投资组合
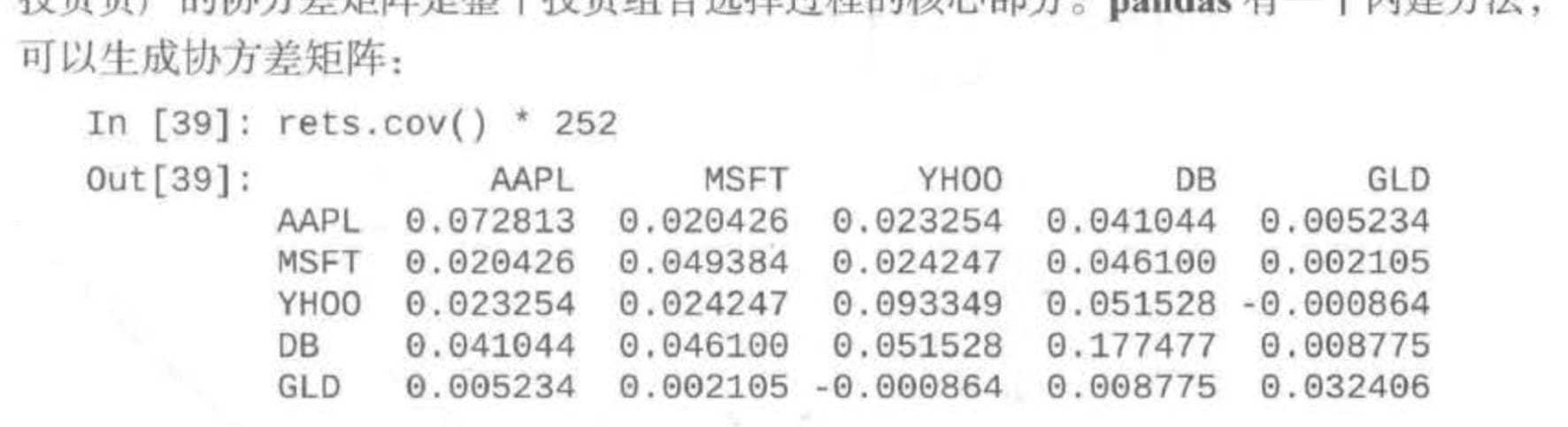
求对数收益 协方差

sum(W) =1

预期收益


最优化投资组合


所有最优化投资组合一一即目标收益率水平俨波动率最小的所有投资者(或者纷走风 险水平下收益率最大的所有投资组合)

对数收益率

收益相关性
- 线性回归
-
pd.corr rolling_corr 不同时期相关性
回归分析
numpy
1 | |
1 | |
statsmodels
1 | |
sklearn
1 | |
持久化
pickle .pkl csv sql sqlite
快 numpy save .npy load pd HDFStore 空间小 使用numpy的结构数组 保存到PyTable 更好
PyTable内存外计算