Face recognition
- 人脸验证(face verification) 输入一张人脸图片,验证输出与模板是否为同一人,即一对一问题
- 人脸识别(face recognition) 输入一张人脸图片,验证输出是否为K个模板中的某一个,即一对多问题 face recognition 更难一些。假设verification错误率是1%, recognition中输出分别与K个模板都进行比较,则相应的错误率就会增加,约K%。模板个数越多,错误率越大一些。
One Shot Learning
每个人的训练样本只包含一张照片,数据库有K个人,则CNN模型输出softmax层就是K维的。 One-shot learning的性能并不好,其包含了两个缺点:
- 每个人只有一张图片,训练样本少,构建的CNN网络不够健壮
- 数据库增加另一个人,输出层softmax的维度就要发生变化,相当于要重新构建CNN网络,使模型计算量大大增加,不够灵活
相似函数(similarity function)
相似函数(similarity function)表示两张图片的相似程度,若较小,则表示两张图片相似。 对于人脸识别问题,则只需计算测试图片与数据库中K个目标的相似函数,取其中d(img1,img2)最小的目标为匹配对象。 若所有的d(img1,img2)都很大,则表示数据库没有这个人。
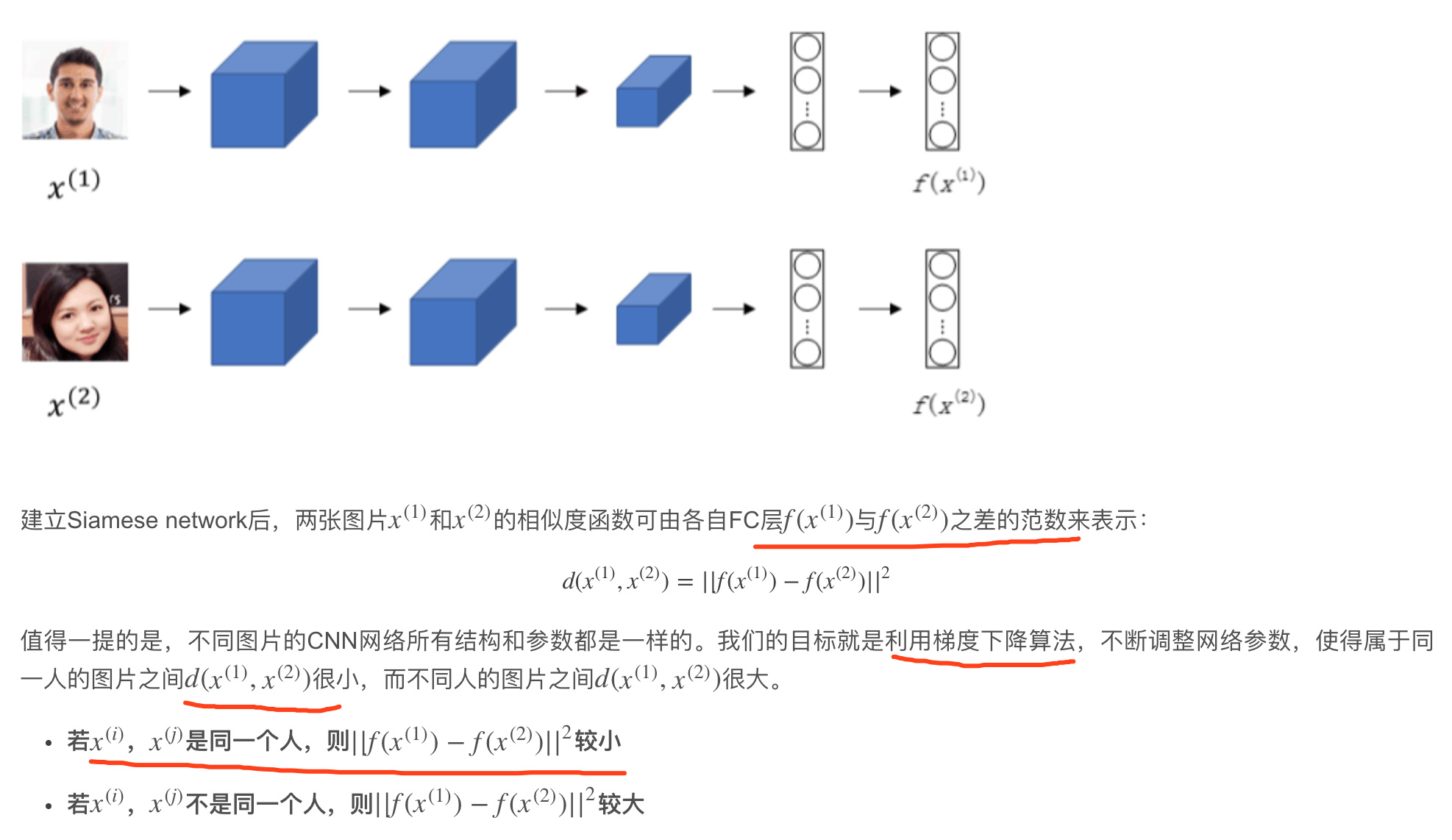
Siamese Network
CNN网络(包括CONV层、POOL层、FC层),最终得到全连接层FC,
该FC层可以看成是原始图片的编码encoding,表征了原始图片的关键特征。这个网络结构我们称之为Siamese network。
每张图片经过Siamese network后,由FC层每个神经元来表征。
Triplet Loss
CNN模型,需要定义合适的损失函数。 Triplet Loss需要每个样本包含三张图片:靶目标(Anchor)、正例(Positive)、反例(Negative)。 靶目标和正例是同一人,靶目标和反例不是同一人。
顺便提一下,这里的$\alpha$也被称为边界margin,类似与支持向量机中的margin。 举个例子,若$d(A,P)=0.5,\alpha=0.2,则d(A,N)\geq0.7$。
接下来,我们根据A,P,N三张图片,就可以定义Loss function为:
\[L(A,P,N)=max(||f(A)-f(P)||^2-||f(A)-F(N)||^2+\alpha,\ 0)\]相应地,对于m组训练样本,cost function为:
\[J=\sum_{i=1}^mL(A^{(i)},P^{(i)},N^{(i)})\]关于训练样本,必须保证同一人包含多张照片,否则无法使用这种方法。
最好的做法是人为选择A与P相差较大(例如换发型,留胡须等),A与N相差较小(例如发型一致,肤色一致等)。 这种人为地增加难度和混淆度会让模型本身去寻找学习不同人脸之间关键的差异,尽力让d(A,P)更小,让d(A,N)更大,即让模型性能更好
Face Verification and Binary Classification
将两个siamese网络组合在一起,将各自的编码层输出经过一个逻辑输出单元, 该神经元使用sigmoid函数,输出1则表示识别为同一人,输出0则表示识别为不同人。
