DaemonSet
-
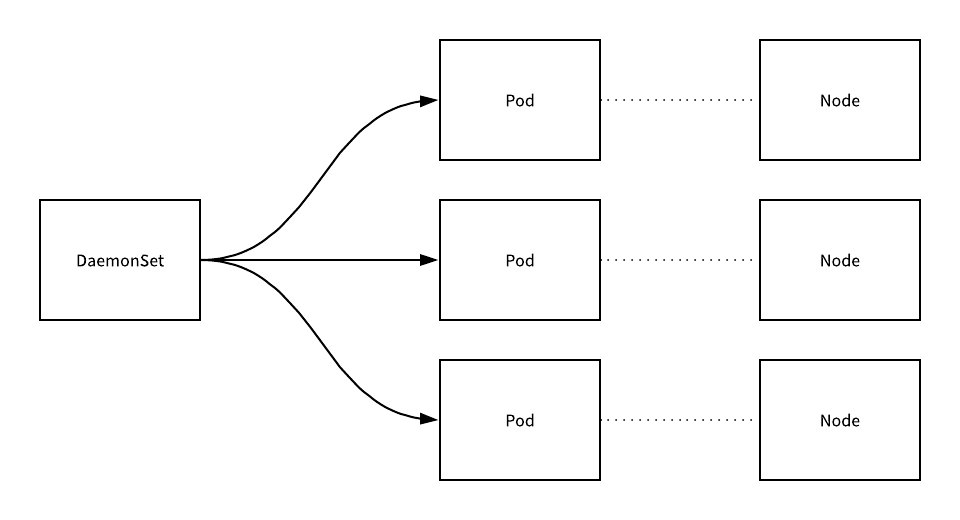
DaemonSet确保全部或者一些Node上运行一个Pod的副本。 -
当有
Node加入集群时,也会为他们新增一个Pod。 -
当有
Node从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有Pod。
一种简单的用法是为每种类型的守护进程在所有的节点上都启动一个 DaemonSet。 一个稍微复杂的用法是为同一种守护进程部署多个 DaemonSet;每个具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求。下面是使用 DaemonSet 的一些典型用法:
-
运行集群存储daemon在每个
Node上运行glusterd、ceph
- 在每个
Node上运行日志收集daemon fluentd、logstash- 在每个
Node上运行监控daemonPrometheus Node Exporter、collectd、Datadog
Kubernetes的DaemonSet资源控制器
- 实现原理

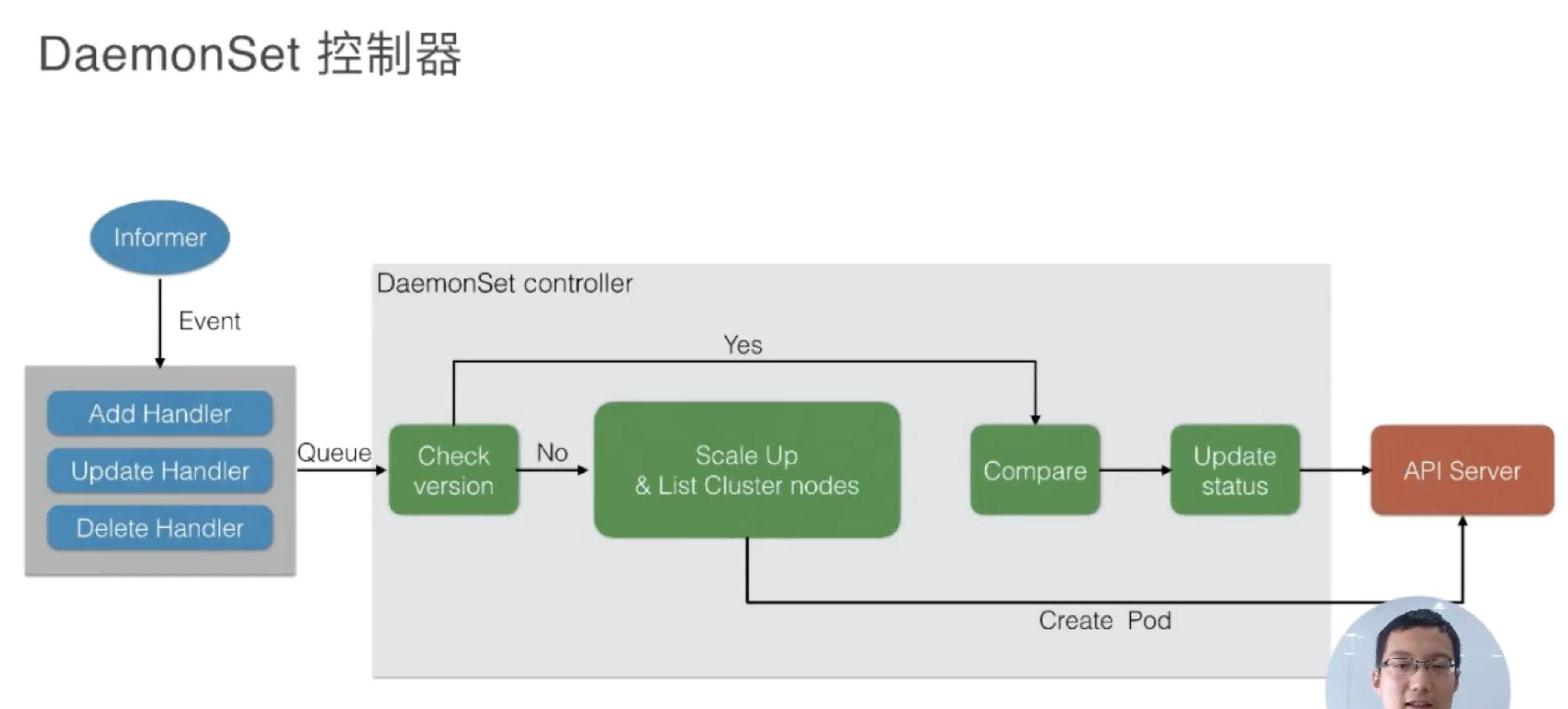
DaemonSet 其实和 Job controller 做的差不多:
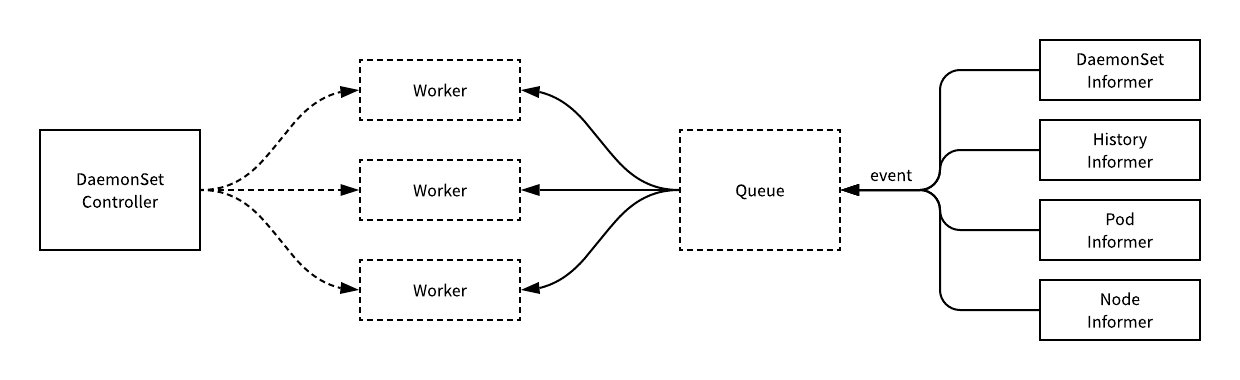
