结构

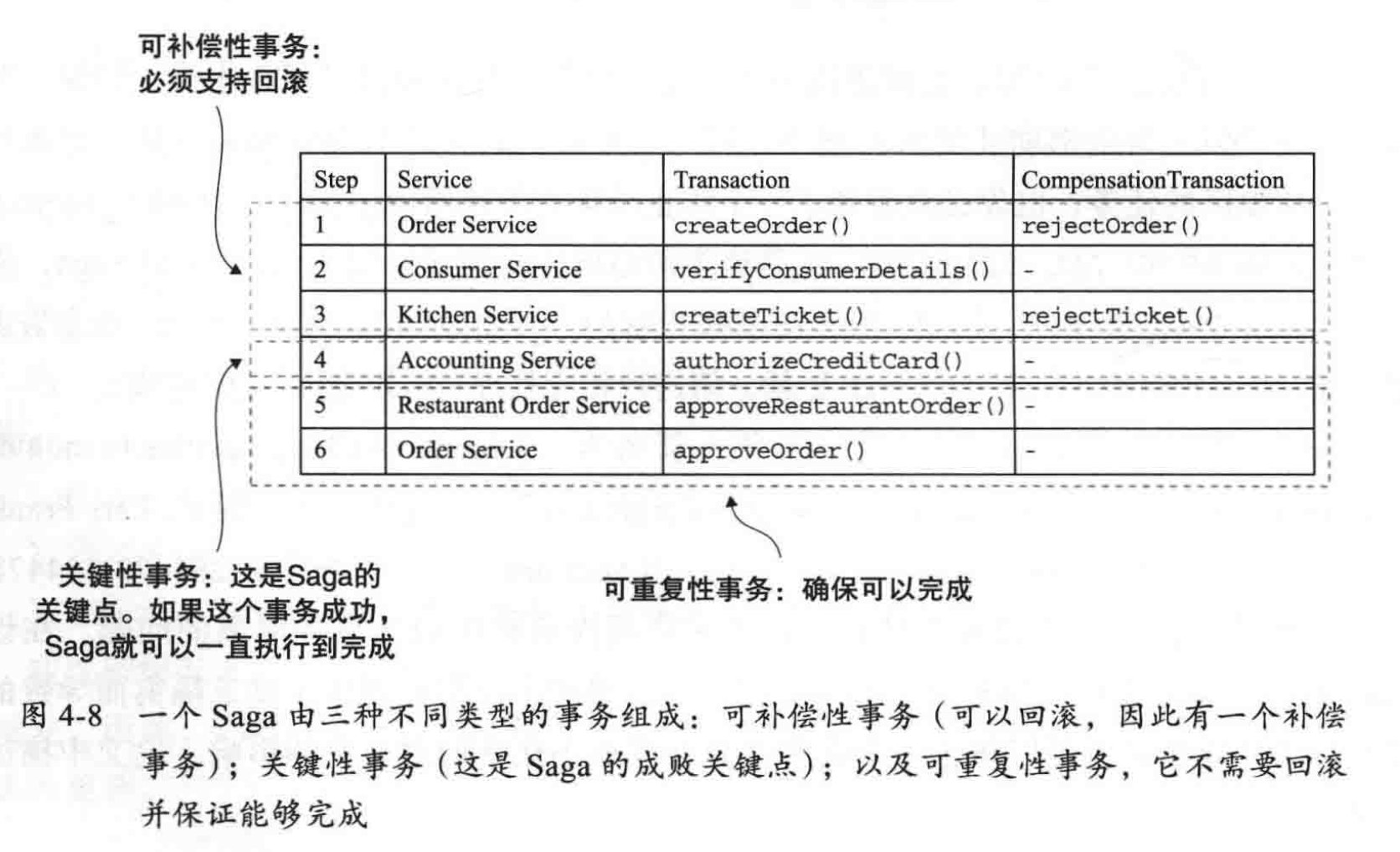
处理类型
协同式
决策和执行顺序逻辑分布在每个部分,通过异步事件沟通


编排式
把决策和执行顺序逻辑集中到编排器,由编排器通知操作方





解决隔离问题


解决隔离的方法

语义锁
程序级锁


交换式更新
更新操作设计成按任意顺序执行

悲观视图
重排步骤


重读值
覆盖数据前检查数据不变

版本文件
记录更新,排序更新记录

业务评级

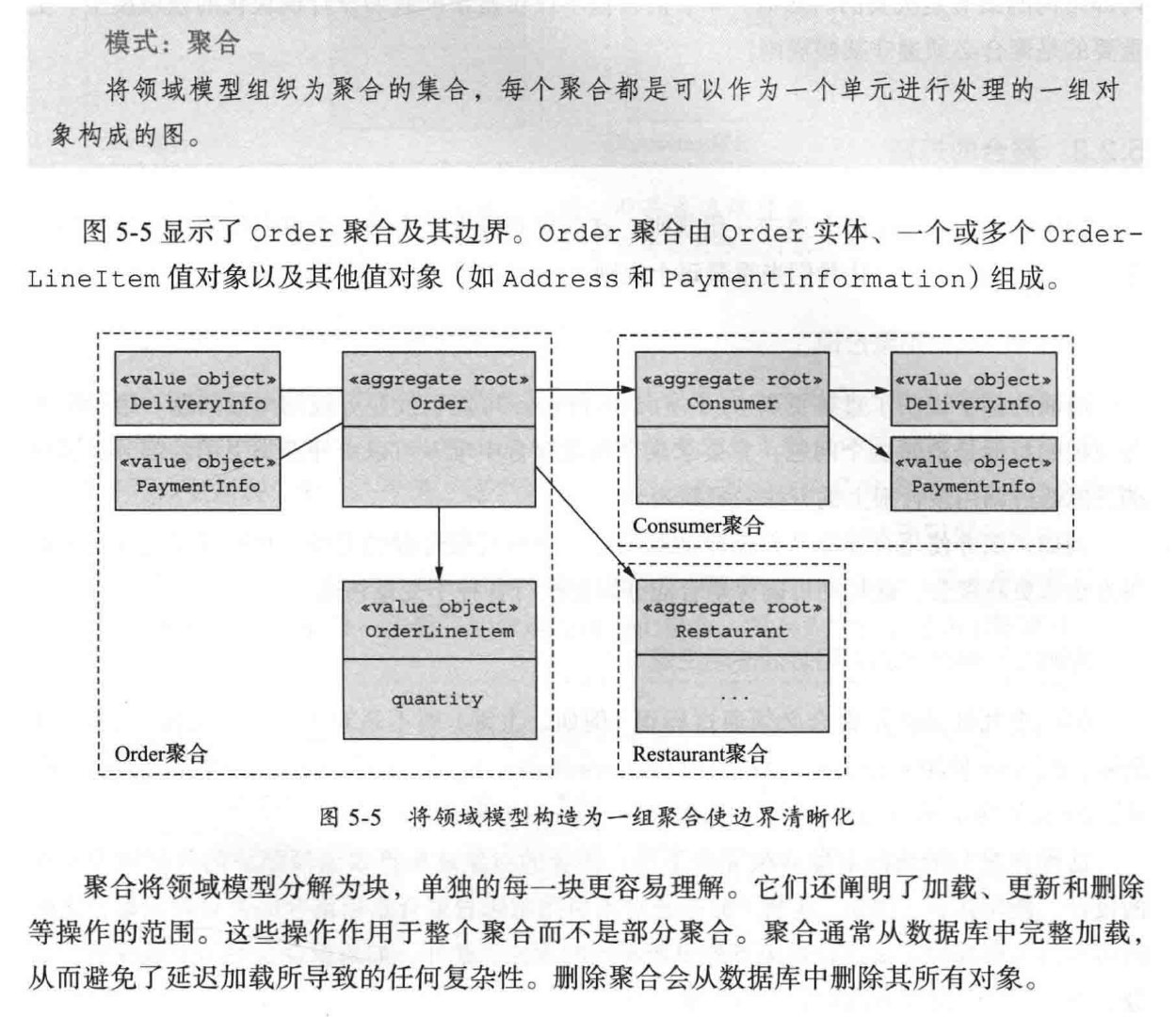
聚合
聚合好处


什么是聚合

概念 聚合的特点
- 高内聚、低耦合,它是领域模型中最底层的边界,可作为拆分微服务的最小单位,但不推荐过度拆分。在对性能有极致要求的场景中,聚合可独立作为一个微服务,以满足版本的高频发布和弹性伸缩要求。
- 一个微服务可包含多个聚合,聚合之间的边界是微服务内天然的逻辑边界。有了该逻辑边界,在微服务架构演进时就可以聚合为单位进行拆分和组合。
聚合根的特点
- 聚合根是实体,有实体的特点,具有全局唯一标识,有独立的生命周期。一个聚合只有一个聚合根,聚合根在聚合内对实体和值对象采用直接对象引用的方式进行组织和协调,聚合根与聚合根之间通过ID关联的方式实现聚合之间的协同。
实体的特点
- 有ID标识,通过ID判断相等性,ID在聚合内唯一即可。状态可变,它依附于聚合根,其生命周期由聚合根管理。实体一般会持久化,但与数据库持久化对象不一定是一对一的关系。实体可引用聚合内的聚合根、实体和值对象。
值对象的特点
- 无ID,不可变,无生命周期,用完即扔。值对象之间通过属性值判断相等性。它的核心本质是值,是一组概念完整的属性组成的集合,用于描述实体的状态和特征。值对象尽量只引用值对象。
区别:
聚合根、实体、值对象的区别
- 聚合根具有全局的唯一标识,而实体只有在聚合内部有唯一的本地标识,值对象没有唯一标识,不存在这个值对象或那个值对象的说法。
- 聚合根除了唯一标识外,其他所有状态信息都理论上可变。实体是可变的。值对象是只读的。