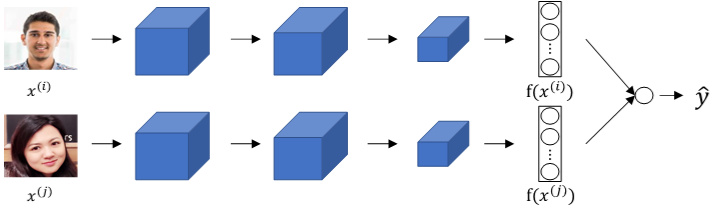
每组训练样本包含两张图片,每个siamese网络结构和参数完全相同。这样就把人脸识别问题转化成了一个二分类问题。引入逻辑输出层参数w和b,输出$\hat y$表达式为:
\[y=\sigma(\sum_{k=1}^Kw_k|f(x^{(i)})_k-f(x^{(j)})_k|+b)\]其中参数$w_k$和b都是通过梯度下降算法迭代训练得到。
在训练好网络之后,进行人脸识别的常规方法是测试图片与模板分别进行网络计算,编码层输出比较,计算逻辑输出单元。 为了减少计算量,可以使用预计算的方式在训练时就将数据库每个模板的编码层输出f(x)保存下来。因为编码层输出f(x)比原始图片数据量少很多, 所以无须保存模板图片,只要保存每个模板的f(x)即可,节约存储空间。而且,测试过程中,无须计算模板的siamese网络, 只要计算测试图片的siamese网络,得到的$f(x^{(i)})$直接与存储的模板$f(x^{(j)})$进行下一步的逻辑输出单元计算即可, 计算时间减小了接近一半。这种方法也可以应用在上一节的triplet loss网络中。
neural style transfer
将一张图片的风格“迁移”到另外一张图片中,生成具有其特色的图片。

Cost Function
神经风格迁移生成图片G的cost function由两部分组成:C与G的相似程度和S与G的相似程度。
\[J(G)=\alpha \cdot J_{content}(C,G)+\beta \cdot J_{style}(S,G)\]其中,$\alpha,\beta是超参数,用来调整J_{content}(C,G)与J_{style}(S,G)的相对比重$。
- 令G为随机像素点 使用梯度下降算法,不断修正G的所有像素点
- J(G)不断减小,G逐渐有C的内容和G的风格
Content Cost Function
J(G) 的第一部分$J_{content}(C,G)$,它表示内容图片C与生成图片G之间的相似度。
使用的CNN网络是之前训练好的模型,例如Alex-Net。需要选择合适的层数l来计算$J_{content}(C,G)$。 根据上一小节的内容,CNN的每个隐藏层分别提取原始图片的不同深度特征,由简单到复杂。如果l太小,没有迁移效果;如果l太深, 则G上某个区域将直接会出现C中的物体。因此,l既不能太浅也不能太深,一般选择网络中间层。
然后比较C和G在l层的激活函数输出\(a^{[l](C)}\)与\(a^{[l](G)}\)。相应的\(J_{content}(C,G)\)的表达式为:
\[J_{content}(C,G)=\frac12||a^{[l](C)}-a^{[l](G)}||^2\]\(a^{[l](C)}\)与\(a^{[l](G)}\)越相似,则\(J_{content}(C,G)\)越小。方法就是使用梯度下降算法,不断迭代修正G的像素值,使\(J_{content}(C,G)\)不断减小。
Style Cost Function
利用CNN网络模型,图片的风格可以定义成第l层隐藏层不同通道间激活函数的乘积(相关性)。
计算不同通道的相关性,反映了原始图片特征间的相互关系,从某种程度上刻画了图片的“风格”。

进阶repo
采用不同content loss 和 style loss 或者不同的颜色控制等方法