Support Vector Machine 介绍
若要保证对未知的测量数据也能进行正确分类,最好让分类直线距离数据集的点都有一定的距离。距离越大,分类直线对测量数据误差的容忍度越高。
容忍更多的noise,有更好的泛化能力 距离用margin表示
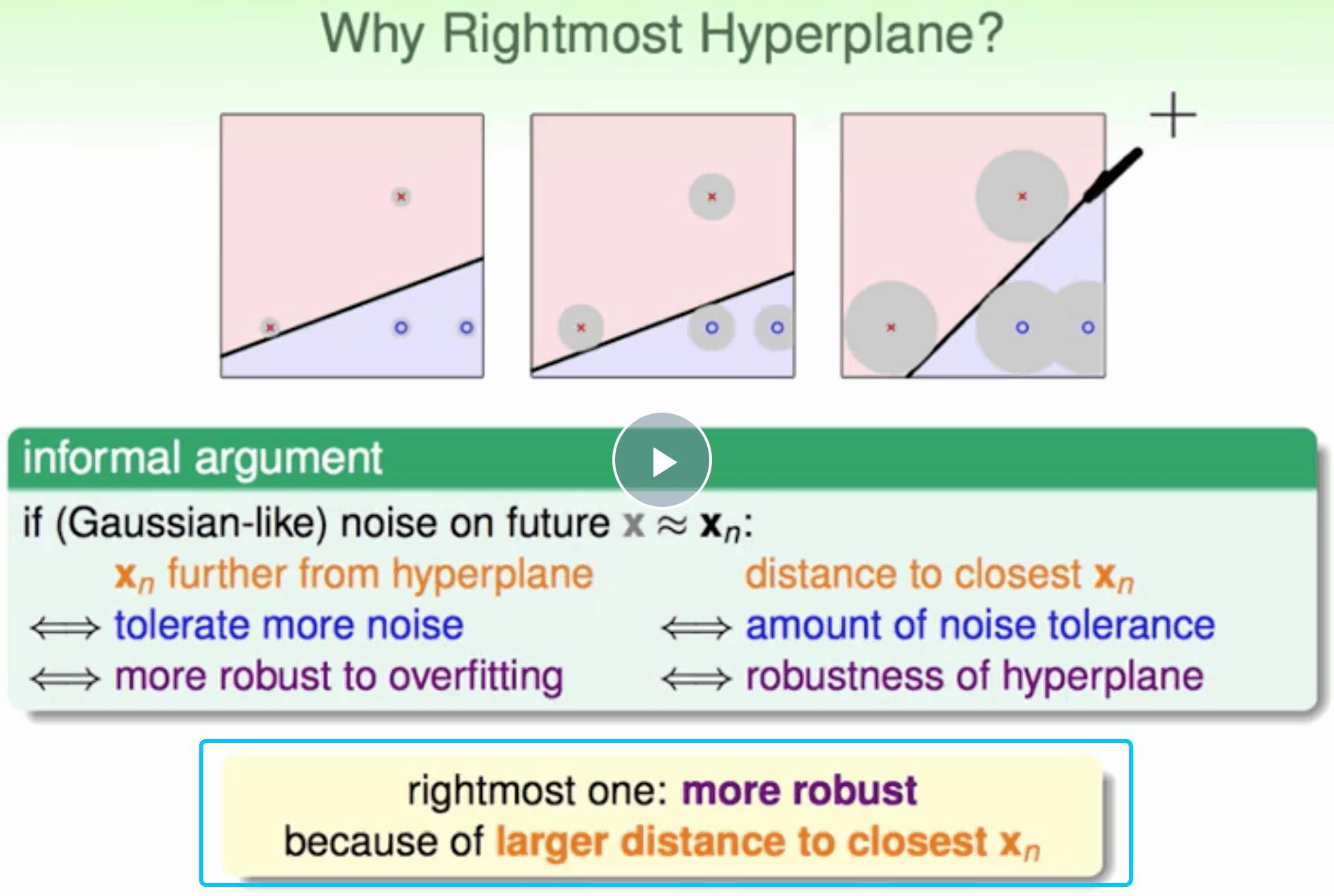 Why large margin ?
因为分隔的线粗 难以将数据集任意完全分隔,有点像regularization,降低model复杂度。
Why large margin ?