- 聚合根有独立的生命周期,实体的生命周期从属于其所属的聚合,实体完全由其所属的聚合根负责管理维护。值对象无生命周期可言,因为只是一个值。
聚合根、实体、值对象对象之间如何建立关联
- 聚合根到聚合根:通过ID关联。
- 聚合根到其内部的实体、值对象:直接对象引用。
- 实体对其他对象的引用规则:1)能引用其所属聚合内的聚合根、实体、值对象。2)能引用外部聚合根,但推荐以ID的方式关联,
- 另外也可以关联某个外部聚合内的实体,但必须是ID关联,否则就出现同一个实体的引用被两个聚合根持有,这是不允许的,一个实体的引用只能被其所属的聚合根持有。
- 值对象对其他对象的引用规则:只需确保值对象是只读的即可,推荐值对象的所有属性都尽量是值对象。
如何识别聚合与聚合根
- 明确含义:一个Bounded Context(界定的上下文)可能包含多个聚合,每个聚合都有一个根实体,叫做聚合根。
- 识别顺序:
- 先找出哪些实体可能是聚合根,
- 再逐个分析每个聚合根的边界,即该聚合根应该聚合哪些实体或值对象。
- 最后再划分Bounded Context。
聚合边界确定法则:根据不变性约束规则(Invariant) 不变性规则有两类:
- 聚合边界内必须具有哪些信息,如果没有这些信息就不能称为一个有效的聚合。
- 聚合内的某些对象的状态必须满足某个业务规则。
聚合规则
领域驱动设计要求聚合遵守一组规则。这些规则确保聚合是一个可以强制执行各种不变量约束的自包含单元。让我们来看看每个规则。
只引用聚合根
它要求聚合根是聚合中唯一可以由外部类引用的部分。客户端只能通过调用聚合根上的方法来更新聚合。此规则可确保聚合能够强制执行各种不变量约束。
聚合间引用使用主键
这种方法与传统的对象建模完全不同,传统的对象建模将领域模型中的外键视为不好的设计。使用标识(例如,主键)而不是对象引用意味着聚合是松耦合的。它确保聚合之间的边界得到很好的定义,并避免意外更新不同的聚合,不会出现跨服务的对象引用问题。
