分片

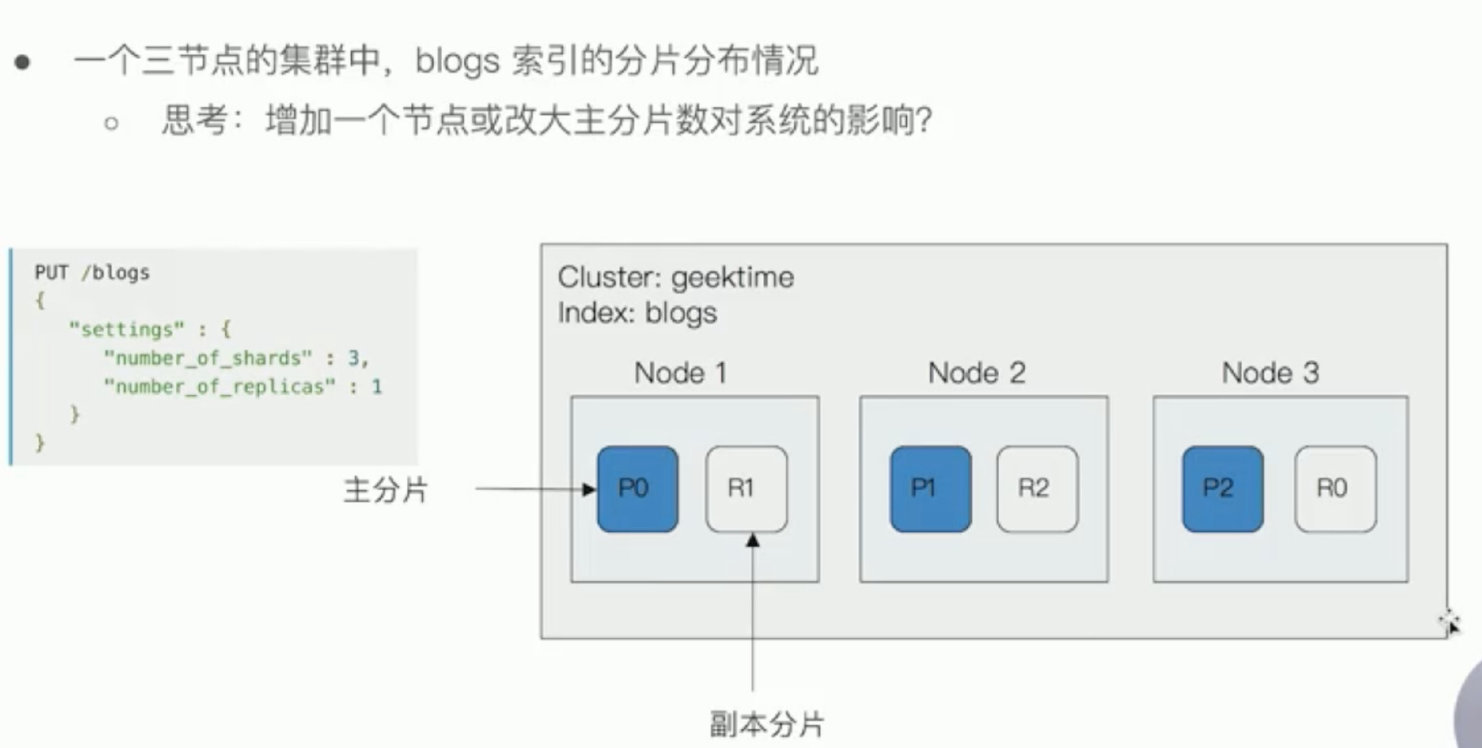

主分片

副本分片

分片数设定

分片过多 增加节点 rebalance

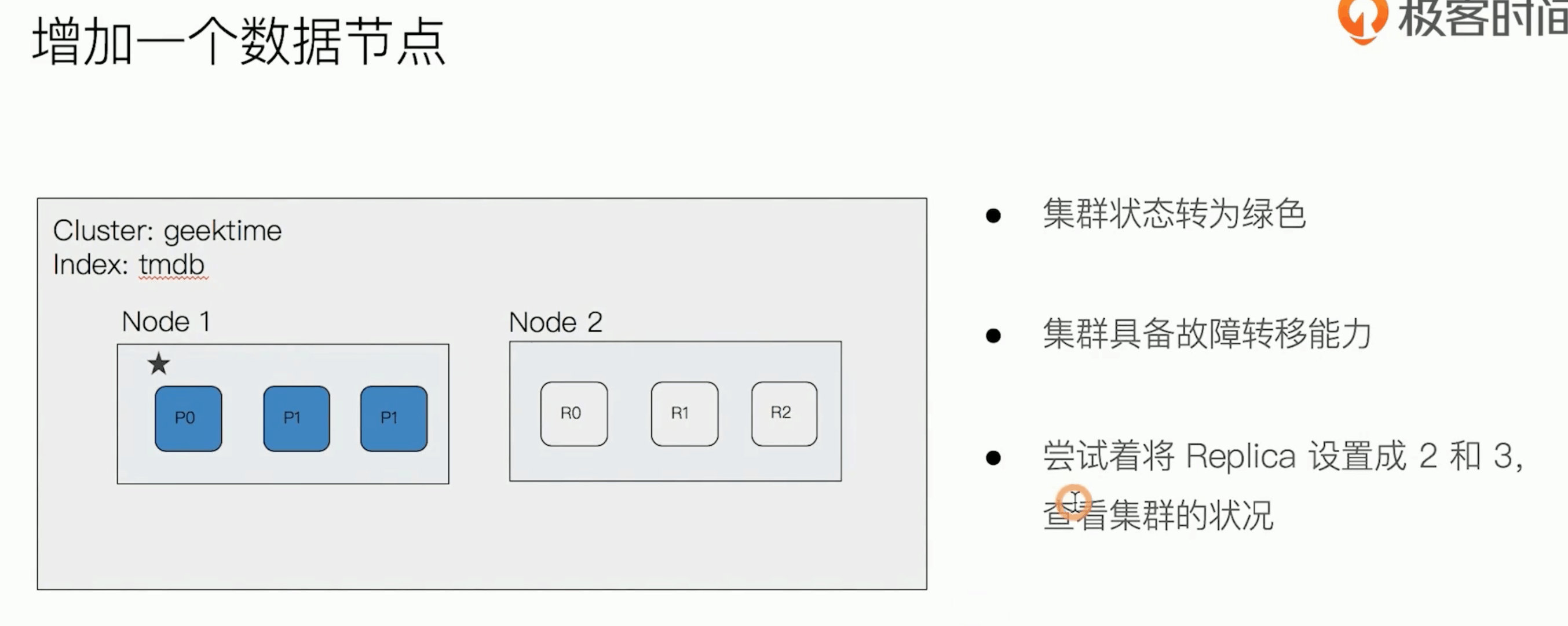
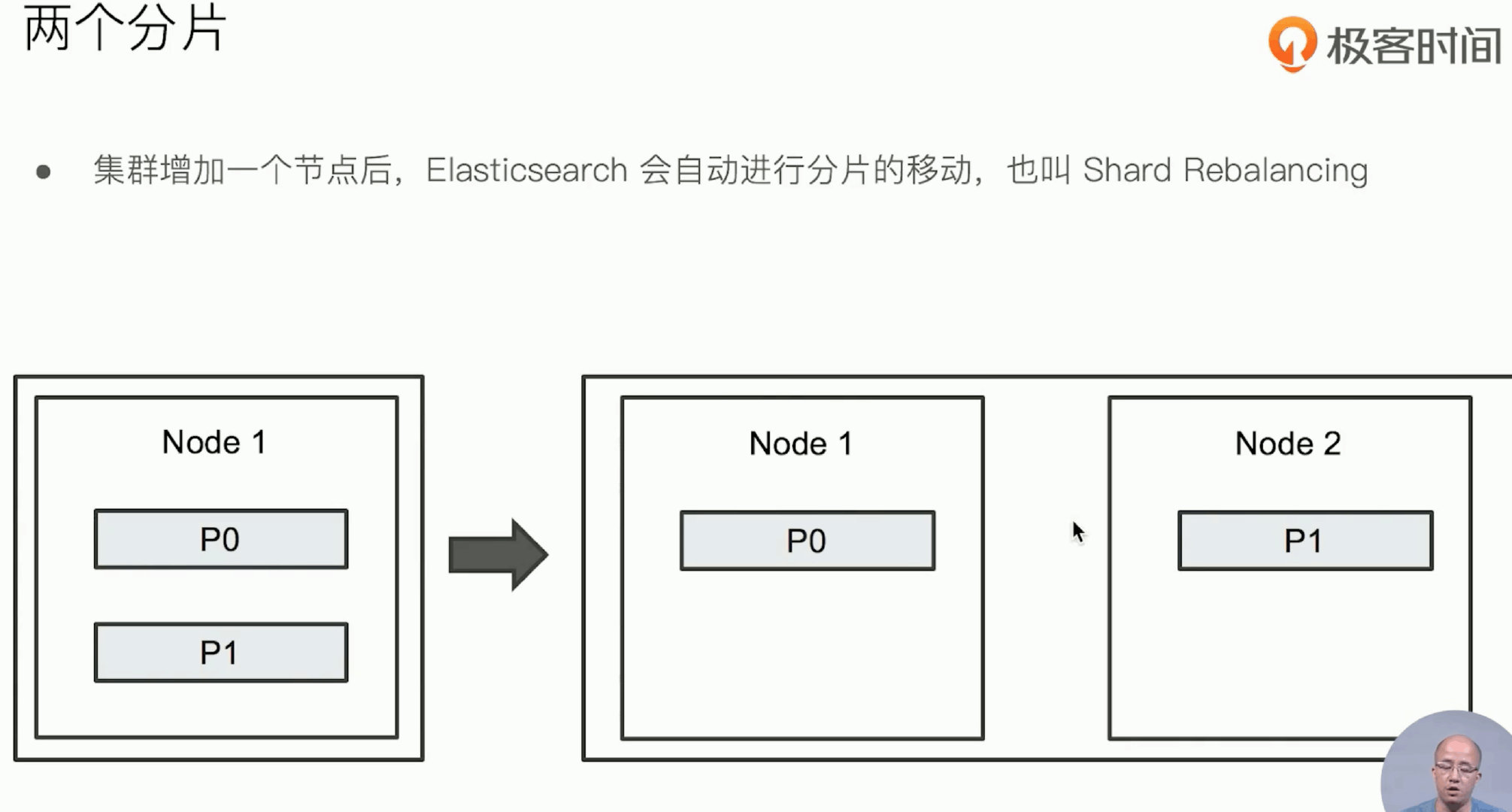
增加一台服务器,此时shard是如何分配的呢