两者都需要根据 watch 这个 API Server 的状态。现在 DaemonSet 和 Job controller 唯一的不同点在于,DaemonsetSet Controller需要去 watch node 的状态,但其实这个 node 的状态还是通过 API Server 传递到 ETCD 上。
当有 node 状态节点发生变化时,它会通过一个内存消息队列发进来,然后DaemonSet controller 会去 watch 这个状态,看一下各个节点上是都有对应的 Pod,如果没有的话就去创建。当然它会去做一个对比,如果有的话,它会比较一下版本,然后加上刚才提到的是否去做 RollingUpdate?如果没有的话就会重新创建,Ondelete 删除 pod 的时候也会去做 check 它做一遍检查,是否去更新,或者去创建对应的 pod。
当然最后的时候,如果全部更新完了之后,它会把整个 DaemonSet 的状态去更新到 API Server 上,完成最后全部的更新。
Kubernetes的DaemonSet实现逻辑
- 调度逻辑
仅在某些节点上运行 Pod:如果指定了 .spec.template.spec.nodeSelector,DaemonSet Controller 将在能够与 Node Selector 匹配的节点上创建 Pod。类似这种情况,可以指定 .spec.template.spec.affinity,然后 DaemonSet Controller 将在能够与 node Affinity 匹配的节点上创建 Pod。 如果根本就没有指定,则 DaemonSet Controller 将在所有节点上创建 Pod。
