安装
HDP安装
避免组件之间不同版本的冲突
要设置好hostname hostname -f
hive mysql-connector-java.jar 404 not found
add new hosts 一直都是preparing
tail -f /var/log/ambari-server/ambari-server.log
Error executing bootstrap Cannot create /var/run/ambari-server/bootstrap
pom scope
编译,测试,运行
- 默认compile 打包的时候通常需要包含进去
- test 仅参与测试相关的工作,包括测试代码的编译,执行
- provided 不会将包打入本项目中,只是依赖过来,编译和测试时有效 (一般运行环境已经存在提供对应jar,项目不用)
引入依赖时注意也安装的组件的版本对应,根据官方选择对应的scala version
1 | |
代码
kafka SSL connect
1 | |
json 解析
1 | |
implements Serializable
org.apache.spark.SparkException: Task not serializable
java bean 和 spark job 都要 implements Serializable
,或者使用Kyro但是没看懂怎么用
java bean
JavaBean 实现 getter and setter, 不然会foreach接收到对象是为null
1 | |
shc库不支持spark stream
垃圾库,还要自己编译,依赖也不一定是你想要的,还不如自己用基础库撸
1 | |
1 | |
The node /hbase is not in ZooKeeper
查看 conf/hbase-site.xml 文件,找到配置项:zookeeper.znode.parent
它就是表示HBase 在 ZooKeeper 中的管理目录,里面存储着关于 HBase 集群的各项重要信息:
1 | |
查看 conf/hbase-env.sh 里面的配置信息:HBASE_MANAGES_ZK,
- 这个参数是告诉 HBase 是否使用自带的 ZooKeeper 管理 HBase 集群。如果为 true,
- 则使用自带的 ZooKeeper ,如果为 false,则使用外部的 ZooKeeper。
