Spark
集群计算框架,相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,内存内运算,比Hadoop快100倍。
优势

Hadoop比

架构
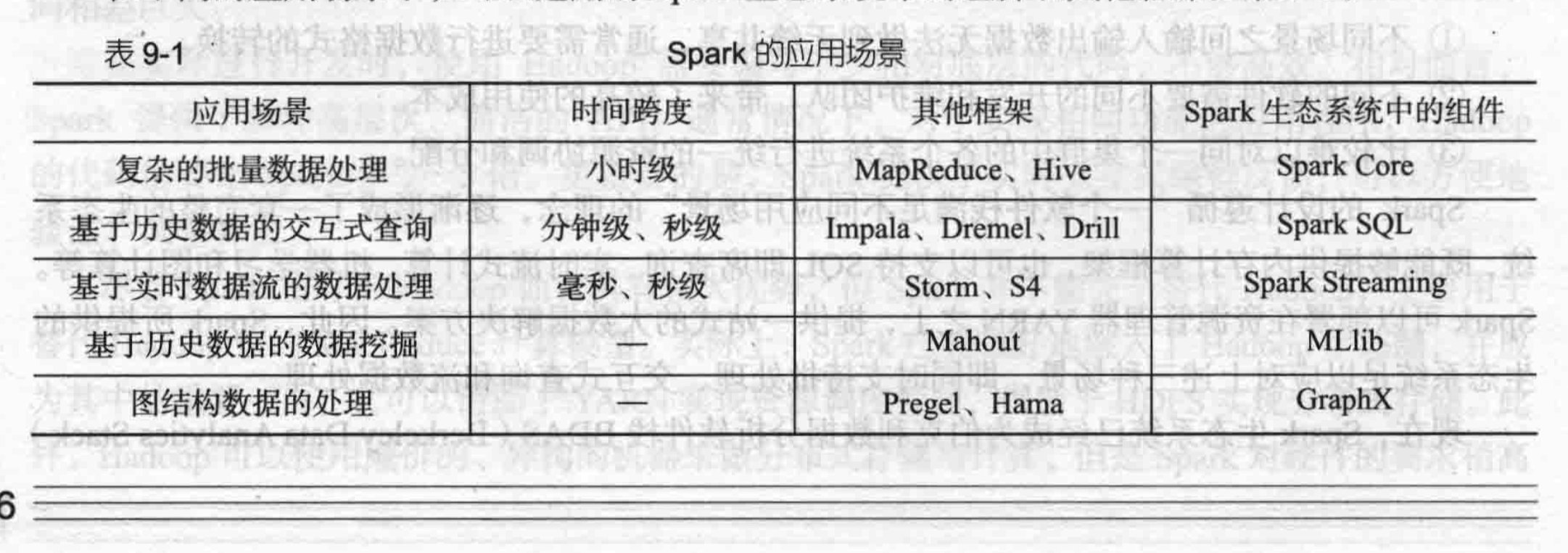
其基础的程序抽象则称为弹性分布式数据集(RDDs),是一个可以并行操作、有容错机制的数据集合。
Spark应用程序作为集群上的独立进程集运行,由SparkContext 主程序中的对象driver program主导


- 应用提交driver创建SparkContext,SparkContext向Cluster Manager注册,申请运行Executor资源
- 申请资源后,Executor启动,将运行状况发送到Cluster Manager
- SparkContext根据RDD依赖关系构建DAG,DAGScheduler解析DAG分成多个Stage(阶段 任务集),计算Stage之间依赖关系,将Stages交给TaskScheduler
- Executor向SparkContext申请任务,TaskScheduler分发将任务到Executor,SparkContext分发应用代码到Executor
- 任务在Executor上执行,反馈到TaskScheduler,DAGScheduler。完成后写入数据,释放资源。

RDD
好处

结构
