容器 VS 虚拟机
虚拟机依赖硬件设备来提供资源隔离,需要更大的资源开销
虚拟机
虚拟机理论上是一个真实的计算机操作系统的封装,它运行在物理设备之上,通过 Hypervisor 进行建立和运行虚拟机体系
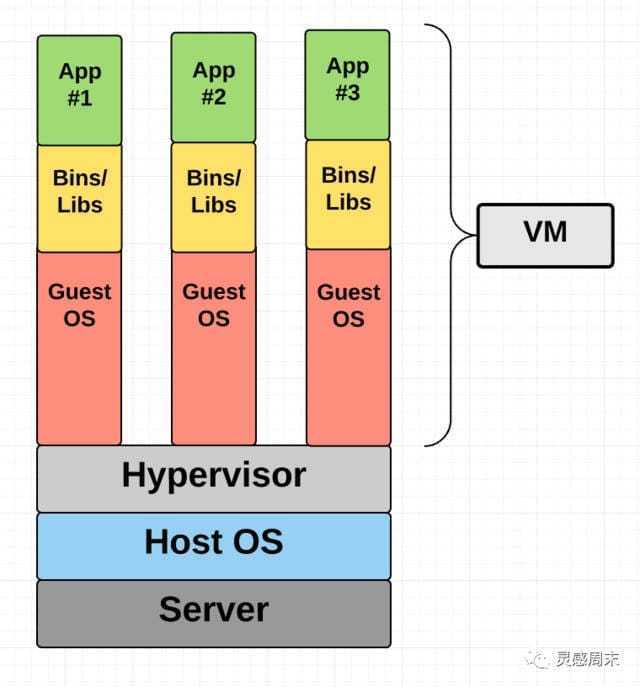
在 Host OS 的基础上,通过 Hypervisor 来进行虚拟机资源控制,并拥有自己的 Guest OS,虽然隔离得更彻底,但是显然资源的开销会更大。
容器
容器技术提供的是操作系统级别的进程隔离,Docker 本身只是操作系统的一个进程,只是在容器技术下,进程之间网络、空间等等是隔离的,互不知道彼此。
多个容器之间是共享了宿主机的操作系统内核。在 Host OS 上,通过 Docker Engine 共享 Host OS 的内核
cgroup 和 namespace 两者对比:
-
两者都是将进程进行分组
-
namespace 是为了隔离进程组之间的资源
-
cgroup 是为了对一组进程进行统一的资源监控和限制。
Docker 的资源隔离Namespace
Docker 正式利用了 Linux Namespace 来实现这一能力,Linux Namespace 是 Linux 提供的一种机制,可以实现不同资源的隔离。

namespace 是 Linux 内核用来隔离内核资源的方式
通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
Linux Namespace API :
- clone - 创建一个新进程
- setns - 允许进程重新加入一个已经存在的 Namespace
- unshare - 将调用进程移动到新的 Namespace
正是这三个 Namespace 操作的 API,使得 Docker 可以在进程级别实现 “独立环境” 的能力。
unshare 示例一下 namespace 创立的过程。容器中 namespace 的创建其实都是用 unshare 这个系统调用来创建的。
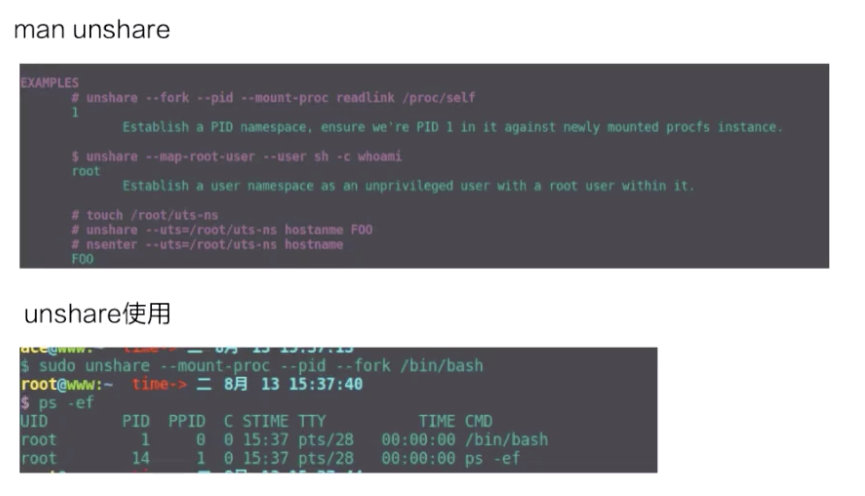
上图上半部分是 unshare 使用的一个例子,下半部分是我实际用 unshare 这个命令去创建的一个 pid namespace。可以看到这个 bash 进程已经是在一个新的 pid namespace 里面,然后 ps 看到这个 bash 的 pid 现在是 1,说明它是一个新的 pid namespace。
namespace 是用来做资源隔离的,Linux 内核上有七种 namespace,docker 中用到了前六种。第七种 cgroup namespace 在 docker 本身并没有用到,但是在 runC 实现中实现了 cgroup namespace。
-
mout namespace。mout namespace 就是保证容器看到的文件系统的视图,是容器镜像提供的一个文件系统,也就是说它看不见宿主机上的其他文件,除了通过 -v 参数 bound 的那种模式,是可以把宿主机上面的一些目录和文件,让它在容器里面可见的。
-
uts namespace,这个 namespace 主要是隔离了 hostname 和 domain。
-
pid namespace,这个 namespace 是保证了容器的 init 进程是以 1 号进程来启动的。
-
network namespace,除了容器用 host 网络这种模式之外,其他所有的网络模式都有一个自己的 network namespace 的文件。
-
user namespace,这个 namespace 是控制用户 UID 和 GID 在容器内部和宿主机上的一个映射,不过这个 namespace 用的比较少。
-
