CRI 简介
在 CRI 出现之前(也就是 Kubernetes v1.5 之前),Docker 作为第一个容器运行时,Kubelet 通过内嵌的 dockershim 操作 Docker API 来操作容器,进而达到一个面向终态的效果。
随着running time越来越多,此时就有人站出来说,我们能不能对容器运行时的操作抽象出一个接口,将 Kubelet 代码与具体的容器运行时的实现代码解耦开,只要实现了这样一套接口,就能接入到 Kubernetes 的体系中,这就是我们后来见到的 Container Runtime Interface (CRI)。
CRI 接口的通信协议是 gRPC,这里的一个时代背景就是当时的 gRPC 刚刚开源,此外它的性能也是优于 http/REST 模式的。gRPC 不需要手写客户端代码和服务端代码,能够自动生成通信协议代码。
CRI实现
kubelet通过CRI(container runtime interface)的标准来与外部容器运行时进行交互。
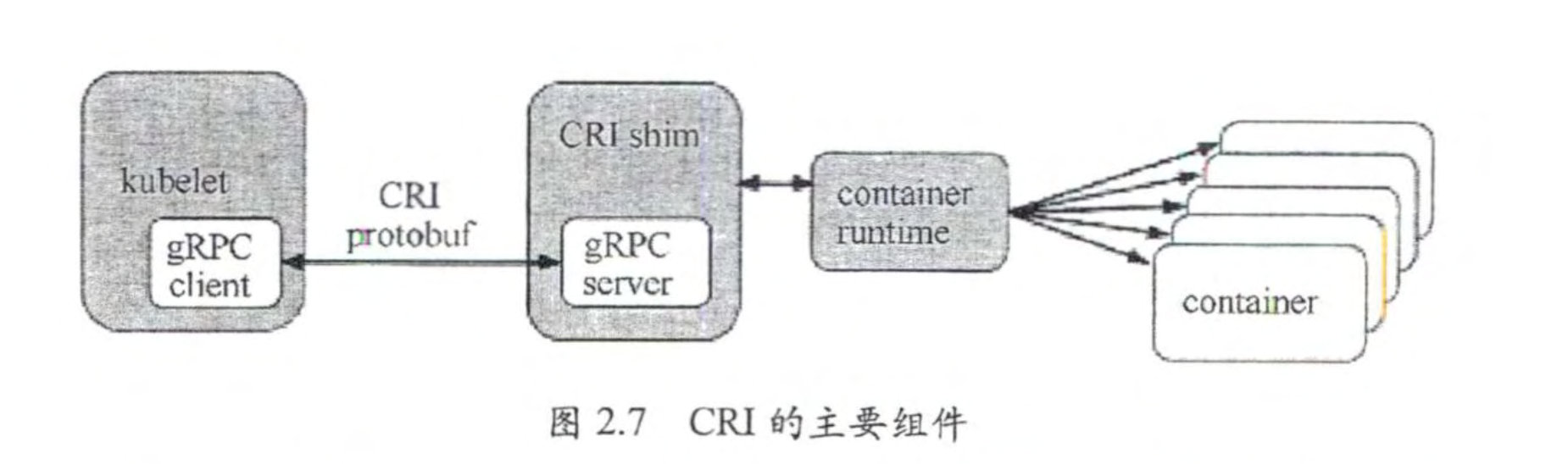
CRI主要定义两个接口, ImageService和RuntimeService。
ImageService:负责镜像的生命管理周期
- 查询镜像列表
- 拉取镜像到本地
- 查询镜像状态
- 删除本地镜像
- 查询镜像占用空间
RuntimeService:负责管理Pod和容器的生命周期
- PodSandbox 的管理接口 PodSandbox是对kubernete Pod的抽象,用来给容器提供一个隔离的环境(比如挂载到相同的cgroup下面)并提供网络等共享的命名空间.PodSandbox通常对应到一个Pause容器或者一台虚拟机
- Container 的管理接口 在指定的 PodSandbox 中创建、启动、停止和删除容器。
- Streaming API接口 包括Exec、Attach和PortForward 等三个和容器进行数据交互的接口,这三个接口返回的是运行时Streaming Server的URL,而不是直接跟容器交互(kubelet处理所有的请求连接, 使其有成为Node通信瓶 颈的可能。在设计 CRI 时,要让容器运行时能够跳过 中间过程。容器运行时可以启动一个 单独的流式服务来处理请求(还能对 Pod 的资源使用情况进行记录),并将服务地址返回 给 kubelet。 这样 kubelet就能反馈信息给 API Server, 使之可以直接连接到容器运行时提 供的服务,并连接到客户端 。)
- 状态接口 包括查询API版本和查询运行时状态
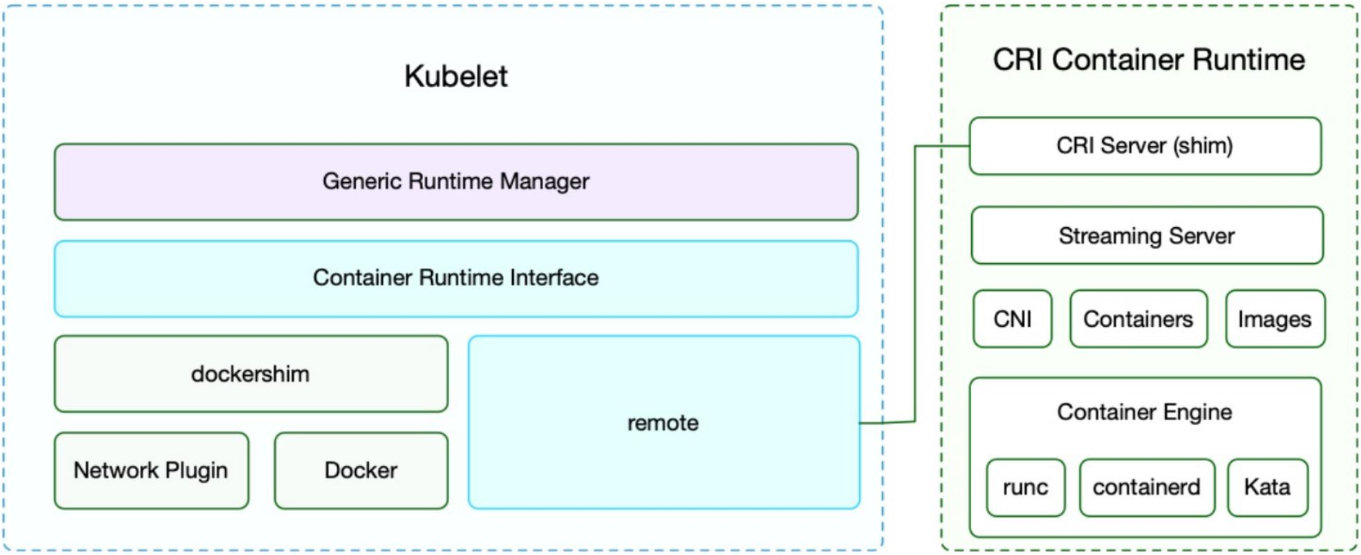
在引入了 CRI 接口之后,Kubelet 的架构如上图所示。