只读分区记录集合,一个RDD多个分区(数据集片段),不同分区可存储到集群上不同节点进行并行计算。
RDD不能直接修改
- 只能基于物理存储的数据转换创建RDD
- 基于其他RDD转换创建新的RDD。
transformations and actions
- transformat操作(map,filter,groupBy,join)接受RDD返回RDD
- action操作(collect,collect)接受RDD返回一个值或者结果。
transformat不会马上计算,Spark会记住对于base dataset的所有转换(RDD依赖关系)。当有action时才会计算出结果(Spark根据RDD依赖关系生成DAG)返回到the driver program。
避免多次转换操作之间数据同步等待,不担心有过多的中间数据。DAG拓扑排序连接一系列RDD操作实现管道化。
默认情况下,每次action都会计算,即使是相同的transform。 可以通过持久化(缓存)机制避免这种重复计算的开销。 可以使用persist()方法对一个RDD标记为持久化,之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化, 而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化,持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复使用。
1 | |
1 | |
Why 高效
- 高容错
根据DAG重新计算,获得丢失数据,避免数据复制高开销,重算过程多节点并行
- 中间结果持久化到内存
- 存放数据都是Java对象,减少序列化和反序列化
RDD依赖
看RDD分区
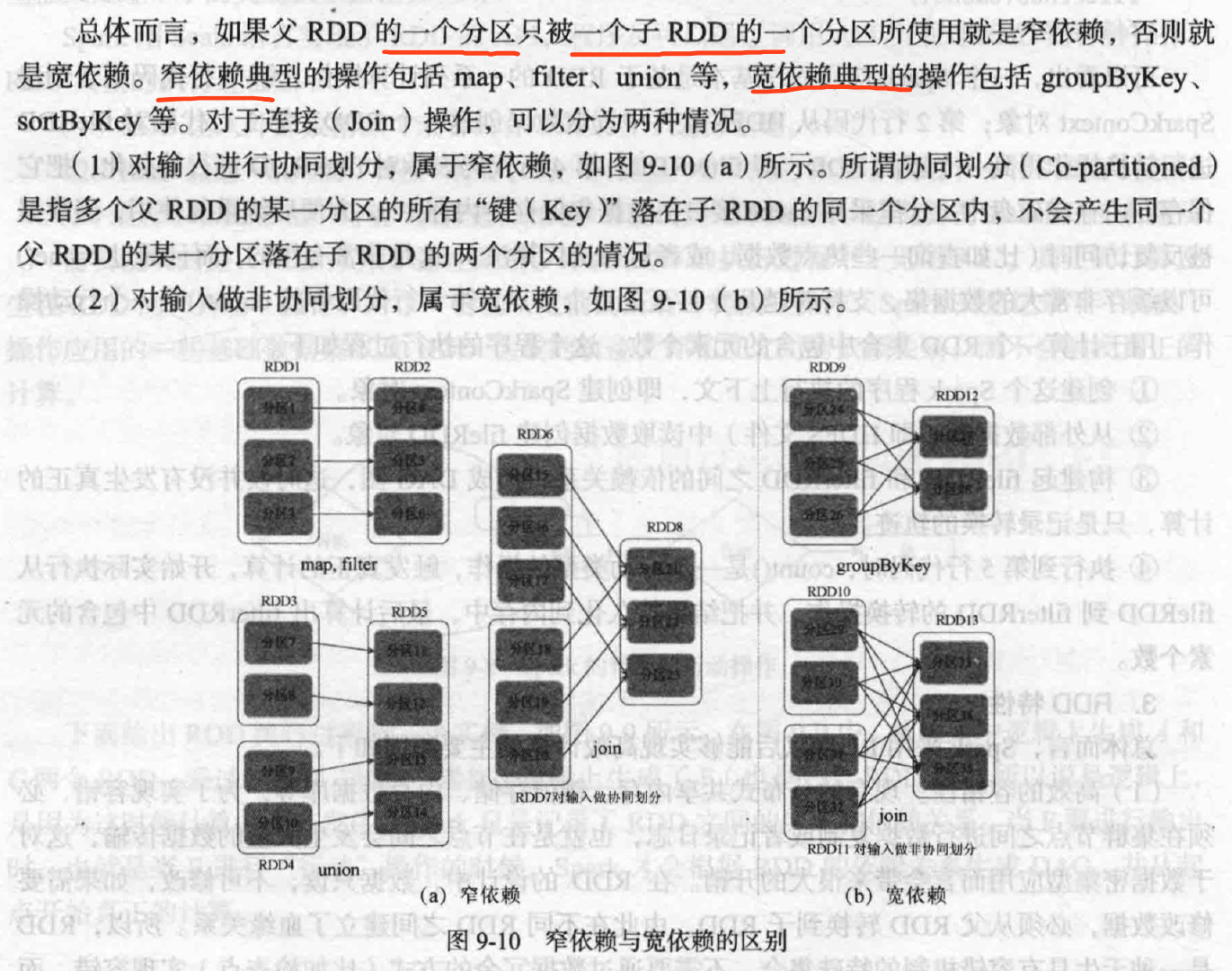
设置分区
分区原则是使得分区的个数尽量等于集群中的CPU核心(core)数目

1 | |
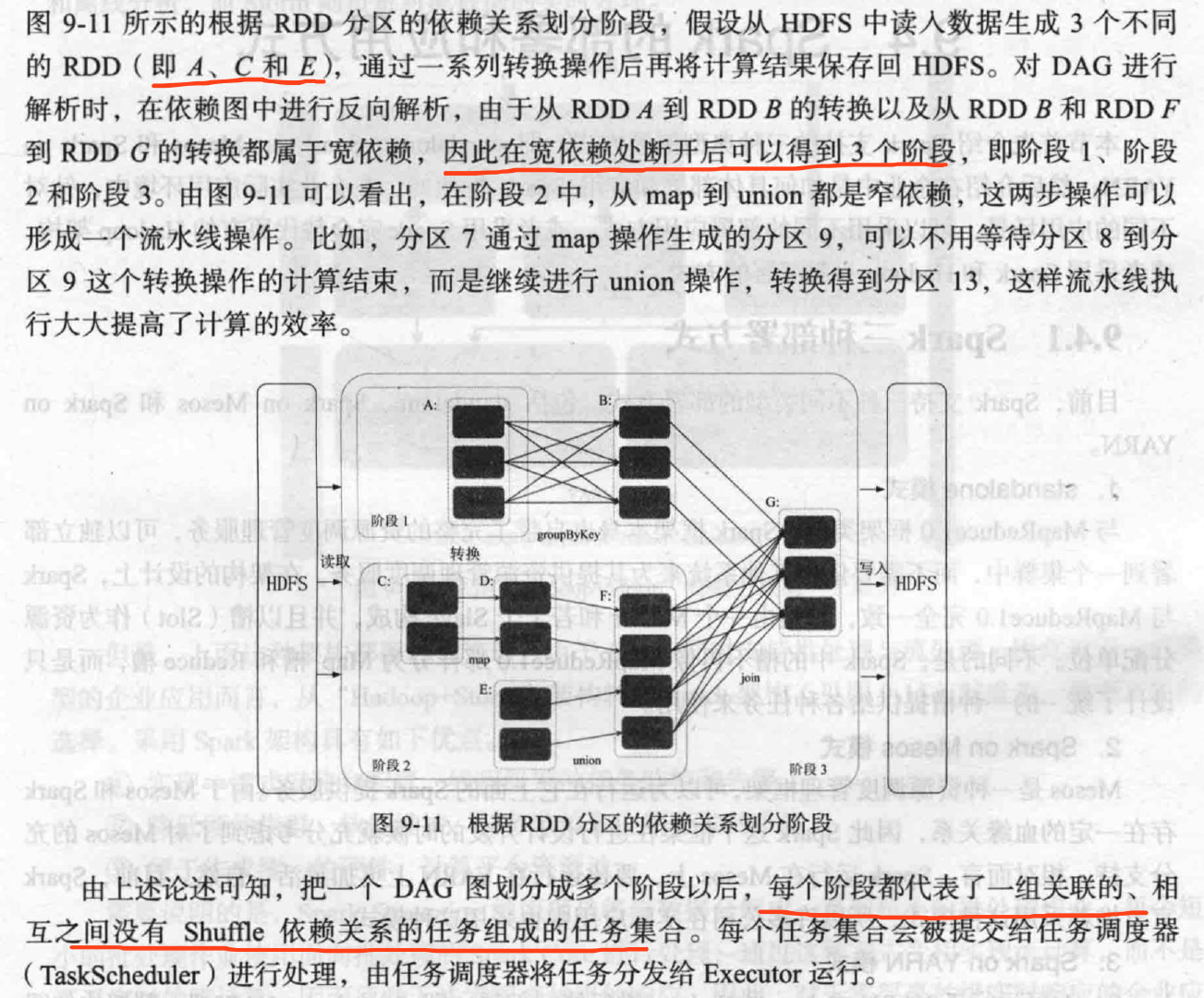
划分DAG
在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖把当前RDD加入到当前stage,尽量窄依赖划分到同一个阶段。
运行过程
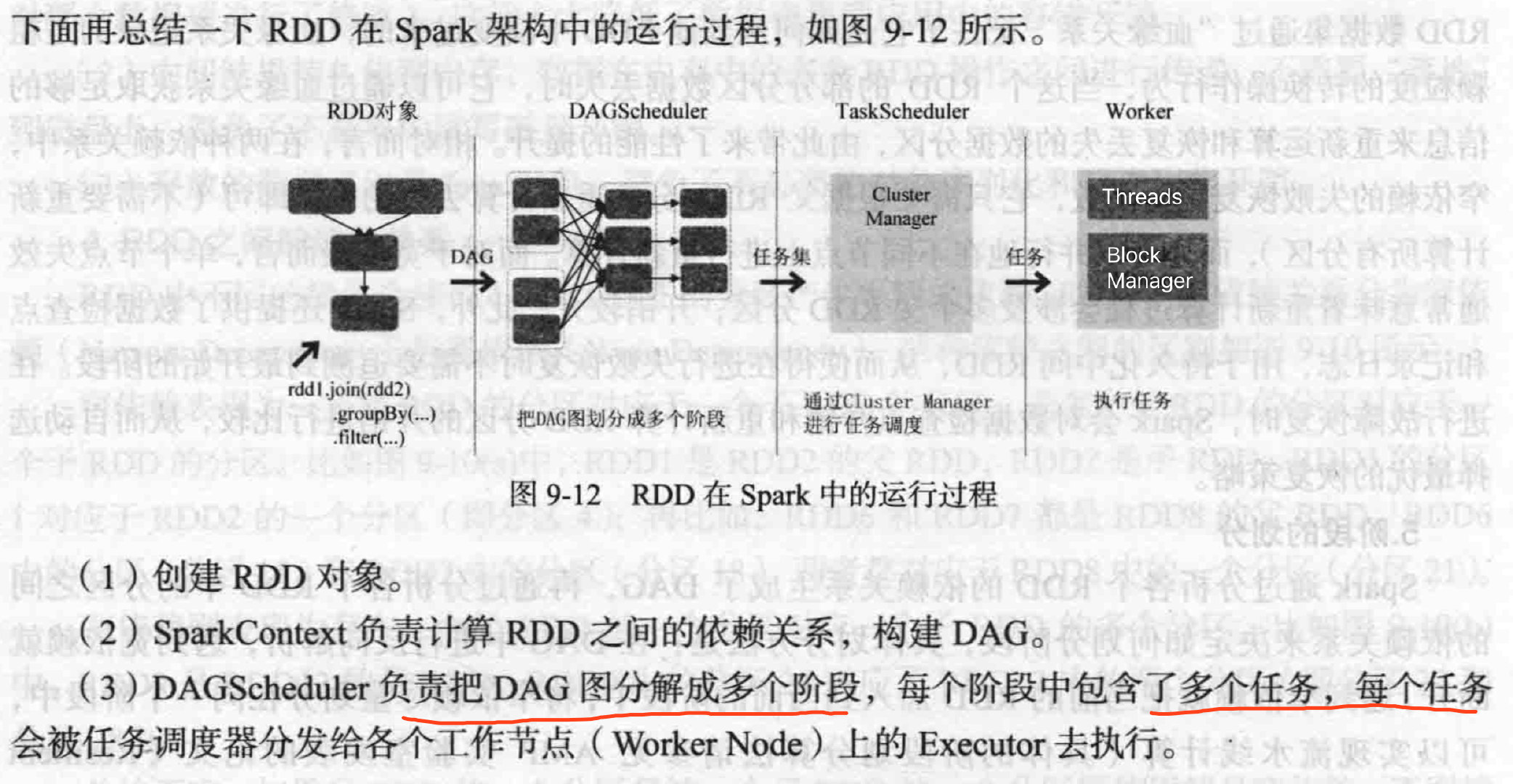
RUN
Interactive
master 参数
- local Run Spark with one worker thread.
- local[n] Run Spark with n worker threads.
- spark://HOST:PORT Connect to a Spark standalone cluster.
- mesos://HOST:PORT Connect to a Mesos cluster.
1 | |
run
run spark script
1 | |
1 | |
py local
The RDD.glom() method returns a list of all of the elements within each partition, and the RDD.collect() method brings all the elements to the driver node.
get RDD from collect
sc.parallelize

get file
sc.textFile

diff flatMap and map
1 | |
1 | |
共享变量 broadcast/accumulators
- 广播变量用来把变量在所有节点的内存之间进行共享
- 累加器则支持在所有不同节点之间进行累加计算(比如计数或者求和)
广播变量
允许程序开发人员在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。
- When use Broadcast variable
只有在跨多个阶段的任务需要相同数据,数据重要,不更改的值。仅在需要时加载,数据仅发送到包含需要它的执行程序的节点。
1
2
3>> broadcastVar = sc.broadcast([1, 2, 3]) >> broadcastVar.value [1,2,3] - In spark, how does broadcast work?