因为分隔的线粗 难以将数据集任意完全分隔,有点像regularization,降低model复杂度。
支持向量(support vector)就是离分隔超平面最近的那些点。
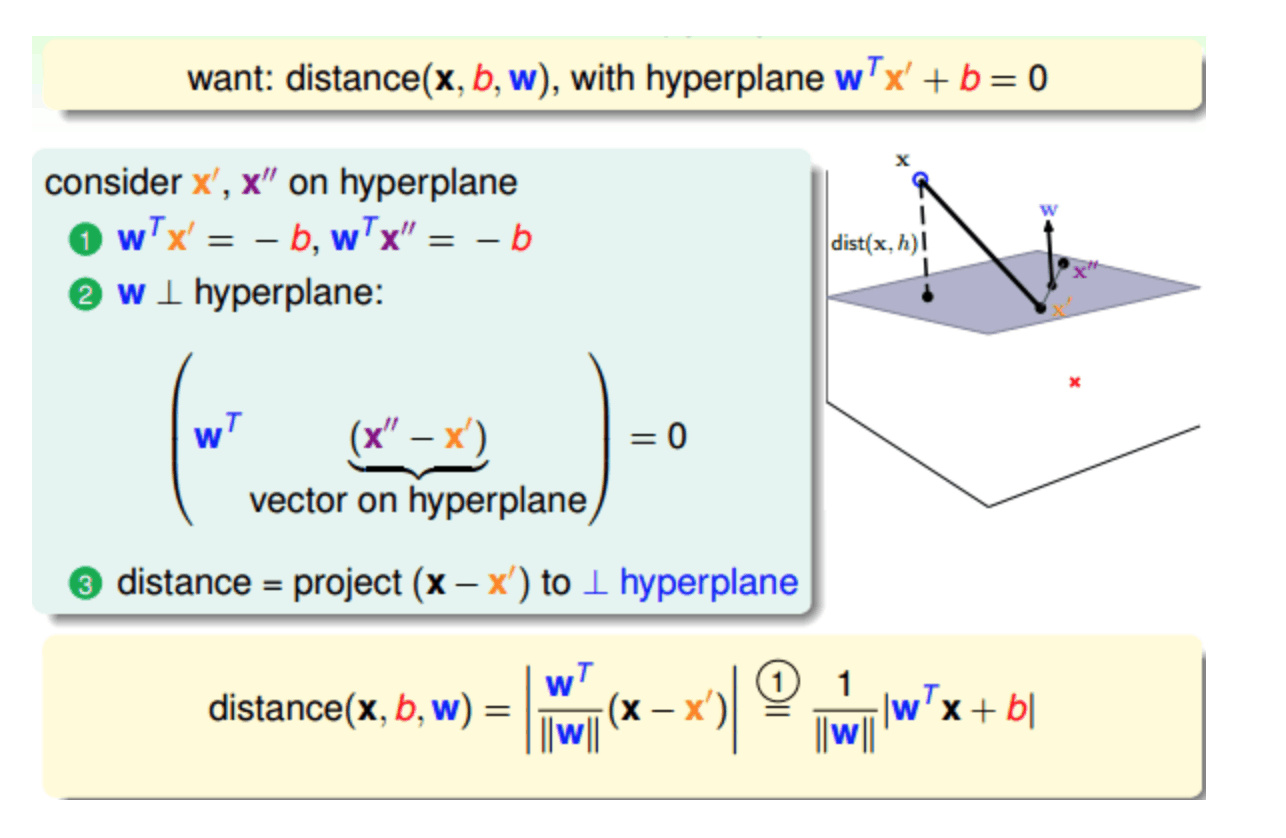
接下来要试着最大化支持向量到分隔面的距离 W 是
法向量 分隔超平面的形式可以写成$w^Tx+b$
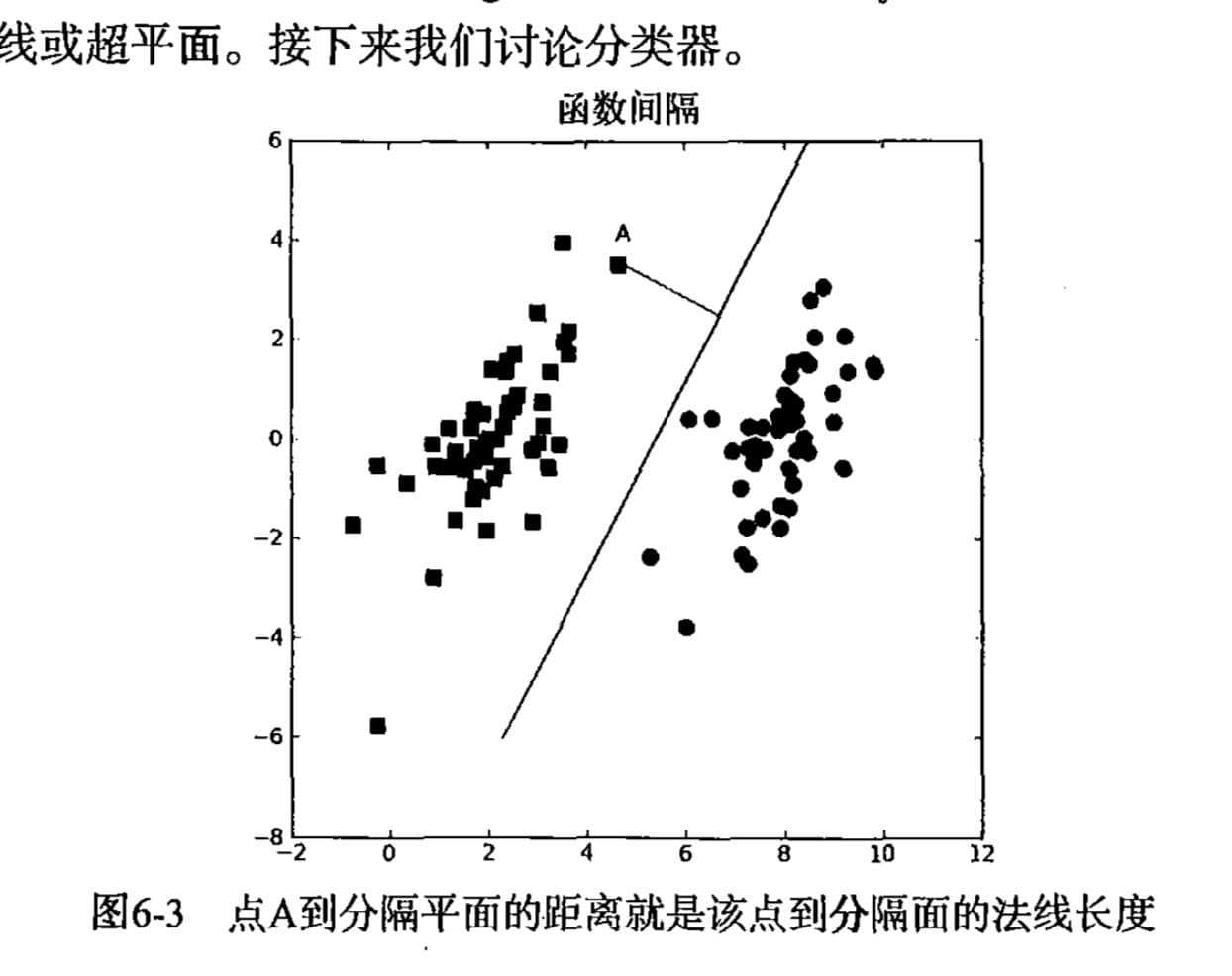
要计算点A到分隔超平面的距离,就必须给出点到分隔面的法线 或垂线的长度,该值为
$\left|w^TA+b\right|/\left|\left|w\right|\right|$
margin最大 => 即让离分类线最近的点到分类线距离最大
SVM 对特征缩放比较敏感,但对特征缩放后(例如使用Scikit-Learn的StandardScaler),判定边界看起来要好得多