跟容器最相关的一个 Manager 是 Generic Runtime Manager,就是一个通用的运行时管理器。我们可以看到目前 dockershim 还是存在于 Kubelet 的代码中的,它是当前性能最稳定的一个容器运行时的实现。remote 指的就是 CRI 接口。
CRI 接口主要包含两个部分:
- 一个是 CRI Server,即通用的比如说创建、删除容器这样的接口
- 另外一个是流式数据的接口 Streaming Server,比如 exec、port-forward 这些流式数据的接口。
这里需要注意的是,我们的 CNI(容器网络接口)也是在 CRI 进行操作的,因为我们在创建 Pod 的时候需要同时创建网络资源然后注入到 Pod 中。接下来就是我们的容器和镜像。我们通过具体的容器创建引擎来创建一个具体的容器。
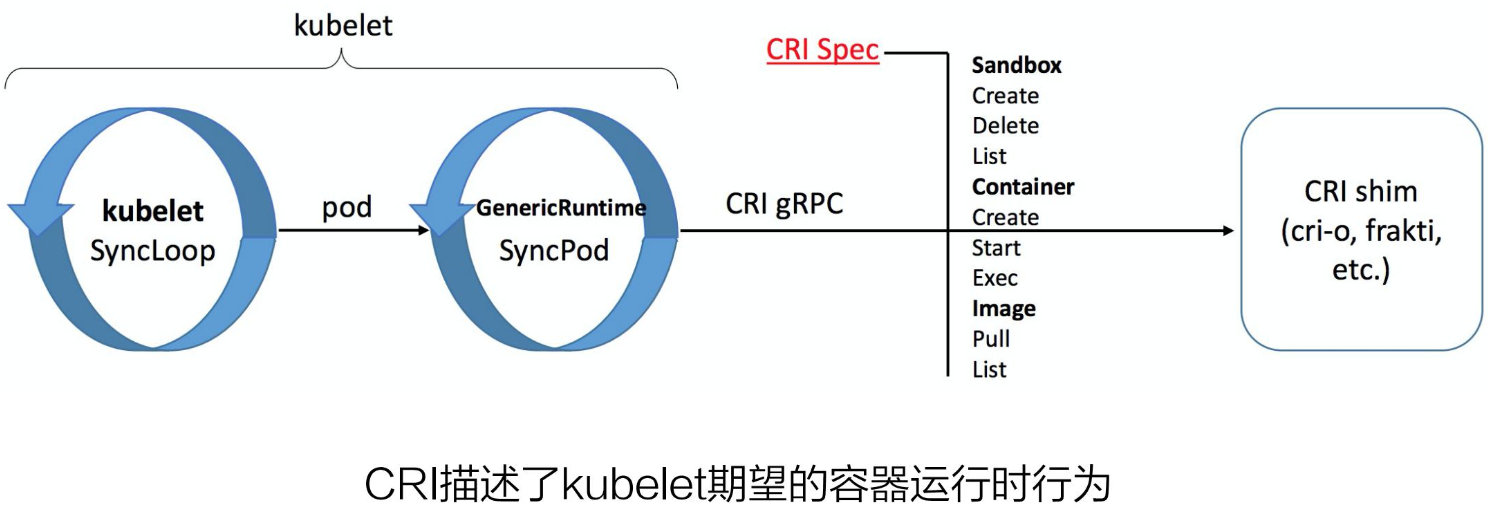
给大家介绍一下 CRI 接口的设计。我们知道 Kubernetes 的一个运作的机制是面向终态的,在每一次调协的循环中,Kubelet 会向 apiserver 获取调度到本 Node 的 Pod 的数据,再做一个面向终态的处理,以达到我们预期的状态。
循环的第一步,首先通过 List 接口拿到容器的状态,再通过 Sandbox 和 Container 接口来创建容器,另外还有镜像接口用来拉取容器镜像。CRI 描述了 Kubelet 期望的容器运行时行为,主要就是我们刚刚所说的 3 个部分。
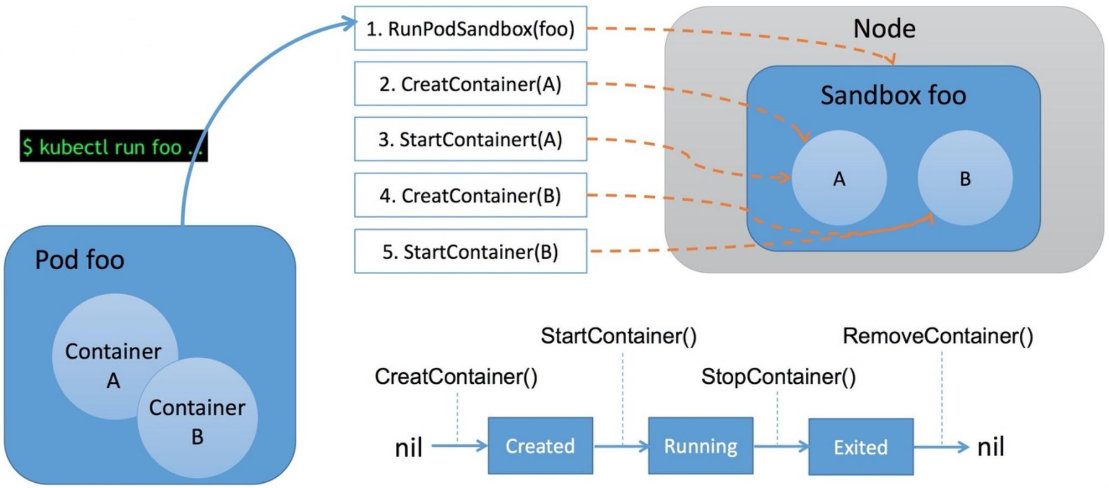
比方说我们通过 kubectl 命令来运行一个 Pod,那么 Kubelet 就会通过 CRI 执行以下操作:
- 首先调用 RunPodSandbox 接口来创建一个 Pod 容器,Pod 容器是用来持有容器的相关资源的,比如说网络空间、PID空间、进程空间等资源;
- 然后调用 CreatContainer 接口在 Pod 容器的空间创建业务容器;
- 再调用 StartContainer 接口启动容器,相对应的销毁容器的接口为 StopContainer 与 RemoveContainer。
CRI streaming 接口
这里给大家介绍一下 CRI 的流式接口 exec。它可以用来在容器内部执行一个命令,又或者说可以 attach 到容器的 IO 流中做各种交互式的命令。它的特别之处在于,一个是节省资源,另一个是连接的可靠性。
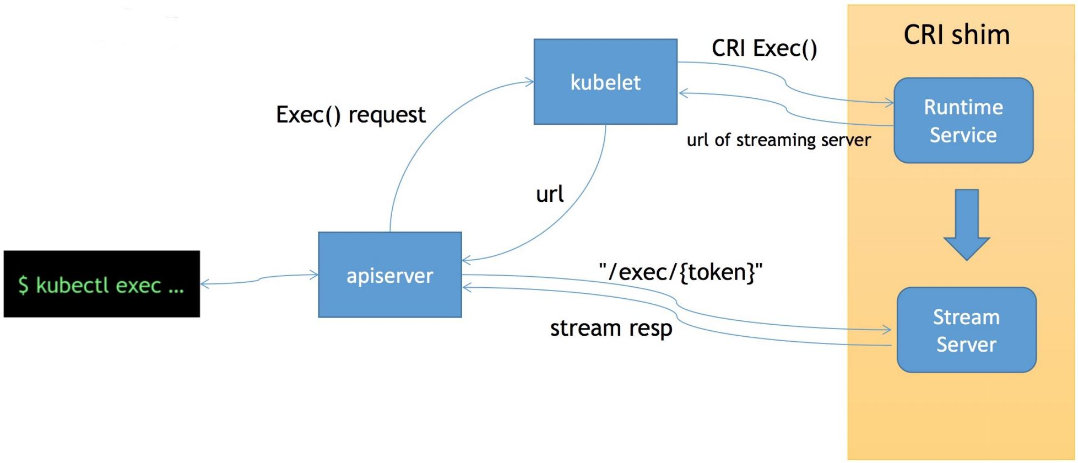
