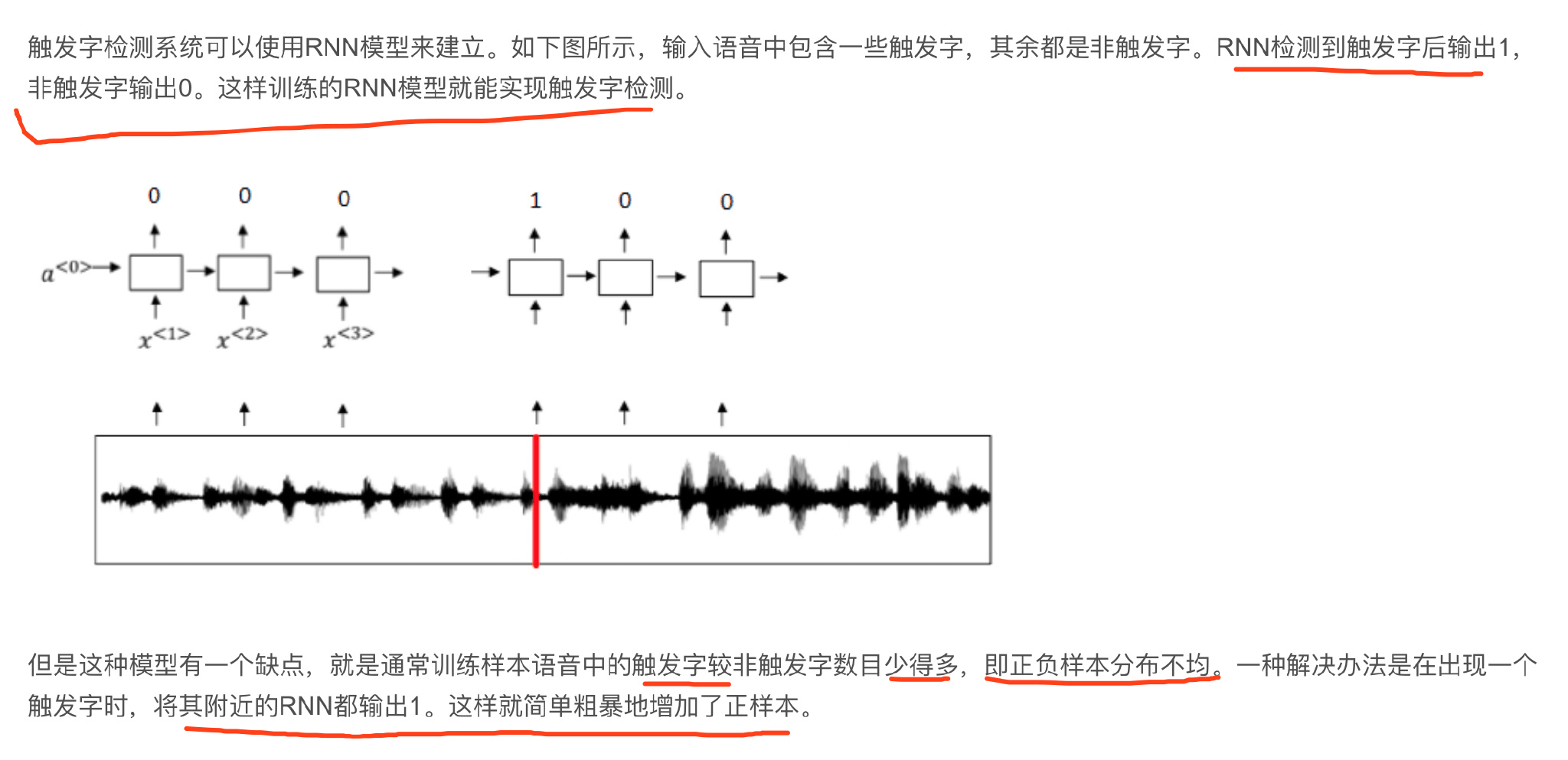
Basic Models
Sequence to sequence(序列)模型在机器翻译和语音识别方面都有着广泛的应用,针对该机器翻译问题,可以使用“编码网络(encoder network)”+“解码网络(decoder network)”两个RNN模型组合的形式来解决。
encoder network将输入语句编码为一个特征向量,传递给decoder network,完成翻译。
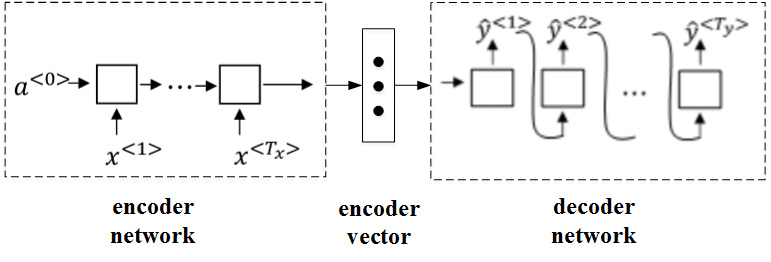
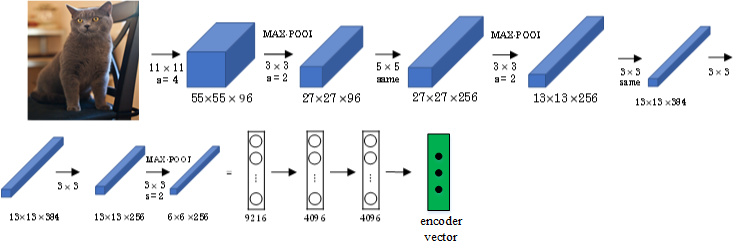
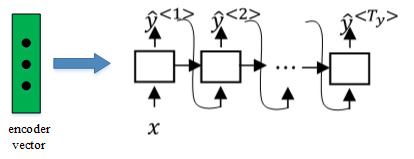
Picking the most likely sentence
machine translation的目标就是根据输入语句,作为条件,找到最佳翻译语句,使其概率最大:
\[max\ P(y^{<1>},y^{<2>},\cdots,y^{<T_y>}|x^{<1>},x^{<2>},\cdots,x^{<T_x>})\]greedy search
每次只寻找一个最佳单词作为翻译输出,力求把每个单词都翻译准确。 缺点:
- 每次只搜索一个单词,没有考虑该单词前后关系,概率选择上有可能会出错。
- 增加了运算成本,降低运算速度
Beam Search
Greedy search每次是找出预测概率最大的单词,而beam search则是每次找出预测概率最大的B个单词。其中,参数B表示取概率最大的单词个数,可调。
- 先从词汇表中找出翻译的第一个单词概率最大的B个预测单词。
