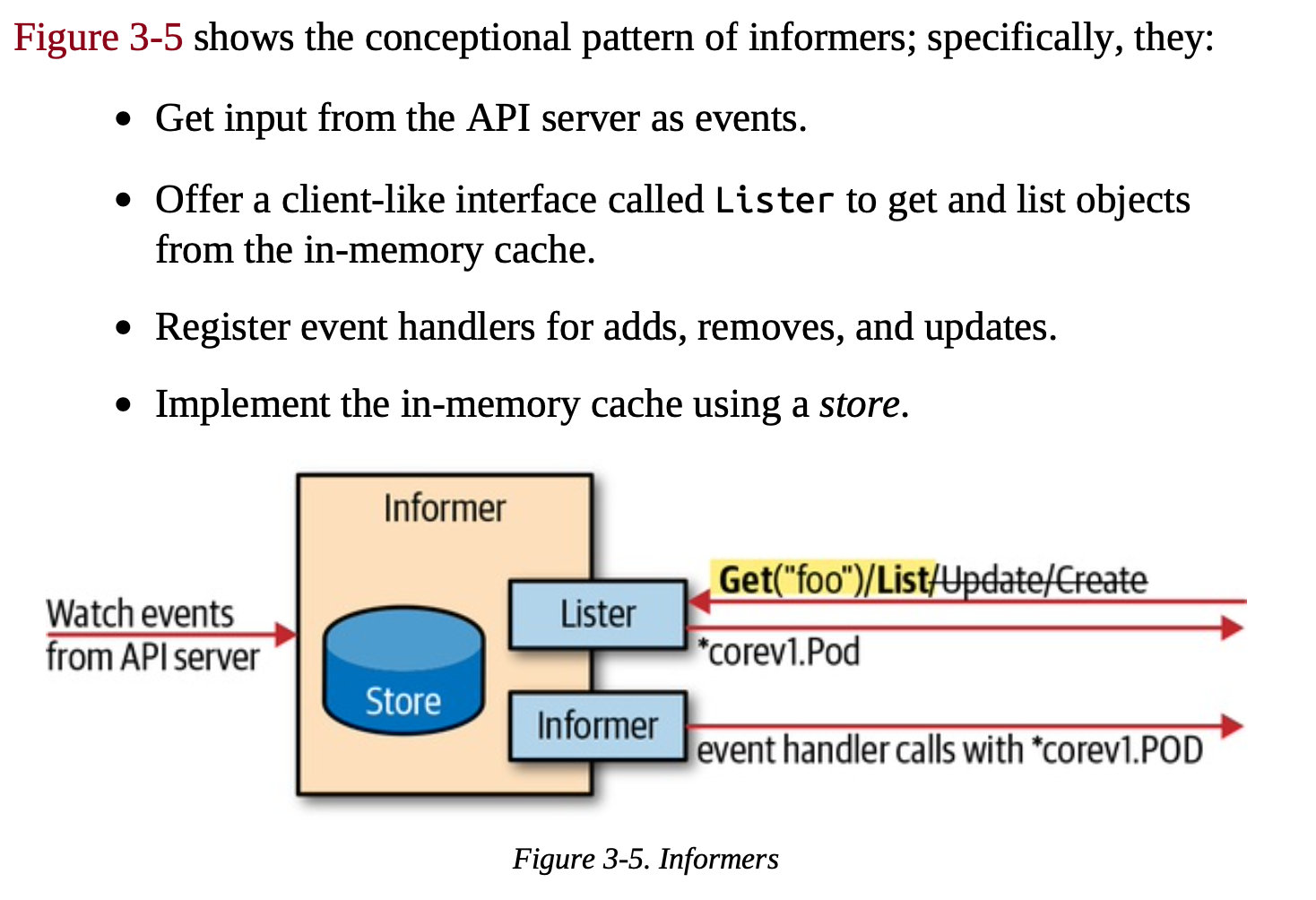
当长时间运行的 watch 连接中断时,Informers尝试用发起另一个 watch 请求从错误中恢复,在不丢失任何事件的情况下拾取事件流。
如果中断时间很长,新的watch连接成功前,etcd把event清空了导致api server丢失事件,Informers会重新列出所有对象,然后会有个周期resync(可配置间隔),内存缓存和业务逻辑之间进行协调,每次都会为所有对象调用已注册的handler
这个resync是纯内存的操作,不会触发对系统的调用,曾经不是这样的,现在的watch错误处理机制,改进到足以使重新列表变得不必要。
Event broadcaster
Event事件管理机制主要有三部分组成:
- EventRecorder:是事件生成者,k8s组件通过调用它的方法来生成事件;
- EventBroadcaster:事件广播器,负责消费EventRecorder产生的事件,然后分发给broadcasterWatcher
- broadcasterWatcher:用于定义事件的处理方式,如上报apiserver;
1 | |
Work Queue
1 | |
The following queue types are derived from this generic interface:
DelayingInterface can add an item at a later time. This makes it easier to requeue items after failures without ending up in a hot-loop:
1 | |
RateLimitingInterface rate-limits items being added to the queue. It extends the DelayingInterface:
1 | |
Most interesting here is the Forget(item) method: it resets the back-off of the given item. Usually, it will be called when an item
has been processed successfully.
The rate limiting algorithm can be passed to the constructor NewRateLimitingQueue. There are several rate limiters defined in the same package, such as the BucketRateLimiter, the ItemExponentialFailureRateLimiter, the ItemFastSlowRateLimiter, and the MaxOfRateLimiter. For more details, you can refer to the package documentation. Most controllers will just use the DefaultControllerRateLimiter() *RateLimiter functions, which gives:
An exponential back-off starting at 5 ms and going up to 1,000 seconds, doubling the delay on each error
A maximal rate of 10 items per second and 100 items burst
Depending on the context, you might want to customize the values. A 1,000 seconds maximal back-off per item is a lot for certain controller applications.
WorkQueue称为工作队列,Kubernetes的WorkQueue队列与普通FIFO(先进先出,First-In, First-Out)队列相比,实现略显复杂,它的主要功能在于标记和去重,并支持如下特性。
主要功能在于标记和去重,并支持如下特性。
-
有序:按照添加顺序处理元素(item)。
- 去重:相同元素在同一时间不会被重复处理,例如一个元素在处理之前被添加了多次,它只会被处理一次。
- 并发性:多生产者和多消费者。
- 标记机制:支持标记功能,标记一个元素是否被处理,也允许元素在处理时重新排队。
- 通知机制:ShutDown方法通过信号量通知队列不再接收新的元素,并通知metric goroutine退出。
- 延迟:支持延迟队列,延迟一段时间后再将元素存入队列。
- 限速:支持限速队列,元素存入队列时进行速率限制。限制一个元素被重新排队(Reenqueued)的次数。
- Metric:支持metric监控指标,可用于Prometheus监控。