首先 exec 操作会发送到 apiserver,经过鉴权,apiserver 将对 Kubelet Server 发起 exec 的请求,然后 Kubelet 会调用 CRI 的 exec 接口将具体的请求发至容器的运行时。这个时候,容器运行时不是直接地在 exec 接口上来服务这次请求,而是通过我们的 streaming server 来异步地返回每一次执行的结果。也就是说 apiserver 其实实际上是跟 streaming server 交互来获取我们的流式数据的。这样一来让我们的整个 CRI Server 接口更轻量、更可靠。
CRI 的一些实现
目前 CRI 的一些实现:
- CRI-containerd
- CRI-O
- PouchContainer @alibaba
- …
CRI-containerd 是目前社区中比较主流的新一代 CRI 的实现,CRI-O 来自于红帽公司,PouchContainer 是由 alibaba 实现的 CRI,其它的 CRI 实现,这里就不一一介绍了。
CRI-containerd
下图是 CRI-containerd 的架构。
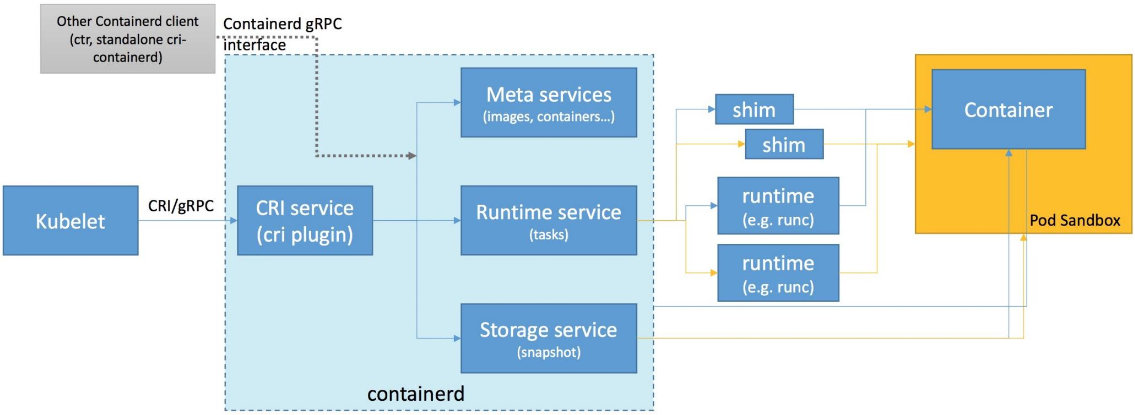
这套 CRI 接口是基于 containerd 实现的。在早期的实现中,CRI 其实是作为一个独立进程的,再跟 containerd 进行交互。这样一来又多了一层进程跟进程之间的开销,因此在后来的版本中 CRI 的是直接以插件的形式实现到 containerd 中的,成为了 containerd 的一部分,从而能够可插拔地使用 CRI 接口。
整个架构看起来非常直观。这里的 Meta services、Runtime service 与 Storage service 都是 containerd 提供的接口。它们是通用的容器相关的接口,包括镜像管理、容器运行时管理等。CRI 在这之上包装了一个 gRPC 的服务。右侧就是具体的容器的实现,比如说,创建容器时就要创建具体的 runtime 和它的 shim,它们和 Container 一起组成了一个 Pod Sandbox。
CRI-containerd 的一个好处是,containerd 还额外实现了更丰富的容器接口,所以它可以用 containerd 提供的 ctr 工具来调用这些丰富的容器运行时接口,而不只是 CRI 接口。
CRI-O
下图是 CRI-O 的实现思路。
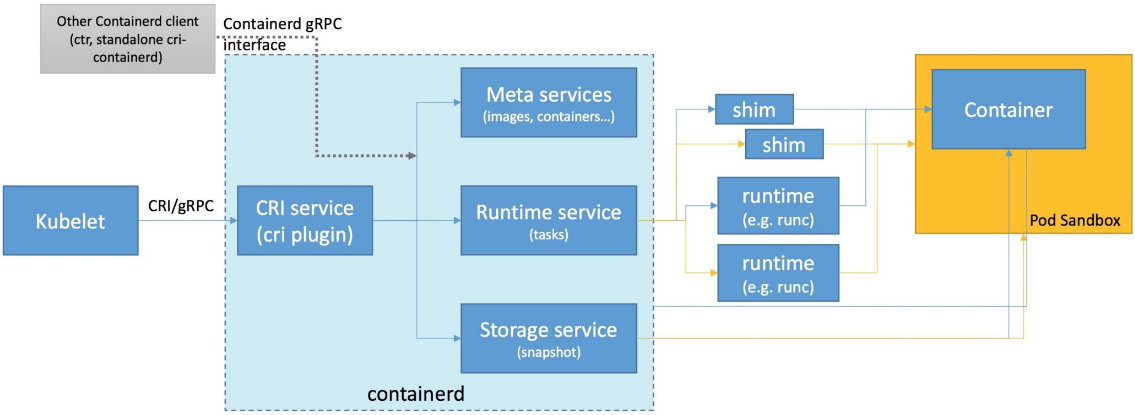
它是通过直接在 OCI 上包装容器接口来实现的一个 CRI 服务。它对外提供的只有具体的 CRI 接口,没有我们前面所提到的 containerd 提供的更丰富的接口。它主要包含两个部分,首先是对容器 runtime 的管理,另一个是对镜像的管理。
RuntimeClass
随着越来越多的容器运行时的出现,不同的容器运行时也有不同的需求场景,于是就有了多容器运行时的需求。但是,如何来运行多容器运行时还需要解决以下几个问题:
-
集群里有哪些可用的容器运行时?