聚合同时也是存储的单元,因此这种方法让持久化也变得简单。我们可以更容易地将聚合存储在NeSQL数据库(如MongoDB)中。通过主键引用聚合,因此不再需要透明延迟加 载(transparent lazy loading),同时也避免了它所带来的问题。通过分片(sharding)聚合来横 向扩展数据库也相对简单。
每个事务只创建或更新一个聚合
此约束还满足大多数NoSQL数据库的受限事务模型。它可以确保单个事务的范围不超越服务的边界。
在单个服务中维护多个聚合的一致性可以在一个事务中更新 多个聚合。例如,服务B可以在单个事务中更新聚合Y和Z。只有在使用支持复杂事务模 型的数据库(如关系型数据库)时才能实现此目的。
聚合颗粒度
在开发领域模型时,你必须做出的关键决策是决定每个聚合的大小。
小好处
由于每个聚合的更新都是序列化的,因此更细粒度的聚合将提高应用程序能同时处理的请求数量,从而提高可扩展性。它还将改善用户体验,因为它降低了两个用户尝试同时更新一个聚合而引发冲突的可能性。
大
- 因为聚合是事务的范围,所以你可能需要定义更大的聚合以使特定的聚合更新操作满足事务的原子性。
- 成为服务分解障碍
邻域事件
领域事件是聚合发生的事情。事件通常代表状态的变化。领域事件聚合在被创建时,或发生其他重大更改时发布领域事件。
事件内容可以包含接收方需要的信息,来增强事件。但是当接收方需求变化,事件类有修改风险。
为什么需要邻域事件
领域事件很有用,因为应用程序的其他协作方(比如客户端、其他应用程序或同一应用程序中的其他组件)通常有兴趣了解聚合的状态更改。
以下是一些可能的场景:
-
使用基于编排的Saga维护服务之间的数据一致性,如第4章所述。
-
通知维护数据副本的服务,源数据已经发生了更改。这种方法称为命令查询职责隔离(CQRS),我会在第7章中进行详细介绍。
-
通过Webhook或消息代理通知不同的应用程序,以触发下一步业务流程。
-
按顺序通知同一应用程序的不同组件,例如,将WebSocket消息发送到用户的浏览器或更新如ElasticSearch这样的文本数据库。
-
向用户发送短信或电子邮件通知,告诉他们订单已发货、他们的医疗处方已准备就绪,或者他们的航班延误。