IPC namespace,这个 namespace 是控制了进程兼通信的一些东西,比方说信号量。
-
cgroup namespace,上图右边有两张示意图,分别是表示开启和关闭 cgroup namespace。用 cgroup namespace 带来的一个好处是容器中看到的 cgroup 视图是以根的形式来呈现的,这样的话就和宿主机上面进程看到的 cgroup namespace 的一个视图方式是相同的。另外一个好处是让容器内部使用 cgroup 会变得更安全。
Docker 的资源限制:cgroups
CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物力资源 (如 cpu memory i/o 等等) 的机制。

容器中常用的和不常用的,这个区别是对 docker 来说的,因为对于 runC 来说,除了最下面的 rdma,所有的 cgroup 其实都是在 runC 里面支持的,但是 docker 并没有开启这部分支持,所以说 docker 容器是不支持下图这些 cgroup 的。
两种 cgroup 驱动
cgroup 主要是做资源限制的,docker 容器有两种 cgroup 驱动:一种是 systemd 的,另外一种是 cgroupfs 的。

-
cgroupfs 比较好理解。比如说要限制内存是多少,要用 CPU share 为多少,其实直接把 pid 写入对应的一个 cgroup 文件,然后把对应需要限制的资源也写入相应的 memory cgroup 文件和 CPU 的 cgroup 文件就可以了。
-
另外一个是 systemd 的一个 cgroup 驱动。这个驱动是因为 systemd 本身可以提供一个 cgroup 管理方式。所以如果用 systemd 做 cgroup 驱动的话,所有的写 cgroup 操作都必须通过 systemd 的接口来完成,不能手动更改 cgroup 的文件。
容器中常用的 cgroup
接下来看一下容器中常用的 cgroup。Linux 内核本身是提供了很多种 cgroup,但是 docker 容器用到的大概只有下面六种:

- CPU,CPU 一般会去设置 cpu share 和 cupset,控制 CPU 的使用率。
- memory,是控制进程内存的使用量。
- device ,device 控制了你可以在容器中看到的 device 设备。
- freezer。它和第三个 cgroup(device)都是为了安全的。当你停止容器的时候,freezer 会把当前的进程全部都写入 cgroup,然后把所有的进程都冻结掉,这样做的目的是,防止你在停止的时候,有进程会去做 fork。这样的话就相当于防止进程逃逸到宿主机上面去,是为安全考虑。
- blkio,blkio 主要是限制容器用到的磁盘的一些 IOPS 还有 bps 的速率限制。因为 cgroup 不唯一的话,blkio 只能限制同步 io,docker io 是没办法限制的。
- pid cgroup,pid cgroup 限制的是容器里面可以用到的最大进程数量。
Docker 的本质还是一个进程,在多个 Docker 进程的情况下,如果其中一个进程就占满了所有的 CPU 与内存,其他进程处于忙等而导致服务无响应,这是难以想象的。因此除了 Namespace 隔离,还需要通过另外一种技术来限制进程资源使用大小情况:cgroups(control groups)。
cgroups 用来将进程统一分组,并用于控制进程的内存、CPU 以及网络等资源使用。cgroups 会将系统进程组成成独立的树,树的节点是进程组,每棵树与一个或者多个 subsystem 关联。subsystem 的作用就是对组进行操作。
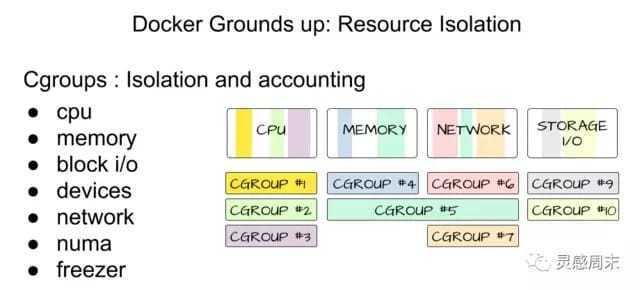