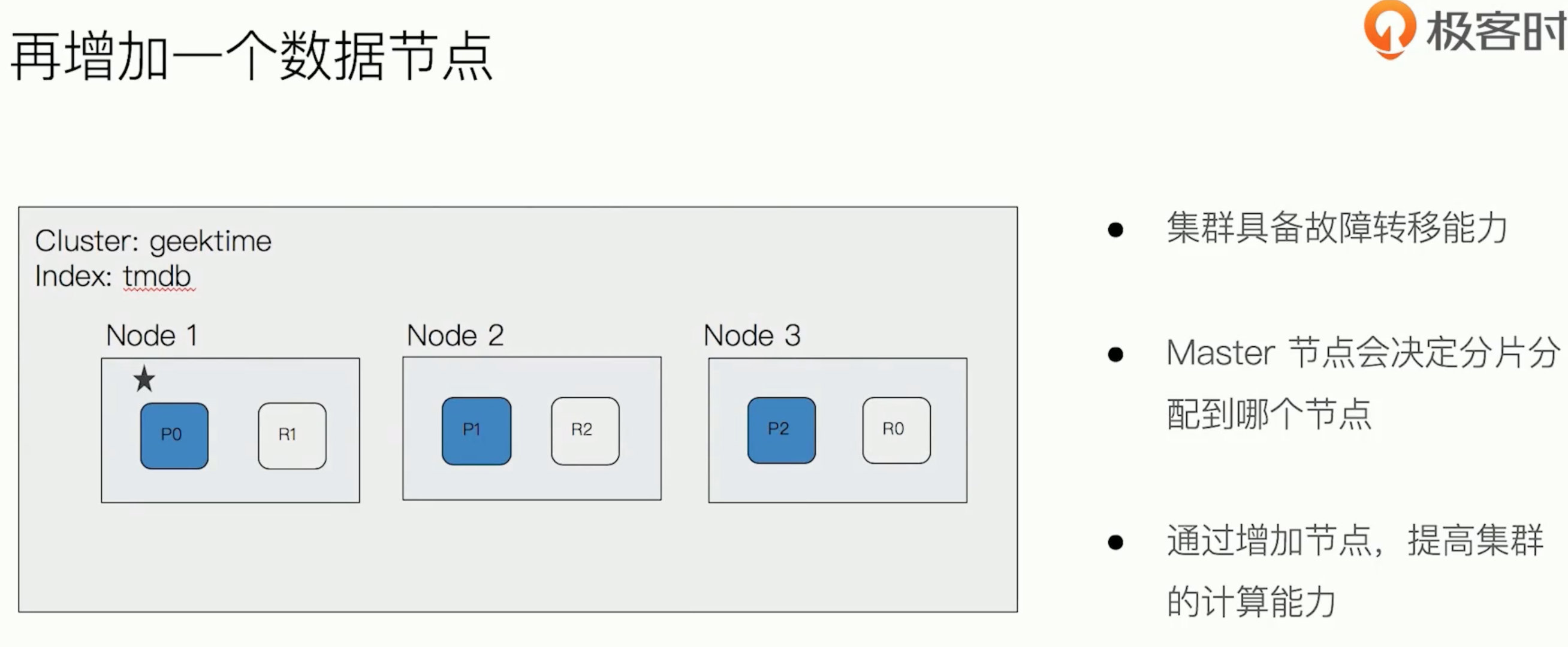
Rebalance(再平衡),当集群中节点数量发生变化时,将会触发es集群的rebalance,即重新分配shard。Rebalance的原则就是尽量使shard在节点中分布均匀,primary shard和replica shard不能分配到一个节点上的,达到负载均衡的目的。
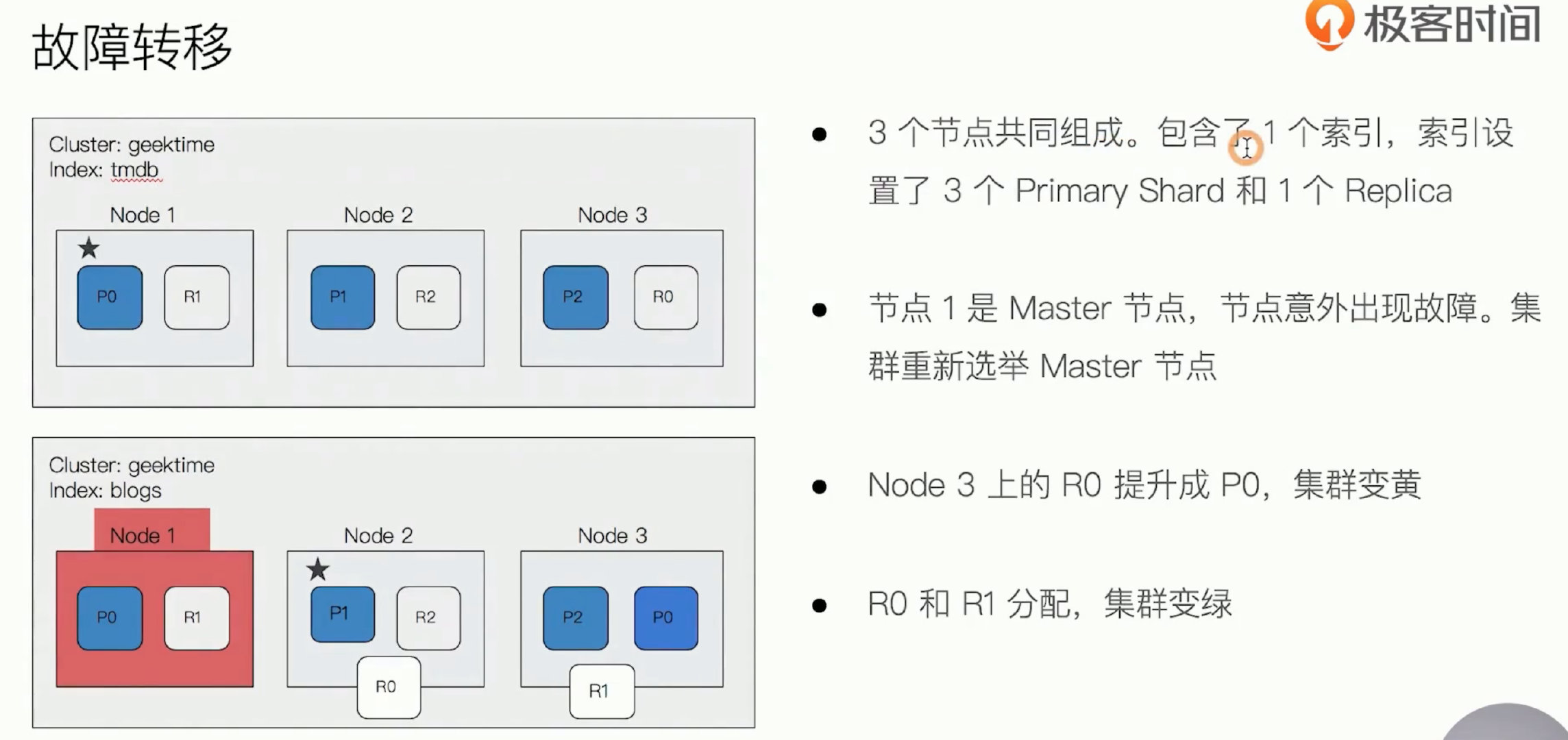