推导过程
 简化计算
简化计算

再简化

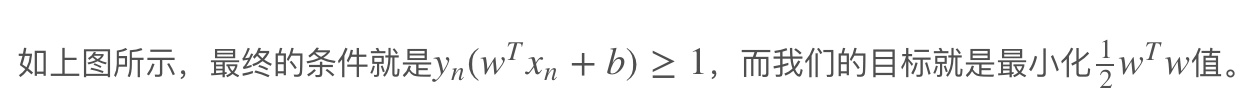
非线性SVM
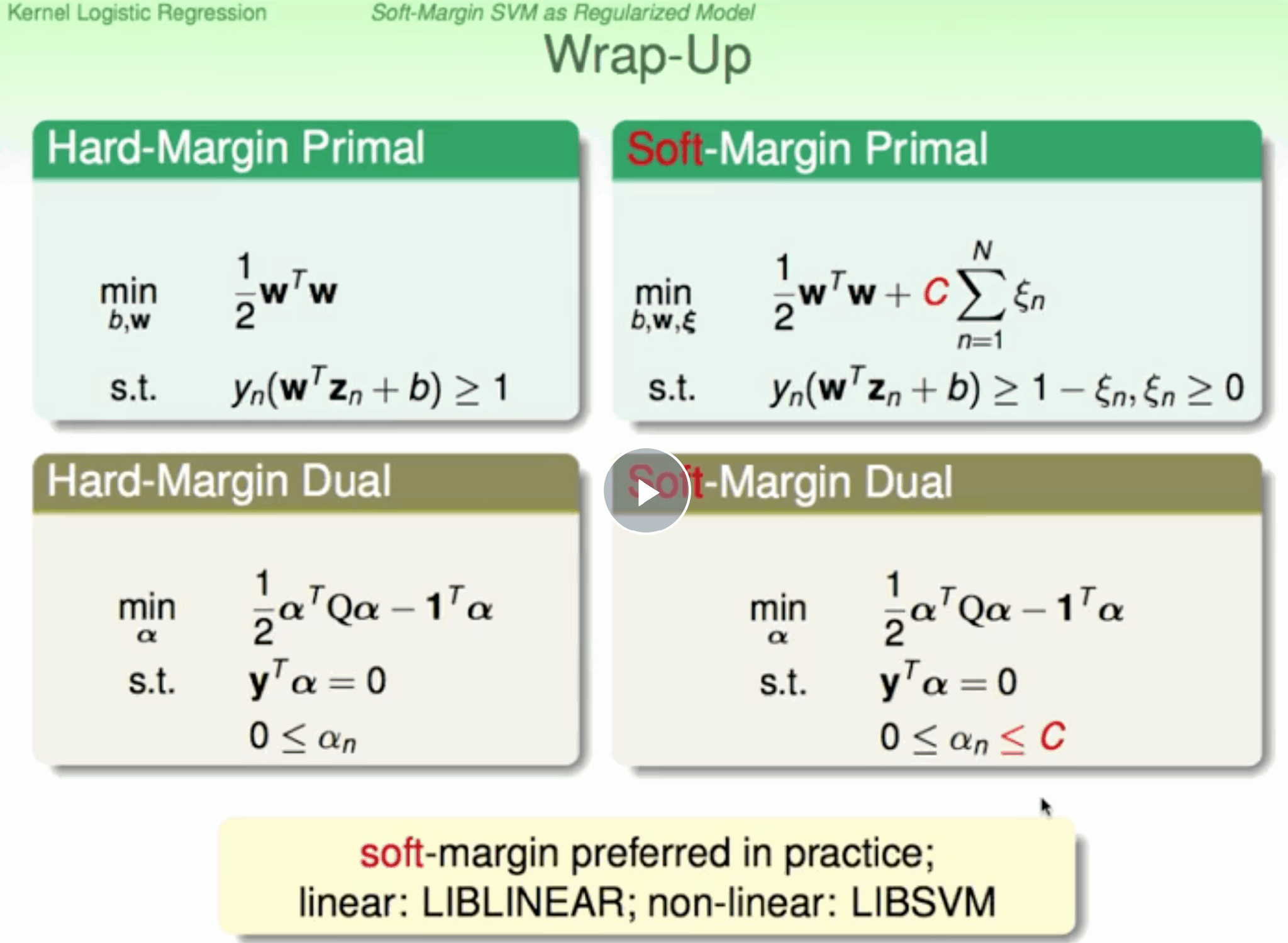
Dual SVM
对于非线性SVM,我们通常可以使用非线性变换将变量从x域转换到z域,设z域维度=d+1 ,d越高,svm通过二次规划求解就越复杂。 dual不依赖d 当数据量N很大时,也同样会增大计算难度。如果N不是很大,一般使用Dual SVM来解决问题,只是简化求解不能真正脱离对d的依赖
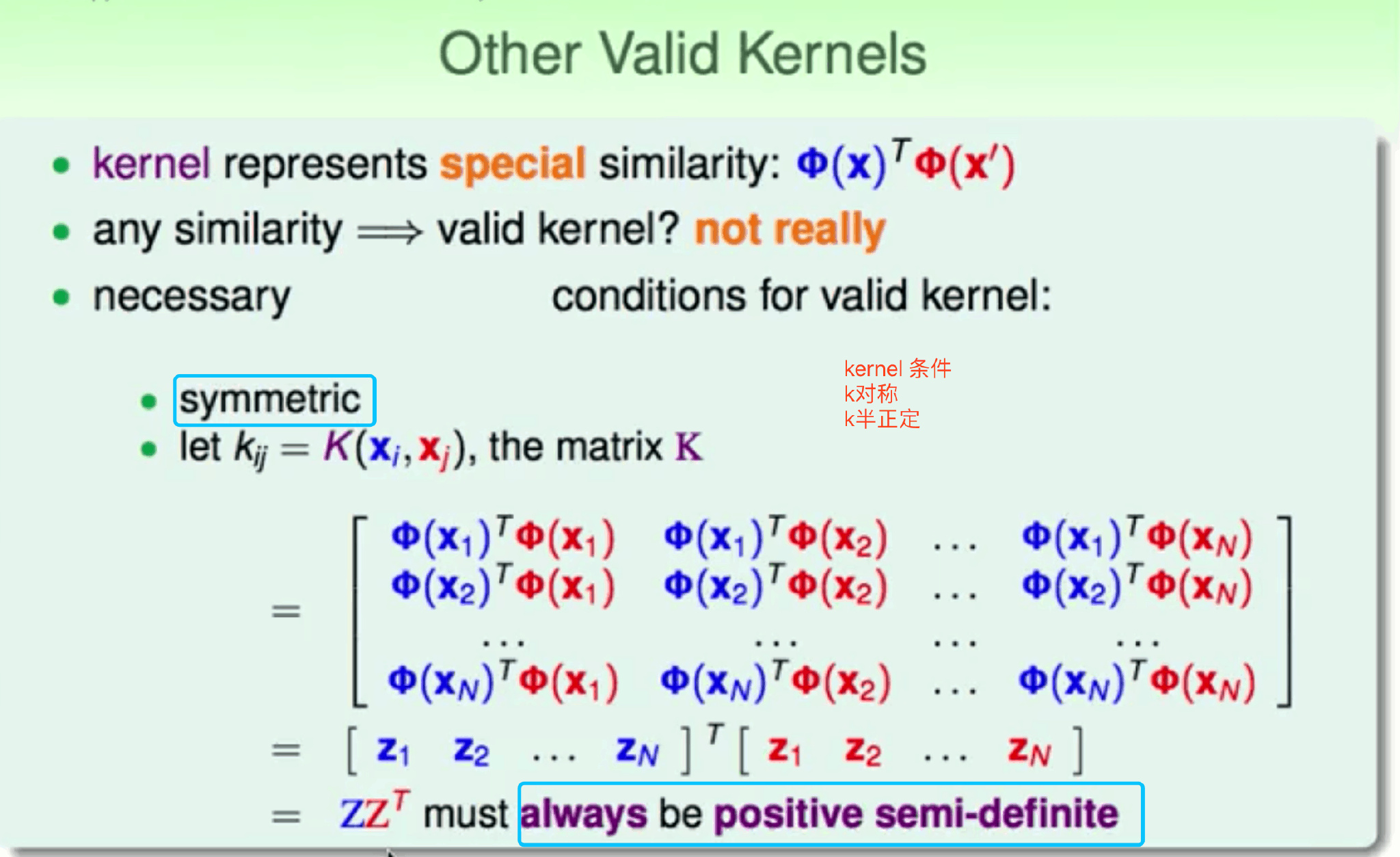
Kernel
基于dual SVM推导 Kernel Function 合并特征转换和计算内积 非线性不受维度限制简化计算速度