WorkQueue支持3种队列,并提供了3种接口,不同队列实现可应对不同的使用场景,分别介绍如下。
- Interface:FIFO队列接口,先进先出队列,并支持去重机制。
- DelayingInterface:延迟队列接口,基于Interface接口封装,延迟一段时间后再将元素存入队列。
- RateLimitingInterface:限速队列接口,基于DelayingInterface接口封装,支持元素存入队列时进行速率限制。
crd
建立过程
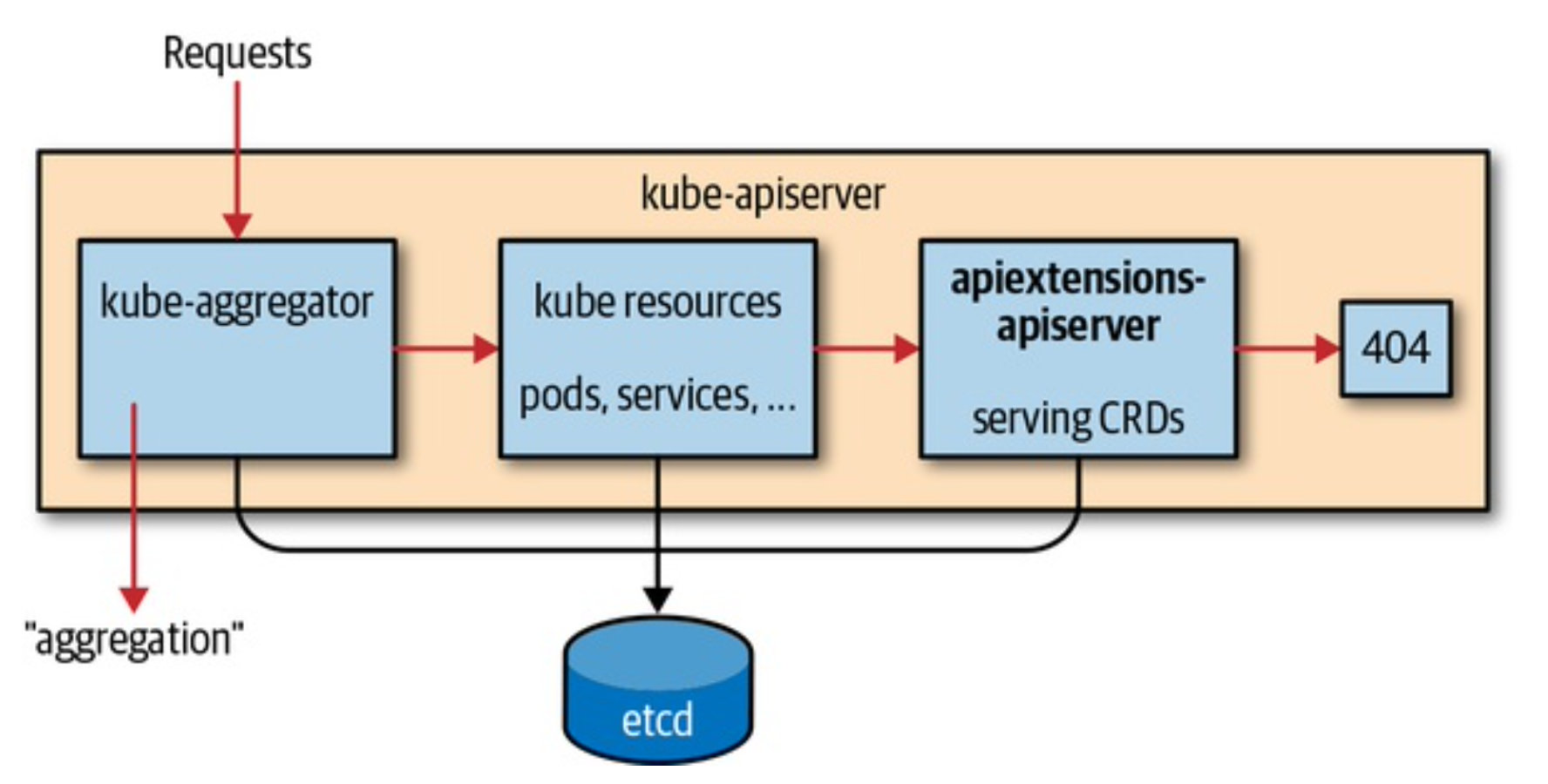
crd的创建由api server里面的apiextensions-apiserver处理,将检查名称并确定它们是否冲突,是否其他资源或它们本身是否一致。
cr创建由apiextensions-apiserver根据 OpenAPI v3 schema检验失败返回400
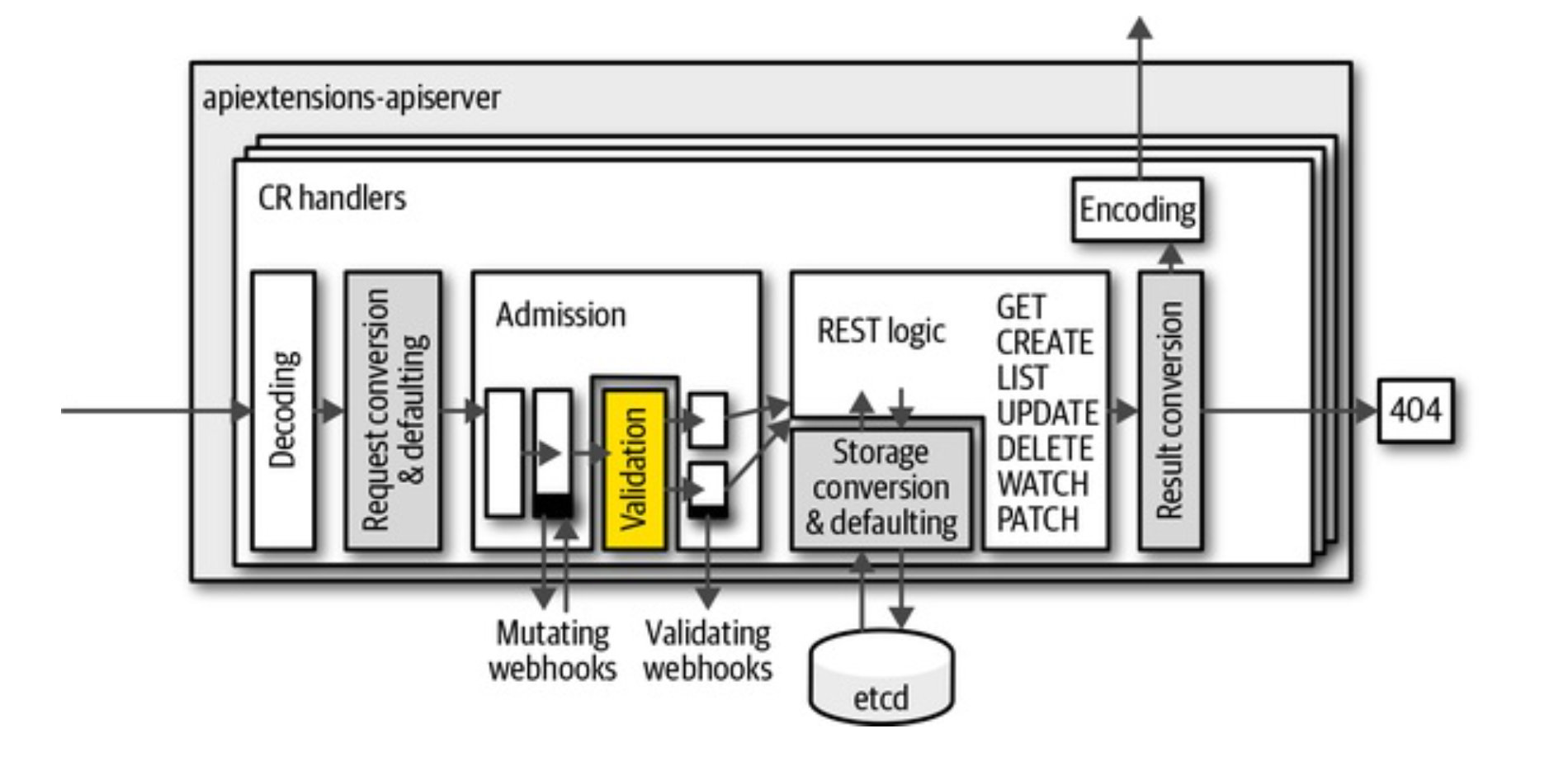
发现自定义资源
- kubectl 通过/apis询问Api server所有的 API group
- kubectl 通过/apis/group/version 查看所有的group存在的资源,找到对应资源所在的Group、VersionheResources

kubectl 会维护一个缓存在~/.kubectl,不必在每次访问时重新检索发现信息,10min失效一次。因此,CRD 的更改可能会在最多 10 分钟后显示在相应用户的 CLI 中。
1 | |
status子资源
-
The user usually should not write status fields.
