CAP
-
一致性(Consistence)
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
-
可用性(Availability)
每一个操作总是能够在一定的时间内返回结果(对数据更新具备高可用性),但是不保证获取的数据为最新数据
-
分区容错性(Partition tolerance)
分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
这里的网络分区是指由于某种原因,网络被分成若干个孤立的区域,而区域之间互不相通。
**为什么CAP总是在CP与AP之间讨论 **是选择Redis的主备集群(AP模型)还是选择ZK、etcd(CP模型)呢
提高可用性加机器。
可用性:我部署两台Redis机器在一个集群中(主备集群),如果此时有一台Redis挂了我客户端照样可以访问另一台Redis,保证了一定程度的可用性(保证允许一台Redis宕机)
主备Redis需要时刻保持数据同步,在A节点的Redis设置了一个M值,然后A节点宕机,有可能B节点的Redis还没来得及同步这个M值,我客户端在B节点读不到M值,这就存在了一致性问题。
分区容错性:这两台主备Redis发生了分区(A、B节点互相连接不上),那就做不了数据同步了,但此时集群依然向外开放服务,此时集群具有分区容错性,如果发生分区,集群就不能对外服务,则集群不具有分区容错性(P特性)
保证P与不保证P的集群是什么样的:
如果没了P,理论上集群不容许任何一个节点发生分区。
当没有分区发生时确实可以保证AC(谁能保证集群系统的节点百分百不会出问题呢?能保证也不需要讨论AC问题了),当发生分区时整个集群不可用,没有现实意义
如果保证P,说明集群就只能从A和C选择其一
CP:若此时不让客户端读取B节点的M值,那么此时不可用,只能让客户端读取A节点,在A节点中M值确实是刚刚客户端Set M = 1值,M值一致,此时是CP模型,可用性被舍弃。
AP:若此时可以让客户端读取B节点的M值,那么此时节点可用,但是读取到的值M=0,如果下次又来一个客户端读取A节点的M值,却读到了M=1,M值不一致,此时是AP模型,一致性被舍弃
Paxos
- Proposer(提案人)只有一个
- Acceptor(接收者)多个
- Learners(学习者)多个
对于一致性算法,安全性(safaty)要求如下:
- 只有被提出的
value才能被选定。 - 只有一个
value被选定 - 如果某个进程认为某个
value被选定了,那么这个value必须是真的被选定的那个。