polynomial Kernel
简化好看的形式 不同的Kernel=>不同的margin


1 | |
linear Kernel
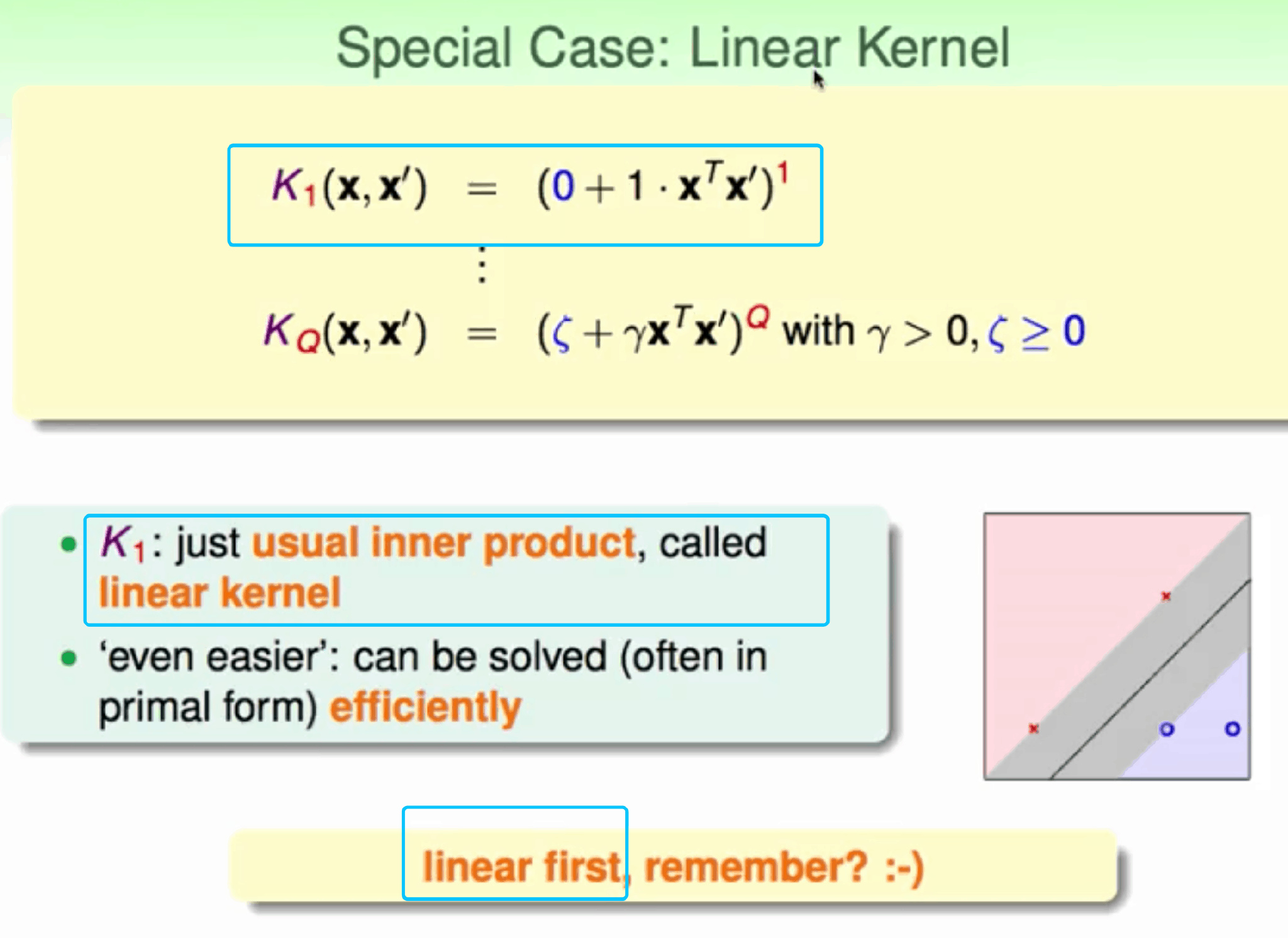
1 | |
Gaussian Kernel
无限维转换 在低维空间解决非线性
利用泰勒展开反推 => Φ(x) ,Φ(x)是无限多维的
 高斯核函数称为径向基函数(Radial Basis Function, RBF)
高斯核函数称为径向基函数(Radial Basis Function, RBF)

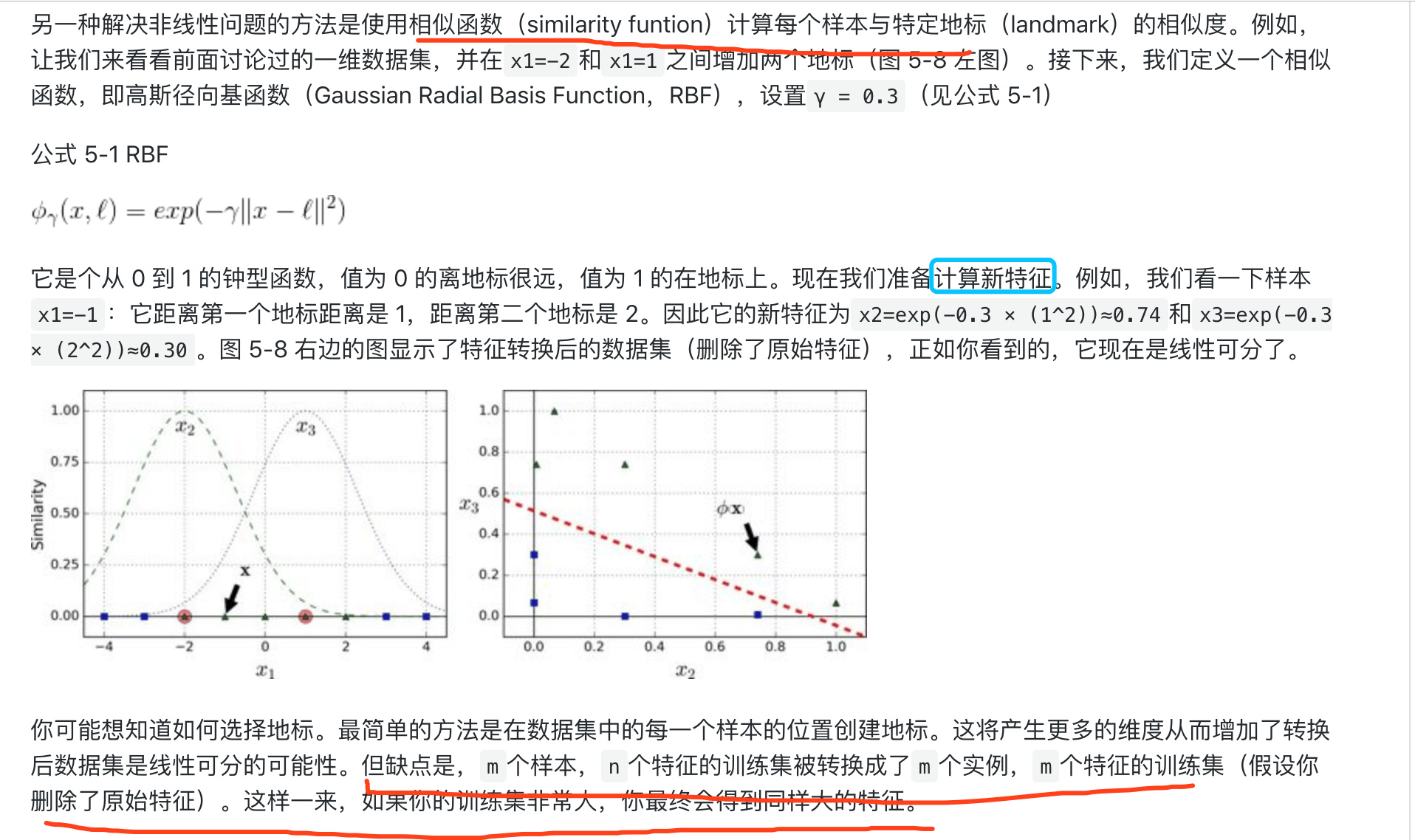
1 | |
对比
Linear Kernel 优点:
- 计算简单、快速,
- 直观,便于理解 缺点:如果数据不是线性可分的情况,不能使用了
Polynomial Kernel
