对象资源的分类
根据不同的级别,可以将 Kubernetes 中的资源进行多种分类。
Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。Kubernetes 拥有一个庞大且快速增长的生态系统。Kubernetes 的服务、支持和工具广泛可用。以下列举的内容都是 Kubernetes 中的 Object,这些对象都可以在 yaml 文件中作为一种 API 类型来配置。
- 工作负载型资源
- Pod、ReplicaSet、Deployment、StatefulSet、DaemonSet、Job、CronJob
- 服务发现及负载均衡型资源
- Service、Ingress
- 配置与存储型资源
- Volume、CSI
- 特殊类型的存储卷
- ConfigMap、Secret、DownwardAPI
- 集群级别资源
- Namespace、Node、Role、ClusterRole、RoleBinding、ClusterRoleBinding
- 元数据型资源
- HPA、PodTemplate、LimitRange
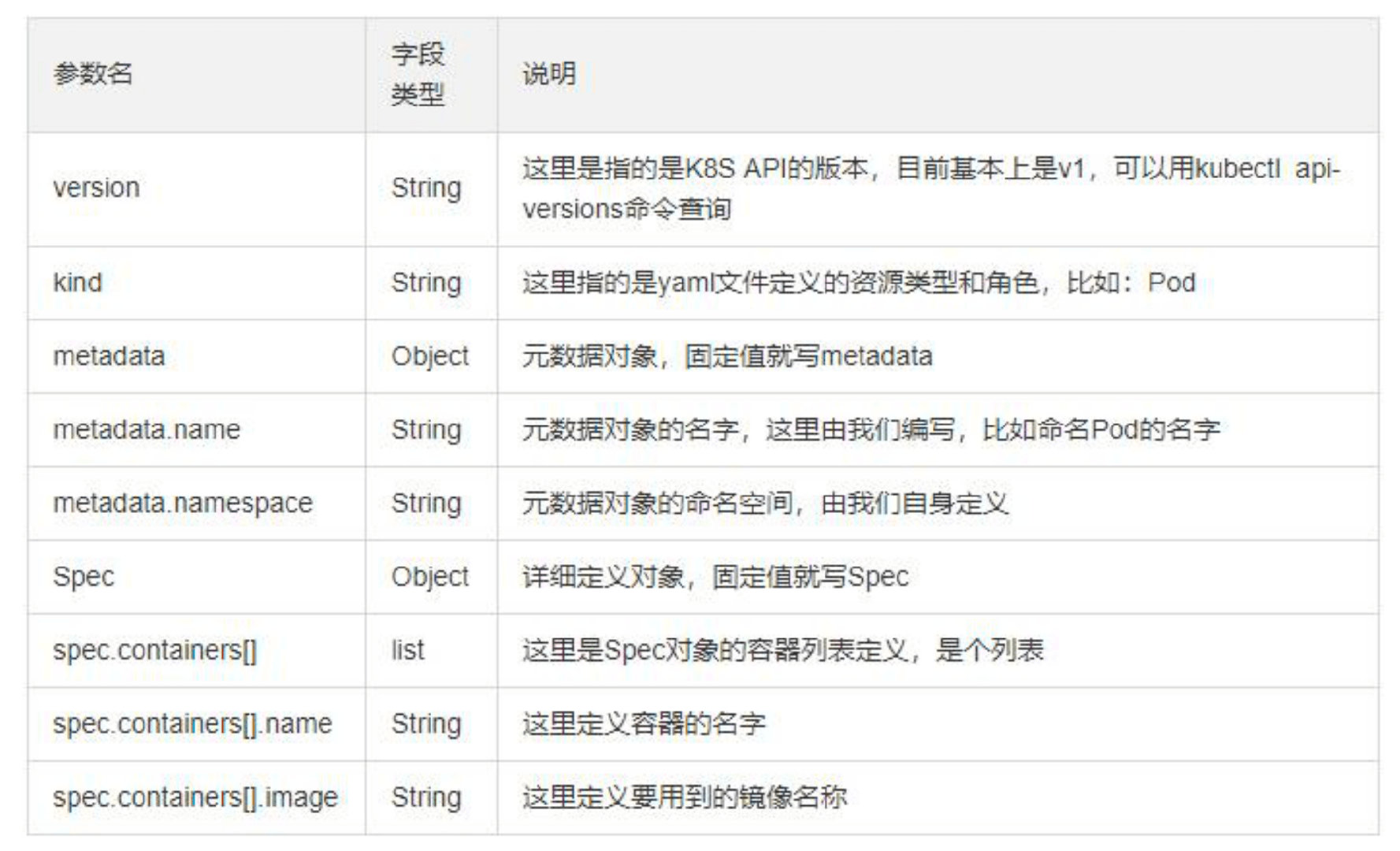
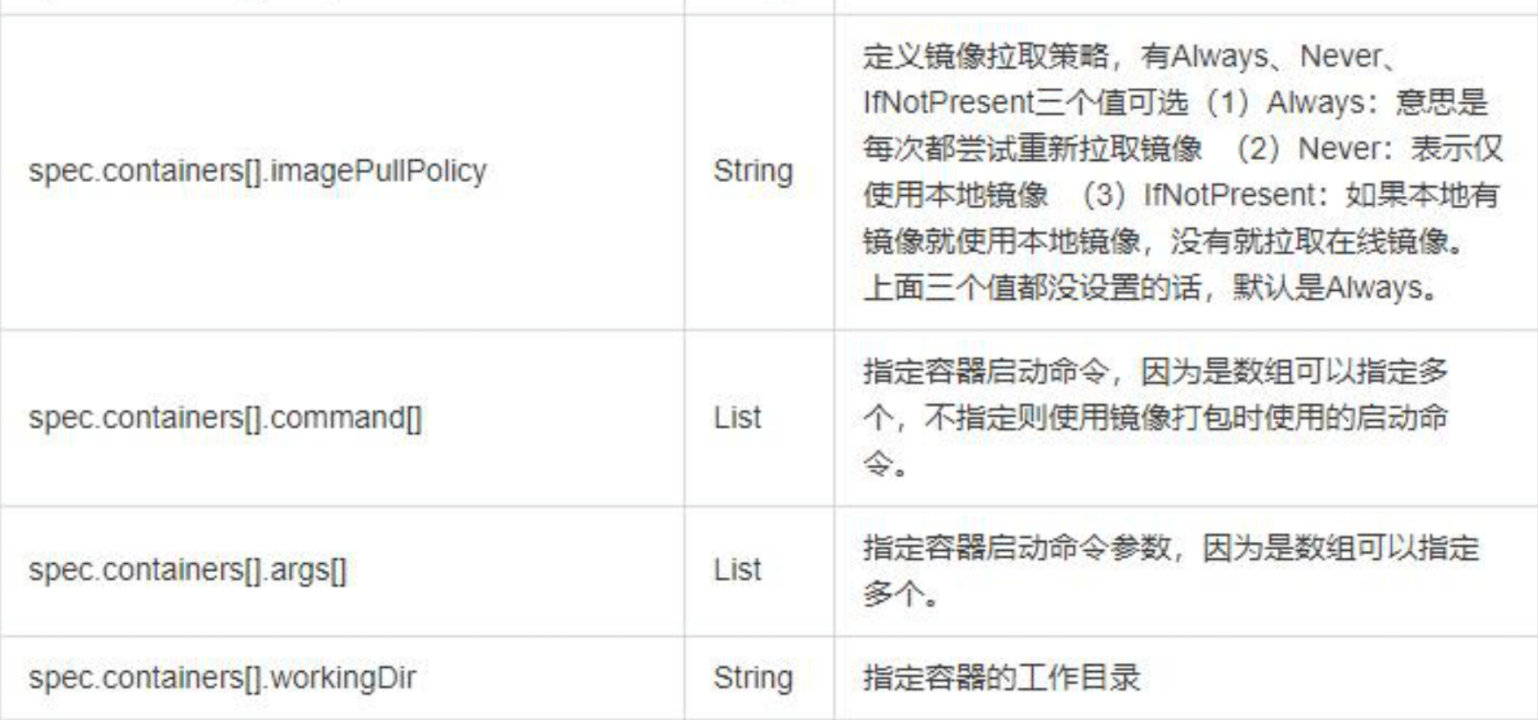
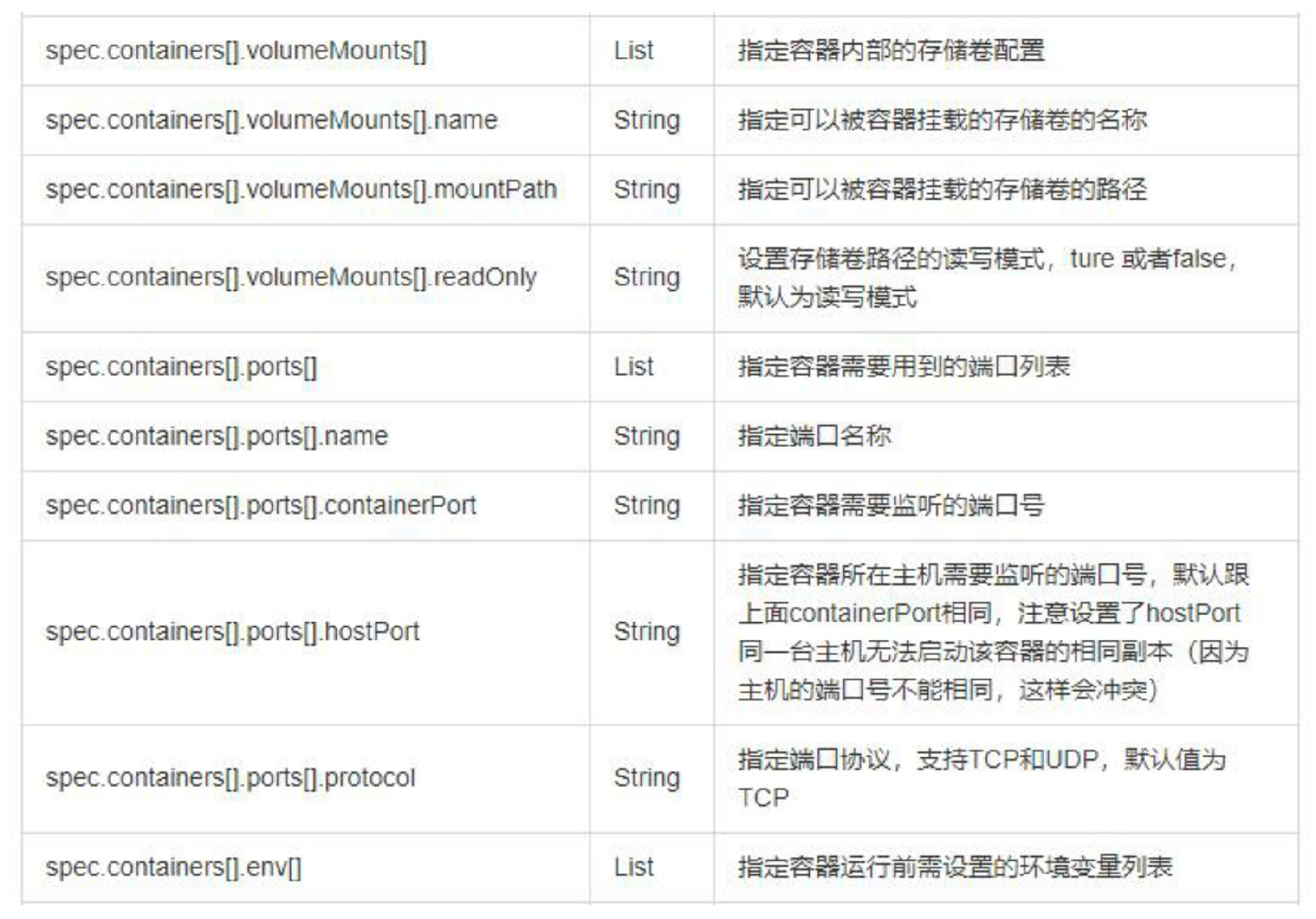
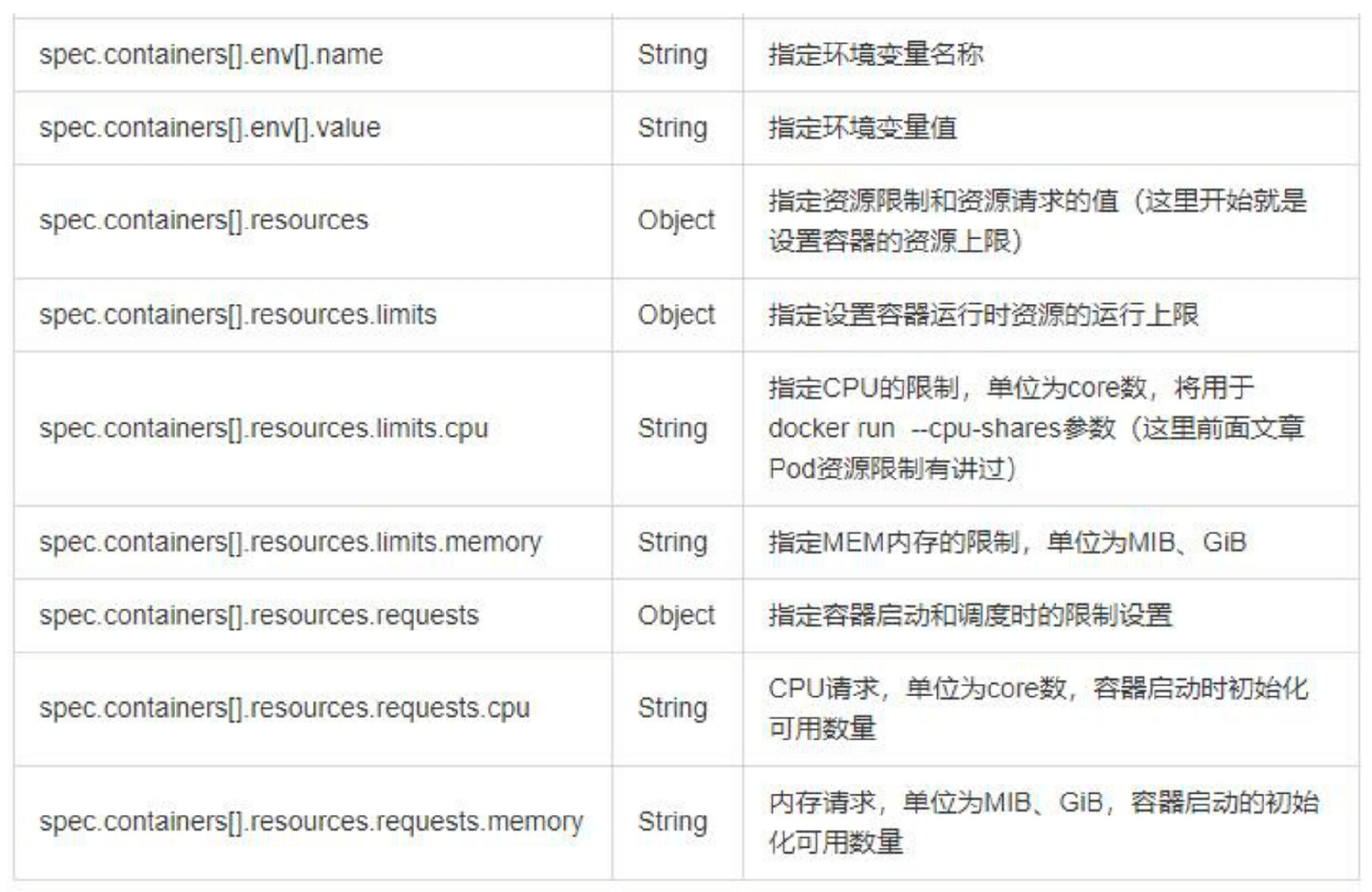
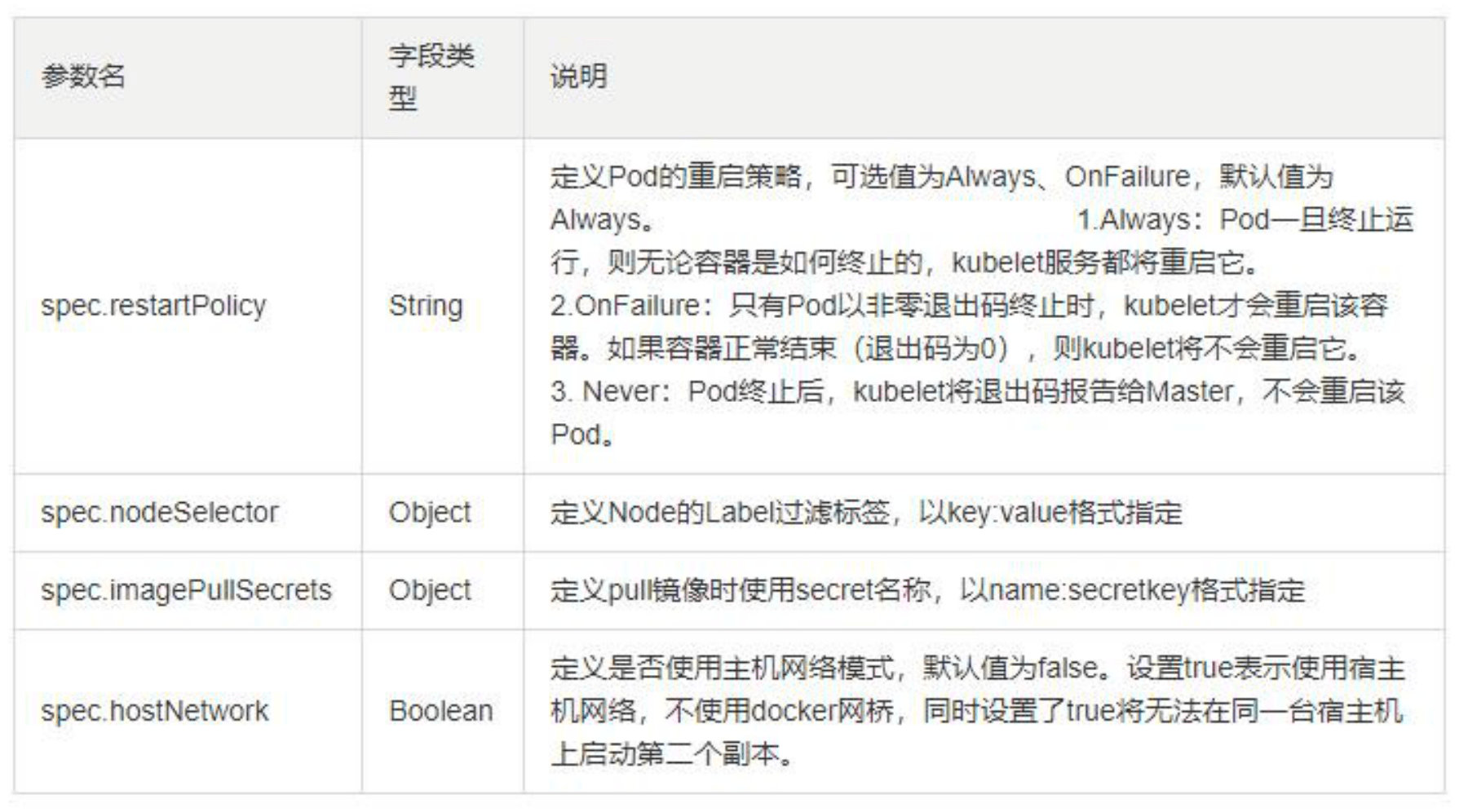
常用字段的解释
yaml文件来描述 Kubernetes 对象
1 | |
1 | |
1 | |
NameSpace
Kubernetes 支持多个虚拟集群,它们底层依赖于同一个物理集群。 这些虚拟集群被称为名字空间( 命名空间 )。
适用