一致性算法的目标是保证最终有一个提出的 value 被选定。当一个 value 被选定后,进程最终也能学习到这个 value。
阶段一
-
Proposer 选择一个提案编号 N,然后向半数以上的 Acceptor 发送编号为 N 的 Prepare 请求。
Proposer 生成提案之前,应该先去学习已经被选定或者可能被选定的 value,然后以该 value 作为自己提出的提案的 value。如果没有 value 被选定,Proposer 才可以自己决定 value 的值。这样才能达成一致。这个学习的阶段就是通过一个 Prepare 请求实现。
-
如果 Acceptor 收到一个编号为 N 的 Prepare 请求,且 N > 该 Acceptor 已经响应过的所有 Prepare 请求的编号,那么它就会将它已经接受过的编号最大的提案(如果有的话)作为响应反馈给 Proposer,同时该 Acceptor 承诺不再接受任何编号小于N的提案。
阶段二
-
如果 Proposer 收到半数以上 Acceptor 对其发出的编号为 N 的 Prepare 请求的响应,那么它就会发送一个针对
1
[N,V]提案的 Accept 请求给半数以上的 Acceptor。如果响应中不包含任何提案,那么 V 就由 Proposer 自己决定
V 就是收到的响应中编号最大的提案的 value。
-
如果 Accepter 收到一个针对编号为 N 的提案的 Accept 请求,只要该 Acceptor 没有对编号大于 N 的 Prepare 请求作出响应,它就接收该提案。
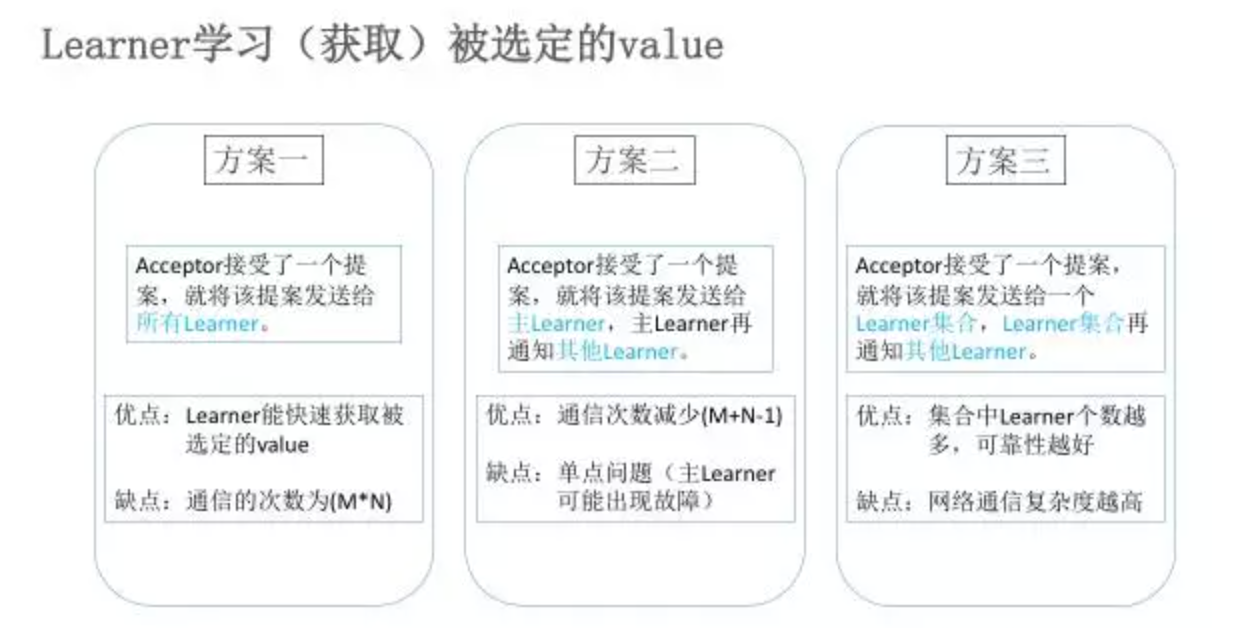
Learner 学习(获取)被选定的value有以下三种方案:
疑问
-
为什么要用“半数以上通过”
过半的思想保证提交的value在同一时刻在分布式系统中是唯一的一致的。
-
当Proposer有很多个的时候,会有什么问题
很难有一个proposer收到半数以上的回复,进而不断地执行第一阶段的协议,决策收敛速度慢,很久都不能做出一个决策。
-
提案为什么要带上编号
为了acceptor可以在自身接受到的提案的对比中做出最终的唯一决策。
RAFT
Raft将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选人(Candidate):
- Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
- Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
- Candidate:Leader选举过程中的临时角色。