 比线性灵活
缺点:
比线性灵活
缺点:
- 当Q很大时,K的数值范围波动很大
- 参数个数较多难以选择合适的值
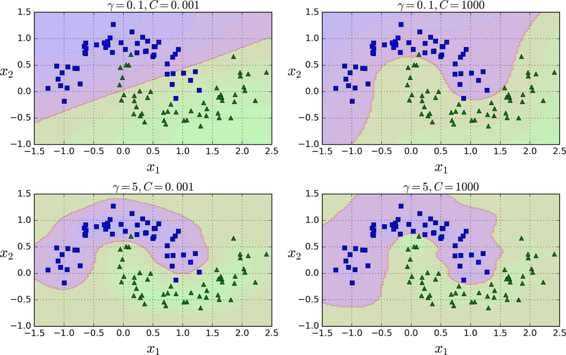
Gaussian Kernel 最常用 要小心用
- 比其他kernel强大
- 容易计算 比poly
- 参数少 比poly 缺点
- 不直观
- slower than linear
- easy overfit

other kernel
m 数据集数量 n 维度
Soft-Margin
允许有分类错误 在 Scikit-Learn 库的 SVM 类,你可以用C超参数(惩罚系数)来控制这种平衡
C 越小 容忍错误度越大 overfit 也可以减少C
 上面的不能用二次规划计算,不能区分error的程度
上面的不能用二次规划计算,不能区分error的程度