export HBASE_MANAGES_ZK=false
hbase分布式配置
1 | |
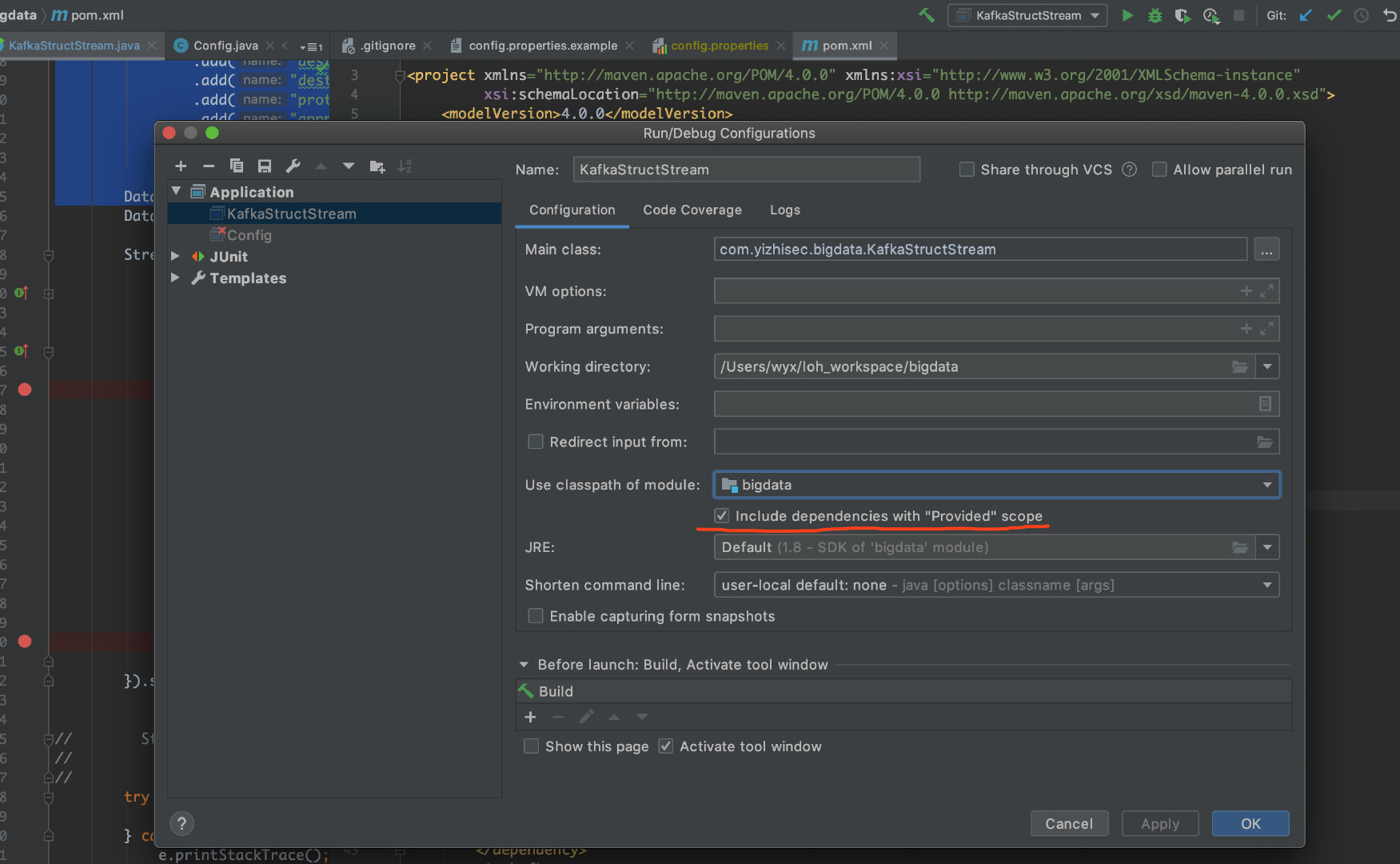
运行代码找不到provided包
java.lang.NoClassDefFoundError: org/apache/spark/internal/Logging
pom已经有spark的依赖,但是run跑不起来,是因为maven里面配置了<scope>provided</scope>,配置了这个就可以跑了
spark submit
java.lang.ClassNotFoundException: Failed to find data source: kafka.
- maven-shade-plugin
- ManifestResourceTransformer 指定入口函数
- ServicesResourceTransformer META-INF/service
- Failed to find data source kafka
1 | |
配置路径问题
1 | |
只能在使用服务器固定路径
yarn.ApplicationMaster: Final app status: FAILED, exitCode: 13
1 | |
去掉代码里面的关于setMaster
Spark Job Keep on Running
使用 deploy-mode
spark job 后台运行
hadoop Permission denied
org.apache.hadoop.security.AccessControlException: Permission denied:
user=root, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
1 | |
1 | |
Phoenix
migrate hbase to phoenix
./sqlline.py node1:2181
./psql.py node1:2181 -m "loh"."traffic"
配置phoenix.schema.isNamespaceMappingEnabled=true在hbase-site.xml自动映射
1 | |
命令行中字符串用单引号,表,列用双引号区分大小写(默认是大写)
1 | |
Error: Operation timed out. (state=TIM01,code=6000)