累加器
运行在集群中的任务,就可以使用add方法来把数值累加到累加器上,但是, 这些任务只能做累加操作,不能读取累加器的值,只有任务控制节点(Driver Program)可以使用value方法来读取累加器的值。
1 | |
文件读写
因为Spark采用了惰性机制,在执行转换操作的时候,即使我们输入了错误的语句, pyspark也不会马上报错,而是等到执行“行动”类型的语句时启动真正的计算,那个时候“转换”操作语句中的错误就会显示出来
-
本地
file:///usr/local/spark/mycode/wordcount/writeback.txt -
hdfs
hdfs://localhost:9000/user/hadoop/word.txt
1 | |
1 | |
1 | |
dataframe
1 | |
1 | |
1 | |
rdd to df
- 反射机制推断RDD
1 | |
- 编程方式定义RDD
1 | |
stream
创建 StreamingContext
1 | |
setAppName(“TestDStream”)是用来设置应用程序名称。 setMaster(“local[2]”)括号里的参数local[2]字符串表示运行在本地模式下,并且启动2个工作线程。
1 | |
File流
输入ssc.start()以后,程序就开始自动进入循环监听状态, 监听程序只监听目录下在程序启动后新增的文件,不会去处理历史上已经存在的文件。
1 | |
socket
1 | |
RDD队列流(DStream)
1 | |