示例运行
- 每个
Node节点都运行一个nginx服务。
1 | |
1 | |
- 每个
Node节点都运行一个fluentd日志监控服务。
1 | |
1 | |
Job/CronJob
任务计划/周期性任务计划
- 首先 kubernetes 的 Job 是一个管理任务的控制器,它可以创建一个或多个 Pod 来指定 Pod 的数量,并可以监控它是否成功地运行或终止;
- 我们可以根据 Pod 的状态来给 Job 设置重置的方式及重试的次数;
- 我们还可以根据依赖关系,保证上一个任务运行完成之后再运行下一个任务;
- 同时还可以控制任务的并行度,根据并行度来确保 Pod 运行过程中的并行次数和总体完成大小。
知识要点
- 基本概念
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。
Cron Job 管理基于时间的 Job,即在给定时间点只运行一次或周期性地在给定时间点运行。
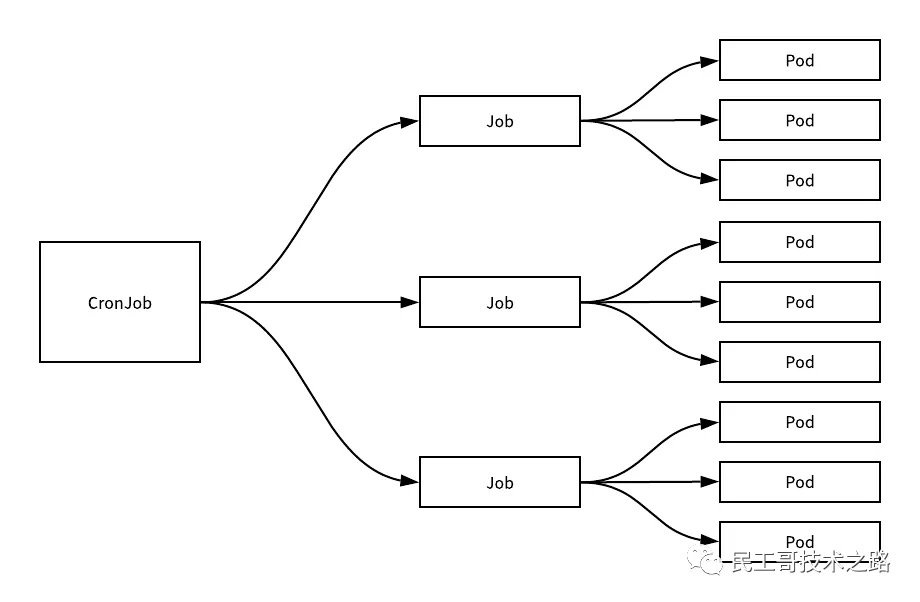
- 执行特点
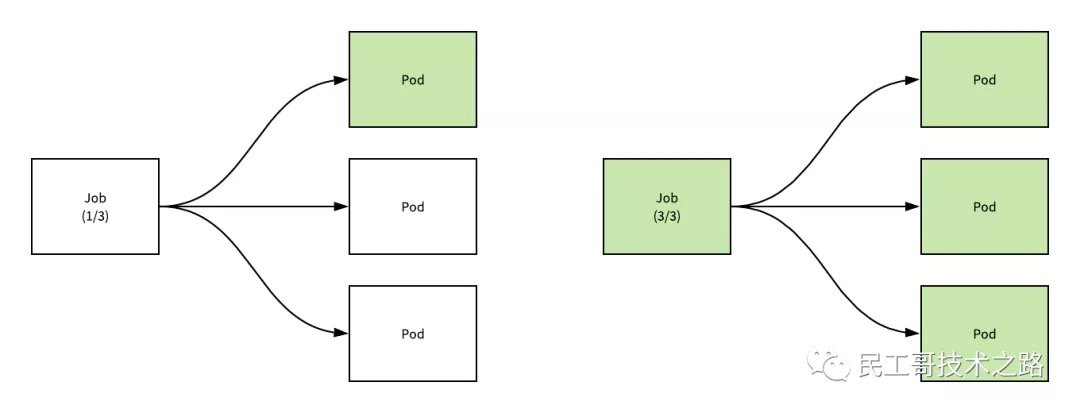
Job 会创建一个或者多个 Pods,并确保指定数量的 Pods 成功终止。随着 Pods 成功结束,Job 跟踪记录成功完成的 Pods 个数。当数量达到指定的成功个数阈值时,任务结束。删除 Job 的操作会清除所创建的全部 Pods。当第一个 Pod 失败或者被删除(比如因为节点硬件失效或者重启)时,Job 对象会启动一个新的 Pod。