phoenix.query.timeoutMs
开启Phoenix Query Server
1 | |
性能测试对比clickhouse
数据导入导出
1 | |
hadoop
复制文件到hadoop报错
java.io.IOException: Failed to replace a bad datanode on the existing
pipeline due to no more good datanodes being available to try.
hdfs-site
- dfs.client.block.write.replace-datanode-on-failure.enable true
- dfs.client.block.write.replace-datanode-on-failure.policy NEVER
导入csv到hbase
1 | |
1 | |
清理 hadoop文件
1 | |
yarn log
1 | |
YARN Registry DNS Start failed
YARN hadoop.registry.dns.bind-port default value = 53
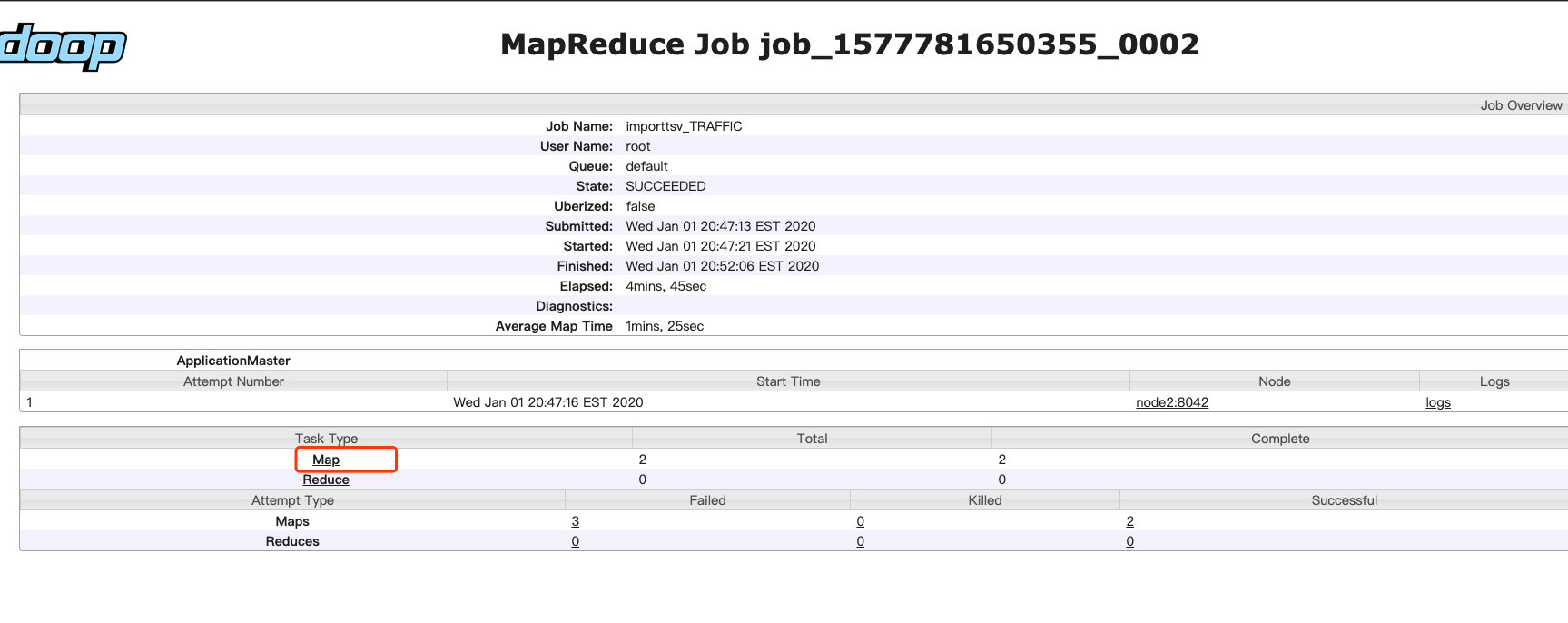
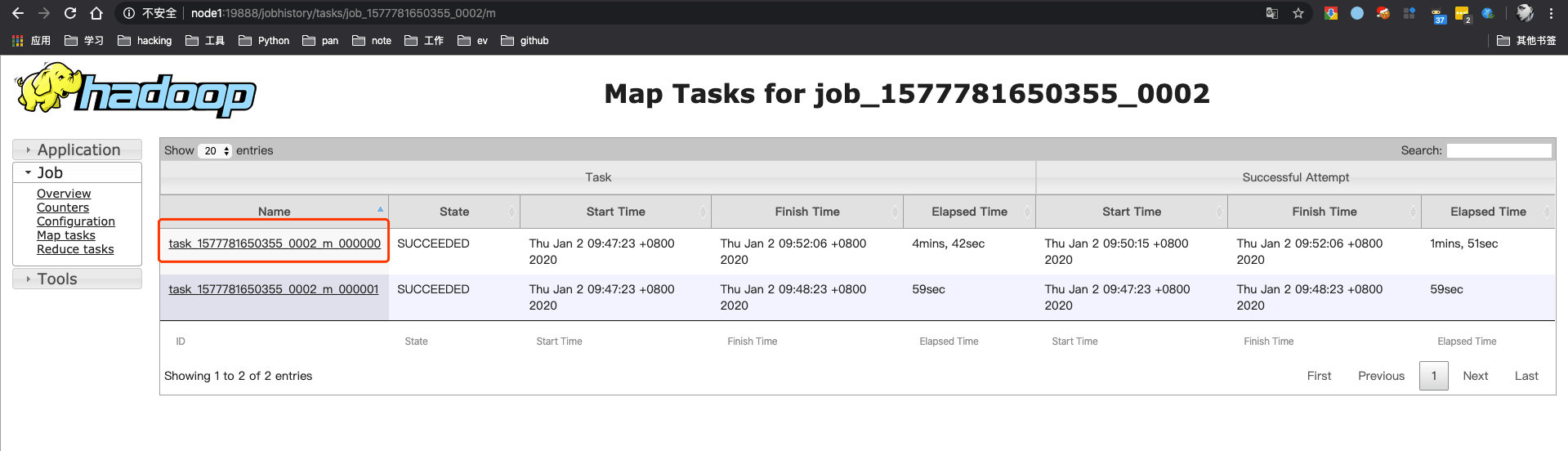
find the failed log in mapreduce.Job
1 | |
The url to track the job: http://node1:8088/proxy/application_1577781650355_0001/
根据log找对应的task和attempt_*
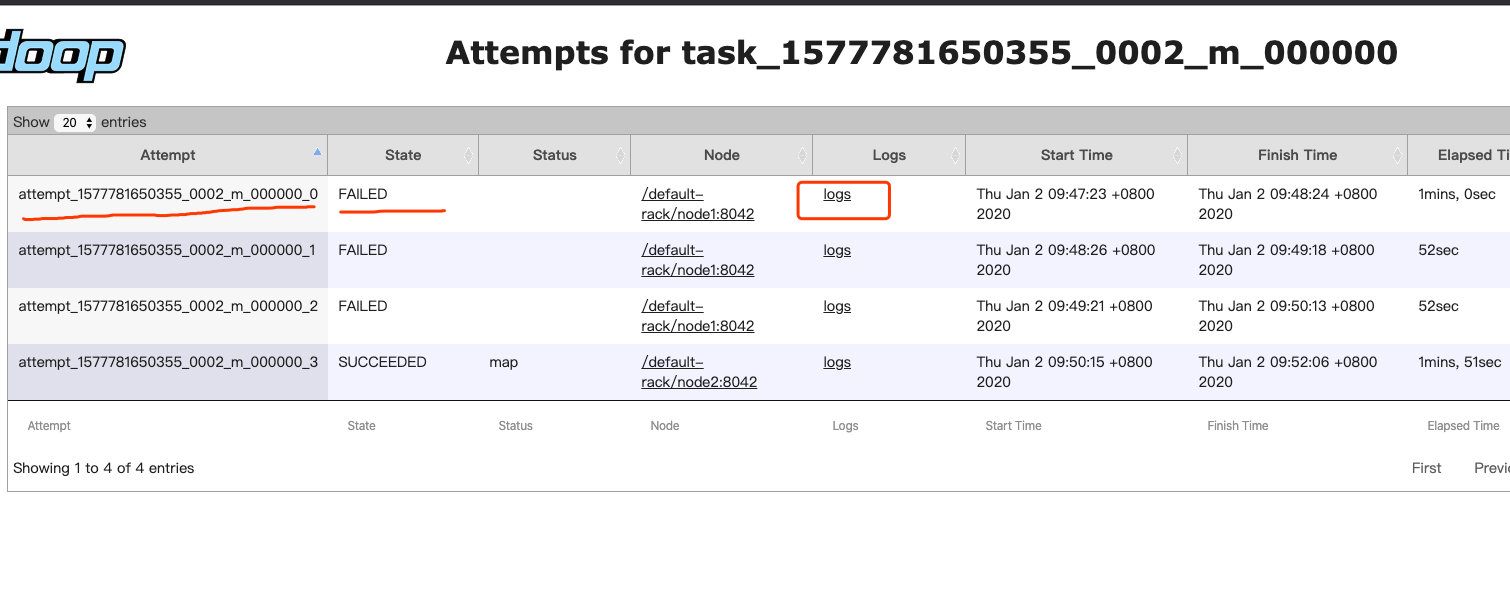
hadoop namenode -format
格式化后重启遇到各种问题
Failed to add storage directory [DISK]file:/tmp/hadoop-hadoop/dfs/data/
1 | |
namenode和datanode的clusterID不一致,删掉各个DataNode节点/tmp/hadoop-hadoop/dfs/data/current重启hadoop
/hadoop/hdfs/namenode/current/VERSION (Permission denied)