高级流
Kafka和Flume等高级输入源,需要依赖独立的库(jar文件)。按照我们前面安装好的Spark版本,这些jar包都不在里面。需要自己下载对应jar (spark-streaming-kafka spark-streaming-flume),复制到Spark目录的jars目录
- Kafka
1 | |
- Flume
1 | |
Dstearm transfer
- 无状态转换:每个批次的处理不依赖于之前批次的数据。
- 有状态转换:当前批次的处理需要使用之前批次的数据或者中间结果。有状态转换包括基于滑动窗口的转换和追踪状态变化的转换(updateStateByKey)。
updateStateByKey 跨批次之间维护状态
1 | |
window
设定一个滑动窗口的长度,并且设定滑动窗口的时间间隔(每隔多长时间执行一次计算)
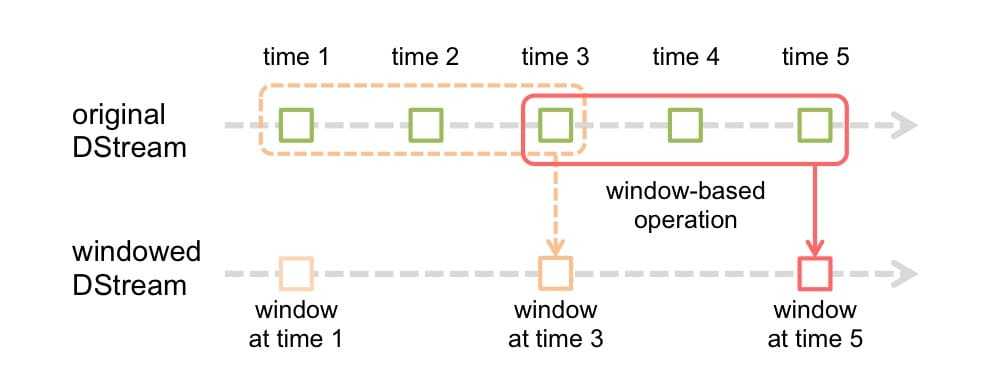 下面给给出一些窗口转换操作的含义:
下面给给出一些窗口转换操作的含义:
- window(windowLength, slideInterval) 基于源DStream产生的窗口化的批数据,计算得到一个新的DStream;
- countByWindow(windowLength, slideInterval) 返回流中元素的一个滑动窗口数;
- reduceByWindow(func, windowLength, slideInterval) 返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数func必须满足结合律,从而可以支持并行计算;