CronJob 对于创建周期性的、反复重复的任务很有用,例如执行数据备份或者发送邮件。CronJobs 也可以用来计划在指定时间来执行的独立任务,例如计划当集群看起来很空闲时 执行某个 Job。

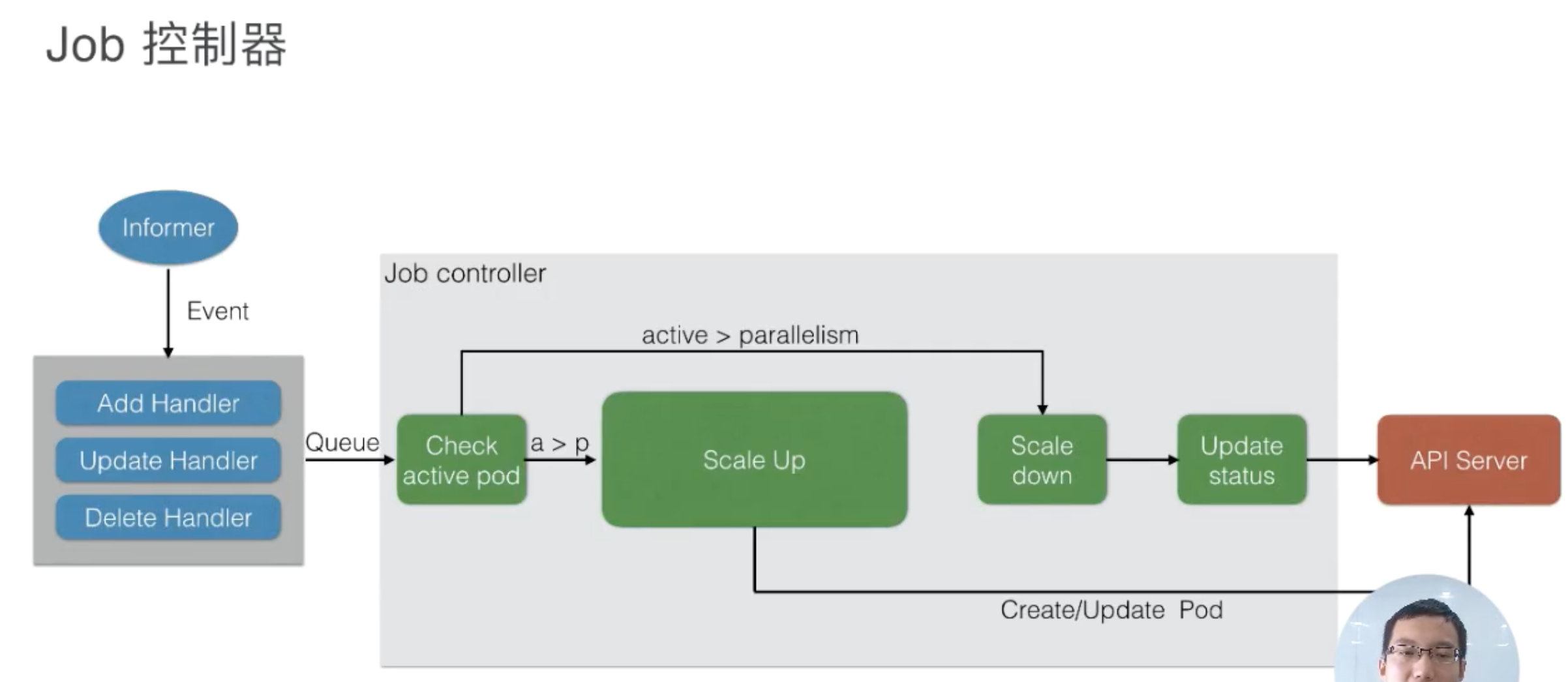
所有的 job 都是一个 controller,它会 watch 这个 API Server,我们每次提交一个 Job 的 yaml 都会经过 api-server 传到 ETCD 里面去,然后 Job Controller 会注册几个 Handler,每当有添加、更新、删除等操作的时候,它会通过一个内存级的消息队列,发到 controller 里面。
通过 Job Controller 检查当前是否有运行的 pod,如果没有的话,通过 Scale up 把这个 pod 创建出来;如果有的话,或者如果大于这个数,对它进行 Scale down,如果这时 pod 发生了变化,需要及时 Update 它的状态。
同时要去检查它是否是并行的 job,或者是串行的 job,根据设置的配置并行度、串行度,及时地把 pod 的数量给创建出来。最后,它会把 job 的整个的状态更新到 API Server 里面去,这样我们就能看到呈现出来的最终效果了。
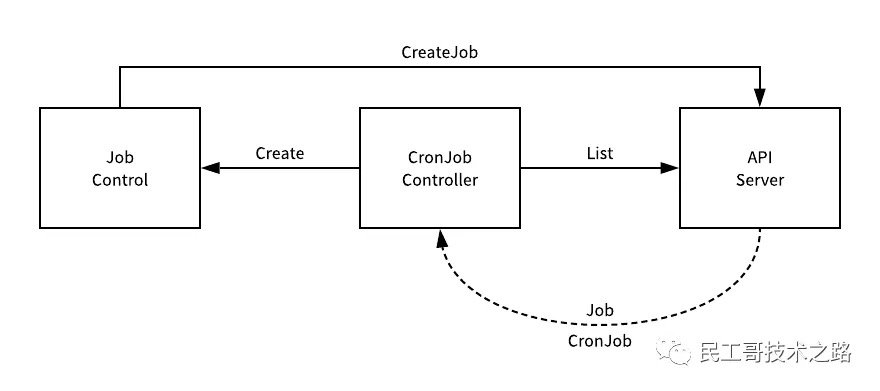
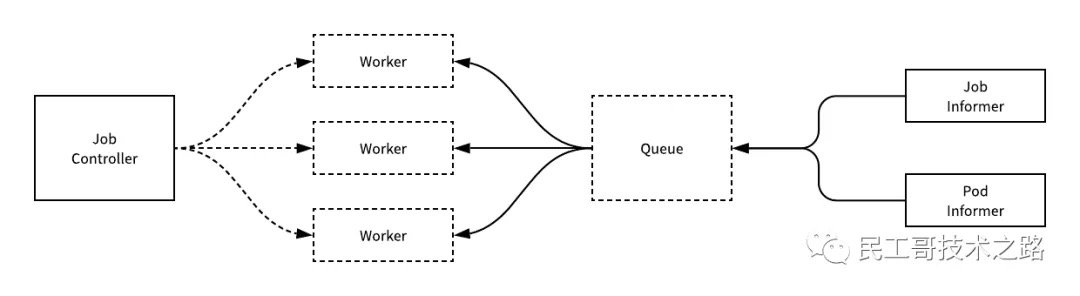