-
The controller should not write specification fields.
1 | |
Automating Code Generation
deepcopy-gen生成func (t *T) DeepCopy() *T和func (t* T)DeepCopyInto(*T)两个方法client-gen创建带类型的client setsinformer-genlister-gen
通过上面四种代码生成器可以构建一个强大的控制器,除此之外还有conversion-gen和defaulter-gen两个生成器给编写aggregated API server提供便利。
1 | |
这些生成器如何生成代码是可以通过命令行参数来控制,也可以细粒度通过在代码中打tag的方式来控制,主要有两类tag
global tags,通常在一个pakcage中的doc.go文件中。
1 | |
local tags,通常在一个struct类型定义上。
1 | |
Solutions for Writing OPerators
1 | |
打包使用helm kustomisze打包
RABC控制最小权限
1 | |
custom API server
CRD的一些限制:
- 限制只能使用etcd作为存储
- 不支持protobuf,只能是JSON
- 只支持/status和/scale两种子资源
- 不支持graceful deletetion、尽管可以通过Finalizer来模拟,但是不支持指定graceful deletion time
- 对API Server的负载影响比较大,因为需要用通用的方式来实现所有正常资源需要走的逻辑和算法
- 只能实现CRUD基本语义
- 不支持同类资源的存储共享(比如不同API Group的相同资源底层不支持使用相同的存储)
相反一个自定义的API Server没有上面的限制。
- 可以使用任何存储,例如metrics API Server可以存储数据在内存中
- 可以提供protobuf支持
- 可以提供任意的子资源
- 可以实现graceful deletion
- 可以实现所有的操作
- 可以实现自定义语义,比如原子的分配ip,如果使用webbook的方式可能会因为后续的pipeline导致请求失败,这个时候分配的ip需要取消,但是webhook是没办法做撤销的,需要结合控制器来完成。这就是因为 webhook可能会产生副作用。