cgroups 的全称是control groups,是Linux内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu,内存等资源实现精细化的控制。
Cgroups的实现也很有意思,它并不是一组系统调用,linux将其实现为了文件系统,这很符合Unix一切皆文件的哲学,因此我们可以直接查看。
系统已经自动在sys/fs/cgroup目录下挂载好了相应文件,每个文夹件代表了上面所讲的某种资源类型。
默认情况下,docker 启动一个容器后,就会在 /sys/fs/cgroup 目录下的各个资源目录下生成以容器 ID 为名字的目录,在容器被 stopped 后,该目录被删除。那么,对容器资源进行控制的方式,就同上边的例子一样,显而易见了。
Docker 存储驱动:Union File Systems
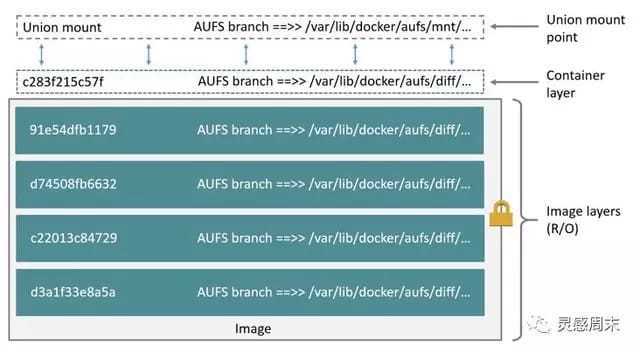
docker 镜像是基于联合文件系统的。简单描述一下联合文件系统(Union File Systems):大概的意思就是说,它允许文件是存放在不同的层级上面的,但是最终是可以通过一个统一的视图,看到这些层级上面的所有文件。
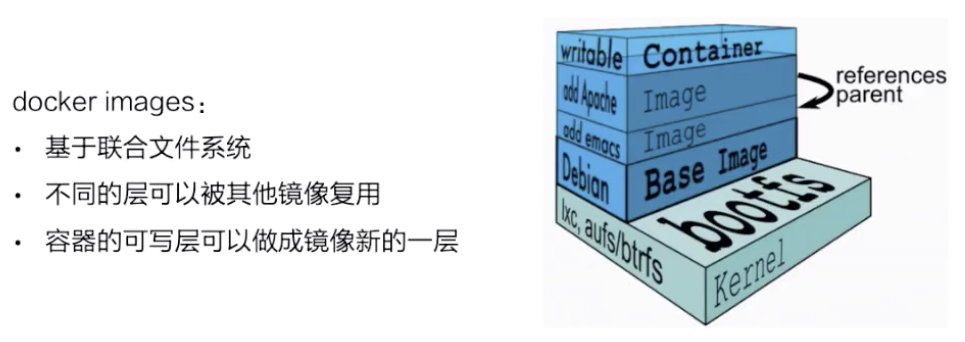
如上图所示,右边是从 docker 官网拿过来的容器存储的一个结构图。这张图非常形象的表明了 docker 的存储,docker 存储也就是基于联合文件系统,是分层的。每一层是一个 Layer,这些 Layer 由不同的文件组成,它是可以被其他镜像所复用的。可以看一下,当镜像被运行成一个容器的时候,最上层就会是一个容器的读写层。这个容器的读写层也可以通过 commit 把它变成一个镜像顶层最新的一层。
Docker 中最典型的存储驱动就是 AUFS(Advanced Multi-layered unification filesytem),可以将 AUFS 想象为一个可以 “栈式叠加” 的文件系统,AUFS 允许在一个基础的文件系统的上,“增量式” 的增加文件。
AUFS 支持将不同目录挂载到同一个目录下,这种挂载对用户来说是透明的。通常,AUFS 最上层是可读写层,而最底层是只读层,每一层都是一个普通的文件系统。
以 overlay 为例
存储流程
接下来我们以 overlay 这个文件系统为例,看一下 docker 镜像是怎么在磁盘上进行存储的。先看一下下面这张图,简单地描述了 overlay 文件系统的工作原理 。
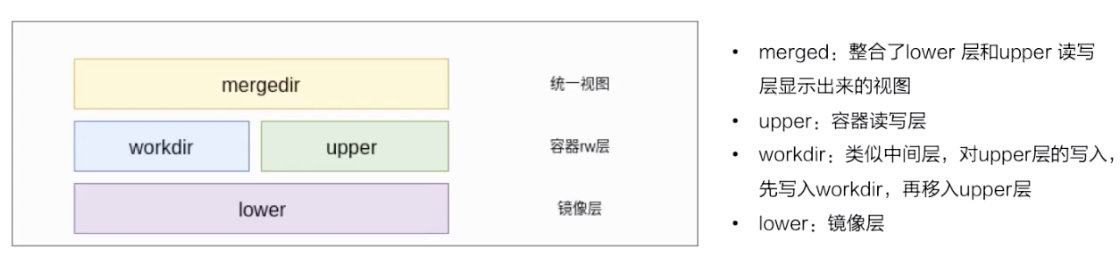
最下层是一个 lower 层,也就是镜像层,它是一个只读层。右上层是一个 upper 层,upper 是容器的读写层,upper 层采用了写实复制的机制,也就是说只有对某些文件需要进行修改的时候才会从 lower 层把这个文件拷贝上来,之后所有的修改操作都会对 upper 层的副本进行修改。
upper 并列的有一个 workdir,它的作用是充当一个中间层的作用。也就是说,当对 upper 层里面的副本进行修改时,会先放到 workdir,然后再从 workdir 移到 upper 里面去,这个是 overlay 的工作机制。
最上面的是 mergedir,是一个统一视图层。从 mergedir 里面可以看到 upper 和 lower 中所有数据的整合,然后我们 docker exec 到容器里面,看到一个文件系统其实就是 mergedir 统一视图层。
文件操作
接下来我们讲一下基于 overlay 这种存储,怎么对容器里面的文件进行操作?

先看一下读操作,容器刚创建出来的时候,upper 其实是空的。这个时候如果去读的话,所有数据都是从 lower 层读来的。