-
如何为 Pod 选择合适的容器运行时?
-
如何让 Pod 调度到装有指定容器运行时的节点上?
-
容器运行时在运行容器时会产生有一些业务运行以外的额外开销,这种「额外开销」需要怎么统计?
RuntimeClass 的大致工作流程
为了解决上述提到的问题,社区推出了 RuntimeClass。它其实在 Kubernetes v1.12 中就已被引入,不过最初是以 CRD 的形式引入的。v1.14 之后,它又作为一种内置集群资源对象 RuntimeClas 被引入进来。v1.16 又在 v1.14 的基础上扩充了 Scheduling 和 Overhead 的能力。
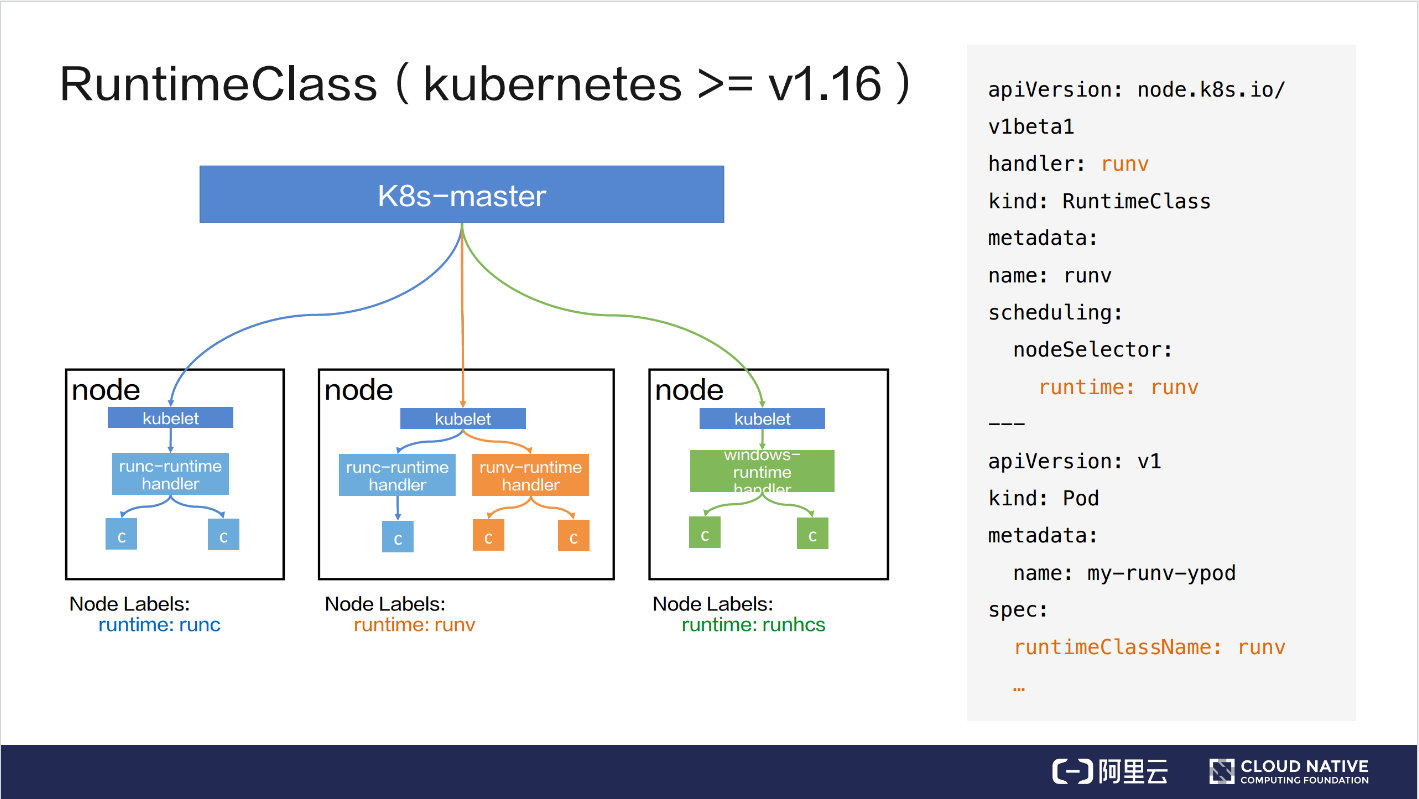
下面以 v1.16 版本为例,讲解一下 Runtime 的工作流程。如上图所示,左侧是它的工作流程图,右侧是一个 YAML 文件。
YAML 文件包含两个部分,上部分负责创建一个名字叫 runv 的 RuntimeClass 对象,下部分负责创建一个 Pod,该Pod 通过 spec.runtimeClassName 引用了 runv 这个 RuntimeClass。
RuntimeClass 对象中比较核心的是 handler,它表示一个接收创建容器请求的程序,同时也对应一个容器运行时。比如说,比如示例中的 Pod 最终会被 runv 容器运行时创建容器;scheduling 决定 Pod 最终会被调度到哪些节点上。
结合左图来说明一下 RuntimeClass 的工作流程:
- K8s-master 接收到创建 Pod 的请求
- 方格部分表示三种类型的节点。每个节点上都有 Label 标识当前节点支持的容器运行时,节点内会有一个或多个 handel,每个 handle 对应一种容器运行时。比如第二个方格表示节点内有支持 runc 和 runv 两种容器运行时的 handler;第三个方格表示节点内有支持 runhcs 容器运行时的 handler
- 根据 scheduling.nodeSelector, Pod 最终会调度到中间方格节点上,并最终由 runv handler 来创建 Pod
RuntimeClass 功能介绍

我们还是以 Kubernetes v1.16 版本中的 RuntimeClass 为例。首先介绍一下 RuntimeClass 的结构体定义。