- 可以对底层类型相同的资源,进行共享存储。
自定义API Server工作流程:
聚合层在 kube-apiserver 进程内运行。在扩展资源注册之前,聚合层不做任何事情。 要注册 API,用户必须添加一个 APIService 对象,用它来“申领” Kubernetes API 中的 URL 路径。 自此以后,聚合层将会把发给该 API 路径的所有内容(例如 /apis/myextension.mycompany.io/v1/…) 转发到已注册的 APIService。
- K8s API server接收到请求
- 请求传递了handler chanin,这里面包含了鉴权、日志审计等
- 请求会走到kube-aggregator组件,这个组件知道哪些API 请求是需要走自定义API Server的,那些Group走API server这是API Service定义的。
- 转发请求给自定义API Server
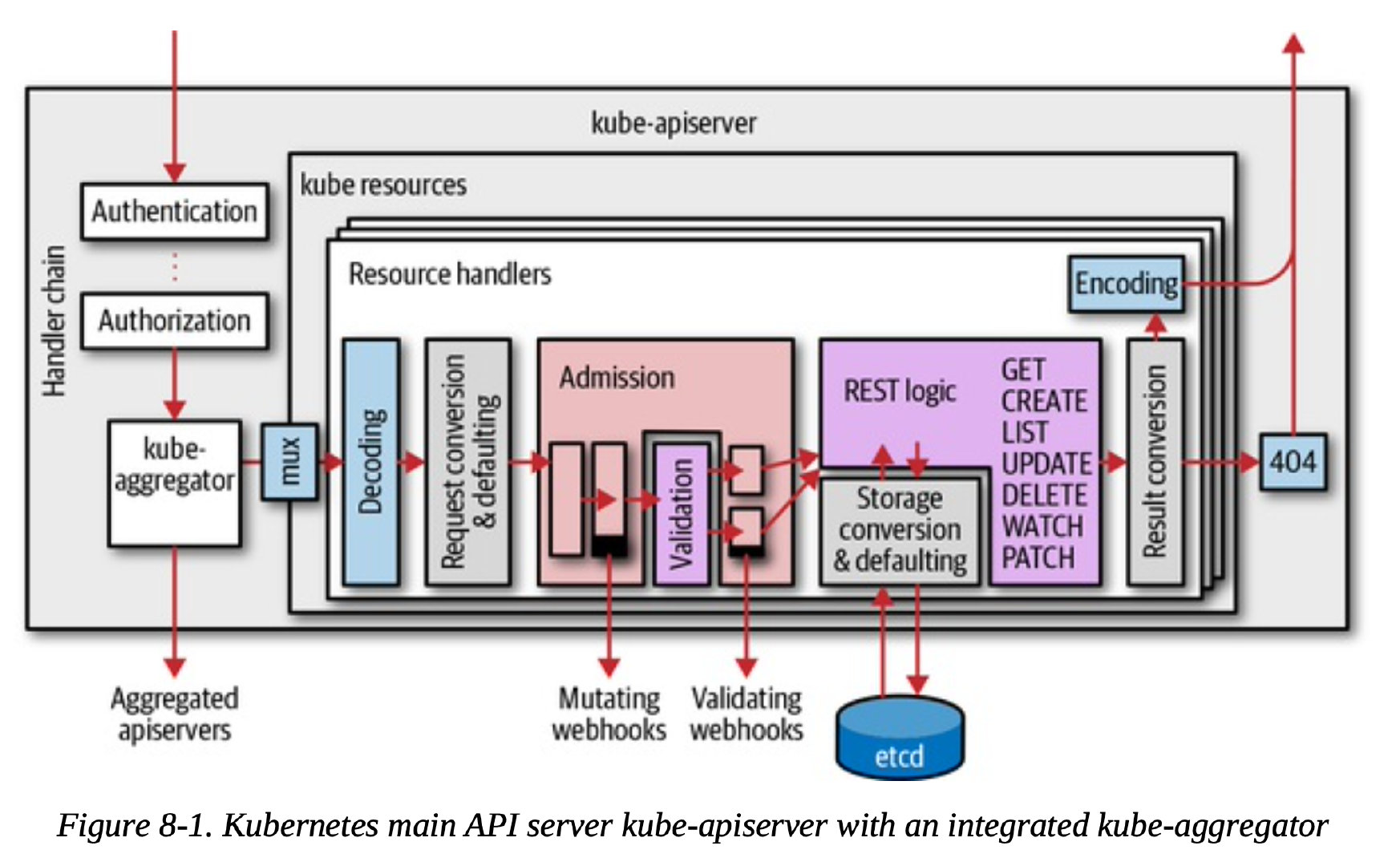
1 | |
APIService 资源类型的最初设计目标是将庞大的主 API Server 分解成多个小型但彼此独立的单元,但它也支持将任何遵循 Kubernetes API 接口设计规范的自定义 APIServer 聚合进主 API Server 中。APIService 是标准的 API 资源类型,它隶属于 apiregistration.k8s.io 资源群组。
API Server在内部给每一个资源都维护了一个内部版本,所有的版本都会转换成这个内部版本再去操作。
- 用户发送指定版本的请求给API server(比如v1)
- API server解码请求,然后转换为内部版本
- API server传递内部版本给admission 和 validation
- API server在registry中实现的逻辑是根据内部版本来实现的
- etcd读和写带有版本的对象(例如v2,存储版本),他将从内部版本进行转换。
- 最终结果会将转换为请求的版本,比如这里就是v1
对于基本类型如何区分默认的零值是设置了还是没有设置,比如bool默认是false,那用户到底是设置了false、还是没有设置导致默认值用了false呢? k8s通过指针来解决,如果有设置那么指针不为空,否则就是没有设置。