写操作如刚才所提到的,overlay 的 upper 层有一个写实数据的机制,对一些文件需要进行操作的时候,overlay 会去做一个 copy up 的动作,然后会把文件从 lower 层拷贝上来,之后的一些写修改都会对这个部分进行操作。
然后看一下删除操作,overlay 里面其实是没有真正的删除操作的。它所谓的删除其实是通过对文件进行标记,然后从最上层的统一视图层去看,看到这个文件如果做标记,就会让这个文件显示出来,然后就认为这个文件是被删掉的。这个标记有两种方式:
- 一种是 whiteout 的方式。
- 第二个就是通过设置目录的一个扩展权限,通过设置扩展参数来做到目录的删除。
操作步骤
接下来看一下实际用 docker run 去启动 busybox 的容器,它的 overlay 的挂载点是什么样子的?

第二张图是 mount,可以看到这个容器 rootfs 的一个挂载,它是一个 overlay 的 type 作为挂载的。里面包括了 upper、lower 还有 workdir 这三个层级。
接下来看一下容器里面新文件的写入。docker exec 去创建一个新文件,diff 这个从上面可以看到,是它的一个 upperdir。再看 upperdir 里面有这个文件,文件里面的内容也是 docker exec 写入的。
最后看一下最下面的是 mergedir,mergedir 里面整合的 upperdir 和 lowerdir 的内容,也可以看到我们写入的数据。
chroot
在这里不得不简单介绍一下 chroot(change root),在 Linux 系统中,系统默认的目录就都是以 / 也就是根目录开头的,chroot 的使用能够改变当前的系统根目录结构,通过改变当前系统的根目录,我们能够限制用户的权利,在新的根目录下并不能够访问旧系统根目录的结构个文件,也就建立了一个与原系统完全隔离的目录结构。
与 chroot 的相关内容部分来自 理解 chroot 一文,各位读者可以阅读这篇文章获得更详细的信息。
cgroup v2
在 Linux 上,控制组约束分配给进程的资源。
kubelet 和底层容器运行时都需要对接 cgroup 来强制执行为 Pod 和容器管理资源, 这包括为容器化工作负载配置 CPU/内存请求和限制。
Linux 中有两个 cgroup 版本:cgroup v1 和 cgroup v2。cgroup v2 是新一代的 cgroup API。
cgroup v2 对 cgroup v1 进行了多项改进,例如:
- API 中单个统一的层次结构设计
- 更安全的子树委派给容器
- 更新的功能特性, 例如压力阻塞信息(Pressure Stall Information,PSI)
- 跨多个资源的增强资源分配管理和隔离
- 统一核算不同类型的内存分配(网络内存、内核内存等)
- 考虑非即时资源变化,例如页面缓存回写
一些 Kubernetes 特性专门使用 cgroup v2 来增强资源管理和隔离。 例如,MemoryQoS 特性改进了内存 QoS 并依赖于 cgroup v2 原语。
与 v1 不同,cgroup v2 只有单个层级树(single hierarchy)。 用如下命令挂载 v2 hierarchy:
- 所有支持 v2 且未绑定到 v1 的控制器,会被自动绑定到 v2 hierarchy,出现在 root 层级中。
- v2 中未在使用的控制器(not in active use),可以绑定到其他 hierarchies。
这说明我们能以完全后向兼容的方式,混用 v2 和 v1 hierarchy。
识别 Linux 节点上的 cgroup 版本
cgroup 版本取决于正在使用的 Linux 发行版和操作系统上配置的默认 cgroup 版本。 要检查你的发行版使用的是哪个 cgroup 版本,请在该节点上运行 stat -fc %T /sys/fs/cgroup/ 命令:
1 | |
对于 cgroup v2,输出为 cgroup2fs。
对于 cgroup v1,输出为 tmpfs。
容器路径
将所有内容放在一起查看 Docker 容器的内存指标,查看以下路径:
/sys/fs/cgroup/memory/docker/<longid>/在 cgroup v1 上,cgroupfs驱动程序/sys/fs/cgroup/memory/system.slice/docker-<longid>.scope/在 cgroup v1 上,systemd驱动程序/sys/fs/cgroup/docker/<longid>/在 cgroup v2 上,cgroupfs驱动程序/sys/fs/cgroup/system.slice/docker-<longid>.scope/在 cgroup v2 上,systemd驱动程序
容器指标
CPU 指标:cpuacct.stat
现在我们已经介绍了内存指标,相比之下其他一切都很简单。CPU 指标在 cpuacct控制器中。
对于每个容器,一个伪文件cpuacct.stat包含容器进程累积的 CPU 使用率,细分为user时间 system。区别在于:
user时间是进程直接控制 CPU 执行进程代码的时间量。systemtime 是内核代表进程执行系统调用的时间。
这些时间以 1/100 秒的滴答声表示,也称为“用户 jiffies”。每秒 有USER_HZ “jiffies”USER_HZ ,在 x86 系统上是 100。从历史上看,这恰好映射到调度程序每秒“滴答”的数量,但更高频率的调度和 无滴答内核使滴答数变得无关紧要。
内存指标:memory.stat
内存指标位于“memory”cgroup 中。内存控制组增加了一点开销,因为它对主机上的内存使用情况进行了非常细粒度的统计。因此,许多发行版选择默认不启用它。通常,要启用它,您所要做的就是添加一些内核命令行参数: cgroup_enable=memory swapaccount=1.
驱动
cgroupfs 驱动程序
该cgroupfs驱动程序是 kubelet 中默认的 cgroup 驱动程序。使用驱动程序时cgroupfs ,kubelet 和容器运行时直接与 cgroup 文件系统交互以配置 cgroups。
当 systemd是初始化系统时,不推荐使用该cgroupfs驱动程序,因为 systemd 需要系统上的单个 cgroup 管理器。此外,如果您使用cgroup v2 ,请使用cgroup 驱动程序而不是 .systemdcgroupfs
systemd cgroup 驱动程序
When systemd is chosen as the init system for a Linux distribution, the init process generates and consumes a root control group ( cgroup) and acts as a cgroup manager.
systemd 与 cgroups 紧密集成,并为每个 systemd 单元分配一个 cgroup。因此,如果您将systemdinit 系统与cgroupfs 驱动程序一起使用,系统将获得两个不同的 cgroup 管理器。
两个 cgroup 管理器导致系统中可用和正在使用的资源的两个视图。在某些情况下,配置为用于cgroupfskubelet 和容器运行时但用于systemd其余进程的节点在资源压力下变得不稳定。
减轻这种不稳定性的方法是systemd当 systemd 是选定的初始化系统时,将其用作 kubelet 和容器运行时的 cgroup 驱动程序。
要设置systemd为cgroup 驱动程序,编辑选项 KubeletConfiguration 并将cgroupDriver其设置为systemd。