- 分别以B个预测单词为条件,计算每个词汇表单词作为预测第二个单词的概率。从中选择概率最大的B个作为第二个单词的预测值。
以此类推,每次都取概率最大的三种预测。最后,选择概率最大的那一组作为最终的翻译语句。
实际应用中,可以根据不同的需要设置B为不同的值。一般B越大,机器翻译越准确,但同时也会增加计算复杂度。
改进 beam search
Beam search中,最终机器翻译的概率是乘积的形式:
\[arg\ max\prod_{t=1}^{T_y} P(\hat y^{<t>}|x,\hat y^{<1>},\cdots,\hat y^{<t-1>})\]多个概率相乘可能会使乘积结果很小,远小于1,造成数值下溢。为了解决这个问题,可以对上述乘积形式进行取对数log运算,即:
\[arg\ max\sum_{t=1}^{T_y} P(\hat y^{<t>}|x,\hat y^{<1>},\cdots,\hat y^{<t-1>})\]因为取对数运算,将乘积转化为求和形式,避免了数值下溢,使得数据更加稳定有效。
这种概率表达式还存在一个问题,就是机器翻译的单词越多,乘积形式或求和形式得到的概率就越小,这样会造成模型倾向于选择单词数更少的翻译语句,使机器翻译受单词数目的影响,这显然是不太合适的。 因此,一种改进方式是进行长度归一化,消除语句长度影响。
\[arg\ max\ \frac{1}{T_y}\sum_{t=1}^{T_y} P(\hat y^{<t>}|x,\hat y^{<1>},\cdots,\hat y^{<t-1>})\]实际应用中,通常会引入归一化因子$\alpha$:
\[arg\ max\ \frac{1}{T_y^{\alpha}}\sum_{t=1}^{T_y} P(\hat y^{<t>}|x,\hat y^{<1>},\cdots,\hat y^{<t-1>})\]若$\alpha=1$,则完全进行长度归一化;若$\alpha=0$,则不进行长度归一化。一般令$\alpha=0.7$,效果不错。
Error analysis in beam search
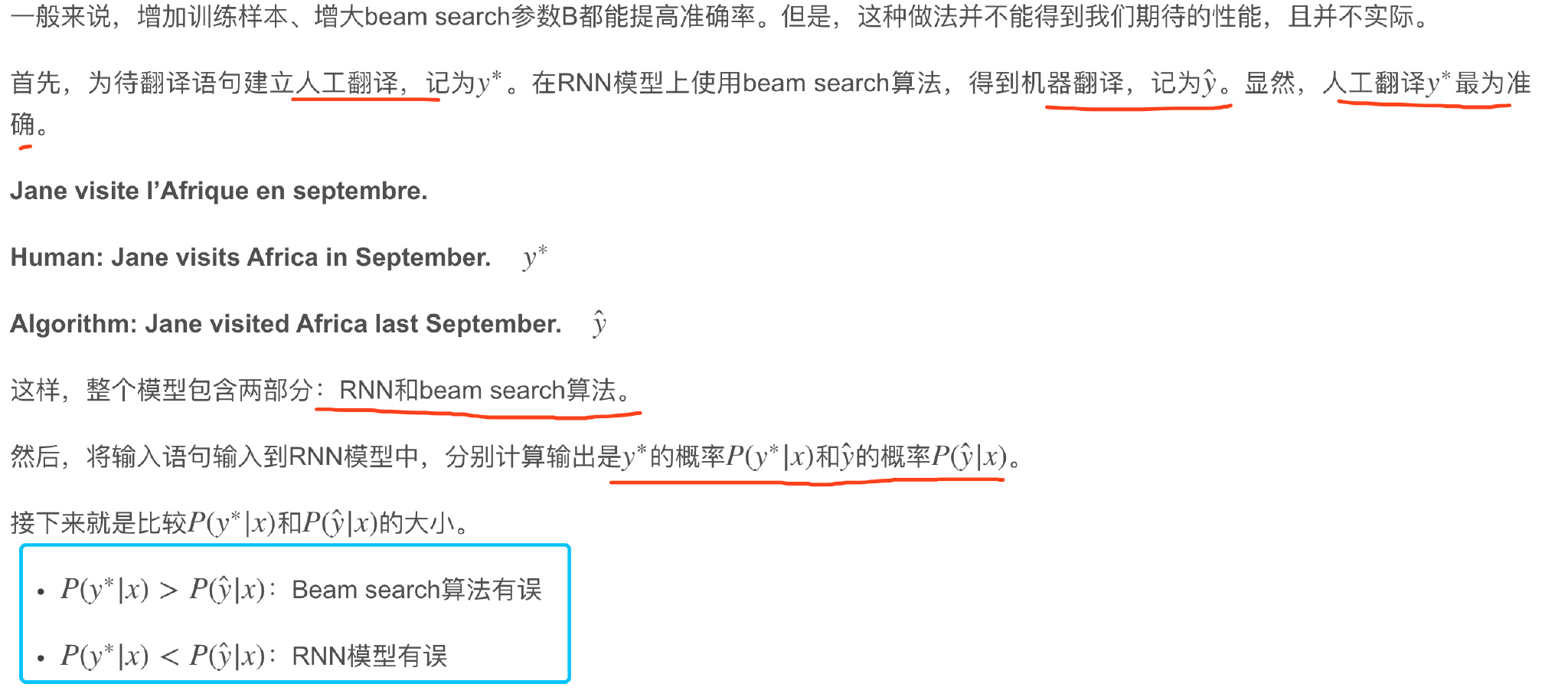
- beam search实际上不能够给你一个能使最大化$P(y\vert x)$的y值
- 虽然$y^{*}$是一个更好的翻译结果,RNN模型却赋予它更低的可能性,是RNN模型出现了问题
如果beam search算法表现不佳,可以调试参数B;若RNN模型不好,则可以增加网络层数,使用正则化,增加训练样本数目等方法来优化。
Bleu Score
使用bleu score,对机器翻译进行打分。机器翻译越接近参考的人工翻译,其得分越高,方法原理就是看机器翻译的各个单词是否出现在参考翻译中。
机器翻译单词出现在参考翻译单个语句中的次数,取最大次数。分母为机器翻译单词数目,分子为相应单词出现在参考翻译中的次数。这种评价方法较为准确。
按照beam search的思想,另外一种更科学的打分方法是bleu score on bigrams,即同时对两个连续单词进行打分。
Example: 连续单词进行打分。仍然是上面那个翻译例子:
French: Le chat est sur le tapis.
Reference 1: The cat is on the mat.
Reference 2: There is a cat on the mat.