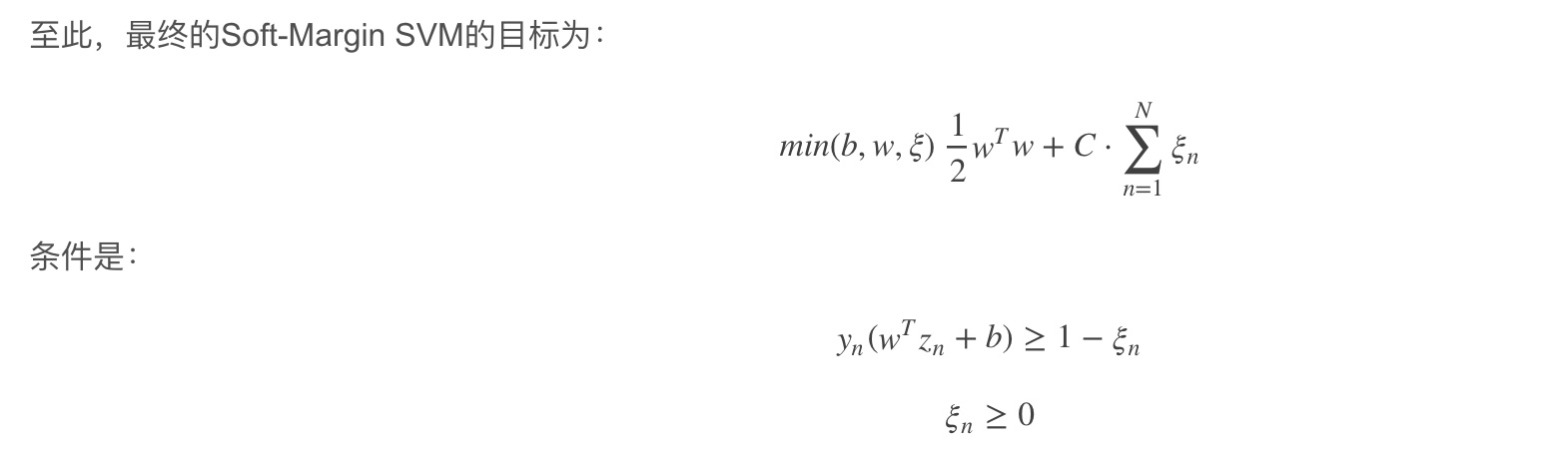 点距离边界
点距离边界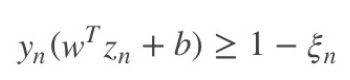
其中,ξn表示每个点犯错误的程度,ξn=0,表示没有错误,ξn越大,表示错误越大, 即点距离边界越小。
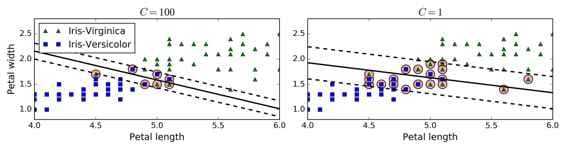
参数C表示尽可能选择宽边界和尽可能不要犯错两者之间的权衡,因为边界宽了,往往犯错误的点会增加 large C表示希望得到更少的分类错误,即不惜选择窄边界也要尽可能把更多点正确分类 small C表示希望得到更宽的边界,即不惜增加错误点个数也要选择更宽的分类边界
加载了内置的鸢尾花(Iris)数据集,缩放特征,并训练一个线性 SVM 模型(使用LinearSVC类,超参数C=1,hinge 损失函数)来检测 Virginica 鸢尾花