故障转移 集群容灾
-
primary shard 所在节点发生故障(red, 因为部分主分片不可用)
- 当es集群中的master节点发生故障,重新选举master节点。
- master行驶其分片分配的任务。
-
master会寻找node1节点上的P0分片的replica shard, replica shard将被提升为primary shard。这个升级过程是瞬间完成,集群的健康状态为yellow,因为不是每一个replica shard都是active的。
- R0 也会重新分配,集群变绿

文档保存到分片

所以设置好index后主分片数不能改,整个存储完全不一样

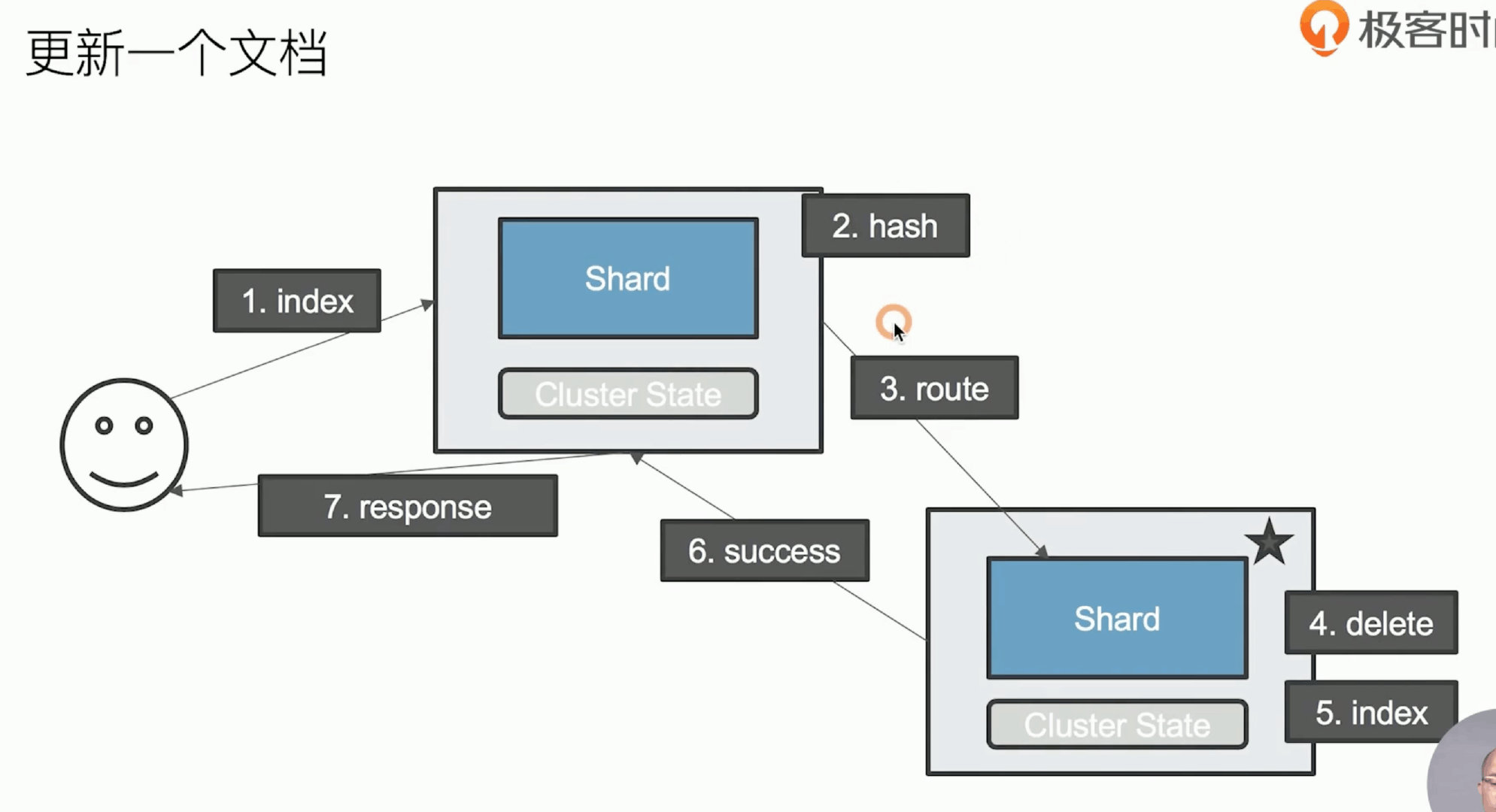
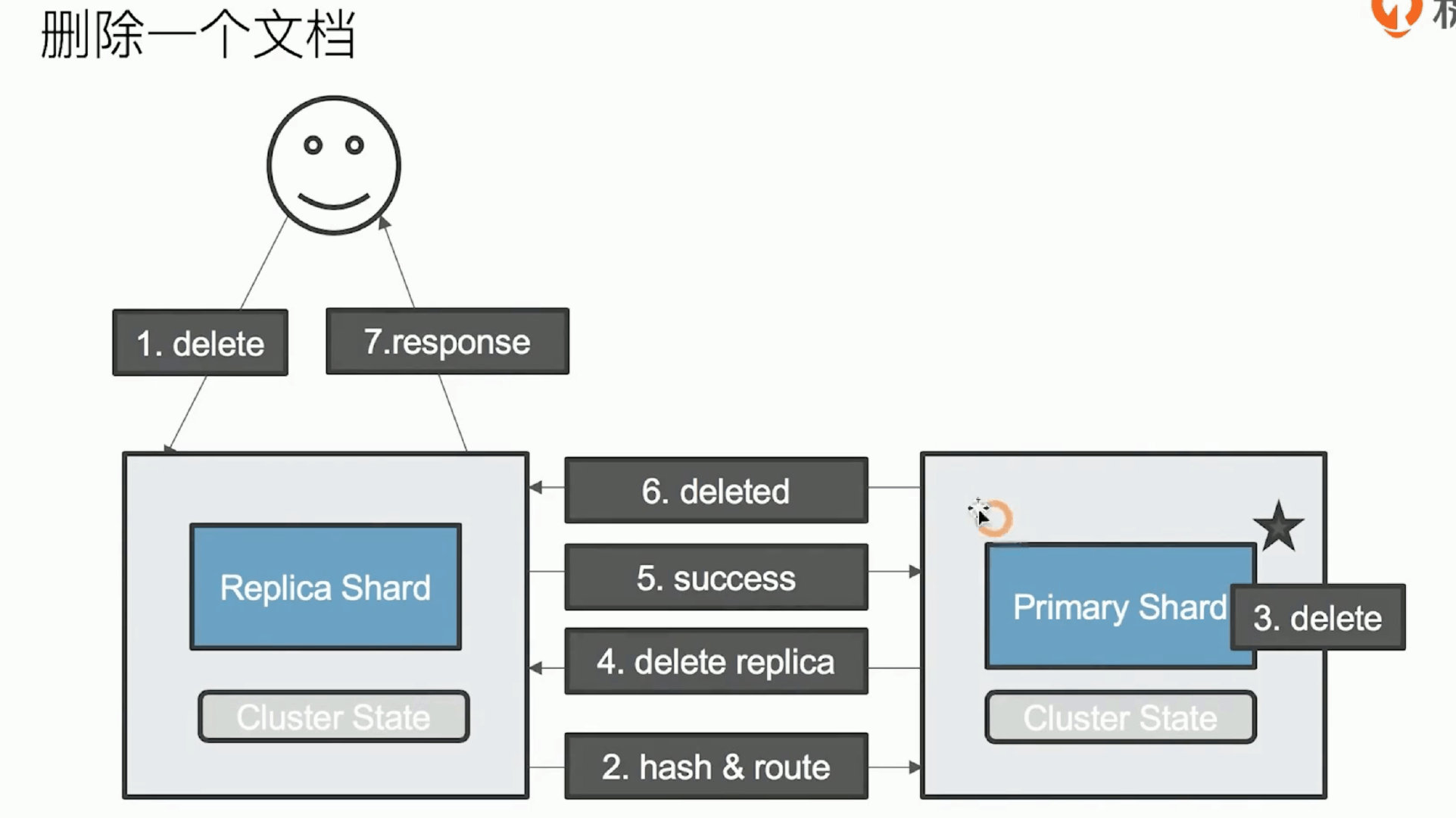
分片设计