MT output: The cat the cat on the mat.
 bigrams出现在参考翻译单个语句中的次数(取最大次数)/ bigrams及其出现在MIT output中的次数count
相应的bigrams precision为:
bigrams出现在参考翻译单个语句中的次数(取最大次数)/ bigrams及其出现在MIT output中的次数count
相应的bigrams precision为:

Attention Model Intuition
注意力模型
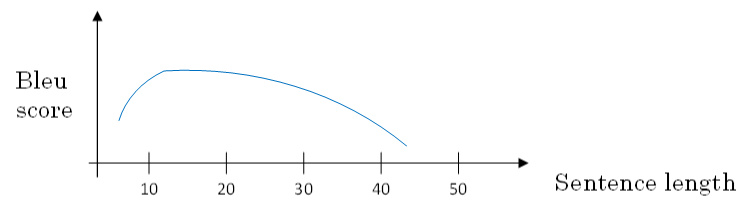 原语句很长,要对整个语句输入RNN的编码网络和解码网络进行翻译,则效果不佳。相应的bleu score会随着单词数目增加而逐渐降低。
对待长语句,正确的翻译方法是将长语句分段,每次只对长语句的一部分进行翻译,使得bleu score不太受语句长度的影响。
原语句很长,要对整个语句输入RNN的编码网络和解码网络进行翻译,则效果不佳。相应的bleu score会随着单词数目增加而逐渐降低。
对待长语句,正确的翻译方法是将长语句分段,每次只对长语句的一部分进行翻译,使得bleu score不太受语句长度的影响。
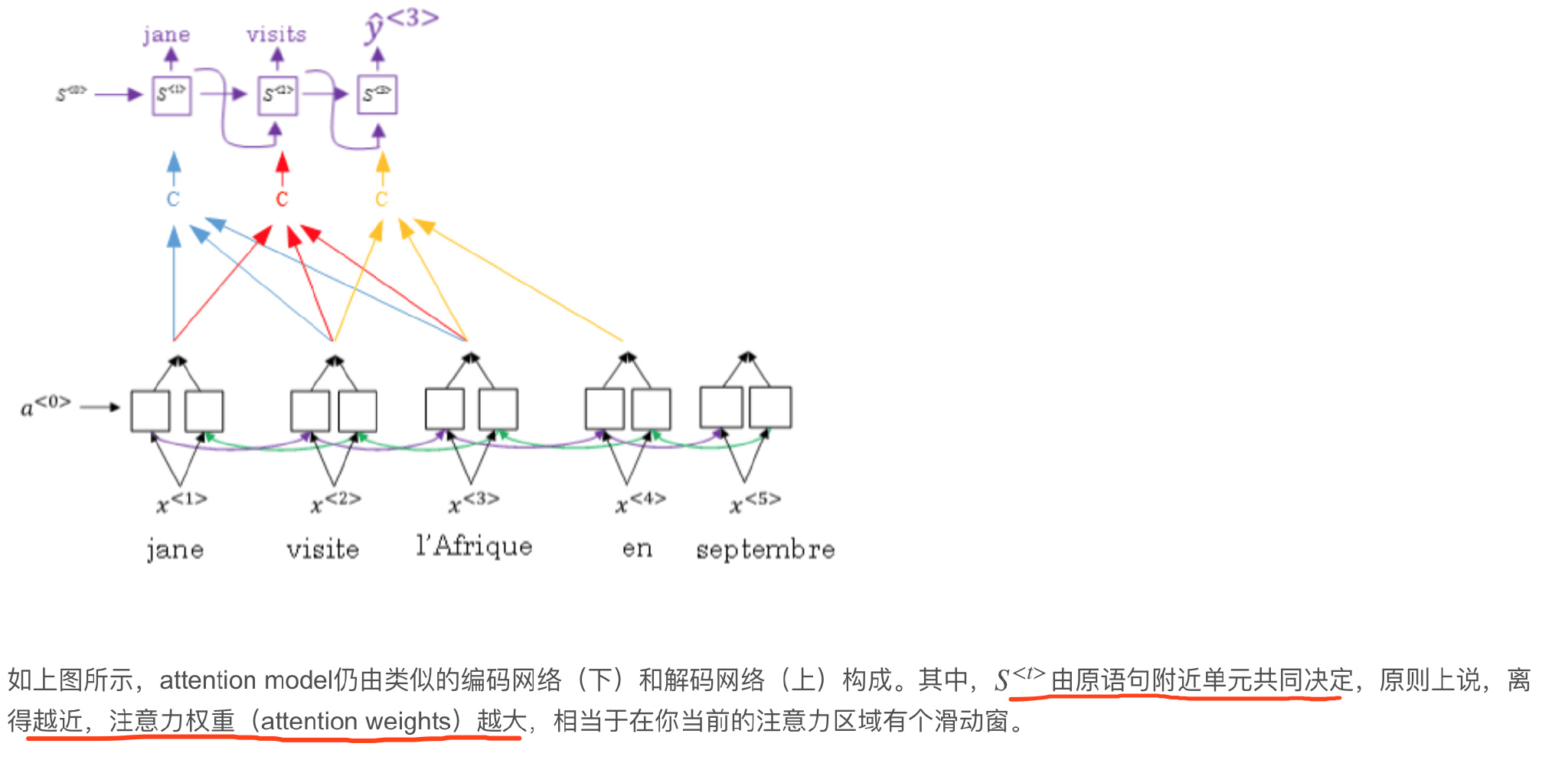