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) 应用到一个(K,V)键值对组成的DStream上时,会返回一个由(K,V)键值对组成的新的DStream。每一个key的值均由给定的reduce函数(func函数)进行聚合计算。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。可以通过numTasks参数的设置来指定不同的任务数;
- reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于先前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作,并对离开窗口的老数据进行“逆向reduce”操作。但是,只能用于“可逆reduce函数”,即那些reduce函数都有一个对应的“逆向reduce函数”(以InvFunc参数传入);
- countByValueAndWindow(windowLength, slideInterval, [numTasks]) 当应用到一个(K,V)键值对组成的DStream上,返回一个由(K,V)键值对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率。
Dstearm output
saveAsTextFiles
存储到mysql
1 | |
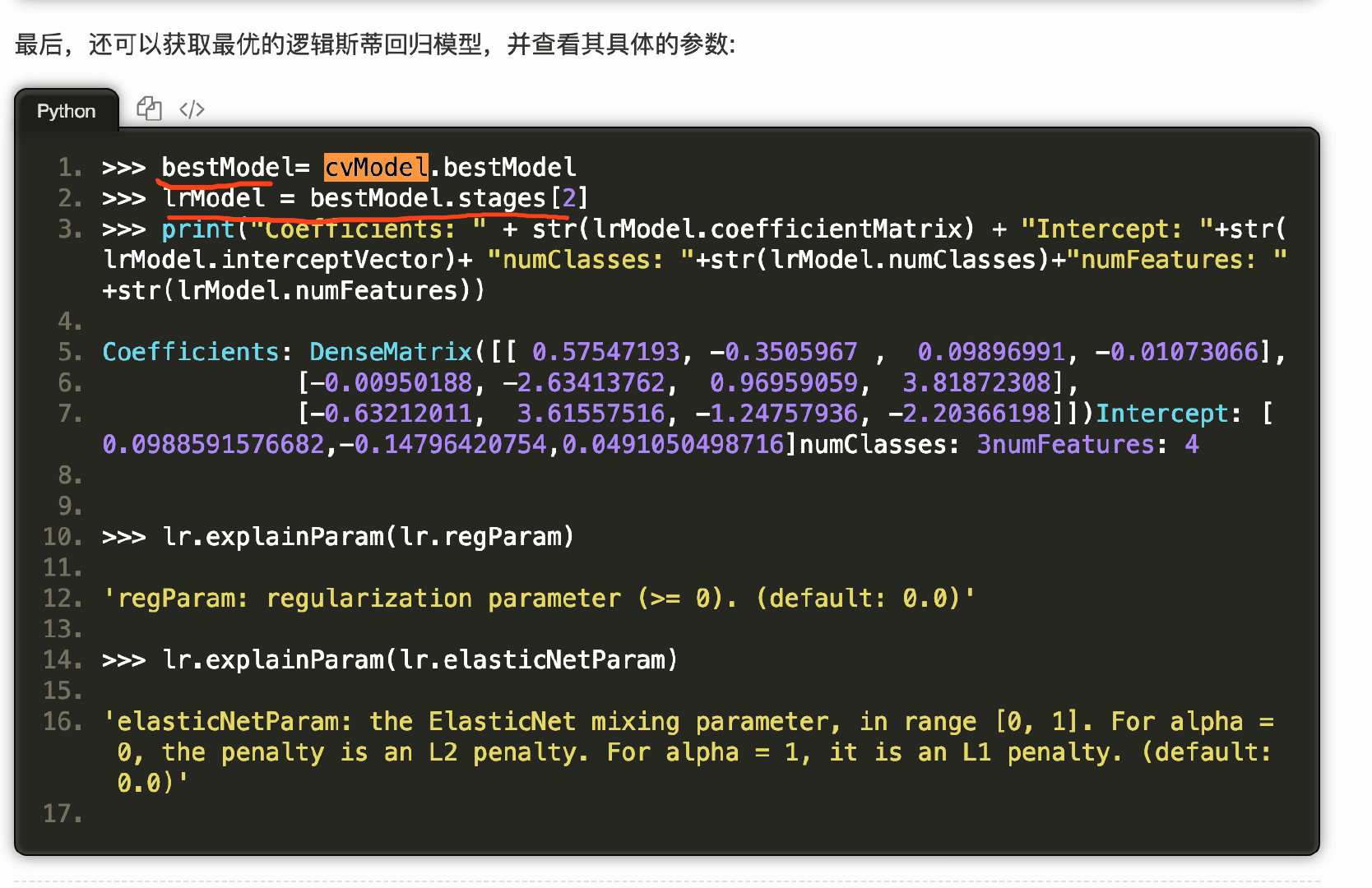
MLLib
 Spark官方推荐使用spark.ml
Spark官方推荐使用spark.ml

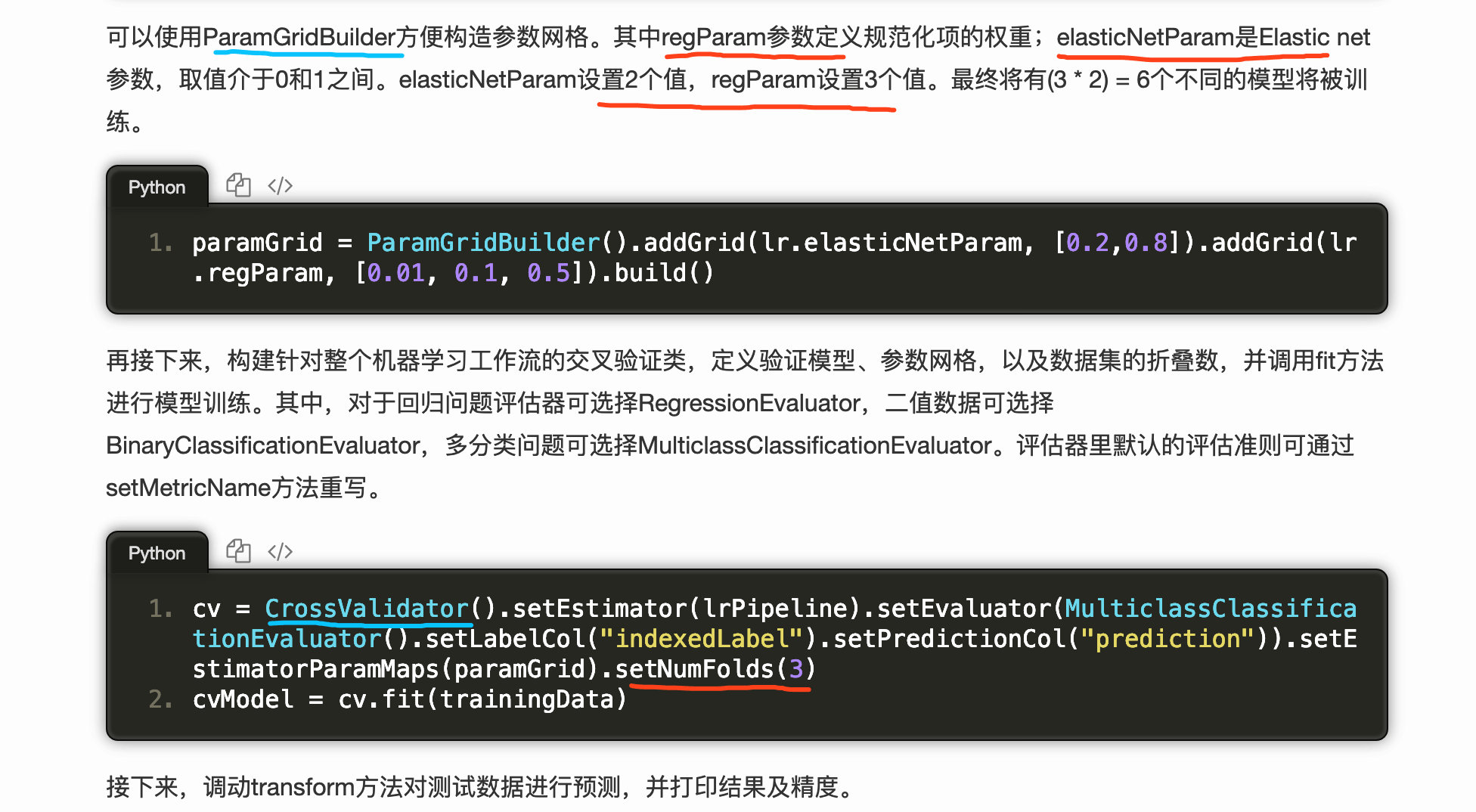
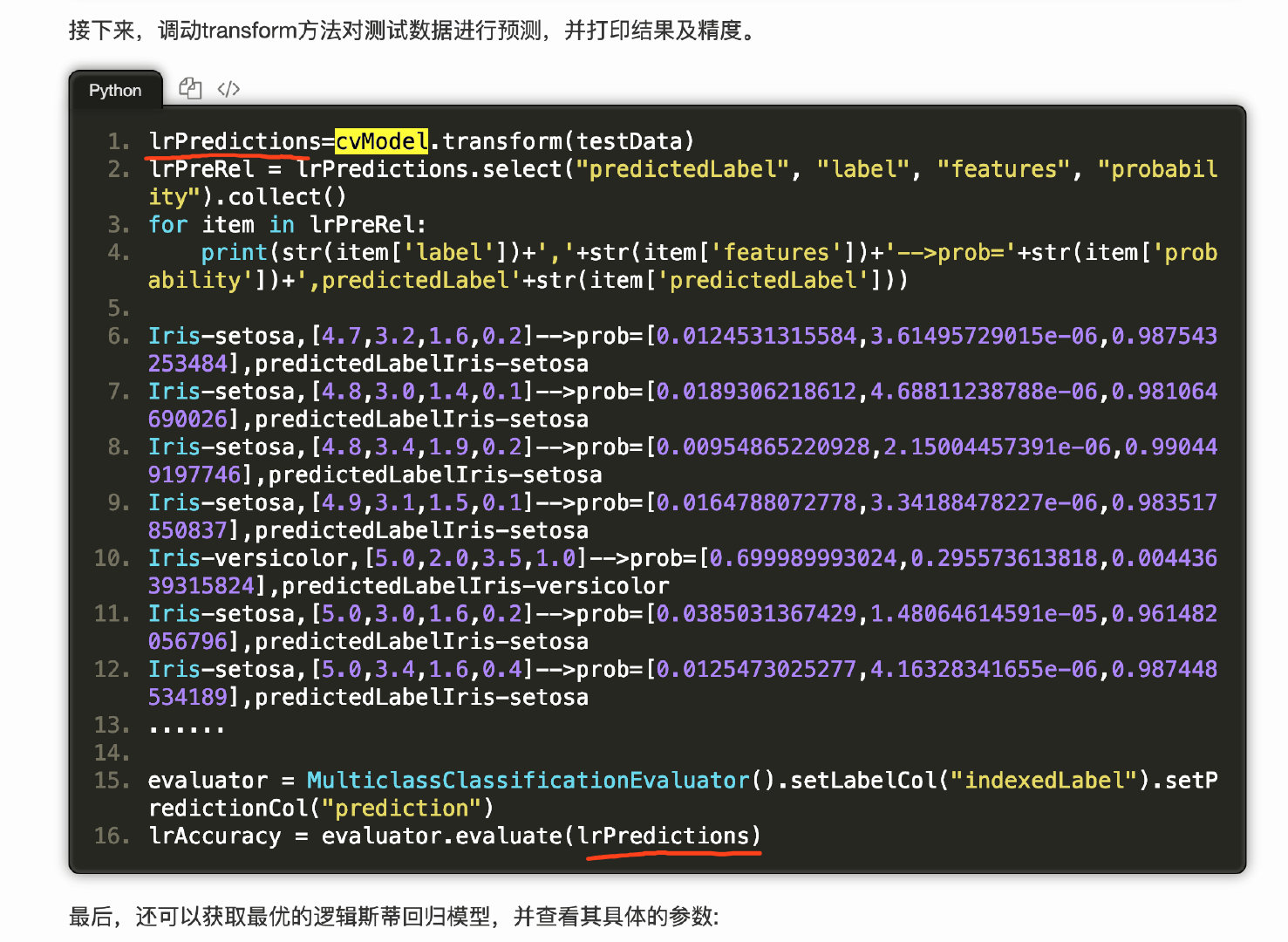
pipline
1 | |
TF-IDF
词语由t表示,文档由d表示,语料库由D表示。
- 词频TF(t,d)是词语t在文档d中出现的次数
- 文件频率DF(t,D)是包含词语的文档的个数
 首先使用分解器Tokenizer把句子划分为单个词语。对每一个句子(词袋),我们使用HashingTF将句子转换为特征向量,最后使用IDF重新调整特征向量。这种转换通常可以提高使用文本特征的性能。
首先使用分解器Tokenizer把句子划分为单个词语。对每一个句子(词袋),我们使用HashingTF将句子转换为特征向量,最后使用IDF重新调整特征向量。这种转换通常可以提高使用文本特征的性能。
1 | |
word2vec

- CBOW ,其思想是通过每个词的上下文窗口词词向量来预测中心词的词向量。
- Skip-gram,其思想是通过每个中心词来预测其上下文窗口词,并根据预测结果来修正中心词的词向量
1 | |
CountVectorizer 词频统计
1 | |
trick
1 | |
Java code
parallelize get javadd
1 | |
map reduce
1 | |
1 | |