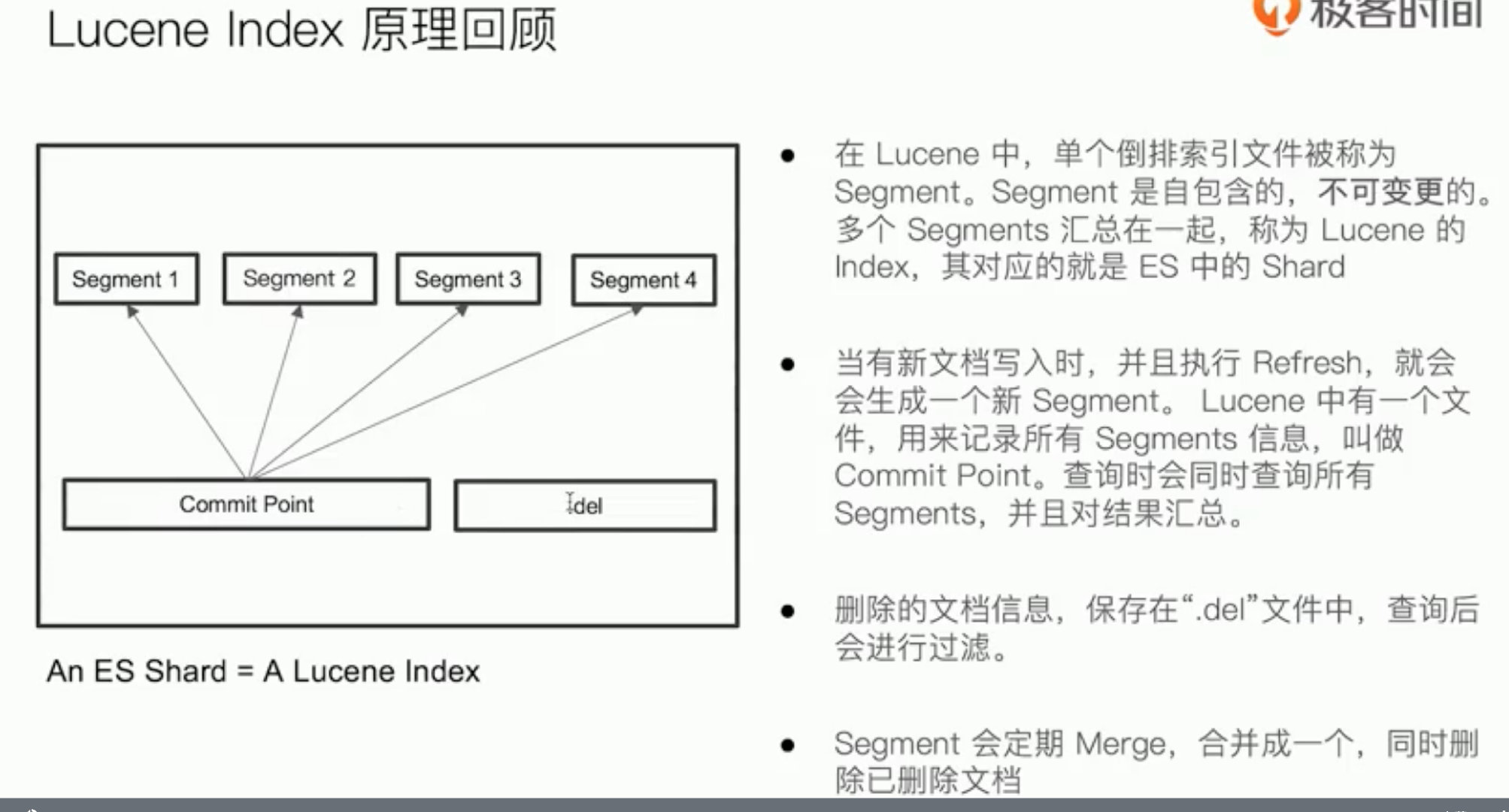
分片机制 写入原理
倒排索引不可变性

删除的文档不会立即清理
多个segment(倒排索引文件)=> lucene index => es shard
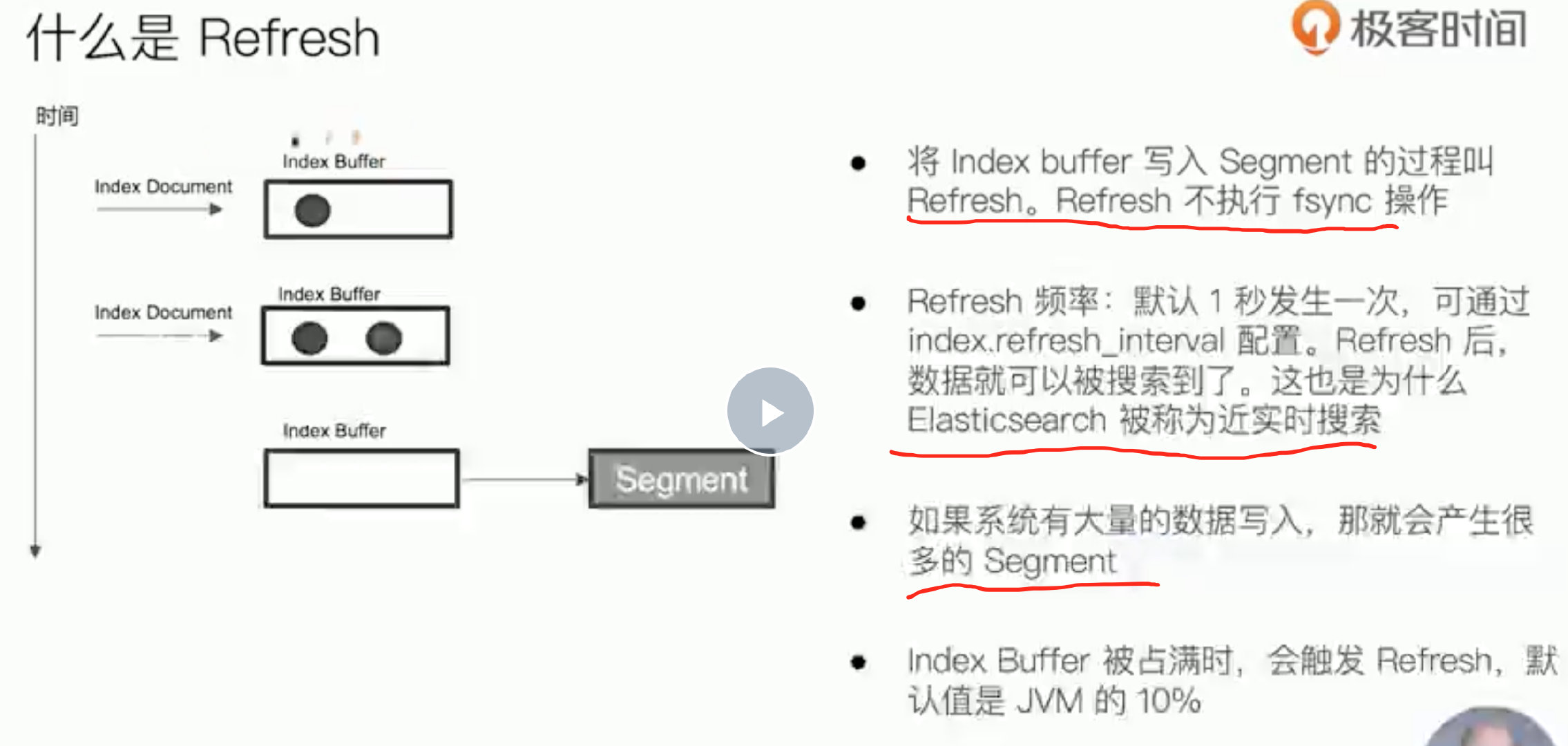
refresh
数据先入buffer buffer 到 segment过程叫refresh