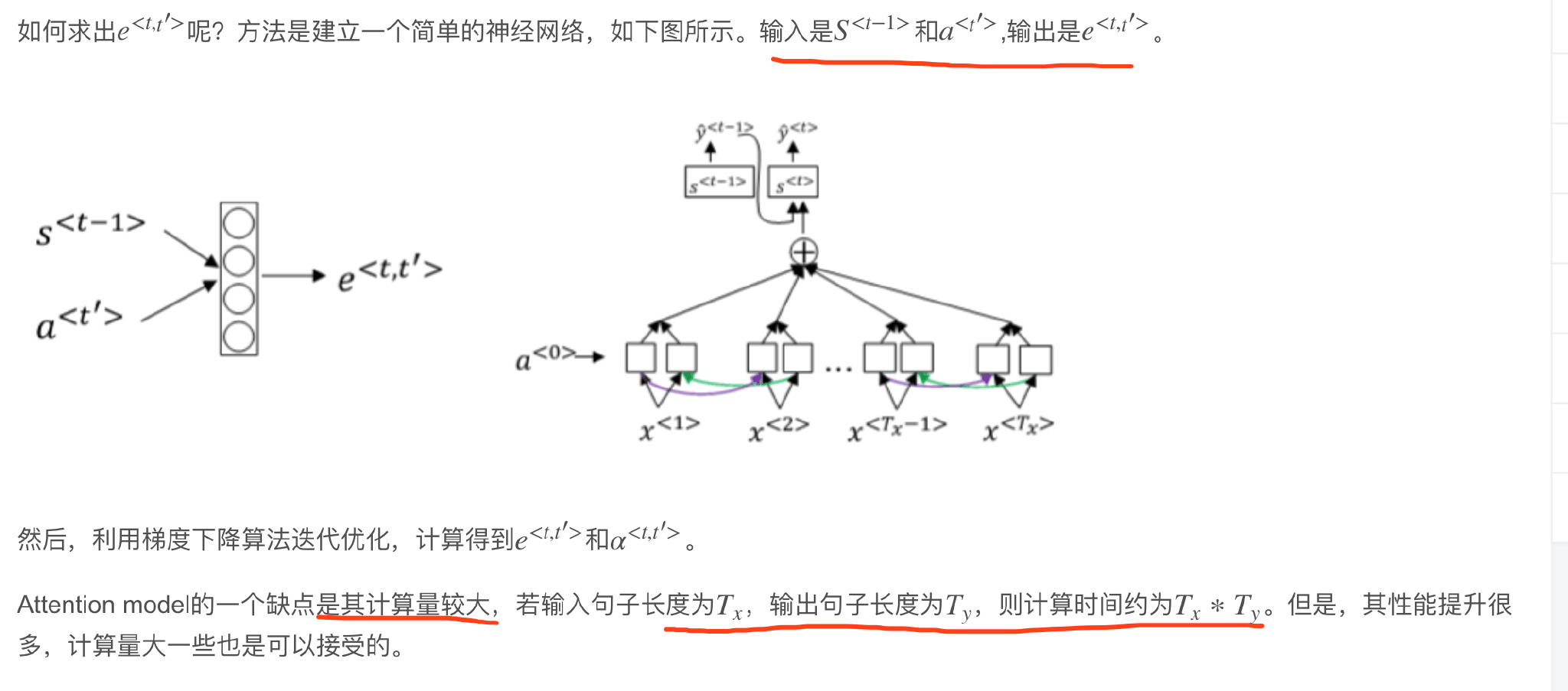
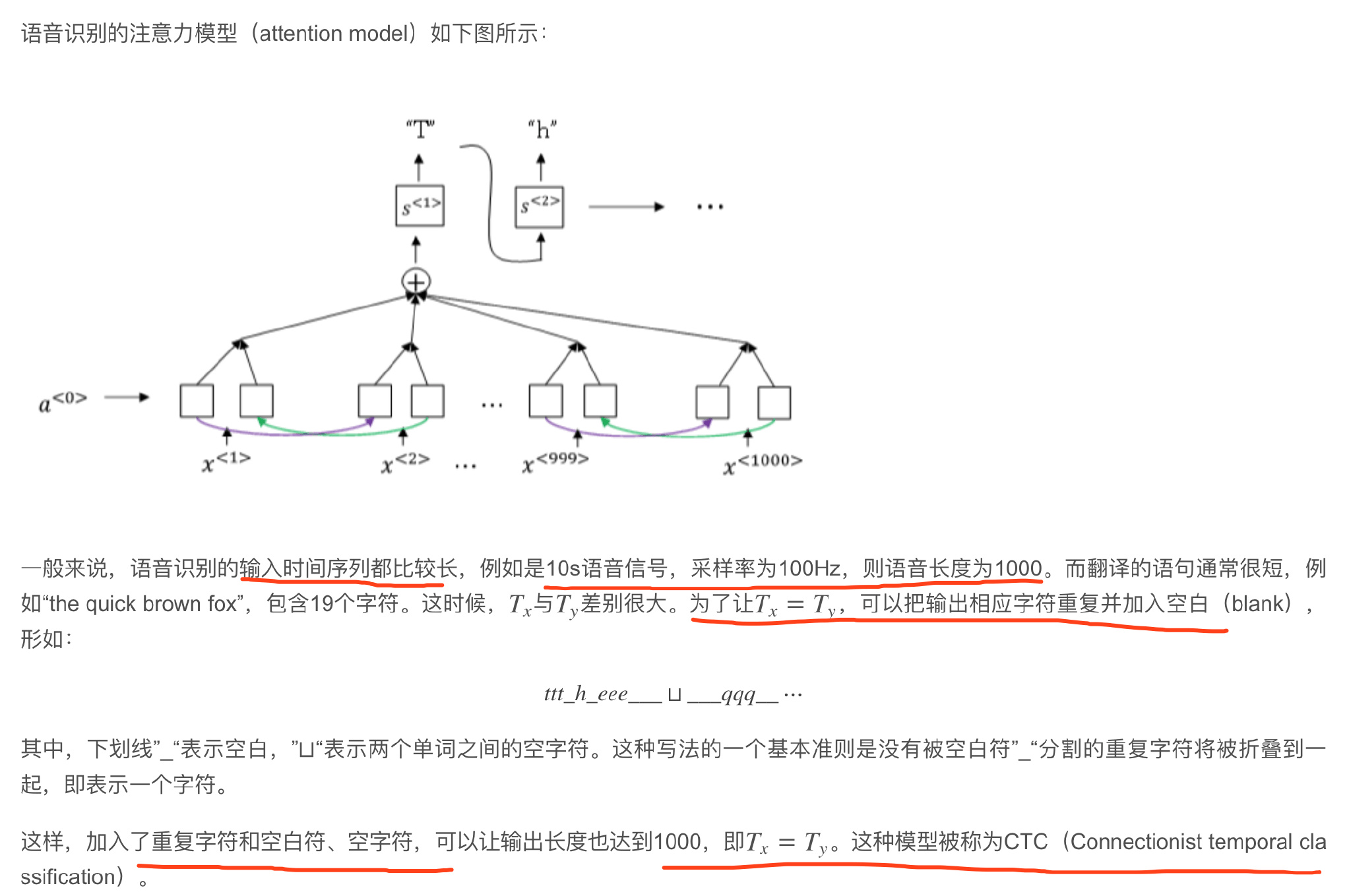
Speech recognition
语音识别的输入是声音,量化成时间序列。更一般地,可以把信号转化为频域信号,即声谱图(spectrogram),再进入RNN模型进行语音识别。
每个单词分解成多个音素(phoneme),构建更精准的传统识别算法。但在end-to-end深度神经网络模型中, 一般不需要这么做也能得到很好的识别效果。通常训练样本很大,需要上千上万个小时的语音素材。
Trigger Word Detection