Raft要求系统在任意时刻最多只有一个Leader,正常工作期间只有Leader和Followers。
Leader选举
Raft 使用心跳(heartbeat)触发Leader选举。当服务器启动时,初始化为Follower。
Leader向所有Followers周期性发送heartbeat。如果Follower在选举超时时间内没有收到Leader的heartbeat,就会等待一段随机的时间后发起一次Leader选举。
Follower将其当前任期(term)加一然后转换为Candidate。它首先给自己投票并且给集群中的其他服务器发送 RequestVote RPC
三种情况
- 赢得了多数的选票,成功选举为Leader;
- 收到了Leader的消息,表示有其它服务器已经抢先当选了Leader;
- 没有服务器赢得多数的选票,Leader选举失败,等待选举时间超时后发起下一次选举。
选举出Leader后,Leader通过定期向所有Followers发送心跳信息维持其统治。若Follower一段时间未收到Leader的心跳则认为Leader可能已经挂了,再次发起Leader选举过程。
日志同步
每次改变数据先记录日志,日志未提交不能改节点的数值。然后 LEADER 会复制数据给其他 Follower 节点,并等大多数节点写日志成功再提交数据。
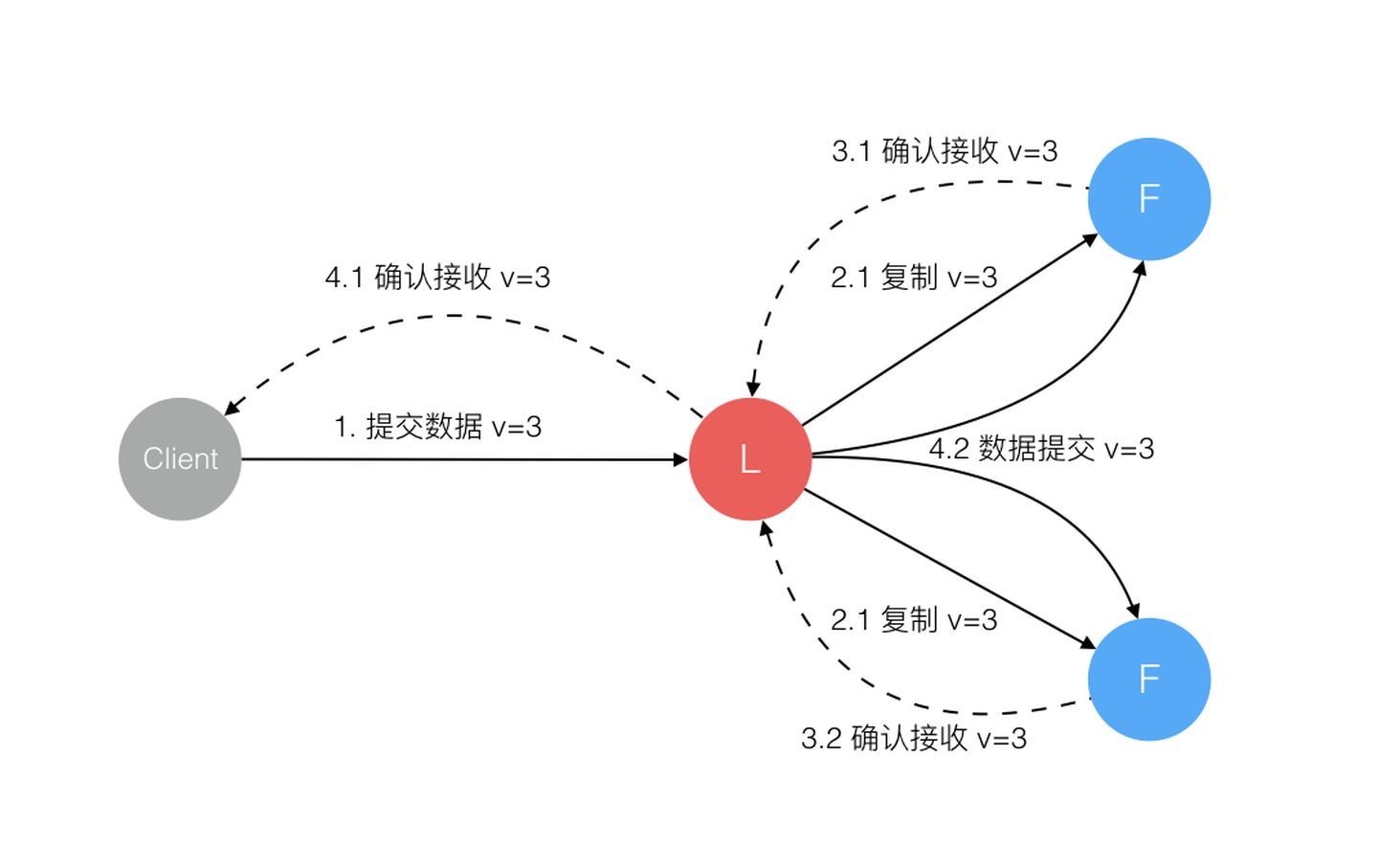
某些Followers可能没有成功的复制日志,Leader会无限的重试 AppendEntries RPC直到所有的Followers最终存储了所有的日志条目。
日志由有序编号(log index)的日志条目组成。每个日志条目包含它被创建时的任期号(term),和用于状态机执行的命令。如果一个日志条目被复制到大多数服务器上,就被认为可以提交(commit)了。
Raft日志同步保证如下两点:
- 如果不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的。
- 如果不同日志中的两个条目有着相同的索引和任期号,则它们之前的所有条目都是完全一样的。
安全性
-
拥有最新的已提交的log entry的Follower才有资格成为Leader。
Candidate在发送RequestVote RPC时,要带上自己的最后一条日志的term和log index,其他节点收到消息时,如果发现自己的日志比请求中携带的更新,则拒绝投票。日志比较的原则是,如果本地的最后一条log entry的term更大,则term大的更新,如果term一样大,则log index更大的更新。