refresh后才数据会被搜索到
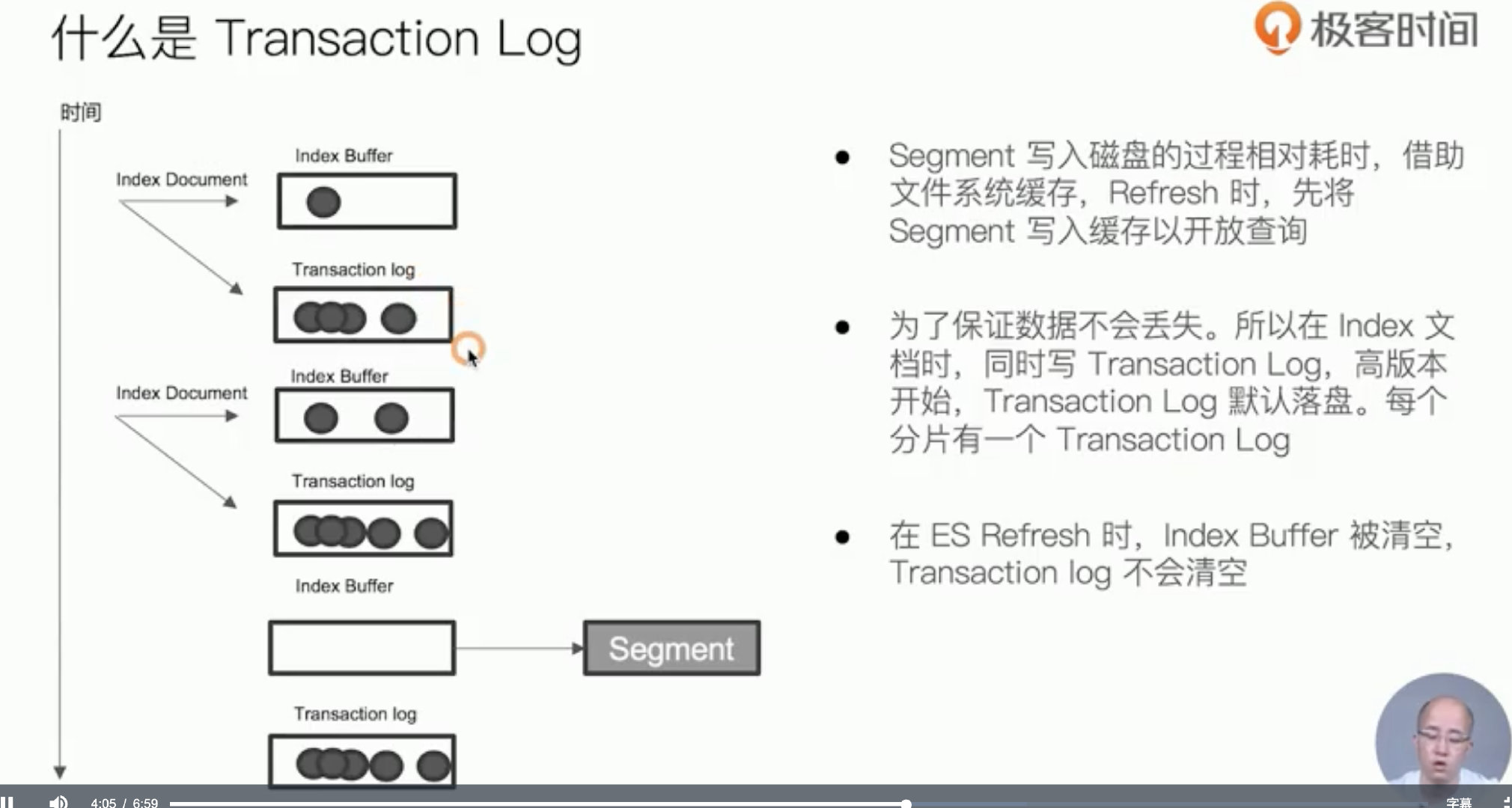
Transaction Log
防断电
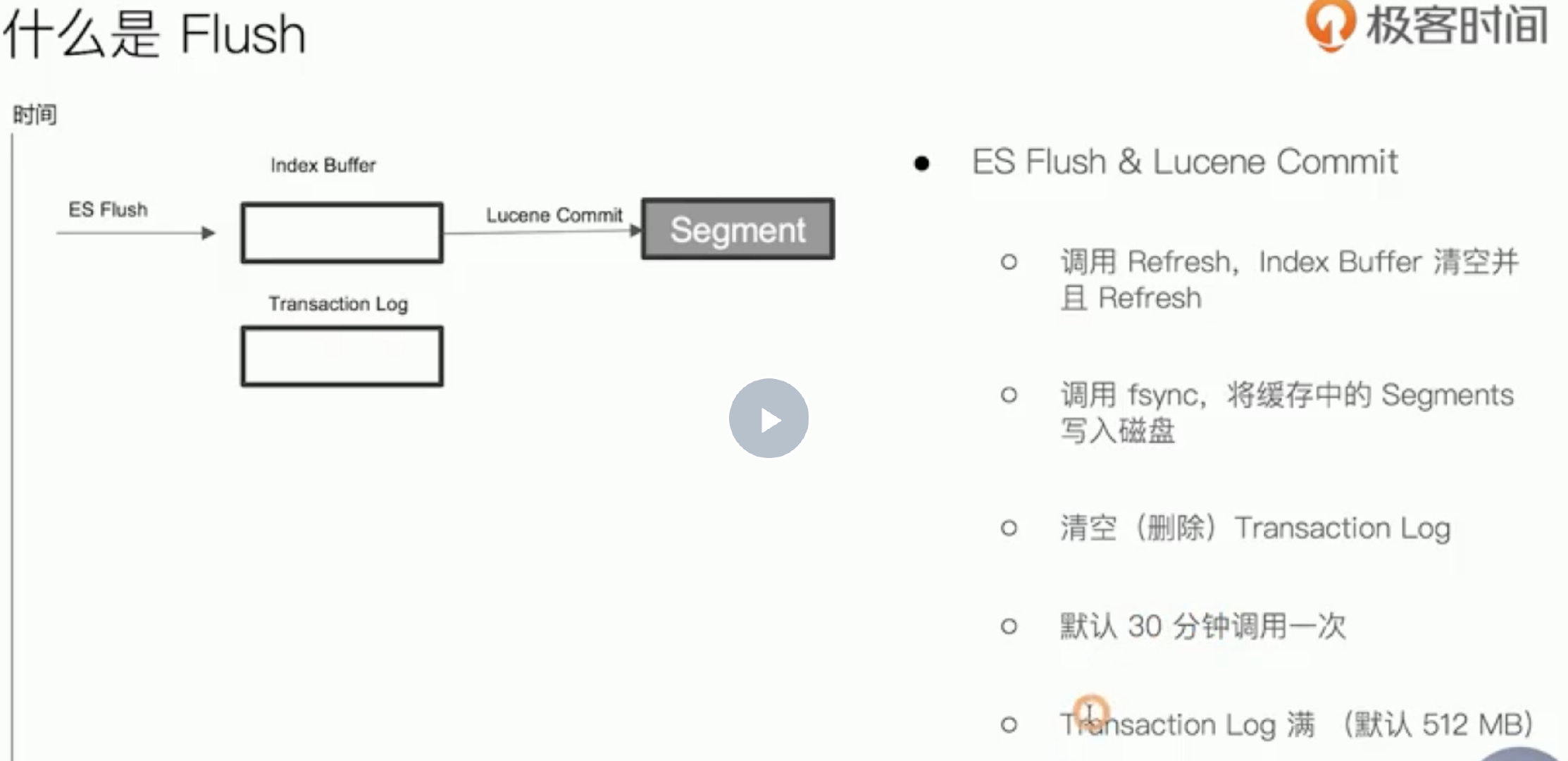
flush
总结
插入
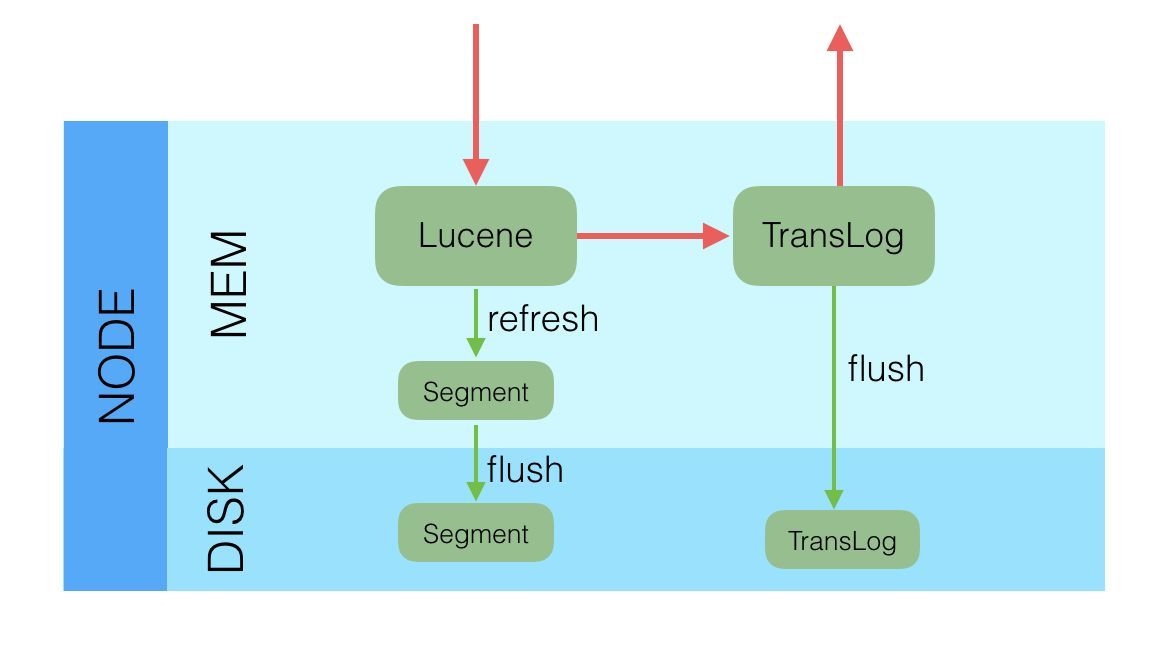
