what
文件系统+监听通知机制
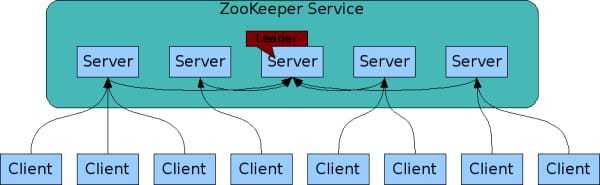
ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能
- 顺序一致性 - 客户端的更新将按发送顺序应用。
- 原子性 - 更新成功或失败。没有部分结果。
- 单系统映像 - 无论服务器连接到哪个服务器,客户端都将看到相同的服务视图。
- 可靠性 - 一旦应用了更新,它将从那时起持续到客户端覆盖更新。
- 及时性 - 系统的客户视图保证在特定时间范围内是最新的。
使用简单
- create : creates a node at a location in the tree
- delete : deletes a node
- exists : tests if a node exists at a location
- get data : reads the data from a node
- set data : writes data to a node
- get children : retrieves a list of children of a node
- sync : waits for data to be propagated
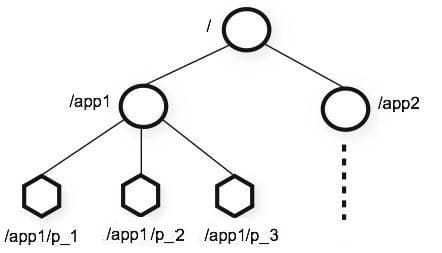
znode
文件目录 znode(目录节点) 节点有两种 持久的,临时的
通过一个 Leader 选举过程来选定一台称为 Leader 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 都只能提供读服务。
znode的存储限制最大不超过1M
- 永久节点:不会因为会话结束或者超时而消失
- 临时节点:如果会话结束或者超时就会消失
- 有序节点:会在节点名的后面加一个数字后缀,并且是有序的,例如生成的有序节点为 /lock/node-0000000000,它的下一个有序节点则为 /lock/node-0000000001,依次类推
观察模式 Watches
观察模式可以使客户端在某一个znode发生变化时得到通知。观察模式有ZooKeeper服务的某些操作启动,并由其他的一些操作来触发。例如,一个客户端对一个znode进行了exists操作,来判断目标znode是否存在,同时在znode上开启了观察模式。如果znode不存在,这exists将返回false。如果稍后,另外一个客户端创建了这个znode,观察模式将被触发,将znode的创建事件通知之前开启观察模式的客户端。我们将在以后详细介绍其他的操作和触发。
集群
ZAB(ZooKeeper Atomic Broadcast 原子广播)
实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
当整个 Zookeeper 集群刚刚启动或者Leader服务器宕机、重启或者网络故障导致不存在过半的服务器与 Leader 服务器保持正常通信时, 所有服务器进入崩溃恢复模式,首先选举产生新的 Leader 服务器,然后集群中 Follower 服务器开始与新的 Leader 服务器进行数据同步。 当集群中超过半数机器与该 Leader 服务器完成数据同步之后,退出恢复模式进入消息广播模式,Leader 服务器开始接收客户端的事务请求生成事物提案来进行事务请求处理。
崩溃恢复
当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人恢复模式并选举产生新的Leader服务器。 当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该Leader服务器完成了状态同步之后,ZAB协议就会退出恢复模式。
消息广播
集群中已经存在一个Leader服务器在负责进行消息广播,那么新加人的服务器就会自觉地进人数据恢复模式: 找到Leader所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
example
ssl zk client
1 | |
op
1 | |
session
概述
在ZooKeeper中,客户端和服务端建立连接后,会话随之建立,生成一个全局唯一的会话ID(Session ID)。服务器和客户端之间维持的是一个长连接,在SESSION_TIMEOUT时间内,服务器会确定客户端是否正常连接(客户端会定时向服务器发送heart_beat,服务器重置下次SESSION_TIMEOUT时间)。因此,在正常情况下,Session一直有效。
在出现网络或其它问题情况下(例如客户端所连接的那台ZK机器挂了,或是其它原因的网络闪断),客户端与当前连接的那台服务器之间连接断了,这个时候客户端会主动在地址列表中选择新的地址进行连接。
过程
客户端需要提供一个服务端地址列表,根据地址开始创建zookeeper对象,这个时候客户端的状态则变更为CONNECTION,按照顺序的方式获取IP来尝试建立网络连接,直到成功连接上服务器,这个时候客户端的状态就可以变更为CONNECTED。
go client state
1 | |
状态顺序
1 | |
仅当state等于StateHasSession时,客户端才是可用的。
会话激活
-
当客户端向服务端发送请求的时候,包括读写请求,都会主动触发一次会话激活
-
如果客户端在sessionTimeOut / 3时间范围内尚未和服务器之间进行通信,即没有发送任何请求,就会主动发起一个PING请求,去触发服务端的会话激活操作
关于时间
ExpiractionTime是指最近一次可能过期的时间点,每一个会话的ExpiractionTime的计算方式如下:
ExpiractionTime = CurrentTime + SessionTimeout
但是不要忘记了,Zookeeper的Leader服务器在运行期间会定期检查是否超时,这个定期的时间间隔为ExpiractionInterval,单位是秒,默认情况下是tickTime的值,即2000毫秒进行一次检查,完整的ExpiractionTime的计算方式如下:
1 | |
在ZK服务器端对会话超时时间是有限制的,主要是minSessionTimeout和maxSessionTimeout这两个参数设置的。Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。 默认的Session超时时间是在2 * tickTime ~ 20 * tickTime。