Job 的并行执行
- 不设置 .spec.completions,默认值为 .spec.parallelism
- 多个 Pod 之间必须相互协调,或者借助外部服务确定每个 Pod 要处理哪个工作条目
- 每个 Pod 都可以独立确定是否其它 Pod 都已完成,进而确定 Job 是否完成
- 一旦至少 1 个 Pod 成功完成,并且所有 Pod 都已终止,即可宣告 Job 成功完成
- .spec.completions 字段设置为非 0 的正数值
- 当 .spec.completions 等于 1 时一个成功的 Pod 就被视为完成
- 通常只启动一个 Pod,除非该 Pod 失败
- 当 Pod 成功终止时,立即视 Job 为完成状态
- 非并行 Job
- 具有确定完成计数的并行 Job
- 带工作队列的并行 Job
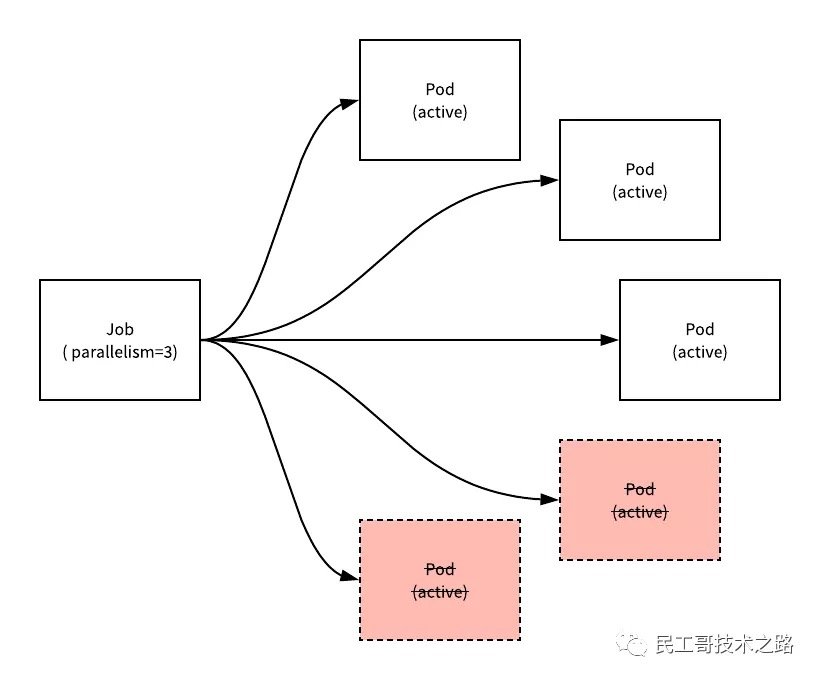
示例运行
Job
- .spec.completions 标志 Job 结束需要成功运行的 Pod 个数,默认为 1
- .spec.parallelism 标志并行运行的 Pod 的个数,默认为 1
- .spec.activeDeadlineSeconds 该值适用于 Job 的整个生命期,无论 Job 创建了多少个 Pod。 一旦 Job 运行时间达到
activeDeadlineSeconds秒,其所有运行中的 Pod 都会被终止,并且 Job 的状态更新为type: Failed及reason: DeadlineExceeded。
注意 Job 的 .spec.activeDeadlineSeconds 优先级高于其 .spec.backoffLimit 设置。 因此,如果一个 Job 正在重试一个或多个失效的 Pod,该 Job 一旦到达 activeDeadlineSeconds 所设的时限即不再部署额外的 Pod,即使其重试次数还未 达到 backoffLimit 所设的限制。
1 | |

CronJob
- .spec.schedule:指定任务运行周期(调度)
- .spec.jobTemplate:指定需要运行的任务(Job 模板)
- .spec.startingDeadlineSeconds:启动 Job 的期限(秒级别)
- .spec.concurrencyPolicy:并发策略(Allow/Forbid/Replace)
- .spec.suspend:挂起
- .spec.successfulJobsHistoryLimit:指定了可以保留多少完成的 Job(历史限制;默认 3)
- .spec.failedJobsHistoryLimit:指定了可以保留多少失败的 Job(历史限制;默认 1)
1 | |
一旦不再需要 Cron Job,简单地可以使用 kubectl 命令删除它。这将会终止正在创建的 Job。然而,运行中的 Job 将不会被终止,不会删除 Job 或它们的 Pod。为了清理那些 Job 和 Pod,需要列出该 Cron Job 创建的全部 Job,然后删除它们。
1 | |