写入操作的延时就等于latency = Latency(Primary Write) + Max(Replicas Write)。只要有副本在,写入延时最小也是两次单Shard的写入时延总和,写入效率会较低。
Elasticsearch是先写内存,最后才写TransLog,一种可能的原因是Lucene的内存写入会有很复杂的逻辑,很容易失败,比如分词,字段长度超过限制等,比较重,为了避免TransLog中有大量无效记录,减少recover的复杂度和提高速度,所以就把写Lucene放在了最前面。二是写Lucene内存后,并不是可被搜索的,需要通过Refresh把内存的对象转成完整的Segment后,然后再次reopen后才能被搜索,一般这个时间设置为1秒钟,导致写入Elasticsearch的文档,最快要1秒钟才可被从搜索到
update
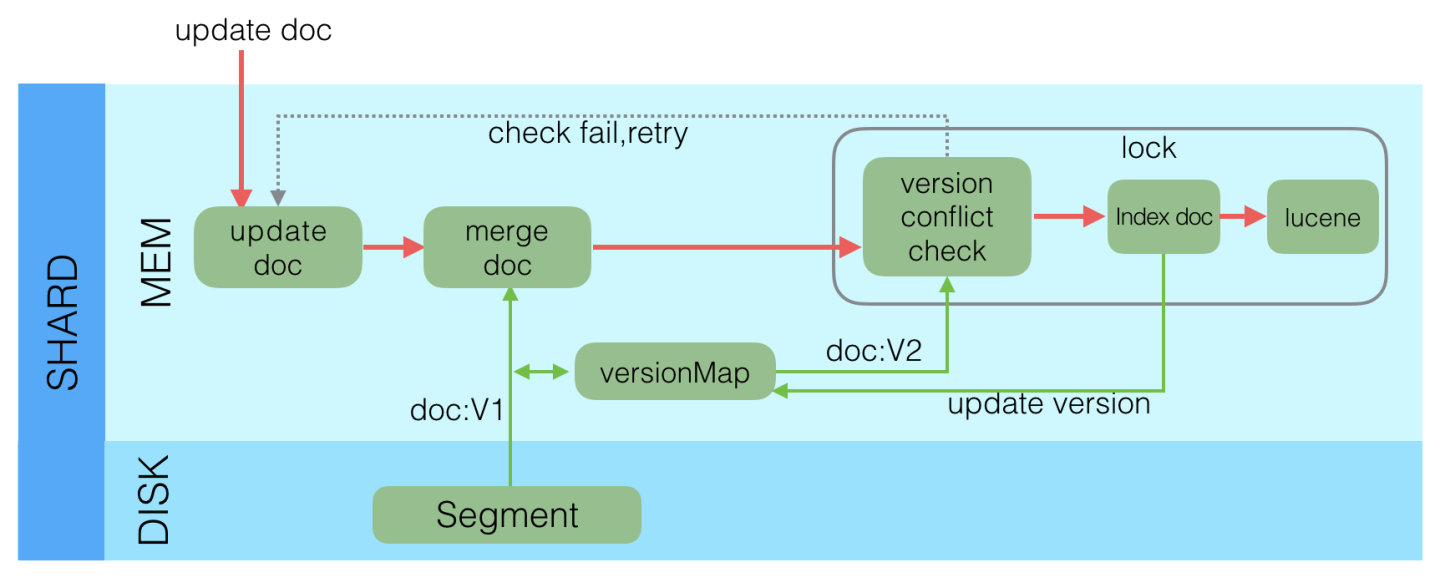
merge