一个 RuntimeClass 对象代表了一个容器运行时,它的结构体中主要包含 Handler, Overhead, Scheduling 三个字段。在之前的例子中我们已提到过 Handler,它表示一个接收创建容器请求的程序,同时也对应一个容器运行时;Overhead 是 v1.16 中才引入的一个新的字段,它表示 Pod 中的业务运行所需资源以外的额外开销;第三个字段Scheduling 也是在 v1.16 中被引入的,该 Scheduling 配置会被自动注入到 Pod 的 nodeSelector 中。
RuntimeClass 资源定义例子
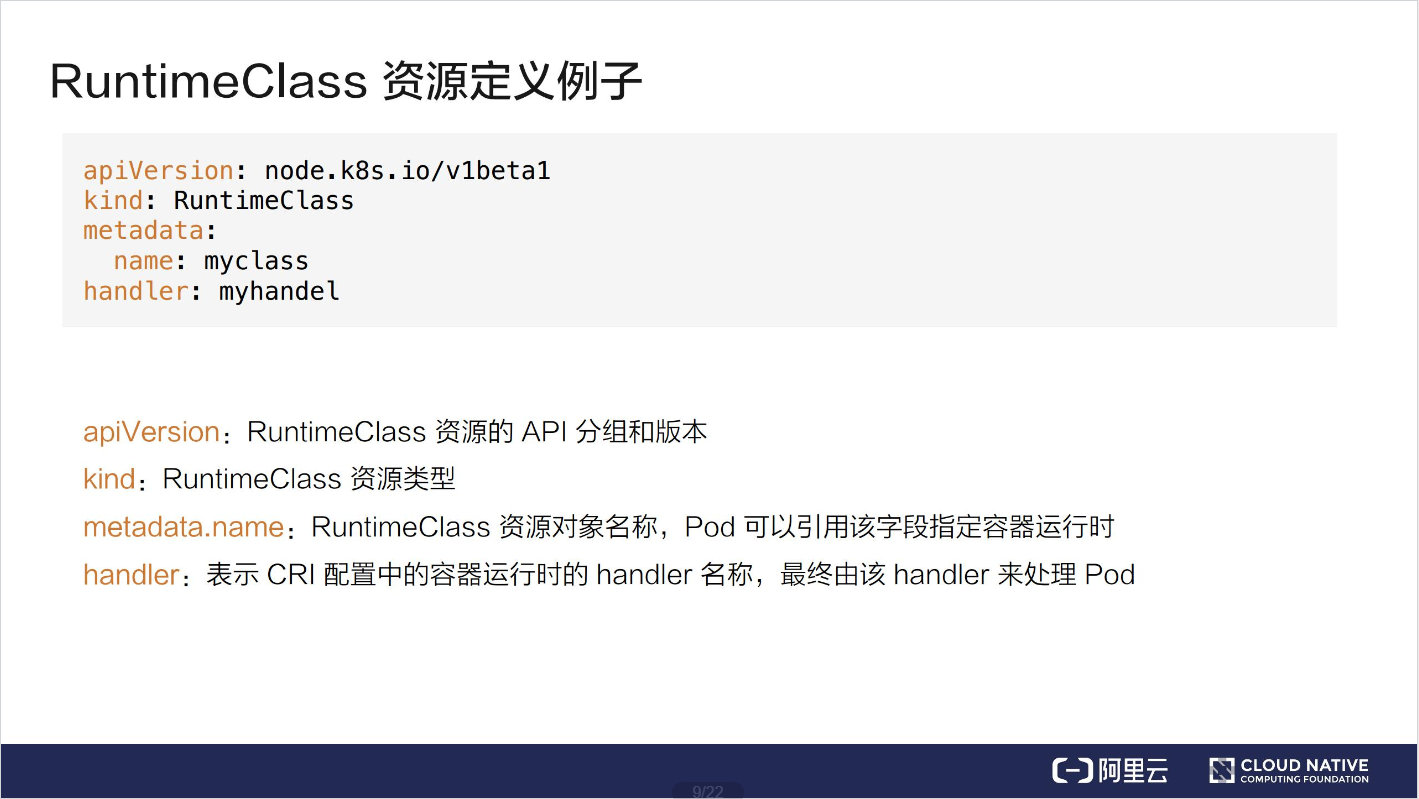
在 Pod 中引用 RuntimeClass 的用法非常简单,只要在 runtimeClassName 字段中配置好 RuntimeClass 的名字,就可以把这个 RuntimeClass 引入进来。
-
Scheduling 结构体的定义
顾名思义,Scheduling 表示调度,但这里的调度不是说 RuntimeClass 对象本身的调度,而是会影响到引用了 RuntimeClass 的 Pod 的调度。

Scheduling 中包含了两个字段,NodeSelector 和 Tolerations。这两个和 Pod 本身所包含的 NodeSelector 和 Tolerations 是极为相似的。
NodeSelector 代表的是支持该 RuntimeClass 的节点上应该有的 label 列表。一个 Pod 引用了该 RuntimeClass 后,RuntimeClass admission 会把该 label 列表与 Pod 中的 label 列表做一次合并。如果这两个 label 中有冲突的,会被 admission 拒绝。这里的冲突是指它们的 key 相同,但是 value 不相同,这种情况就会被 admission 拒绝。另外需要注意的是,RuntimeClass 并不会自动为 Node 设置 label,需要用户在使用前提前设置好。
Tolerations 表示 RuntimeClass 的容忍列表。一个 Pod 引用该 RuntimeClass 之后,admission 也会把 toleration 列表与 Pod 中的 toleration 列表做一个合并。如果这两处的 Toleration 有相同的容忍配置,就会将其合并成一个。