名字空间适用于存在很多跨多个团队或项目的用户的场景。对于只有几到几十个用户的集群,根本不需要创建或考虑名字空间。当需要名称空间提供的功能时,请开始使用它们。
名字空间为名称提供了一个范围。资源的名称需要在名字空间内是唯一的,但不能跨名字空间。 名字空间不能相互嵌套,每个 Kubernetes 资源只能在一个名字空间中。
名字空间是在多个用户之间划分集群资源的一种方法(通过资源配额)。
不必使用多个名字空间来分隔仅仅轻微不同的资源,例如同一软件的不同版本: 应该使用标签 来区分同一名字空间中的不同资源。
example
1 | |
1 | |
Kubernetes 会创建四个初始名字空间:
default没有指明使用其它名字空间的对象所使用的默认名字空间kube-systemKubernetes 系统创建对象所使用的名字空间kube-public这个名字空间是自动创建的,所有用户(包括未经过身份验证的用户)都可以读取它。 这个名字空间主要用于集群使用,以防某些资源在整个集群中应该是可见和可读的。 这个名字空间的公共方面只是一种约定,而不是要求。kube-node-lease此名字空间用于与各个节点相关的租期(Lease)对象; 此对象的设计使得集群规模很大时节点心跳检测性能得到提升。
标签
1 | |
基于等值 或 基于不等值 的需求
允许按标签键和值进行过滤。 匹配对象必须满足所有指定的标签约束,尽管它们也可能具有其他标签。 可接受的运算符有=、== 和 != 三种。 前两个表示 相等(并且只是同义词),而后者表示 不相等。例如:
1 | |
前者选择所有资源,其键名等于 environment,值等于 production。 后者选择所有资源,其键名等于 tier,值不同于 frontend,所有资源都没有带有 tier 键的标签。 可以使用逗号运算符来过滤 production 环境中的非 frontend 层资源:environment=production,tier!=frontend。
下面的示例 Pod 选择带有标签 “accelerator=nvidia-tesla-p100“。
1 | |
基于集合 的需求
基于集合 的标签需求允许你通过一组值来过滤键。 支持三种操作符:in、notin 和 exists (只可以用在键标识符上)。例如:
1 | |
选择了所有包含了有 partition 标签的资源;没有校验它的值
api
两种标签选择算符都可以通过 REST 客户端用于 list 或者 watch 资源。 例如,使用 kubectl 定位 apiserver,可以使用 基于等值 的标签选择算符可以这么写:
1 | |
或者使用 基于集合的 需求:
1 | |
正如刚才提到的,基于集合 的需求更具有表达力。例如,它们可以实现值的 或 操作:
1 | |
或者通过 exists 运算符限制不匹配:
1 | |