1 | |
1 | |
log 目录
/var/log/var/log/hadoop/hdfs/hadoop-hdfs-namenode-<hostname>.log
YARN Timeline Service can not start due to HBase
1 | |
1 | |
1 | |
Kylin
install kylin on ambari
Failed to create /kylin. Please make sure the user has right to access /kylin
1 | |
kylin.env.hdfs-working-dir in $KYLIN_HOME/conf/kylin.properties
1 | |
1 | |
替换成
1 | |
Exception in thread “main” java.lang.IllegalArgumentException: Failed to find metadata store by url: kylin_metadata@hbase
1 | |
kylin 版本问题
Something wrong with Hive CLI or Beeline, please execute Hive CLI or Beeline CLI in terminal to find the root cause.
1 | |
1 | |
Couldn’t find hive executable jar. Please check if hive executable jar exists in HIVE_LIB folder.
因为find-hive-dependency.sh缺了设置hive_exec_path
1 | |
HIVE_LIB not found, please check hive installation or export HIVE_LIB=’YOUR_LOCAL_HIVE_LIB’.
配置HIVE_LIB
spark not found, set SPARK_HOME, or run bin/download-spark.sh
1 | |
UI 访问不了
log $KYLIN_HOME/logs目录的kylin.log和kylin.out
1 | |
1 | |
spark 批处理
kafka offset 要latest