为什么引入 Pod Overhead?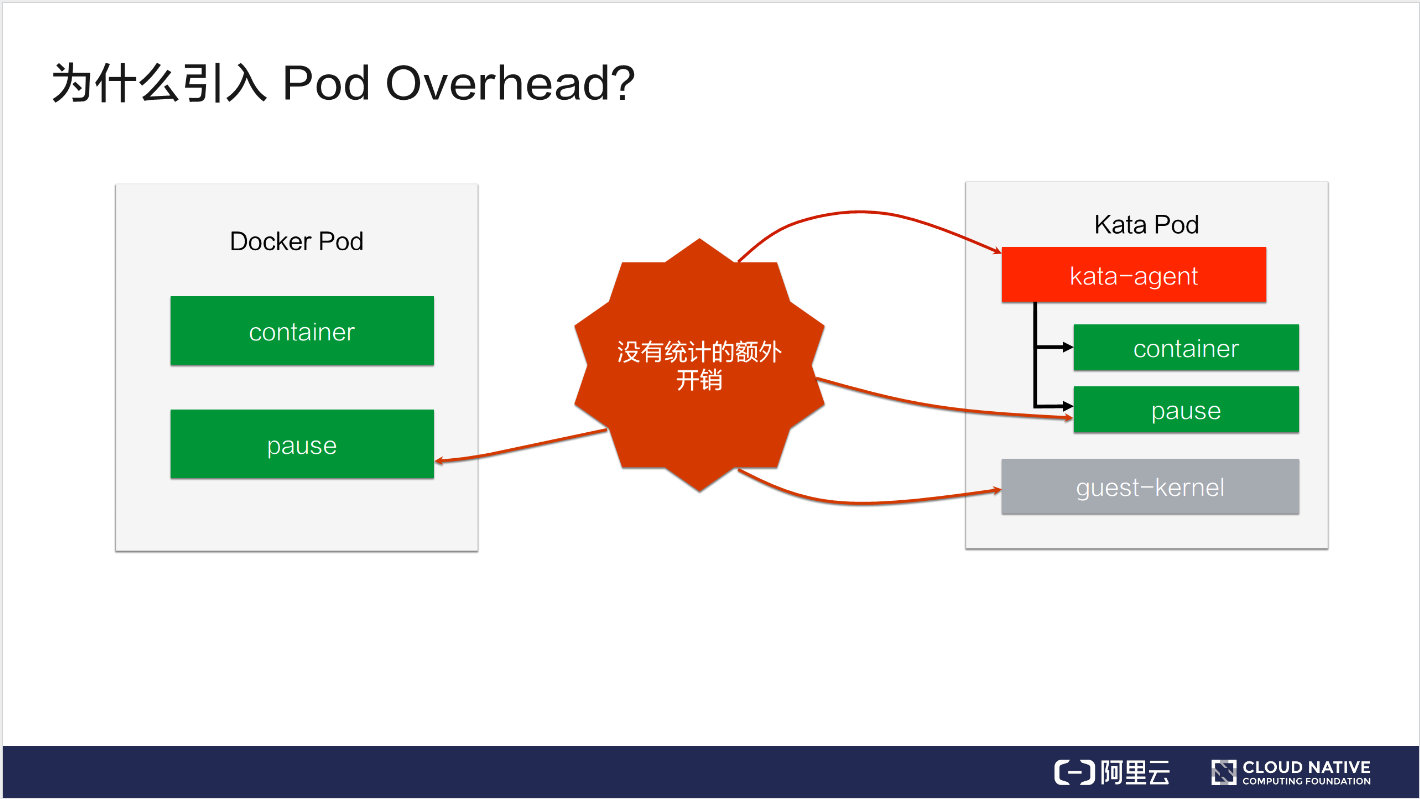
上图左边是一个 Docker Pod,右边是一个 Kata Pod。我们知道,Docker Pod 除了传统的 container 容器之外,还有一个 pause 容器,但我们在计算它的容器开销的时候会忽略 pause 容器。对于 Kata Pod,除了 container 容器之外,kata-agent, pause, guest-kernel 这些开销都是没有被统计进来的。像这些开销,多的时候甚至能超过 100MB,这些开销我们是没法忽略的。
这就是我们引入 Pod Overhead 的初衷。它的结构体定义如下:

它的定义非常简单,只有一个字段 PodFixed。它这里面也是一个映射,它的 key 是一个 ResourceName,value 是一个 Quantity。每一个 Quantity 代表的是一个资源的使用量。因此 PodFixed 就代表了各种资源的占用量,比如 CPU、内存的占用量,都可以通过 PodFixed 进行设置。
Pod Overhead 的使用场景与限制
Pod Overhead 的使用场景主要有三处:
- Pod 调度
在没有引入 Overhead 之前,只要一个节点的资源可用量大于等于 Pod 的 requests 时,这个 Pod 就可以被调度到这个节点上。引入 Overhead 之后,只有节点的资源可用量大于等于 Overhead 加上 requests 的值时才能被调度上来。
- ResourceQuota
它是一个 namespace 级别的资源配额。假设我们有这样一个 namespace,它的内存使用量是 1G,我们有一个 requests 等于 500 的 Pod,那么这个 namespace 之下,最多可以调度两个这样的 Pod。而如果我们为这两个 Pod 增添了 200MB 的 Overhead 之后,这个 namespace 下就最多只可调度一个这样的 Pod。
- Kubelet Pod 驱逐
引入 Overhead 之后,Overhead 就会被统计到节点的已使用资源中,从而增加已使用资源的占比,最终会影响到 Kubelet Pod 的驱逐。
以上是 Pod Overhead 的使用场景。除此之外,Pod Overhead 还有一些使用限制和注意事项:
- Pod Overhead 最终会永久注入到 Pod 内并且不可手动更改。即便是将 RuntimeClass 删除或者更新,Pod Overhead 依然存在并且有效;
- Pod Overhead 只能由 RuntimeClass admission 自动注入(至少目前是这样的),不可手动添加或更改。如果这么做,会被拒绝;
- HPA 和 VPA 是基于容器级别指标数据做聚合,Pod Overhead 不会对它们造成影响。
多容器运行时示例
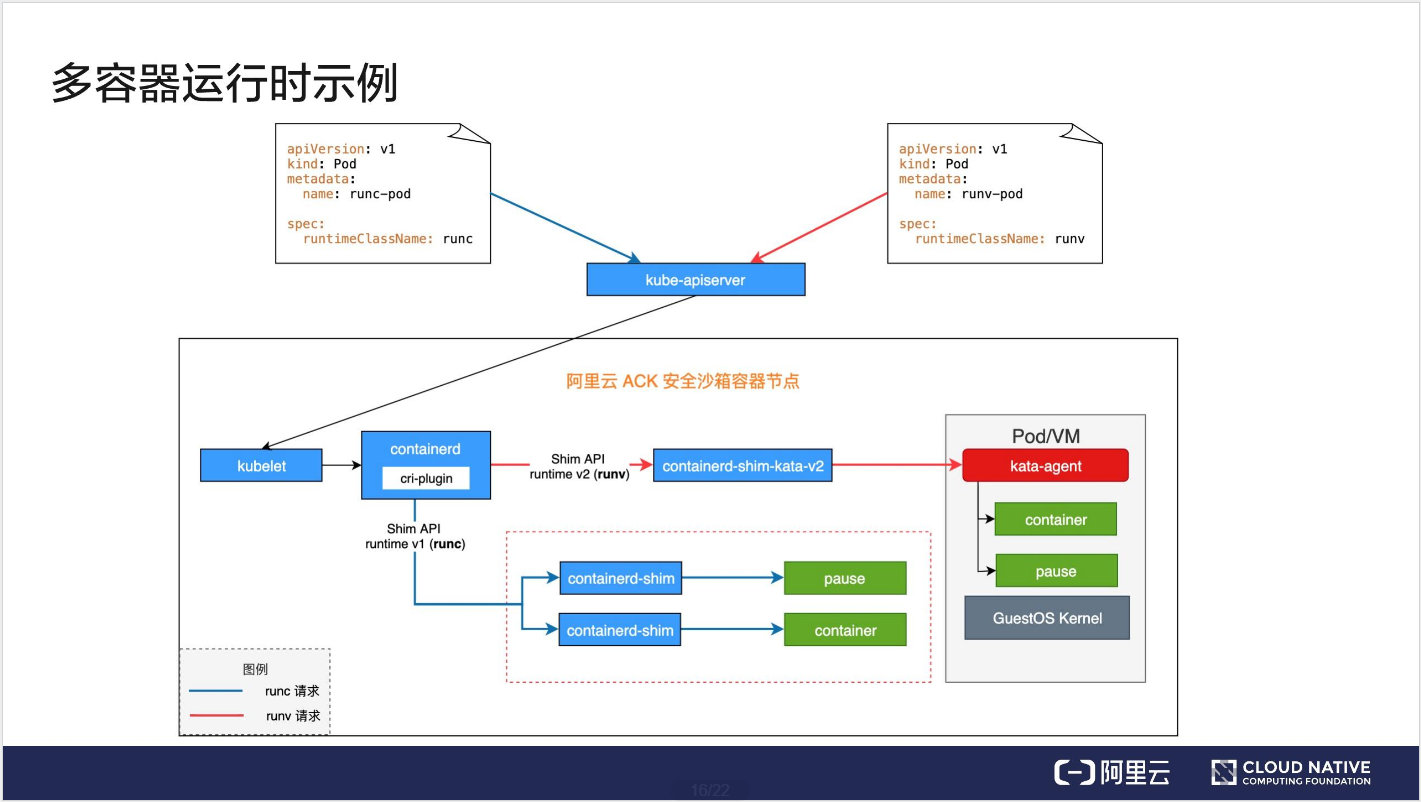
目前阿里云 ACK 安全沙箱容器已经支持了多容器运行时,我们以上图所示环境为例来说明一下多容器运行时是怎么工作的。
如上图所示有两个 Pod,左侧是一个 runc 的 Pod,对应的 RuntimeClass 是 runc,右侧是一个 runv 的Pod,引用的 RuntimeClass 是 runv。对应的请求已用不同的颜色标识了出来,蓝色的代表是 runc 的,红色的代表是 runv 的。图中下半部分,其中比较核心的部分是 containerd,在 containerd 中可以配置多个容器运行时,最终上面的请求也会到达这里进行请求的转发。
我们先来看一下 runc 的请求,它先到达 kube-apiserver,然后 kube-apiserver 请求转发给 kubelet,最终 kubelet 将请求发至 cri-plugin(它是一个实现了 CRI 的插件),cri-plugin 在 containerd 的配置文件中查询 runc 对应的 Handler,最终查到是通过 Shim API runtime v1 请求 containerd-shim,然后由它创建对应的容器。这是 runc 的流程。
runv 的流程与 runc 的流程类似。也是先将请求到达 kube-apiserver,然后再到达 kubelet,再把请求到达 cri-plugin,cri-plugin 最终还回去匹配 containerd 的配置文件,最终会找到通过 Shim API runtime v2 去创建 containerd-shim-kata-v2,然后由它创建一个 Kata Pod。
下面我们再看一下 containerd 的具体配置。