1 | |

svm regression
 λ 越大,L2Regularization的程度就越大。C越小,相应的margin就越大。Large-Margin等同于Regularization效果一致,防止过拟合的作用。
L2-regularized linear model都可以使用kernel来解决。
λ 越大,L2Regularization的程度就越大。C越小,相应的margin就越大。Large-Margin等同于Regularization效果一致,防止过拟合的作用。
L2-regularized linear model都可以使用kernel来解决。
不仅仅支持线性和非线性的分类任务,还支持线性和非线性的回归任务。
技巧在于逆转我们的目标:限制间隔违规的情况下,不是试图在两个类别之间找到尽可能大的“街道”(即间隔)。
SVM 回归任务是限制间隔违规情况下,尽量放置更多的样本在“街道”上。“街道”的宽度由超参数$ϵ$控制。
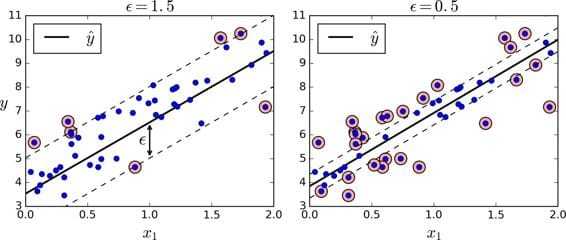
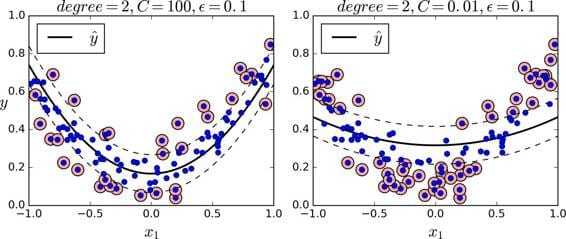
1 | |
1 | |
-
SVM Classifier 在margin外 trying to fit the largest possible street between two classes while limiting margin violations
-
SVM Regression 在margin内 tries to fit as many instances as possible on the street while limiting margin violations