containerd 默认放在 etc/containerd/config.toml 这个位置下。比较核心的配置是在 plugins.cri.containerd 目录下。其中 runtimes 的配置都有相同的前缀 plugins.cri.containerd.runtimes,后面有 runc, runv 两种 RuntimeClass。这里面的 runc 和 runv 和前面 RuntimeClass 对象中 Handler 的名字是相对应的。除此之外,还有一个比较特殊的配置 plugins.cri.containerd.runtimes.default_runtime,它的意思是说,如果一个 Pod 没有指定 RuntimeClass,但是被调度到当前节点的话,那么就默认使用 runc 容器运行时。
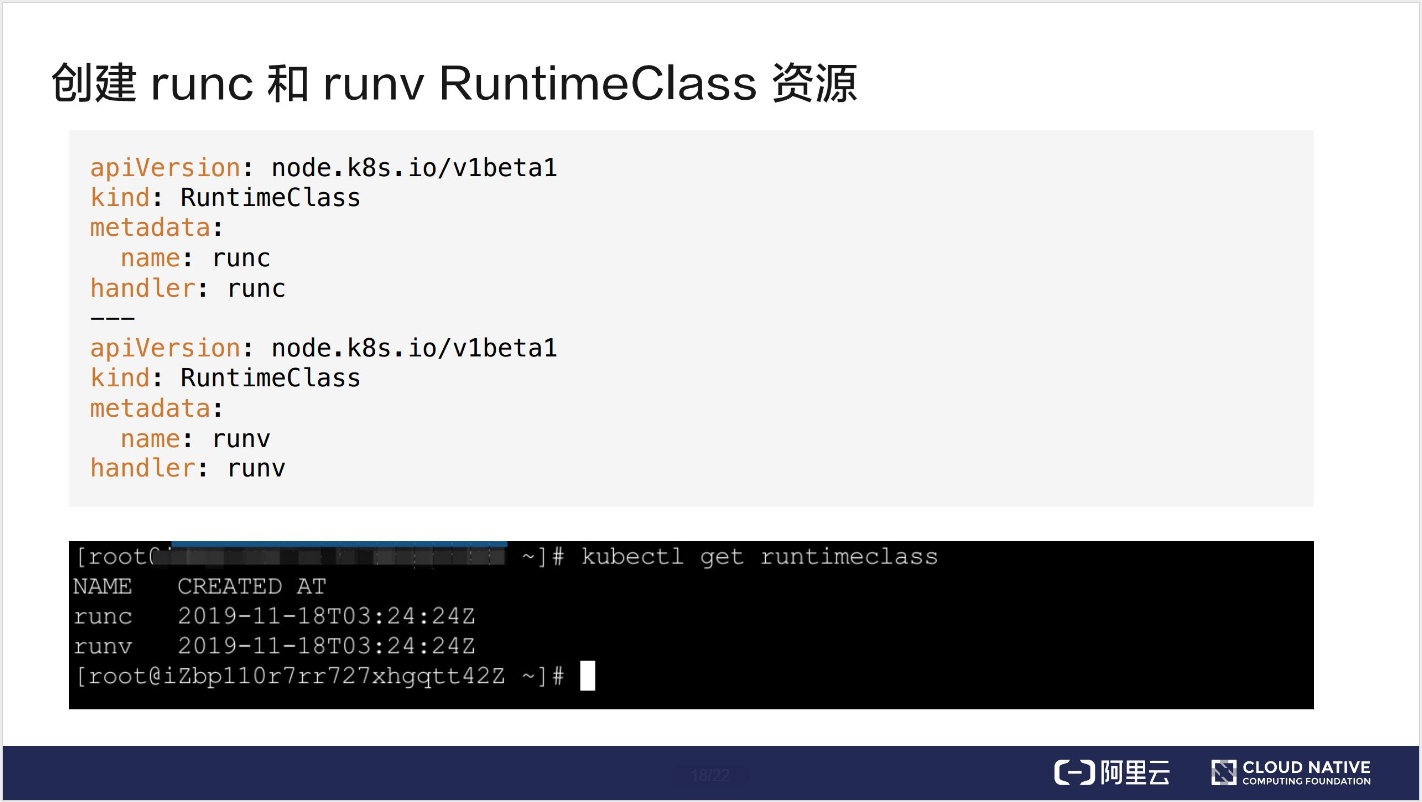
下面的例子是创建 runc 和 runv 这两个 RuntimeClass 对象,我们可以通过 kubectl get runtimeclass 看到当前所有可用的容器运行时。
下图从左至右分别是一个 runc 和 runv 的 Pod,比较核心的地方就是在 runtimeClassName 字段中分别引用了 runc 和 runv 的容器运行时。

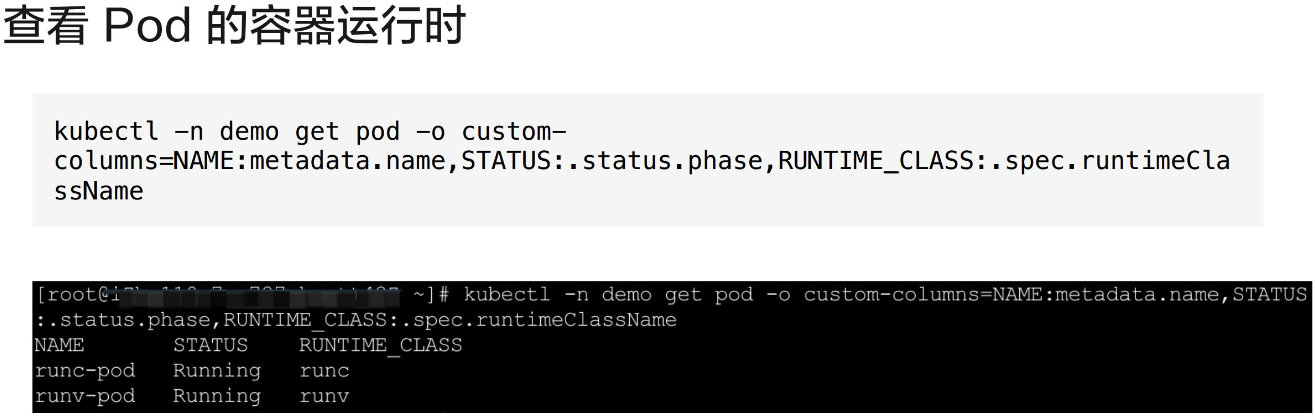
最终将 Pod 创建起来之后,我们可以通过 kubectl 命令来查看各个 Pod 容器的运行状态以及 Pod 所使用的容器运行时。我们可以看到现在集群中有两个 Pod,一个是 runc-pod,一个是 runv-pod,分别引用的是 runc 和 runv 的 RuntimeClass,并且它们的状态都是 Running。
本节总结
本节课的主要内容就到此为止了,这里为大家简单总结一下:
- RuntimeClass 是 Kubernetes 一种内置的全局域资源,主要用来解决多个容器运行时混用的问题;
- RuntimeClass 中配置 Scheduling 可以让 Pod 自动调度到运行了指定容器运行时的节点上。但前提是需要用户提前为这些 Node 设置好 label;
- RuntimeClass 中配置 Overhead,可以把 Pod 中业务运行所需意外的开销统计进来,让调度、ResourceQuota、Kubelet Pod 驱逐等行为更准确。
学过了